Kubernetes学习前的必知知识点
Table of Contents
DevOps详解
到底该如何理解DevOps
持续集成,持续交付,持续部署(CI/CD)简介
在有关微服务、DevOps、Cloud-native、系统部署等的讨论中,蓝绿部署、AB 测试、灰度发布、滚动发布、红黑部署等概念经常被提到,它们有什么区别呢?
微服务架构
Docker三剑客:Compose,Machine和Swarm
容器编排工具怎么选 Swarm kubernetes Mesos的优缺点
Swarm,Fleet,Kubernetes,Mesos -编排工具的对比
借鉴
DevOps详解
最近我阅读了很多有关DevOps的文章,其中一些非常有趣,然而一些内容也很欠考虑。貌似很多人越来越坚定地在DevOps与chef、puppet或Docker容器的熟练运用方面划了等号。对此我有不同看法。DevOps的范畴远远超过puppet或Docker等工具。
这样的看法甚至让我感觉有些气愤。DevOps在我看来极为重要,过去15年来,我一直在大型机构,主要是大型金融机构中从事工程业务。DevOps是一种非常重要的方法论,该方法将解决一些最大型问题的基本原则和实践恰如其分地融为一体,很好地解决了此类机构的软件开发项目中一种最令人感觉悲凉的失败要素:开发者和运维人员之间的混乱之墙。
请不要误会我的这种观点,除了某些XP实践,大部分此类大型机构对敏捷开发方法论的运用还有很长的路要走,同时还有很多其他原因会导致软件开发项目的失败或延误。
但在我看来,混乱之墙目前依然是他们所面临的最令人沮丧、最浪费时间、同时也相当愚蠢的问题。
与其独自生闷气,我觉得不如说点更实在的东西,写一篇尽可能精准的文章,向大家介绍DevOps到底是什么,能为我们带来什么。长话短说,DevOps并不是某一套工具。DevOps是一种方法论,其中包含一系列基本原则和实践,仅此而已。而所用的工具(或者说“工具链”吧,毕竟用于为这些实践提供支持的工具集有着极高的扩展性)只是为了对这样的实践提供支持。
最终来说,这些工具本身并不重要。相比两年前,目前的DevOps工具链已经产生了翻天覆地的变化,可想而知,两年后还会产生更大的差异。不过这并不重要。重要的是能够合理地理解这些基本原则和实践。
本文并不准备介绍某些工具链,甚至完全不会提到这些工具。网上讨论DevOps工具链的文章已经太多了。我想在本文中谈谈最基本的原则和实践,它们的主要目的,毕竟这些才是对我而言最重要的。
DevOps是一种方法论,归纳总结了面临独一无二的机遇和强有力需求的网络巨头们,结合自身业务本质构思出全新工作方式的过程中所采用的实践,而他们的业务需求也很直接:以史无前例的节奏对自己的系统进行演进,有时候可能还需要以天为单位对系统或业务进行扩展。
虽然DevOps对初创公司来说很明显是不可或缺的,但我认为那些有着庞大的老式IT部门的大企业才是能从这些基本原则和实践中获得最大收益的。本文将试图解释得出这个结论的原因和实现方法。
本文的部分内容已发布为Slideshare演示幻灯片,可在这里浏览:http://www.slideshare.net/JrmeKehrli/devops-explained-72091158
1. 简介
DevOps所关注的不是工具本身,也不是对chef或Docker的掌握程度。DevOps是一种方法论,是一系列可以帮助开发者和运维人员在实现各自目标(Goal)的前提下,向自己的客户或用户交付最大化价值及最高质量成果的基本原则和实践。
开发者和运维人员之间最大的问题在于:虽然都是企业中大型IT部门不可或缺的,但他们有着截然不同的目的(Objective)。

开发者和运维人员之间目的上的差异就叫做混乱之墙。下文会介绍这个概念的准确定义,以及为什么我认为这种状况很严峻并且很糟糕。
DevOps是一种融合了一系列基本原则和实践的方法论(并从这些实践中派生出了各种工具),意在帮助这些人员向着一个统一的共同目的努力:尽可能为公司提供更多价值。
令人惊奇的是,这个问题竟然有一个非常简单的“银子弹”:让生产端变得敏捷起来!
而这恰恰正是DevOps所要达成的唯一目标!
但在进一步讨论这一点之前,首先需要谈谈其他几件事。
1.1 管理信条
IT管理这场战争的原动力到底是什么?换句话说,在软件开发项目中,管理工作首要的,以及最重要的目的是什么?
有什么想法吗?
我来提供一个线索吧:在建立一家初创公司时,最重要的事情是什么?
当然是要加快上市时间(TTM)!
上市时间(即TTM)是指一件产品从最初的构思到最终可供用户使用或购买这一过程所需要的时间。对于产品很快会过时的行业,TTM是一个非常重要的概念。
在软件工程方面,所采用的方法、业务,以及具体技术几乎每年都会变化,因而TTM就成了一个非常重要的KPI(关键绩效指标)。
TTM通常也会被叫做前置时间(Lead Time)。
第一个问题在于,(很多人认为)在开发过程中TTM和产品质量是两个对立的属性。在下文可以看到,改善质量(进而提高稳定性)是运维人员的目的,而开发者的目的在于降低前置时间(进而提高TTM)。
请容我来解释一下。
IT组织或部门通常会通过两个关键的KPI进行评估:软件本身的质量,因而需要尽可能减少缺陷的数量;此外还有TTM,因而需要将业务构想(通常由业务用户提供)变为最终成果,并以尽可能快的速度提供给用户或客户。
这里的问题在于,大部分情况下这两个截然不同的目的是由两个不同团队提供支持的:负责构建软件的开发者,以及负责运行软件的运维人员。
1.2 一个典型的IT组织
在组织内部负责管理重要IT部门的典型IT组织通常看起来是这样的:

主要由于历史的原因(大部分运维人员来自硬件和电信业务领域),运维人员和开发者分属不同的组织结构分支。开发者属于研发部门,而运维人员大部分时候属于基础架构部门(或专门的运维部门)。
别忘了,他们有着不同的目的:

此外作为旁注,这两个团队有时候会使用不同的预算来运营。开发团队使用构建(Build)预算,运维团队使用运营(Run)预算。不同的预算,对控制权越来越高的需求,以及企业IT成本的缩水,这些因素结合在一起会进一步放大两个团队各自目的的对立性。
(依本人愚见,时至今日,随着人与人之间无时无刻随时随地进行的交互,以及由不同目的推动着企业和社会进行数字化转型,IT预算方面古老的“规划/构建/运行”框架已经不那么合理了,不过这又是另一回事了。)
1.3 运维人员测挫败感
接下来看看运维人员,一起看看典型的运维团队把大部分时间都花在哪里了:

(来源:Study from Deepak Patil [Microsoft Global Foundation Services] in 2006, via James Hamilton [Amazon Web Services]
生产团队有将近一半(47%)的时间花在了与部署有关的工作中:
- 执行实际的部署工作,或
- 修复与部署工作有关的问题
这样的KPI其实相当疯狂,但实际上我们早就应该采纳。实际上早在40年前,计算机科学的“原始时代”就已涌现出运维团队,当时计算机主要运用在工业界,运维人员需要手工运行大量命令来执行自己的任务。为了履行职责,他们已经习惯于按照清单运行各种各样的命令或手工流程。
突然有一天他们终于意识到自己“总在做着相同的事情”,然而长达四十多年的工作过程中却几乎没人考虑过变革。
考虑到这一点你会发现,实在是太疯狂了。平均来说,运维人员将近一半的时间都在处理与部署有关的任务!
为了改变这种状况,必须考虑到两个最关键的需求:
- 通过自动化部署将目前这种手工任务所需的时间减少31%。
- 通过产业化措施(类似于通过XP和敏捷实现的软件开发产业化)将需要处理的与这些部署有关的问题减少16%。
1.4 基础架构自动化
在这方面也有一个相当富有启发性的统计结果:
以手工操作的数量所表示的成功部署概率。

这些统计告诉我们:
- 只需手工运行5条命令的情况下,成功部署的概率就已跌至86%。
- 如需手工运行55条命令,成功部署的概率将跌至22%。
- 如需手工运行100条命令,成功部署的概率将趋近于0(仅2%)!
成功部署意味着软件能够按照预期在生产环境中运行。未能成功部署意味着有东西出错,可能需要进行必要的分析才能了解部署过程中哪里出错,是否需要应用某种补丁,或需要修改某些配置。
因此让这一切实现自动化并不惜一切代价避免手工操作似乎是个好主意,对吧?
那么行业里这方面的现状是怎样的:

(来源:IT Ops & DevOps Productivity Report 2013 - Rebellabs )
(说实话,这个统计信息比较老了,是2013年的结果,相信现在的结果会有所不同)
然而这也可以让我们明确的知道,在基础架构自动化方面我们还有多远的路要走,并且DevOps的基本原则和实践依然是那么的重要。
网络巨头们当然会通过新的方法和实践及时满足自己的需求,他们早已开始构建自己的工程业务,而正是他们所确立的实践逐渐衍生出当今我们所熟悉的DevOps。
看看这些网络巨头们在这方面目前所处的位置吧,举几个例子:
- Facebook有数千名开发和运维人员,成千上万台服务器。平均来说一位运维人员负责500台服务器(还认为自动化是可选的吗?)他们每天部署两次(环式部署,Deployment ring的概念)。
- Flickr每天部署10次。
- Netflix明确针对失败进行各种设计!他们的软件按照设计从最底层即可容忍系统失败,他们会在生产环境中进行全面的测试:每天通过随机关闭虚拟机的方式在生产环境中执行65000次失败测试…… 并确保这种情况下一切依然可以正常工作。
他们这种做法秘密何在?
1.5 DevOps:仅此一次,一颗神奇的银子弹
他们的秘密很简单:将敏捷扩展至生产端:

DevOps的共存主要是为了扩展敏捷开发实践,进一步完善软件变更在构建、验证、部署、交付等阶段中的流动,同时通过软件应用程序的全面所有权予力跨职能团队完成从设计到生产支持等各环节的工作。
DevOps鼓励软件开发者和IT运维人员之间所进行的沟通、协作、集成和自动化,借此有助于改善双方在交付软件过程中的速度和质量。
DevOps团队更侧重于通过标准化开发环境和自动化交付流程改善交付工作的可预测性、效率、安全性,以及可维护性。理想情况下,DevOps可以为开发者提供更可控的生产环境,帮助他们更好地理解生产基础架构。
DevOps鼓励团队自主进行自己应用程序的构建、验证、交付和支持。
那么核心原则到底是什么?

下文将介绍最重要的三大基本原则。
2. 基础架构即代码
人总会犯错,因为人脑实在是不擅长处理重复性的任务,相比Shell脚本,人类的速度实在是太慢了。毕竟我们都是人类,因此有必要像处理代码那样考虑和处理有关基础架构的概念!
基础架构即代码(IaC)是大部分通用DevOps实践的前提要求,例如版本控制、代码审阅、持续集成、自动化测试。这一概念涉及计算基础架构(容器、虚拟机、物理机、软件安装等)的管理和供应,以及通过机器可处理的定义文件或脚本对其进行的配置,交互式配置工具和手工命令的使用已经不合时宜了。
这一原则对DevOps的重要性怎么强调都不为过,它可以真正将软件开发相关的实践应用给服务器和基础架构。
云计算使得复杂的IT部署可以继续效仿传统物理拓扑。我们可以相对轻松地对复杂虚拟网络、存储和服务器的构建实现自动化。服务器环境的方方面面,上至基础架构下至操作系统设置,均可编码并存储至版本控制仓库。
2.1 概述
以非常概括的方式来看,基础架构和运维所需实现的自动化程度可通过下图这种架构来表示:

上述架构图中作为示例的工具主要面向不同层的构建工作,实际上DevOps工具链的作用远不止如此。
我觉得在这里可以略微深入地谈谈DevOps的工具链了。
2.2 DevOps工具链
DevOps实际是一种文化上的变迁,代表了开发、运维、测试等环节之间的协作,因此DevOps工具是非常多种多样的,甚至可以由多种工具组成一个完整的DevOps工具链。此类工具可以应用于一种或多种类别,并可体现出软件开发和交付过程的不同阶段:
- 编码:代码开发和审阅,版本控制工具、代码合并工具
- 构建:持续集成工具、构建状态统计工具
- 测试:通过测试和结果确定绩效的工具
- 打包:成品仓库、应用程序部署前暂存
- 发布:变更管理、发布审批、发布自动化
- 配置:基础架构配置和部署,基础架构即代码工具
- 监视:应用程序性能监视、最终用户体验
虽然可用工具有很多,但其中一些环节是组织内部应用DevOps工具链不可或缺的。
诸如Docker(容器化)、Jenkins(持续集成)、Puppet(基础架构构建)、Vagrant(虚拟化平台)等常用、广泛使用的工具都是2016年的DevOps热门工具。
基础架构组件的版本控制、持续集成和自动化测试
基础架构的版本控制能力(而非基础架构的构建脚本或配置文件)及对其进行自动化测试的能力极其重要。
DevOps最终会将30年前软件工程领域所采用的同一套XP实践带至生产端。
此外基础架构元素应该能向软件交付物一样进行持续集成。
2.3 收益
DevOps的收益有很多,包括但不限于:
- 可重复性与可靠性:时至今日,构建生产用计算机只需要运行脚本或必要的puppet命令即可。通过恰当地使用Docker容器或Vagrant虚拟机,只需运行一条命令即可配置好包含操作系统层以及所需软件和配置的生产用计算机。当然,随着各种变更或软件开发、持续集成,并自动测试,这套构建脚本或机制也会进行持续集成。
最终幸亏有了XP或敏捷,我们在软件开发端所使用的同一套实践也能让运维端获益。
- 生产力:一键部署,一键供应,一键创建新环境……整个生产环境可以通过一条命令或一键点击的方式创建。这样的一条命令也许会运行长达数小时,但在这过程中运维人员可以从事其他更有趣的工作,而无需等待一条命令执行完毕后继续输入下一条命令,毕竟这样的过程有时候可能需要花费几天时间才能完成……
- 恢复时间!:一键点击即可恢复生产环境,就是这么简单。
- 确保基础架构的同质:彻底避免运维人员每次构建环境或安装软件时最终获得的结果与预期有所差异,这是确保基础架构绝对同质(Homogeneous)并且可再现的唯一可行方法。以此为基础,通过对脚本或Puppet配置文件使用版本控制机制,我们甚至可以重建出与上周、上个月,或软件特定版本发布时完全一致的生产环境。
- 维持整齐划一的标准:基础架构标准甚至可以不复存在,代码本身就是标准。
- 让开发者自行完成大部分工作:如果开发者自己突然可以在自己的基础架构上一键点击重建生产环境,他们也就可以自行完成很多与生产环境有关的任务,例如更好地理解生产失败,提供更恰当的配置,实现部署脚本等。
这只是我个人感觉IaC可提供的部分收益,相信还有很多其他收益。
3. 持续交付
持续交付是一种可以帮助团队以更短的周期交付软件的方法,该方法确保了团队可以在任何时间发布出可靠的软件。该方法意在以更快速度更高频率进行软件的构建、测试和发布。
通过对生产环境中的应用程序进行更高频次的增量更新,这种方法有助于降低交付变更过程中涉及的成本、时间和风险。足够简单直接并且可重复的部署流程对持续交付而言至关重要。
注意:持续交付 ≠ 持续部署 - 有时候很多人会把持续交付误认为成持续部署。持续部署是指每个变更可以自动部署到生产环境。持续交付是指团队确保每个变更可以部署至生产环境,但也许并不需要实际部署,这通常可能是出于业务方面的原因。只有成功实现持续交付的前提下,才能进行持续部署。
持续交付的主要想法在于:
- 部署越频繁,对部署流程就会越熟悉,自动化机制就能获得更好的结果。如果同一件事每天需要执行3次,很快你将变的无比娴熟,但很快也会因为日复一日解决同样的问题而感到厌烦。
- 部署越频繁,所部属的变更集就越微不足道,而这些微不足道的内容最有可能出错,甚至可能导致丢失对整个变更集的控制力。
- 部署越频繁,TTR(修复/解决所需时间)指标就会越出色,从业务用户处获得有关功能的各类反馈的速度越快,作出改进以便完美满足对方需求的过程也会越简单(这方面TTR与TTM其实非常相似)。

(来源:Ops Meta-Metrics: The Currency You Pay For Change )
但持续交付并不仅仅是尽可能频繁地构建可发布、生产就绪版本的软件产品那么简单。持续交付包含3个关键实践:
- 从实践中学习
- 自动化
- 更频繁的部署
3.1 从实践中学习
持续交付的关键在于要能从实践中学习。真理并不存在于开发团队中,而在于业务用户中。然而无论花多长时间,没人能真正清楚地表达自己的想法,或者将自己的想法用清晰的文档概括出来。也正是因此,敏捷方法论强调将功能提供给用户,并不惜一切代价从用户处获得尽可能多的反馈。
持续交付与持续部署类似,需要尽可能减少前置时间,这也是尽快从用户处获得“真理”的关键。
但真理绝对不会来自正规形式的用户反馈。我们绝不能尽信自己的用户或寄希望于通过正规形式的反馈了解用户。我们只能相信自己的度量。
痴迷于度量是精益创业(Lean Startup)活动中一个重要的概念,但这一概念对DevOps同样重要。我们应该度量一切!确定最恰当的度量指标可以让团队了解某种方法最终能否成功或失败,了解怎样做可以获得更好的结果,以及哪些最成功的做法同时也蕴含着一定的风险。为了帮助团队做出更明智的决策,在确定要衡量的指标时,一定要抱着“宁多勿少”的原则。
不需要“考虑”,只需要“知道”!“知道”的唯一方法就是度量,度量一切:响应时间、用户思考时间、展示次数、API调用次数、点击率等,但这些并非需要度量的全部。找出所有能让你更进一步了解用户对功能看法的度量指标,对所有这些指标进行度量!
这种方法可以表示为如下形式:

3.2 自动化
自动化已经在上文2. 基础架构即代码一节进行了讨论。
在这里我想强调的是,在没有将与基础架构有关的所有供应和任务实现妥善、全面的自动化之前,持续交付根本无从谈起。
这一点很重要,因此有必要再重复一遍:环境的搭建和生产就绪版本软件的部署只需要一键点击,只需要运行一条命令,整个过程应该自动完成。否则根本无法设想能一天多次部署同一个软件。
在下文的3.5 零停机部署一节中,还将介绍有助于自动化交付的其他重要技术。
3.3 更频繁的部署
DevOps的信条在于:
“越是困难的事,需要更频繁地进行!”
敏捷思维中,困难任务更要迎难而上,更频繁地去做,这中想法非常重要。
自动化测试、重构、数据库迁移、面向客户的产品规格、规划、发布 - 所有这些活动都要尽可能频繁地进行。
原因主要有三点:
- 首先,随着要做的工作量逐渐增加,这些任务也会变的愈加困难,但如果能拆解为小块,则会变的相对容易些。
以数据库迁移为例:一些涉及大量表的大规模数据库迁移工作很麻烦,容易出错。但如果一次只迁移一部分,则可以相对较容易地成功完成整个迁移任务。此外还可以轻松地将多个小规模的迁移任务安排成一定的序列,在将一个艰难的大任务拆解为一系列容易实现的小目标后,处理起来就简单多了。(这也是数据库重构的本质)
- 第二个原因在于反馈。大部分敏捷思维关注的是设置反馈环路,借此让我们更快速地学习了解。反馈已经是极限编程(Extreme Programming)中一个非常重要,蕴含巨大价值的概念。在诸如软件开发等复杂流程中,我们需要更频繁地检查自己的最新进展,并进行必要的纠正。为此我们必须尽一切可能创建反馈环路,并提高反馈的频率,这样才能更快速地酌情做出调整。
- 第三个原因是实践。对于任何活动,越频繁地从事就越能获得完善。实践可以帮助我们理清整个流程,让我们更熟悉代表有事情出错的征兆。只要认真琢磨自己从事的工作,就能提炼出近一步完善所需的实践。
对于软件开发,也有可能实现一定程度的自动化。一旦有人将某件事做了多次,就可以更容易地确定该如何进行自动化,更重要的是,这样的人在对这些事情实现自动化方面将有更大的动机。此时自动化尤为重要,因为可以加快速度并降低出错的概率。

那么这就产生了一个问题:使用DevOps方法时,该选择怎样的交付频率?
这个问题没有标准答案,而是取决于产品、团队、市场、公司、用户、运维需求等各种因素。
我认为最佳答案应该是:如果不能实现至少每两周一次交付,或在冲刺阶段结束时交付,那么连敏捷都谈不上,DevOps又从何谈起呢?
DevOps鼓励我们尽可能频繁的交付。在我看来,你需要对团队进行培训,让他们能够做到尽可能频繁的交付。我在我的团队中使用的一种较为可行的方法是在QA环境中每天交付两次。交付过程是完全自动化的:每天两次,中午和午夜各一次,计算机启动起来,构建软件组件,运行集成测试,构建并启动虚拟机,部署软件组件,对其进行配置,运行功能测试等。
3.4 持续交付的前提需求
在改为使用持续交付方式之前,需要满足哪些要求?
我草拟的需求清单如下:
- 对软件组件的开发和平台的供应和设置进行持续集成。
- TDD - 测试驱动的开发。这一点还有待商榷……但始终还是需要面对:TDD是目前唯一能通过单元测试对代码和分支进行可接受程度覆盖的方法(单元测试使得问题的修复过程比集成测试或功能测试容易很多)。
- 代码审阅!至少要进行代码审阅……如果能进行结对编程(Pair programming)当然就更好了。
- 软件的持续审计 - 例如使用Sonar。
- 在生产级环境实现功能测试的自动化。
- 更强大的非功能测试自动化(性能、可用性等)。
- 独立于目标环境的自动化打包和部署。
另外在管理重大功能和演进时,还需要具备健全的软件开发实践,例如零停机部署技术。
3.5 零停机部署
“零停机部署(ZDD)可在不中断现有服务的情况下部署新版系统。”
通过ZDD方式部署应用程序时,可在确保用户不会遭遇应用程序停机的前提下将新版应用引入生产环境。从用户和公司的角度来看,这应该是最佳部署方式,因为可以在不造成任何中断的情况下引入新功能并修复Bug。
下文将介绍4种技术:
- 功能开关(Feature Flipping)
- 摸黑启动(Dark launch)
- 蓝/绿部署(Blue/Green Deployment)
- 金丝雀发布(Canari release)
功能开关
功能开关可供我们在软件运行过程中启用/禁用相应的功能。这种技术其实非常容易理解和使用:为生产版本提供一个能彻底禁用某项功能的配置,并只在对应功能彻底完工可以正常工作后才将该属性激活。
举例来说,若要将某个应用程序内的一个功能全局禁用或激活:
if Feature.isEnabled('new_awesome_feature') # Do something new, cool and awesomeelse # Do old, same as always stuffend
或者如果要真对具体用户实现类似目的:
if Feature.isEnabled('new_awesome_feature', current_user) # Do something new, cool and awesomeelse # Do old, same as always stuffend
摸黑启动
摸黑启动的目的在于通过生产环境进行负载模拟!
在测试环境中,通常很难为软件模拟出成百上千万用户规模的负载。
如果不进行切实的负载测试,就无法知道基础架构能否承受住最终面临的压力。
此时并不需要模拟负载,而是可以实际部署这样的功能,然后看看在不影响可用性的前提下到底会发生什么。
Facebook将这种做法称之为功能的“摸黑启动”。
假设我们要将一个有5亿用户使用的静态搜索字段变成一个包含自动补全功能的字段,借此让用户可以更快速获得搜索结果。为该功能构建一个Web服务,并且希望模拟所有用户同时输入文字,向该Web服务生成大量请求的场景。
此时即可通过摸黑启动策略为现有表单添加一个隐藏的后台进程,通过该进程将输入的搜索关键字发送给新增的自动补全服务,并自动发送多次。
就算新增的Web服务彻底崩溃了,也不会造成任何实质损害。网页上可以完全忽略服务器错误。而就算该服务崩溃了,我们至少还可以对该服务进行优化和完善,直到能承受如此大量的负载。
这就等于在现实世界中进行了一次负载测试。
蓝/绿部署
蓝/绿部署是指为下一版产品构建另一个完整的生产环境。开发和运维团队可以在这个单独的生产环境中放心地构建下一版产品。
当下一版产品全部完成后,可以修改负载均衡器的配置,以透明的方式将用户自动重定向至新发布的下一版。
随后可将上一版的生产环境回收,用于构建下下一版的产品。
以此类推。

(来源:Les Patterns des Géants du Web – Zero Downtime Deployment )
这是一种相当有效简单的方法,但问题在于这种方式需要双倍的基础架构以及更多的服务器等。
假设一下Facebook希望将包含成千上万台服务器的环境“照原样再来一套”……
其实还有更好的方法。
金丝雀发布
从本质来看,金丝雀发布与蓝/绿部署非常类似,但无需准备额外的一套生产环境。
这种方式的目标在于以增量的方式将用户切换至新版本:随着越来越多的服务器从当前版本迁移至下一版,相同比例的用户也会被同时迁移。
通过这种方式,每个生产环境都能获得与负载需求相匹配的服务器数量。
首先,只将少量服务器和少部分用户迁移至下一版,借此还可以在无须冒险影响所有用户的前提下对新版进行测试。
当所有服务器最终从当前版迁移至下一版后,发布工作已经完成,又可以从头开始准备下下一版了。

(来源:Les Patterns des Géants du Web – Zero Downtime Deployment )
4. 协作
敏捷软件开发破除了需求分析、测试和开发之间的一些隔阂。部署、运维和维护等其他活动与软件开发过程中的其他环节也存在类似的分隔。DevOps方法意在破除所有这些隔阂,鼓励开发和运维人员之间的协作。
如果没有培养出正确的文化,就算有最棒的工具,DevOps对你而言也不过是另一个热门词汇罢了。
DevOps文化的主要特征在于开发和运维角色之间日益增加的协作。这是一种在团队内部以及组织层面上很重要的文化变迁,通过这样的变迁才能促进更好的协作。
这种方式解决了一个非常重要的问题,而这个问题完全可以用下面这个网络流行话来体现:

(来源:DevOps Memes @ EMCworld 2015 )
团队合作对DevOps是如此的重要,大部分方法论所要实现的最终目标总的来说可以通过两个C来实现:协作(Collaboration)和沟通(Communication)。虽然单纯做到这些距离真正的DevOps工作环境还有很大的差距,但任何公司只要能坚持这两个C,就等于迈出了最正确的第一步。
但为什么会那么难做到?
4.1 混乱之墙
因为有一堵混乱之墙:

在传统开发周期中,开发团队将新发布的软件“隔墙扔给”运维人员,意味着自己的工作已经顺利完成。
运维人员接手开发者的成果,准备开始进行部署。运维人员手工修改由开发者提供的部署脚本,当然更多时候这些脚本都是运维人员自己维护的。
运维人员还需要手工修改配置文件,以反映生产环境的需求,而生产环境往往与开发或QA环境有很大差异。
就算最理想的情况,运维人员可能只是做了一些在上一个环境中已经做过的重复工作,而最糟糕的情况,可能会引入或发现新的Bug。
随后IT运维团队开始讨论他们所认为的,目前最正确的部署流程,然而由于开发和运维在脚本、配置、流程,甚至环境等方面的差异,基本上等同于要从零开始将所有工作重新执行一遍。
当然这一过程中不可避免会遇到问题,他们联系开发者希望进行排错。运维称开发者提供的代码本身有问题,开发者则回应称代码在自己的环境中一切正常,因此错误肯定源自运维端。
由于配置、文件位置,以及面临这种状态所执行的操作与自己的预期等因素存在较大差异,开发者甚至很难对这样的问题进行诊断。变更窗口留下的时间所剩无几,当然也没什么足够靠谱的方法将环境回滚至上一个正常状态。
那么原本应该一帆风顺的部署过程,为什么最后却变成了“众志成城”的应急演习?必须经历大量指责和错误才能最终让生产环境恢复可用状态?
这种情况经常发生,经常!
DevOps来救场了
通过在共同的业务目的情境中让开发和运维角色与流程变的一致,DevOps有助于促进IT的统一。开发和运维都需要明确,自己是统一业务流程的一份子。DevOps思维确保了无论组织结构是怎样的,个体决策与行为需要尽力为统一的业务流程提供支持和促进作用。
亚马逊CTOWerner Vogel甚至在2014年说过:
“谁开发,谁运行。”
4.2 软件开发流程
下图简要描述了敏捷软件开发流程通常的样子。
最开始,业务代表与产品负责人以及架构团队合作定义软件,这一过程可能会使用Story Mapping和用户故事,或者使用更完整的规范。
随后开发团队通过短暂的开发冲刺开发出软件,并在每个冲刺结束后将生产就绪版本的软件发布给业务用户,进而收集反馈并尽可能频繁地调整方向。
最后,经历过每个新的里程碑后,将软件部署给整个业务线更广泛的用户群体。

DevOps造成的最大挑战在于需要理解运维人员是软件的另一个用户群体!因此他们也应该被全面纳入软件开发流程中。
在预定的时间里,运维应该给出自己的非功能需求,就如同业务用户给出自己的功能需求一样。开发团队应该按照同等程度的重要性和优先级处理这种非功能需求。
在实现的过程中,运维应该持续提供反馈和非功能测试规范,就像业务用户针对功能特性提供反馈一样。
最后,运维和业务用户一样,成为了软件的用户。

通过采用DevOps方法,运维可以全面融入软件开发流程中。
4.3 共享工具
在传统的大型企业中,运维团队和开发团队分别使用专用的,没有什么交集的工具集。
运维人员通常并不想了解开发团队所使用的SCM系统以及持续集成环境。他们认为这些并非自己的本职工作,害怕自己在触及这些系统后会被开发者的各种请求所淹没。毕竟他们为了照料生产系统就有忙不完的工作了。
另一方面,开发者通常无法访问生产系统的日志和监视日志,有时这是因为没有这样的意愿,有时则是因为制度或安全方面的顾虑。
这种状况需要改变!DevOps应运而生。

这个目标其实很难实现。举例来说,出于制度或安全方面的原因,日志可能会被实时匿名化,同时需要对监管工具进行必要的保护,以避免未经培训或本应被禁止的开发者更改生产环境的配置。因此实现这一目标需要付出大量时间和成本资源。但这样做所能获得的收益远大于所需进行的投入,这种方法对整个公司的投资回报非常明显。
4.4 协同工作
DevOps的一种基本哲学是认为,开发者和运维人员必须定期进行密切的合作。
这就意味着他们必须将对方视作重要的利益相关者,并积极主动地寻求合作。
受到XP实践中“现场客户”的启发,敏捷开发者受此激励可以与业务进行更紧密的合作,自律的敏捷者还可以更进一步将这样的实践运用给更广泛的利益相关者,例如可以让开发者与所有其他相关者进行合作,包括运维和支持人员。
这是一条双行道:运维和支持人员也必须愿意与开发者进行密切的合作。

此外还可以通过协作:
- 让运维人员参与敏捷仪式(每日Scrum、冲刺规划、再次冲刺等)
- 让开发者参与生产环境的推出任务
- 在开发和运维之间打造统一的持续改进目标
5. 结论
DevOps是一次革命,主要是为了消除拥有大规模IT部门的大型企业中,开发团队和运维团队之间由于历史原因产生的隔阂与孤立所造成的混乱现状。
在我15年的职业生涯中,2/3的时间就职于此类大行机构,其中大部分是金融机构,每天我都在见证者这堵混乱之墙的存在。例如我经常会听到这样的说法:
- “在我的Tomcat上工作很正常,很抱歉,但我完全不懂你所用的Websphere,帮不上你了。”(开发者说)
- “我们真的不能从生产数据库中给你提取这张表,里面包含了与客户有关的机密数据。”(运维人员说)
每天都会遇到其他很多类似的对话……天天如此!
好在DevOps日渐成熟,越来越多传统企业也在开始逐渐走上正途,开始接受DevOps的原则和实践。但还有很多企业无动于衷。
那么对于那些小规模的,开发和运维职能之间通常不会产生那么大分歧的企业呢?
这样的企业应用DevOps原则和实践,例如自动化部署、持续交付和功能开关,一样能获益匪浅。
我认为DevOps原则可以总结为:

DevOps实际上是向着大规模敏捷(Scaling Agility)迈出的另一步!
到底该如何理解DevOps
如何实施DevOps成为众多企业迫切面临的问题,本文作者刘相,有10多年的从业经验,他结合自身企业实施DevOps的经验,梳理出DevOps在企业的组织、技术、流程等方面的最佳实践与价值,以及如何搭建DevOps平台来支撑DevOps的落地工作。
本文内容包括:
1.什么是DevOps及误区
2.DevOps企业实践
3.DevOps架构支撑
4.实施DevOps价值
什么是DevOps及误区
DevOps概念从2009年提出已有8个年头。可是在8年前的那个时候,为什么DevOps没有迅速走红呢?即便是在2006年Amazon发布了ECS,微软在2008年和2010年提出和发布了Azure,DevOps的重要性似乎都没有那么强烈。我分析其原因主要有:
1.第一个很重要的原因是因为那时候云计算还是小众产品,更多的与虚拟化、虚拟机相关,它们还是重量级的IT基础设施。
2.第二个很重要的原因是容器相关技术(Docker为代表)还没有横空出世,直到2013年7月。
3.第三个很重要的原因是,Martin Fowler在2014年3月提出了Micro Service,这为DevOps的推广也打了兴奋剂。
可以看出,当前DevOps概念的深入人心,离不开云计算、容器/Docker、微服务、敏捷等相关概念和实施的成熟发展。
另外,随着互联网对传统企业的冲击,需要更快的业务试错与业务创新,其背后本质是企业IT的精益运营,让软件的生产、交付、获取、升级、遥测变得自动与自助,近两年,DevOps在传统企业也开始备受关注与各种尝试。
对DevOps的理解,可能千人千面。先来看下对DevOps的狭义理解。
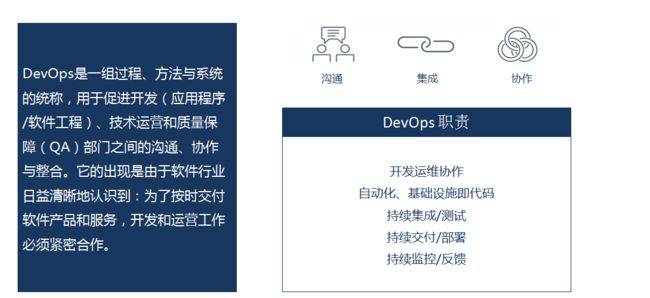
维基百科对DevOps的定义比较拗口。其实往简化里讲DevOps是提倡开发和IT运维之间的高度协同,从而在完成高频率部署的同时,提高生产环境的可靠性、稳定性、弹性和安全性。
从另外一个维度,广义上来说,DevOps不仅需要打通开发运维之间的部门墙,我们认为DevOps更多的需要从应用的全生命周期考虑,实现全生命周期的工具全链路打通与自动化、跨团队的线上协作能力。
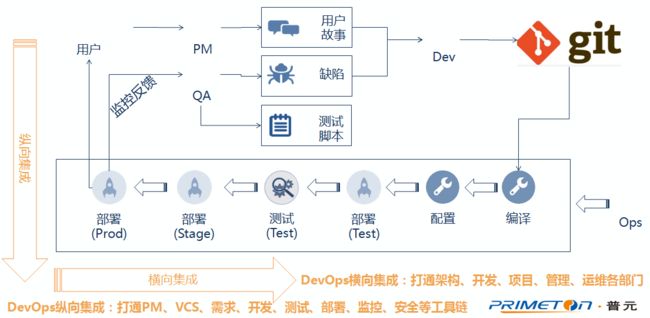
第一,纵向集成,打通应用全生命周期(需求、设计、开发、编译、构建、测试、打包、发布、配置、监控等)的工具集成。纵向集成中DevOps强调的重点是跨工具链的「自动化」,最终实现全部人员的「自助化」。举个例子,项目组的开发人员可以通过DevOps的平台上,自主申请开通需要的各种服务,比如开通开发环境、代码库等。
第二,横向集成,打通架构、开发、管理、运维等部门墙。横向集成中DevOps强调的重点是跨团队的「线上协作」,也即是通过IT系统,实现信息的「精确传递」。举个例子,传统的系统上线部署方式,可能是一个冗长的说明文档,上百页都有可能,但在DevOps的平台下,就应该是通过标准运行环境的选择、环境配置的设置、部署流程的编排,实现数字化的「部署手册」,并且这样的手册,不仅操作人员可以理解,机器也能够执行,过程可以被追踪和审计。
DevOps是通过工具链与持续集成、交付、反馈与优化进行端到端整合,完成无缝的跨团队、跨系统协作。
在团队使用DevOps时,存在误区是必然的。在我们同大量的客户交流中,大致有这几种误区认知:

? 没有使用云相关产品(IaaS、PaaS),组织很难开展DevOps;
? 微服务架构开发的应用适合DevOps,传统SOA应用不适合;实施DevOps和应用架构无关,无论是微服务架构,还是SOA类型应用,都可以开展DevOps工作;
? 认为将一组自动化工具的运用等同于DevOps的成功,那就太小瞧DevOps了。采用自动化工具本身不是DevOps,只有将这些工具与持续集成、持续交付、持续的反馈与优化进行端到端的整合时,这些工具才成为DevOps的一部分;
? 设立独立的DevOps团队是很多组织开启DevOps之旅的另外一个误区。事实上,如果这么做,将会导致更多的竖井。在责任没有清晰定义的情况下,成立这些团队,会创造更多的混乱,不要试图把。
? DevOps不仅仅是自动化。毫无疑问,自动化是DevOps非常重要的一部分,但不是唯一的部分,一定程度的部署自动化往往会与DevOps混为一谈,实施DevOps需要从敏捷、持续、协作、系统性、自动化五个维度进行建设与改进。
在DevOps实施过程中,团队经过总结积累,制定了团队的DevOps宣言,支撑团队从敏捷型组织转向DevOps(企业敏捷)。

DevOps企业实践
实施DevOps的核心目标是加速团队、企业的IT精益运行,从根本上提升IT的生产效率,加速部门、企业的业务创新能力。让团队从IT支撑部门,转向为IT创新部门。
实施DevOps过程中,需要从组织、技术、流程三个维度进行持续的优化与改进。
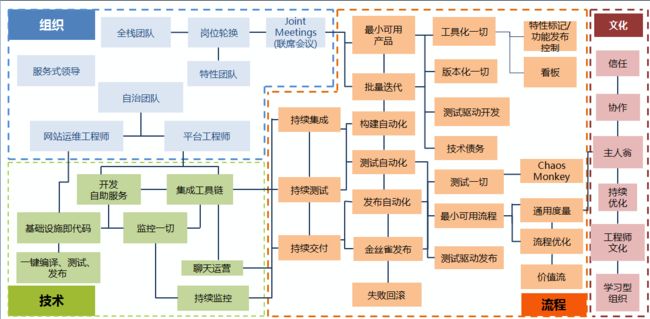
实施DevOps,可以参考总结的“DevOps实践模型”,从组织、技术、流程三个维度中选择关键的活动项进行最佳实践活动。
可以梳理出目前团队中欠缺但又容易改进的点,逐步将更多的实践活动纳入团队当中。团队实施DevOps的目的在于,将重复、价值低的事情交由DevOps平台实现,让团队成员做更有创新、更有价值的事情。
根据我们的实施经验,在传统企业中,技术方面的实践最容易在团队中实现、流程次之、组织的优化与变革最为艰难;大家尝试的时候,可以由易入难。
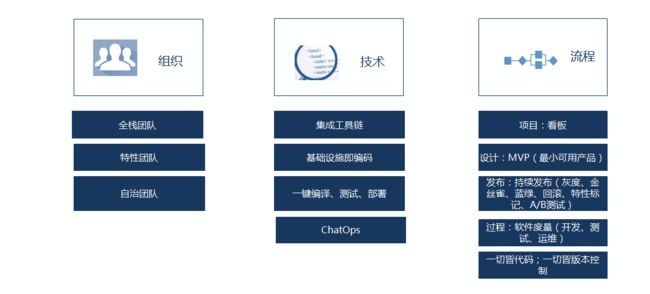
组织方面
如何实施DevOps成为众多企业迫切面临的问题,本文作者刘相,有10多年的从业经验,他结合自身企业实施DevOps的经验,梳理出DevOps在企业的组织、技术、流程等方面的最佳实践与价值,以及如何搭建DevOps平台来支撑DevOps的落地工作。
技术方面
集成工具链:打通应用应用开发工具链:需求、项目、代码、构建、测试、打包、发布、配置、监控;
基础设施即编码:将基础环境服务化、可编程化,基础设施让项目团队可以自助获取;让基础设施从物理机、虚拟机、走向容器;
一键编译、测试、部署:开发人员可以从代码开始,一键获得可访问的环境,根据需要可以推送开发、测试、预发、生产环境;
ChatOps:开发以及运营人员在内的团队成员将沟通、工具和过程整合在一起的协作模型。基于对话驱动开发,将工具植入对话中,保障团队能够自动执行任务与协作。最近比较流行的hubot可以认为是ChatOps的探路者。
流程方面
看板:在DevOps中不能仅仅把看板当做任务协调沟通的机制;把看板作为在制品管制平台,量化组织生产能力的工具;
MVP:采用MVP(最小可行产品)原则,快速拥抱变化。最短时间内快速交付产品原型,然后通过测试并收集用户的反馈,快速迭代,不断修正产品,最终适应市场的需求。
发布:建立持续发布机制,形成自动化、自助化两种能力,支持常见的灰度发布、金丝雀、蓝绿、回滚、A/B测试等;
软件度量:通过软件度量(包括过程度量、质量度量、用户度量、成本度量),推算出组织的各种有效指标;一则掌控组织的生产力水平,二则通过度量数据,反向优化组织瓶颈点;
一切皆代码:文档(用户故事、用户场景、功能特性等)、配置(应用配置、环境配置、脚本等)、环境(基础设施、中间件环境等)、发布包(二方库、三方库、部署包)需要统一看待成代码,纳入版本管理,同时建立5者间的关系,提供全视角的链路追踪。举个例子,每个发布的版本,可以追溯其对应的配置,代码、文档,发布的功能点。
组织、技术、流程三个维度中,技术、流程可以通过平台或者工具进行最佳实践的固化。
基于此,我们规划了DevOps平台,支持广义的DevOps,帮助客户快速实现DevOps建设。
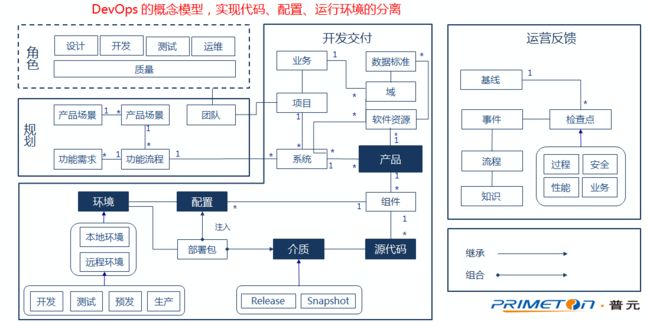
平台建设第一步,梳理出DevOps的整体概念模型。从角色、规划设计、开发交付、运营反馈四个维度进行梳理。
以产品为核心,将代码、配置、环境进行严格分离,同时覆盖产品全生命周期。
这里面概念看似简单,其实很多:比如:部署包=介质包+配置,这和传统的CI和CD体系就有点不一样;
再比如:环境分开发、测试、预发、生产,我们觉得即使公有云上,也应该给客户将这些做物理或逻辑隔离,因为大家的配额需求不一样,容器replication需求也可能不一样;
再比如:运营反馈,既然要做DevOps,那整个过程导出都应该可以有检查点插入,为运营提供有效数据,我们把检查点至少分成了四类,包括过程的、安全的、性能的、业务的。
DevOps架构支撑
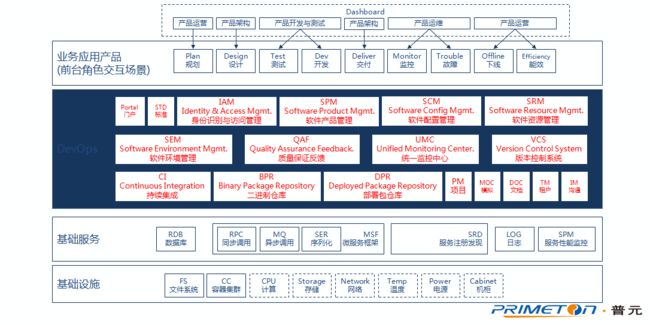
基于领域模型梳理DevOps平台业务架构,目前共建设18个领域系统来支撑,比如:软件产品的管理、软件各阶段环境的管理、质量的管理、部署包、二进制包的管理、资源管理、监控中心、认证中心等。
每个领域系统严格按照AKF扩展立方体的Y轴进行拆分,采用微服务架构模式进行平台建设。
“DevOps业务架构”,是我们基于对企业IT管理的理解,所进行的平台化设想。从图里还可以看到,红色字部分,是我们对现有DevOps的落地实现。
? Portal(DevOps门户),自研,提供给用户使用的统一操作门户,包括用户管理、产品看板、产品全生命周期(设计、开发、测试、预发、生产、监控、故障处理)管理等;
? IAM(身份识别与访问管理),自研,提供用户身份识别和访问控制的能力,包括用户管理、Token管理和用户授权等功能;
? SPM(软件产品管理),自研,提供产品、组件的基准定义和管理能力,包括产品类型、产品管理、组件管理、依赖产品管理及产品投放市场等功能;
? SCM(软件配置管理),自研,提供产品、组件配置管理能力,包括配置项的定义和在各个不同环境下的配置信息的管理维护能力;
? SRM(软件资源管理),自研,提供产品和组件自动编译、打包和部署的能力,提供部署模板管理,支持编译和部署流程编排,编译和部署进度跟踪以及日志查看;
? SEM(软件环境管理),自研,提供租户和产品环境资源配额、负载均衡,以及运行容器的管理能力,包括租户可用资源的配额,以及基于租户资源的产品和组件在各种环境下的资源配额(如开发环境、测试环境、生产环境等等)和负载均衡;同时,还提供运行容器的创建、销毁、调度、复制以及持久化卷管理等能力;
? QAF(质量保证反馈),自研,提供产品的质量管理和监控能力,包括测试用例管理、缺陷管理、质量监控等;
? UMC(统一运维中心),开源集成、借鉴自研相结合,提供统一的监控、预警、故障处理等能力,包括系统日志和业务日志的监控,产品的资源使用情况和运行情况监控,故障定位等。
? VCS(版本控制系统),开源集成 ,主要以GitLab为核心,不直接提供GitLab的原生界面,所有功能在统一的DevOps上提供;提供源代码库管理的能力,包括代码库的创建、维护,分支的管理和用户权限控制等;
? CI(持续集成),主要以Jenkins为核心,使之成为以API为主要使用方式的服务,提供持续集成任务调度和执行的能力,包括集成任务管理、编译、打包等;
? BPR(二进制介质仓库),开源集成,主要以nexus为核心;提供二进制包仓库的管理能力,包括二进制包、文档等编译产物的上传、下载和存储访问等;
? DPR(可部署介质仓库),自研,主要存储可部署的介质,其主要区别是注入了与环境相关的配置(这种部署模型是很适合没有上Docker或者容器,以虚机为主的IT基础设施或者物理机);
? PM(项目管理),自研,可以与常见的PM管理工具对接与集成,提供产品的开发过程的管理和协作的能力,主要包括:任务计划、人员分工和过程跟踪、看板等;
? MOC(API模拟),开源集成,为REST API调用提供模拟能力,以便产品或组件在开发调试期间可以脱离依赖、减少阻塞、单独运行,支持根据Swagger和Mock数据发布Mock Rest Service,支持用户私有的MOCK数据;
? DOC(API文档),开源集成,提供REST API/SPI文档的自动生成能力;
? TM(租户管理),自研,提供租户管理的能力,包括租户管理、邀请码管理和租户配额等功能;
? IM(即时沟通),开源集成,提供产品设计、开发、测试、运维等相关人员间的协作沟通能力,支持群组聊天、离线消息推送、聊天记录查询和导出;
啰啰嗦嗦,罗列了18个核心的领域系统。
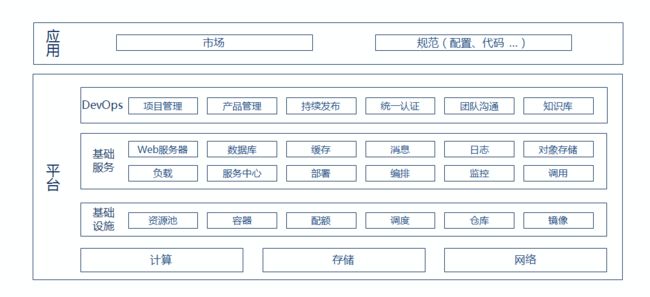
逻辑架构整个DevOps平台分为三层:
? 基础设施层:包括IaaS,CaaS,我们分别是基于OpenStack和Kubernetes、Docker的,上层有一层不同环境的适配;
? 基础服务层:包括服务管理与调度的基础能力,如注册中心,编排,伸缩漂移;还有一堆具体的企业级或互联网式的云服务;
? DevOps层:更多的是工作流程(需求、设计、开发、测试、发布等)的串接,看板等文化的体现;
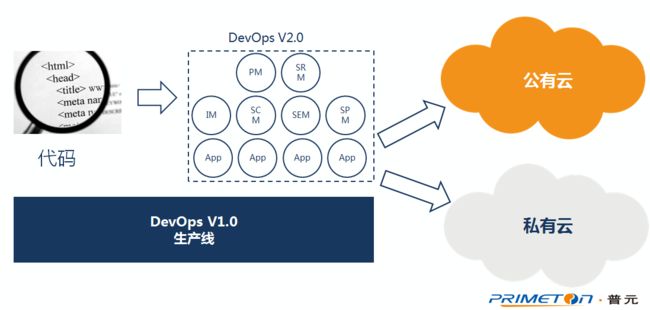
在整个平台研发过程中,采用了是自己开发自己的模式,即使用上一个发布的平台作为生产线,支撑下一个版本的产品研发工作。自己交付自己可以带来两点好处:
1. 平台交付客户前,自己先把可能的坑趟掉;
2. 当前生产线所有不能满足的功能,视作下一版本的需求(实际操作过程中,我们仅允许使用wiki作为辅助工具来支撑生产线未满足的需求);
所以可以拿一些数字估算一下当前的规模。在研发过程中,把DevOps视为一套业务平台,目前规划的领域有18个,如果每个领域中再有多个以微服务架构落地的系统进行支撑,预计总共支撑DevOps的系统,就会超过50个。同时提供Mock、开发、测试、预发、生产5类环境(每类环境中可能还会有多套,比如集成测试、性能测试、全链路测试)。
当前版本的DevOps,整体的部署规模将超过200个集群,部署的进程实例总数也会轻松超过500个。需要注意的是,500这个数字,还没包含技术平台中的一些分布式中间件,比如缓存、消息队列等等集群。
不过,500映射到企业内IT人员自己用的平台,这个数字,对于不同的企业,可能是个天文数字,也可能只是九牛一毛。
实施DevOps价值
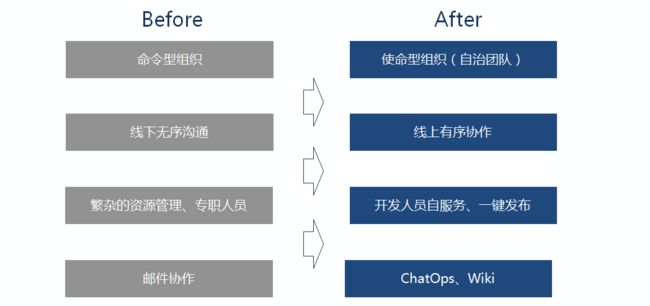
在部门实施DevOps之后,我们团队有显著改变:
? 在团队组织上,每个团队小而自治且是全栈团队,沟通、技能互补,每个团队负责独立的领域系统,目标感非常明确,团队在走向使命型组织;
? 项目的从原先线下协作、沟通,统一到统一的DevOps平台上协作、沟通;团队成员可以随时了解项目进展全貌,利用平台可以做到各种过程数据的实时收集(举例,比如需求变更、任务延期等);
? 资源管理由原来专职人员,过渡到开发人员实现自助化服务,可以按需实现各类环境申请与开通,基础设施即服务提供来技术的支撑;
? 从原来的邮件文化,到DevOps平台统一沟通,同时DevOps打通多个工具链路端,任务分发、沟通、提醒可以实时推送;
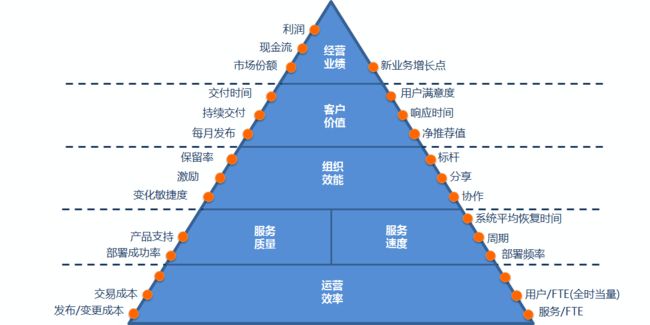
最后给大家奉上DevOps成熟度评判指标,在践行DevOps时,可以从运营效率、IT服务水平、组织效能、客户价值、经营业绩五个维度进行评判,持续优化与改进。
持续集成,持续交付,持续部署(CI/CD)简介
概述:
软件开发周期中需要一些可以帮助开发者提升速度的自动化工具。其中工具最重要的目的是促进软件项目的持续集成与交付。通过CI/CD工具,开发团队可以保持软件更新并将其迅速的投入实践中。CI/CD也被认为是敏捷开发的最重要实践之一。
一 、持续集成
从上图可以看到,持续集成应该至少包括以下几部分:
自动化构建Continuous Build
自动化测试Continuous Test
自动化集成Continuous Intergration
1.自动化构建
包括以下过程:
将源码编译成为二进制码
打包二进制码
运行自动化测试
生成文档
生成分发媒体(例如:Debian DEB、Red Hat RPM或者Windows MSI文件)
所以,自动化构建,从功能角度分,最关键的是三部分:版本控制工具、构建工具、CI服务器。而其中最核心的又是构建工具。其他开源的、与持续集成相关的工具也有很多,但大多数是辅助性的工具。
(1)版本控制工具
有时,版本控制又称为配置管理(SCM),所以版本控制工具同时也是配置管理工具。在各类版本控制的开源软件中,最著名的莫过于CVS、SVN(Subversion)、GIT三个了。
这三个工具各有千秋。其中,GIT支持离线工作,更适合开源软件或者开发人员不能集中办公情况下的版本管理工作。同时,SVN和GIT可以配合使用。
(2)构建工具
构建工具是持续集成的核心,它对源代码进行自动化编译、测试、代码检查,以及打包程序、部署(发布)到应用服务器上。从配置管理工具上下载最新源代码后,所有的后续工作几乎都可以通过构建工具完成。
在java开发中,比较有名的构建工具就是Ant、Maven、Gradle。在PHP开发中,Phing(基于Ant)也比较有名。同样的,Maven也可通过相关的PHP-Maven插件完成对PHP开发构建的支持。
(3)CI服务器
CI服务器的主要作用就是提供一个平台,用于整合版本控制和构建工作,并管理、控制自动化的持续集成。
开源软件中,比较有名的CI服务器包括Jenkins、CruiseControl、Continuum。而比较有名的商业化CI服务器是TeamCity、Bamboo、Pulse等。
(4)其他工具
很多工具可以通过与构建工具、CI工具相结合(当然,其中有很多工具也可以单独工作),来完成更多的自动测试、报告生成等工作。根据工具不同,其具体的结合方法也不同,但大体都是通过插件形式进行结合的。例如:
Maven中通过依赖和plugin方式引入第三方工具
Jenkins主要通过各类插件引入第三方工具
这些工具种类实在太多,可以根据实际工作需要进行选择。
2.自动化测试
自动化测试是持续集成必不可少的一部分,基本上,没有自动化测试的持续集成,都很难称之为真正的持续集成。我们希望持续集成能够尽早的暴露问题,但这远非配置一个 Hudson/Jenkins服务器那么简单,只有真正用心编写了较为完整的测试用例,并一直维护它们,持续集成才能孜孜不倦地运行测试并第一时间报告问题。
测试自动化是使用特定的软件(独立于被测试的软件)来控制测试的执行以及比较实际输出与预期输出。测试自动化可以将某些重复但必要的任务自动化,或者执行某些难以手动执行的额外测试。
自动化测试还包括单元测试、集成测试、系统测试、验收测试、性能测试等,在不同的场景下,它们都能为软件开发带来极大的价值。
二、持续交付
持续交付(Continuous Delivery, CD)是一种软件工程的手段,让软件在短周期内产出,确保软件随时可以被可靠地发布。其目的在于更快、更频繁地构建、测试以及发布软件。通过加强对生产环境的应用进行渐进式更新,这种手段可以降低交付变更的成本与风险。一个简单直观的与可重复的部署过程对于持续交付来说是很重要的。
三、持续部署
如图所示,持续部署与持续交付之间的差异就是前者将部署自动化了。
在持续交付的实践中,交付的目标是QA,但是实际上,软件最终是要交付到客户手上的。在SaaS领域里,持续部署采用得比较广泛,因为服务比较容易做到静默升级。
采用持续部署的前提是自动化测试的覆盖率足够高。
采用持续部署的好处是能减少运维的工作量,缩短新特性从开发到实际交付的周期。
四、CI/CD具体实现
常见CI/CD工具及其比较:
这里的支持,意思应该是直接的支持,例如Jenkins,其实和git结合也很简单,通过脚本就可以实现。
五、持续集成工具集之 Jenkins简介
Jenkins 是一个可扩展的持续集成引擎。
1.主要用于:
持续、自动地构建/测试软件项目。
监控一些定时执行的任务。Jenkins拥有的特性包括:
2.Jenkins拥有的特性包括:
易于安装-只要把jenkins.war部署到servlet容器,不需要数据库支持。
易于配置-所有配置都是通过其提供的web界面实现。
集成RSS/E-mail通过RSS发布构建结果或当构建完成时通过e-mail通知。
生成JUnit/TestNG测试报告
分布式构建支持Jenkins能够让多台计算机一起构建/测试。
文件识别:Jenkins能够跟踪哪次构建生成哪些jar,哪次构建使用哪个版本的jar等。
插件支持:支持扩展插件,你可以开发适合自己团队使用的工具。
3.Jenkins的出现
目前持续集成(CI)已成为当前许多软件开发团队在整个软件开发生命周期内侧重于保证代码质量的常见做法。它是一种实践,旨在缓和和稳固软件的构建过程。并且能够帮助您的开发团队应对如下挑战:
软件构建自动化 :配置完成后,CI系统会依照预先制定的时间表,或者针对某特定事件,对目标软件进行构建。
构建可持续的自动化检查 :CI系统能持续地获取新增或修改后签入的源代码,也就是说,当软件开发团队需要周期性的检查新增或修改后的代码时,CI系统会不断确认这些新代码是否破坏了原有软件的成功构建。这减少了开发者们在检查彼此相互依存的代码中变化情况需要花费的时间和精力。
构建可持续的自动化测试 :构建检查的扩展部分,构建后执行预先制定的一套测试规则,完成后触发通知(Email,RSS等等)给相关的当事人。
生成后后续过程的自动化 :当自动化检查和测试成功完成,软件构建的周期中可能也需要一些额外的任务,诸如生成文档、打包软件、部署构件到一个运行环境或者软件仓库。这样,构件才能更迅速地提供给用户使用。
部署一个CI系统需要的最低要求是,一个可获取的源代码的仓库,一个包含构建脚本的项目。
下图概括了CI系统的基本结构:
4.使用Jenkins的一些理由:
该系统的各个组成部分是按如下顺序来发挥作用的:
开发者检入代码到源代码仓库。
CI系统会为每一个项目创建了一个单独的工作区。当预设或请求一次新的构建时,它将把源代码仓库的源码存放到对应的工作区。
CI系统会在对应的工作区内执行构建过程。
(配置如果存在)构建完成后,CI系统会在一个新的构件中执行定义的一套测试。完成后触发通知(Email,RSS等等)给相关的当事人。
(配置如果存在)如果构建成功,这个构件会被打包并转移到一个部署目标(如应用服务器)或存储为软件仓库中的一个新版本。软件仓库可以是CI系统的一部分,也可以是一个外部的仓库,诸如一个文件服务器或者像Java.NET、 SourceForge之类的网站。
CI系统通常会根据请求发起相应的操作,诸如即时构建、生成报告,或者检索一些构建好的构件。
Jenkins就是这么一个CI系统。之前叫做Hudson。
是所有CI产品中在安装和配置上最简单
基于Web访问,用户界面非常友好、直观和灵活,在许多情况下,还提供了AJAX的即时反馈。
Jenkins是基于Java开发的(如果你是一个Java开发人员,这是非常有用的),但它不仅限于构建基于Java的软件。
Jenkins拥有大量的插件。这些插件极大的扩展了Jenkins的功能;它们都是开源的,而且它们可以直接通过web界面来进行安装与管理。
5.Jenkins的目标
Jenkins的主要目标是监控软件开发流程,快速显示问题。所以能保证开发人员以及相关人员省时省力提高开发效率。
CI系统在整个开发过程中的主要作用是控制:当系统在代码存储库中探测到修改时,它将运行构建的任务委托给构建过程本身。如果构建失败了,那么CI系统将通知相关人员,然后继续监视存储库。它的角色看起来是被动的;但它确能快速反映问题。
特别是它具有以下优点:
Jenkins一切配置都可以在web界面上完成。有些配置如MAVEN_HOME和Email,只需要配置一次,所有的项目就都能用。当然也可以通过修改XML进行配置。
支持Maven的模块(Module),Jenkins对Maven做了优化,因此它能自动识别Module,每个Module可以配置成一个job。相当灵活。
测试报告聚合,所有模块的测试报告都被聚合在一起,结果一目了然,使用其他CI,这几乎是件不可能完成的任务。
构件指纹(artifact fingerprint),每次build的结果构件都被很好的自动管理,无需任何配置就可以方便的浏览下载。
在有关微服务、DevOps、Cloud-native、系统部署等的讨论中,蓝绿部署、AB 测试、灰度发布、滚动发布、红黑部署等概念经常被提到,它们有什么区别呢?
在有关微服务、DevOps、Cloud-native、系统部署等的讨论中,蓝绿部署、A/B 测试、灰度发布、滚动发布、红黑部署等概念经常被提到,它们有什么区别呢?通过搜索相关资料,做一个简单的辨析,如下:
一、蓝绿部署(Blue/Green Deployment)
过去的 10 年里,很多公司都在使用蓝绿部署(发布)来实现热部署,这种部署方式具有安全、可靠的特点。蓝绿部署虽然算不上“ Sliver Bullet”,但确实很实用。
蓝绿部署是最常见的一种0 downtime部署的方式,是一种以可预测的方式发布应用的技术,目的是减少发布过程中服务停止的时间。蓝绿部署原理上很简单,就是通过冗余来解决问题。通常生产环境需要两组配置(蓝绿配置),一组是active的生产环境的配置(绿配置),一组是inactive的配置(蓝绿配置)。用户访问的时候,只会让用户访问active的服务器集群。在绿色环境(active)运行当前生产环境中的应用,也就是旧版本应用version1。当你想要升级到version2 ,在蓝色环境(inactive)中进行操作,即部署新版本应用,并进行测试。如果测试没问题,就可以把负载均衡器/反向代理/路由指向蓝色环境了。随后需要监测新版本应用,也就是version2 是否有故障和异常。如果运行良好,就可以删除version1 使用的资源。如果运行出现了问题,可以通过负载均衡器指向快速回滚到绿色环境。
蓝绿部署的优点:
这种方式的好处在你可以始终很放心的去部署inactive环境,如果出错并不影响生产环境的服务,如果切换后出现问题,也可以在非常短的时间内把再做一次切换,就完成了回滚。而且同时在线的只有一个版本。蓝绿部署无需停机,并且风险较小。
(1) 部署版本1的应用(一开始的状态),所有外部请求的流量都打到这个版本上。
(2) 部署版本2的应用,版本2的代码与版本1不同(新功能、Bug修复等)。
(3) 将流量从版本1切换到版本2。
(4) 如版本2测试正常,就删除版本1正在使用的资源(例如实例),从此正式用版本2。
从过程不难发现,在部署的过程中,应用始终在线。并且,新版本上线的过程中,并没有修改老版本的任何内容,在部署期间,老版本的状态不受影响。这样风险很小,并且,只要老版本的资源不被删除,理论上,可以在任何时间回滚到老版本。
蓝绿部署的弱点:
使用蓝绿部署需要注意的一些细节包括:
1、当切换到蓝色环境时,需要妥当处理未完成的业务和新的业务。如果数据库后端无法处理,会是一个比较麻烦的问题。
2、有可能会出现需要同时处理“微服务架构应用”和“传统架构应用”的情况,如果在蓝绿部署中协调不好这两者,还是有可能导致服务停止;
3、需要提前考虑数据库与应用部署同步迁移/回滚的问题。
4、蓝绿部署需要有基础设施支持。
5、在非隔离基础架构( VM 、 Docker 等)上执行蓝绿部署,蓝色环境和绿色环境有被摧毁的风险。
6、另外,这种方式不好的地方还在于冗余产生的额外维护、配置的成本,以及服务器本身运行的开销。
蓝绿部署适用的场景:
1、不停止老版本,额外搞一套新版本,等测试发现新版本OK后,删除老版本。
2、蓝绿发布是一种用于升级与更新的发布策略,部署的最小维度是容器,而发布的最小维度是应用。
3、蓝绿发布对于增量升级有比较好的支持,但是对于涉及数据表结构变更等等不可逆转的升级,并不完全合适用蓝绿发布来实现,需要结合一些业务的逻辑以及数据迁移与回滚的策略才可以完全满足需求。
A/B 测试(A/B Testing)
A/B 测试跟蓝绿部署完全是两码事。A/B 测试是用来测试应用功能表现的方法,例如可用性、受欢迎程度、可见性等等。 蓝绿部署的目的是安全稳定地发布新版本应用,并在必要时回滚。
A/B 测试与蓝绿部署的区别在于, A/B 测试目的在于通过科学的实验设计、采样样本代表性、流量分割与小流量测试等方式来获得具有代表性的实验结论,并确信该结论在推广到全部流量可信。
A/B 测试和蓝绿部署可以同时使用。
灰度发布/金丝雀发布
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式。灰度发布是增量发布的一种类型,灰度发布是在原有版本可用的情况下,同时部署一个新版本应用作为“金丝雀”(金丝雀对瓦斯极敏感,矿井工人携带金丝雀,以便及时发发现危险),测试新版本的性能和表现,以保障整体系统稳定的情况下,尽早发现、调整问题。
灰度发布/金丝雀发布由以下几个步骤组成:
1、准备好部署各个阶段的工件,包括:构建工件,测试脚本,配置文件和部署清单文件。
2、从负载均衡列表中移除掉“金丝雀”服务器。
3、升级“金丝雀”应用(排掉原有流量并进行部署)。
4、对应用进行自动化测试。
5、将“金丝雀”服务器重新添加到负载均衡列表中(连通性和健康检查)。
6、如果“金丝雀”在线使用测试成功,升级剩余的其他服务器。(否则就回滚)
灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
灰度发布/金丝雀部署适用的场景:
1、不停止老版本,额外搞一套新版本,不同版本应用共存。
2、灰度发布中,常常按照用户设置路由权重,例如90%的用户维持使用老版本,10%的用户尝鲜新版本。
3、经常与A/B测试一起使用,用于测试选择多种方案。AB test就是一种灰度发布方式,让一部分用户继续用A,一部分用户开始用B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。
趣闻 :
金丝雀部署(同理还有金丝雀测试),“金丝雀”的由来:17世纪,英国矿井工人发现,金丝雀对瓦斯这种气体十分敏感。空气中哪怕有极其微量的瓦斯,金丝雀也会停止歌唱;而当瓦斯含量超过一定限度时,虽然鲁钝的人类毫无察觉,金丝雀却早已毒发身亡。当时在采矿设备相对简陋的条件下,工人们每次下井都会带上一只金丝雀作为“瓦斯检测指标”,以便在危险状况下紧急撤离。
滚动发布(rolling update)
滚动发布,一般是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本。这种部署方式相对于蓝绿部署,更加节约资源——它不需要运行两个集群、两倍的实例数。我们可以部分部署,例如每次只取出集群的20%进行升级。
这种方式也有很多缺点,例如:
(1) 没有一个确定OK的环境。使用蓝绿部署,我们能够清晰地知道老版本是OK的,而使用滚动发布,我们无法确定。
(2) 修改了现有的环境。
(3) 如果需要回滚,很困难。举个例子,在某一次发布中,我们需要更新100个实例,每次更新10个实例,每次部署需要5分钟。当滚动发布到第80个实例时,发现了问题,需要回滚。此时,脾气不好的程序猿很可能想掀桌子,因为回滚是一个痛苦,并且漫长的过程。
(4) 有的时候,我们还可能对系统进行动态伸缩,如果部署期间,系统自动扩容/缩容了,我们还需判断到底哪个节点使用的是哪个代码。尽管有一些自动化的运维工具,但是依然令人心惊胆战。
并不是说滚动发布不好,滚动发布也有它非常合适的场景。
红黑部署(Red-Black Deployment)
这是Netflix采用的部署手段,Netflix的主要基础设施是在AWS上,所以它利用AWS的特性,在部署新的版本时,通过AutoScaling Group用包含新版本应用的AMI的LaunchConfiguration创建新的服务器。测试不通过,找到问题原因后,直接干掉新生成的服务器以及Autoscaling Group就可以,测试通过,则将ELB指向新的服务器集群,然后销毁掉旧的服务器集群以及AutoScaling Group。
红黑部署的好处是服务始终在线,同时采用不可变部署的方式,也不像蓝绿部署一样得保持冗余的服务始终在线。
微服务架构
目录如下:
一、微服务架构介绍
二、出现和发展
三、传统开发模式和微服务的区别
四、微服务的具体特征
五、SOA和微服务的区别
六、如何具体实践微服务
七、常见的微服务设计模式和应用
八、微服务的优点和缺点
九、思考:意识的转变
十、参考资料和推荐阅读
一、微服务架构介绍
微服务架构(Microservice Architecture)是一种架构概念,旨在通过将功能分解到各个离散的服务中以实现对解决方案的解耦。你可以将其看作是在架构层次而非获取服务的
类上应用很多SOLID原则。微服务架构是个很有趣的概念,它的主要作用是将功能分解到离散的各个服务当中,从而降低系统的耦合性,并提供更加灵活的服务支持。
概念:把一个大型的单个应用程序和服务拆分为数个甚至数十个的支持微服务,它可扩展单个组件而不是整个的应用程序堆栈,从而满足服务等级协议。
定义:围绕业务领域组件来创建应用,这些应用可独立地进行开发、管理和迭代。在分散的组件中使用云架构和平台式部署、管理和服务功能,使产品交付变得更加简单。
本质:用一些功能比较明确、业务比较精练的服务去解决更大、更实际的问题。
二、出现和发展
微服务(Microservice)这个概念是2012年出现的,作为加快Web和移动应用程序开发进程的一种方法,2014年开始受到各方的关注,而2015年,可以说是微服务的元年;
越来越多的论坛、社区、blog以及互联网行业巨头开始对微服务进行讨论、实践,可以说这样更近一步推动了微服务的发展和创新。而微服务的流行,Martin Fowler功不可没。
这老头是个奇人,特别擅长抽象归纳和制造概念。特别是微服务这种新生的名词,都有一个特点:一解释就懂,一问就不知,一讨论就打架。
Martin Fowler是国际著名的OO专家,敏捷开发方法的创始人之一,现为ThoughtWorks公司的首
席科学家。在面向对象分析设计、UML、模式、软件开发方法学、XP、重构等方面,都是世界顶级的
专家,现为Thought Works公司的首席科学家。Thought Works是一家从事企业应用开发和——集
成的公司。早在20世纪80年代,Fowler就是使用对象技术构建多层企业应用的倡导者,他著有几
本经典书籍: 《企业应用架构模式》、《UML精粹》和《重构》等。
———— 百度百科
三、传统开发模式和微服务的区别
先来看看传统的web开发方式,通过对比比较容易理解什么是Microservice Architecture。和Microservice相对应的,这种方式一般被称为Monolithic(单体式开发)。
所有的功能打包在一个 WAR包里,基本没有外部依赖(除了容器),部署在一个JEE容器(Tomcat,JBoss,WebLogic)里,包含了 DO/DAO,Service,UI等所有逻辑。

优点:
①开发简单,集中式管理
②基本不会重复开发
③功能都在本地,没有分布式的管理和调用消耗
缺点:
1、效率低:开发都在同一个项目改代码,相互等待,冲突不断
2、维护难:代码功功能耦合在一起,新人不知道何从下手
3、不灵活:构建时间长,任何小修改都要重构整个项目,耗时
4、稳定性差:一个微小的问题,都可能导致整个应用挂掉
5、扩展性不够:无法满足高并发下的业务需求
常见的系统架构遵循的三个标准和业务驱动力:
1、提高敏捷性:及时响应业务需求,促进企业发展
2、提升用户体验:提升用户体验,减少用户流失
3、降低成本:降低增加产品、客户或业务方案的成本
基于微服务架构的设计:
目的:有效的拆分应用,实现敏捷开发和部署

关于微服务的一个形象表达:

X轴:运行多个负载均衡器之后的运行实例
Y轴:将应用进一步分解为微服务(分库)
Z轴:大数据量时,将服务分区(分表)
四、微服务的具体特征
官方的定义:
1、一些列的独立的服务共同组成系统
2、单独部署,跑在自己的进程中
3、每个服务为独立的业务开发
4、分布式管理
5、非常强调隔离性
大概的标准:
1、分布式服务组成的系统
2、按照业务,而不是技术来划分组织
3、做有生命的产品而不是项目
4、强服务个体和弱通信( Smart endpoints and dumb pipes )
5、自动化运维( DevOps )
6、高度容错性
7、快速演化和迭代
五、SOA和微服务的区别
1、SOA喜欢重用,微服务喜欢重写
SOA的主要目的是为了企业各个系统更加容易地融合在一起。 说到SOA不得不说ESB(EnterpriseService Bus)。 ESB是什么? 可以把ESB想象成一个连接所有企业级服务的脚手架。
通过service broker,它可以把不同数据格式或模型转成canonical格式,把XML的输入转成CSV传给legacy服务,把SOAP 1.1服务转成 SOAP 1.2等等。 它还可以把一个服务
路由到另一个服务上,也可以集中化管理业务逻辑,规则和验证等等。 它还有一个重要功能是消息队列和事件驱动的消息传递,比如把JMS服务转化成SOAP协议。 各服务间可能有
复杂的依赖关系。
微服务通常由重写一个模块开始。要把整个巨石型的应用重写是有很大的风险的,也不一定必要。我们向微服务迁移的时候通常从耦合度最低的模块或对扩展性要求最高的模块开始,
把它们一个一个剥离出来用敏捷地重写,可以尝试最新的技术和语言和框架,然 后单独布署。 它通常不依赖其他服务。微服务中常用的API Gateway的模式主要目的也不是重用代码,
而是减少客户端和服务间的往来。API gateway模式不等同与Facade模式,我们可以使用如future之类的调用,甚至返回不完整数据。
2、SOA喜欢水平服务,微服务喜欢垂直服务
SOA设计喜欢给服务分层(如Service Layers模式)。 我们常常见到一个Entity服务层的设计,美其名曰Data Access Layer。 这种设计要求所有的服务都通过这个Entity服务层
来获取数据。 这种设计非常不灵活,比如每次数据层的改动都可能影响到所有业务层的服务。 而每个微服务通常有它自己独立的data store。 我们在拆分数据库时可以适当的做些
去范式化(denormalization),让它不需要依赖其他服务的数据。
微服务通常是直接面对用户的,每个微服务通常直接为用户提供某个功能。 类似的功能可能针对手机有一个服务,针对机顶盒是另外一个服务。 在SOA设计模式中这种情况通常会用到
Multi-ChannelEndpoint的模式返回一个大而全的结果兼顾到所有的客户端的需求。
3、SOA喜欢自上而下,微服务喜欢自下而上
SOA架构在设计开始时会先定义好服务合同(service contract)。 它喜欢集中管理所有的服务,包括集中管理业务逻辑,数据,流程,schema,等等。 它使用Enterprise
Inventory和Service Composition等方法来集中管理服务。 SOA架构通常会预先把每个模块服务接口都定义好。 模块系统间的通讯必须遵守这些接口,各服务是针对他们的调用者。
SOA架构适用于TOGAF之类的架构方法论。
微服务则敏捷得多。只要用户用得到,就先把这个服务挖出来。然后针对性的,快速确认业务需求,快速开发迭代。
六、怎么具体实践微服务
要实际的应用微服务,需要解决一下四点问题:
1、客户端如何访问这些服务
2、每个服务之间如何通信
3、如此多的服务,如何实现?
4、服务挂了,如何解决?(备份方案,应急处理机制)
1、客户端如何访问这些服务
原来的Monolithic方式开发,所有的服务都是本地的,UI可以直接调用,现在按功能拆分成独立的服务,跑在独立的一般都在独立的虚拟机上的 Java进程了。客户端UI如何访问他的?
后台有N个服务,前台就需要记住管理N个服务,一个服务下线/更新/升级,前台就要重新部署,这明显不服务我们 拆分的理念,特别当前台是移动应用的时候,通常业务变化的节奏更快。
另外,N个小服务的调用也是一个不小的网络开销。还有一般微服务在系统内部,通常是无 状态的,用户登录信息和权限管理最好有一个统一的地方维护管理(OAuth)。
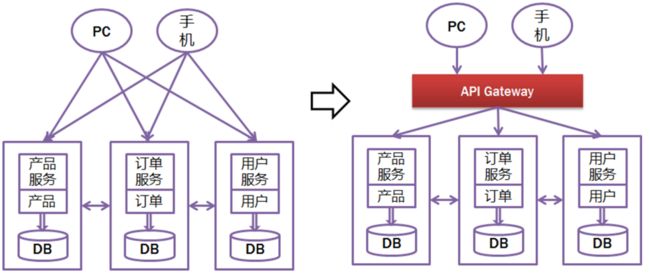
所以,一般在后台N个服务和UI之间一般会一个代理或者叫API Gateway,他的作用包括:
① 提供统一服务入口,让微服务对前台透明
② 聚合后台的服务,节省流量,提升性能
③ 提供安全,过滤,流控等API管理功能
其实这个API Gateway可以有很多广义的实现办法,可以是一个软硬一体的盒子,也可以是一个简单的MVC框架,甚至是一个Node.js的服务端。他们最重要的作 用是为前台(通常是
移动应用)提供后台服务的聚合,提供一个统一的服务出口,解除他们之间的耦合,不过API Gateway也有可能成为单点故障点或者性能的瓶颈。
用过Taobao Open Platform(淘宝开放平台)的就能很容易的体会,TAO就是这个API Gateway。
2、每个服务之间如何通信
所有的微服务都是独立的Java进程跑在独立的虚拟机上,所以服务间的通信就是IPC(inter process communication),已经有很多成熟的方案。现在基本最通用的有两种方式:
同步调用:
①REST(JAX-RS,Spring Boot)
②RPC(Thrift, Dubbo)
异步消息调用(Kafka, Notify, MetaQ)

同步和异步的区别:
一般同步调用比较简单,一致性强,但是容易出调用问题,性能体验上也会差些,特别是调用层次多的时候。RESTful和RPC的比较也是一个很有意 思的话题。
一般REST基于HTTP,更容易实现,更容易被接受,服务端实现技术也更灵活些,各个语言都能支持,同时能跨客户端,对客户端没有特殊的要求,只要封装了HTTP的
SDK就能调用,所以相对使用的广一些。RPC也有自己的优点,传输协议更高效,安全更可控,特别在一个公司内部,如果有统一个 的开发规范和统一的服务框架时,
他的开发效率优势更明显些。就看各自的技术积累实际条件,自己的选择了。
而异步消息的方式在分布式系统中有特别广泛的应用,他既能减低调用服务之间的耦合,又能成为调用之间的缓冲,确保消息积压不会冲垮被调用方,同时能保证调用方的
服务体验,继续干自己该干的活,不至于被后台性能拖慢。不过需要付出的代价是一致性的减弱,需要接受数据最终一致性;还有就是后台服务一般要 实现幂等性,因为消息
发送出于性能的考虑一般会有重复(保证消息的被收到且仅收到一次对性能是很大的考验);最后就是必须引入一个独立的broker,如果公司内部没有技术积累,
对broker分布式管理也是一个很大的挑战。
3、如此多的服务,如何实现?
在微服务架构中,一般每一个服务都是有多个拷贝,来做负载均衡。一个服务随时可能下线,也可能应对临时访问压力增加新的服务节点。服务之间如何相互感知?服务如何管理?
这就是服务发现的问题了。一般有两类做法,也各有优缺点。基本都是通过zookeeper等类似技术做服务注册信息的分布式管理。当服务上线时,服务提供者将自己的服务信息
注册到ZK(或类似框架),并通过心跳维持长链接,实时更新链接信息。服务调用者通过ZK寻址,根据可定制算法, 找到一个服务,还可以将服务信息缓存在本地以提高性能。
当服务下线时,ZK会发通知给服务客户端。
客户端做:优点是架构简单,扩展灵活,只对服务注册器依赖。缺点是客户端要维护所有调用服务的地址,有技术难度,一般大公司都有成熟的内部框架支持,比如Dubbo。
服务端做:优点是简单,所有服务对于前台调用方透明,一般在小公司在云服务上部署的应用采用的比较多。

4、服务挂了,如何解决
前面提到,Monolithic方式开发一个很大的风险是,把所有鸡蛋放在一个篮子里,一荣俱荣,一损俱损。而分布式最大的特性就是网络是不可靠的。通过微服务拆分能降低这个风险,
不过如果没有特别的保障,结局肯定是噩梦。所以当我们的系统是由一系列的服务调用链组成的时候,我们必须确保任一环节出问题都不至于影响整体链路。相应的手段有很多:
①重试机制
②限流
③熔断机制
④负载均衡
⑤降级(本地缓存)
这些方法基本都很明确通用,比如Netflix的Hystrix:https://github.com/Netflix/Hystrix

七、常见的设计模式和应用
有一个图非常好的总结微服务架构需要考虑的问题,包括:
1、API Gateway
2、服务间调用
3、服务发现
4、服务容错
5、服务部署
6、数据调用

六种常见的微服务架构设计模式:
1、聚合器微服务设计模式
这是一种最常见也最简单的设计模式:

聚合器调用多个服务实现应用程序所需的功能。它可以是一个简单的Web页面,将检索到的数据进行处理展示。它也可以是一个更高层次的组合微服务,对检索到的数据增加业务逻辑后进一步
发布成一个新的微服务,这符合DRY原则。另外,每个服务都有自己的缓存和数据库。如果聚合器是一个组合服务,那么它也有自己的缓存和数据库。聚合器可以沿X轴和Z轴独立扩展。
2、代理微服务设计模式
这是聚合模式的一个变种,如下图所示:

在这种情况下,客户端并不聚合数据,但会根据业务需求的差别调用不同的微服务。代理可以仅仅委派请求,也可以进行数据转换工作。
3、链式微服务设计模式
这种模式在接收到请求后会产生一个经过合并的响应,如下图所示:

在这种情况下,服务A接收到请求后会与服务B进行通信,类似地,服务B会同服务C进行通信。所有服务都使用同步消息传递。在整个链式调用完成之前,客户端会一直阻塞。
因此,服务调用链不宜过长,以免客户端长时间等待。
4、分支微服务设计模式
这种模式是聚合器模式的扩展,允许同时调用两个微服务链,如下图所示:
5、数据共享微服务设计模式
自治是微服务的设计原则之一,就是说微服务是全栈式服务。但在重构现有的“单体应用(monolithic application)”时,SQL数据库反规范化可能会导致数据重复和不一致。
因此,在单体应用到微服务架构的过渡阶段,可以使用这种设计模式,如下图所示:

在这种情况下,部分微服务可能会共享缓存和数据库存储。不过,这只有在两个服务之间存在强耦合关系时才可以。对于基于微服务的新建应用程序而言,这是一种反模式。
6、异步消息传递微服务设计模式
虽然REST设计模式非常流行,但它是同步的,会造成阻塞。因此部分基于微服务的架构可能会选择使用消息队列代替REST请求/响应,如下图所示:

八、优点和缺点
1、微服务的优点:
关键点:复杂度可控,独立按需扩展,技术选型灵活,容错,可用性高
①它解决了复杂性的问题。它会将一种怪异的整体应用程序分解成一组服务。虽然功能总量 不变,但应用程序已分解为可管理的块或服务。每个服务都以RPC或消息驱动的API的
形式定义了一个明确的边界;Microservice架构模式实现了一个模块化水平。
②这种架构使每个服务都能够由专注于该服务的团队独立开发。开发人员可以自由选择任何有用的技术,只要该服务符合API合同。当然,大多数组织都希望避免完全无政府状态并
限制技术选择。然而,这种自由意味着开发人员不再有义务使用在新项目开始时存在的可能过时的技术。在编写新服务时,他们可以选择使用当前的技术。此外,由于服务相对较小,
因此使用当前技术重写旧服务变得可行。
③Microservice架构模式使每个微服务都能独立部署。开发人员不需要协调部署本地服务的变更。这些变化可以在测试后尽快部署。例如,UI团队可以执行A | B测试,并快速迭代
UI更改。Microservice架构模式使连续部署成为可能。
④Microservice架构模式使每个服务都可以独立调整。您可以仅部署满足其容量和可用性限制的每个服务的实例数。此外,您可以使用最符合服务资源要求的硬件。
2、微服务的缺点
关键点(挑战):多服务运维难度,系统部署依赖,服务间通信成本,数据一致性,系统集成测试,重复工作,性能监控等
①一个缺点是名称本身。术语microservice过度强调服务规模。但重要的是要记住,这是一种手段,而不是主要目标。微服务的目标是充分分解应用程序,以便于敏捷应用程序开发和部署。
②微服务器的另一个主要缺点是分布式系统而产生的复杂性。开发人员需要选择和实现基于消息传递或RPC的进程间通信机制。此外,他们还必须编写代码来处理部分故障,
因为请求的目的地可能很慢或不可用。
③微服务器的另一个挑战是分区数据库架构。更新多个业务实体的业务交易是相当普遍的。但是,在基于微服务器的应用程序中,您需要更新不同服务所拥有的多个数据库。使用分布式事务
通常不是一个选择,而不仅仅是因为CAP定理。许多今天高度可扩展的NoSQL数据库都不支持它们。你最终不得不使用最终的一致性方法,这对开发人员来说更具挑战性。
④测试微服务应用程序也更复杂。服务类似的测试类将需要启动该服务及其所依赖的任何服务(或至少为这些服务配置存根)。再次,重要的是不要低估这样做的复杂性。
⑤Microservice架构模式的另一个主要挑战是实现跨越多个服务的更改。例如,我们假设您正在实施一个需要更改服务A,B和C的故事,其中A取决于B和B取决于C.在单片应用程序中,
您可以简单地更改相应的模块,整合更改,并一次性部署。相比之下,在Microservice架构模式中,您需要仔细规划和协调对每个服务的更改。例如,您需要更新服务C,然后更新服务B,
然后再维修A.幸运的是,大多数更改通常仅影响一个服务,而需要协调的多服务变更相对较少。
⑥部署基于微服务的应用程序也更复杂。单一应用程序简单地部署在传统负载平衡器后面的一组相同的服务器上。每个应用程序实例都配置有基础架构服务(如数据库和消息代理)
的位置(主机和端口)。相比之下,微服务应用通常由大量服务组成。例如,每个服务将有多个运行时实例。更多的移动部件需要进行配置,部署,扩展和监控。此外,您还需要实现服务
发现机制,使服务能够发现需要与之通信的任何其他服务的位置(主机和端口)。传统的基于故障单和手动操作的方法无法扩展到这种复杂程度。因此,成功部署微服务应用程序需要
开发人员更好地控制部署方法,并实现高水平的自动化。
九、思考:意识的转变
微服务对我们的思考,更多的是思维上的转变。对于微服务架构:技术上不是问题,意识比工具重要。
关于微服务的几点设计出发点:
1、应用程序的核心是业务逻辑,按照业务或客户需求组织资源(这是最难的)
2、做有生命的产品,而不是项目
3、头狼战队,全栈化
4、后台服务贯彻Single Responsibility Principle(单一职责原则)
5、VM->Docker (to PE)
6、DevOps (to PE)
同时,对于开发同学,有这么多的中间件和强大的PE支持固然是好事,我们也需要深入去了解这些中间件背后的原理,知其然知其所以然,在有限的技术资源如何通过开源技术实施微服务?
最后,一般提到微服务都离不开DevOps和Docker,理解微服务架构是核心,devops和docker是工具,是手段。
十、参考资料和推荐阅读:
http://kb.cnblogs.com/page/520922/
http://www.infoq.com/cn/articles/seven-uservices-antipatterns
http://www.csdn.net/article/2015-08-07/2825412
http://blog.csdn.net/mindfloating/article/details/45740573
http://blog.csdn.net/sunhuiliang85/article/details/52976210
http://www.oschina.net/news/70121/microservice
Docker三剑客:Compose,Machine和Swarm
Docker三大编排工具:
Docker Compose:是用来组装多容器应用的工具,可以在 Swarm集群中部署分布式应用。
Docker Machine:是支持多平台安装Docker的工具,使用 Docker Machine,可以很方便地在笔记本、云平台及数据中心里安装Docker。
Docker Swarm:是Docker社区原生提供的容器集群管理工具。
Docker Compose
Github地址: https://github.com/docker/compose
简单来讲,Compose是用来定义和运行一个或多个容器应用的工具。使用compaose可以简化容器镜像的建立及容器的运行。
Compose使用python语言开发,非常适合在单机环境里部署一个或多个容器,并自动把多个容器互相关联起来。
Compose 中有两个重要的概念:
服务 (service):一个应用的容器,实际上可以包括若干运行相同镜像的容器实例。
项目 (project):由一组关联的应用容器组成的一个完整业务单元,在 docker-compose.yml 文件中定义。
Compose是使用YML文件来定义多容器应用的,它还会用 docker-compose up 命令把完整的应用运行起来。docker-compose up 命令为应用的运行做了所有的准备工作。从本质上讲,Compose把YML文件解析成docker命令的参数,然后调用相应的docker命令行接口,从而把应用以容器化的方式管理起来。它通过解析容器间的依赖关系来顺序启动容器。而容器间的依赖关系则可以通过在 docker-compose.yml文件中使用 links 标记指定。
安装Docker compose:
官方文档
pip安装:
pip install docker-compose
从github安装:
curl -L --fail https://github.com/docker/compose/releases/download/1.17.0/run.sh -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
卸载:
rm /usr/local/bin/docker-compose # 使用curl安装的
pip uninstall docker-compose # 使用pip卸载
命令说明
docker-compose --help
Docker Machine
Github地址: https://github.com/docker/machine/
Docker Machine 是 Docker 官方编排(Orchestration)项目之一,负责在多种平台上快速安装 Docker 环境。
Docker Machine 项目基于 Go 语言实现,目前在 Github 上进行维护。
安装:
curl -L https://github.com/docker/machine/releases/download/v0.13.0/docker-machine-`uname -s`-`uname -m` > /usr/local/bin/docker-machine
chmod +x /usr/local/bin/docker-machine
完成后,查看版本信息:
# docker-machine -v
docker-machine version 0.13.0, build 9ba6da9
为了得到更好的体验,我们可以安装 bash completion script,这样在 bash 能够通过 tab 键补全 docker-mahine 的子命令和参数。
下载方法:
base=https://raw.githubusercontent.com/docker/machine/v0.13.0
for i in docker-machine-prompt.bash docker-machine-wrapper.bash docker-machine.bash
do
sudo wget "$base/contrib/completion/bash/${i}" -P /etc/bash_completion.d
done
确认版本将其放置到 /etc/bash_completion.d 目录下。
然后在你的bash终端中运行如下命令,告诉你的设置在哪里可以找到docker-machine-prompt.bash你以前下载的文件 。
source /etc/bash_completion.d/docker-machine-prompt.bash
要启用docker-machine shell提示符,请添加 $(__docker_machine_ps1)到您的PS1设置中~/.bashrc。
PS1='[\u@\h \W$(__docker_machine_ps1)]\$ '
使用:
Docker Machine 支持多种后端驱动,包括虚拟机、本地主机和云平台等
创建本地主机实例:
使用 virtualbox 类型的驱动,创建一台 Docker主机,命名为test
安装VirtualBox:
配置源:
# cat /etc/yum.repos.d/virtualbox.repo
[virtualbox]
name=Oracle Linux / RHEL / CentOS-$releasever / $basearch - VirtualBox
baseurl=http://download.virtualbox.org/virtualbox/rpm/el/$releasever/$basearch
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://www.virtualbox.org/download/oracle_vbox.asc
#安装VirtualBox:
yum search VirtualBox
yum install -y VirtualBox-5.2
/sbin/vboxconfig # 重新加载VirtualBox服务
创建主机:
# docker-machine create -d virtualbox test
Running pre-create checks...
Creating machine...
(test) Copying /root/.docker/machine/cache/boot2docker.iso to /root/.docker/machine/machines/test/boot2docker.iso...
(test) Creating VirtualBox VM...
(test) Creating SSH key...
(test) Starting the VM...
(test) Check network to re-create if needed...
(test) Found a new host-only adapter: "vboxnet0"
(test) Waiting for an IP...
Waiting for machine to be running, this may take a few minutes...
Detecting operating system of created instance...
Waiting for SSH to be available...
Detecting the provisioner...
Provisioning with boot2docker...
Copying certs to the local machine directory...
Copying certs to the remote machine...
Setting Docker configuration on the remote daemon...
Checking connection to Docker...
Docker is up and running!
To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env test
也可以在创建时加上如下参数,来配置主机或者主机上的 Docker。
--engine-opt dns=114.114.114.114 #配置 Docker 的默认 DNS
--engine-registry-mirror https://registry.docker-cn.com #配置 Docker 的仓库镜像
--virtualbox-memory 2048 #配置主机内存
--virtualbox-cpu-count 2 #配置主机 CPU
更多参数请使用 docker-machine create --driver virtualbox --help 命令查看。
查看主机:
# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
test - virtualbox Running tcp://192.168.99.100:2376 v18.05.0-ce
创建主机成功后,可以通过 env 命令来让后续操作目标主机:
docker-machine env test
可以通过 SSH 登录到主机:
docker-machine ssh test
官方支持驱动:
# 通过 -d 选项可以选择支持的驱动类型。
amazonec2
azure
digitalocean
exoscale
generic
google
hyperv
none
openstack
rackspace
softlayer
virtualbox
vmwarevcloudair
vmwarefusion
vmwarevsphere
第三方驱动请到第三方驱动列表 查看
常用操作命令:
active 查看活跃的 Docker 主机
config 输出连接的配置信息
create 创建一个 Docker 主机
env 显示连接到某个主机需要的环境变量
inspect 输出主机更多信息
ip 获取主机地址
kill 停止某个主机
ls 列出所有管理的主机
provision 重新设置一个已存在的主机
regenerate-certs 为某个主机重新生成 TLS 认证信息
restart 重启主机
rm 删除某台主机
ssh SSH 到主机上执行命令
scp 在主机之间复制文件
mount 挂载主机目录到本地
start 启动一个主机
status 查看主机状态
stop 停止一个主机
upgrade 更新主机 Docker 版本为最新
url 获取主机的 URL
version 输出 docker-machine 版本信息
help 输出帮助信息
每个命令,又带有不同的参数,可以通过docker-machine COMMAND --help查看。
Docker Swarm
Docker Swarm 是 Docker 官方三剑客项目之一,提供 Docker 容器集群服务,是 Docker 官方对容器云生态进行支持的核心方案。使用它,用户可以将多个 Docker 主机封装为单个大型的虚拟 Docker 主机,快速打造一套容器云平台。
Docker 1.12 Swarm mode 已经内嵌入 Docker 引擎,成为了 docker 子命令 docker swarm。请注意与旧的 Docker Swarm 区分开来。
Swarm mode内置kv存储功能,提供了众多的新特性,比如:具有容错能力的去中心化设计、内置服务发现、负载均衡、路由网格、动态伸缩、滚动更新、安全传输等。使得 Docker 原生的 Swarm 集群具备与 Mesos、Kubernetes 竞争的实力。
基本概念
Swarm 是使用 SwarmKit 构建的 Docker 引擎内置(原生)的集群管理和编排工具。
节点:
运行 Docker 的主机可以主动初始化一个 Swarm 集群或者加入一个已存在的 Swarm 集群,这样这个运行 Docker 的主机就成为一个 Swarm 集群的节点 (node)
节点分为管理 (manager) 节点和工作 (worker) 节点
管理节点:用于 Swarm 集群的管理,docker swarm 命令基本只能在管理节点执行(节点退出集群命令 docker swarm leave 可以在工作节点执行)。一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为 leader,leader 通过 raft 协议实现。
工作节点:是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。也可以通过配置让服务只运行在管理节点。
集群中管理节点与工作节点的关系如下所示:

服务和任务:
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。
服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式:
replicated services 按照一定规则在各个工作节点上运行指定个数的任务。
global services 每个工作节点上运行一个任务。
两种模式通过 docker service create 的 --mode 参数指定。
容器、任务、服务的关系如下所示:

swarm:
从 v1.12 开始,集群管理和编排功能已经集成进 Docker Engine。当 Docker Engine 初始化了一个 swarm 或者加入到一个存在的 swarm 时,它就启动了 swarm mode。没启动 swarm mode 时,Docker 执行的是容器命令;运行 swarm mode 后,Docker 增加了编排 service 的能力。
Docker 允许在同一个 Docker 主机上既运行 swarm service,又运行单独的容器。
node:
swarm 中的每个 Docker Engine 都是一个 node,有两种类型的 node:manager 和 worker。
为了向 swarm 中部署应用,我们需要在 manager node 上执行部署命令,manager node 会将部署任务拆解并分配给一个或多个 worker node 完成部署。manager node 负责执行编排和集群管理工作,保持并维护 swarm 处于期望的状态。swarm 中如果有多个 manager node,它们会自动协商并选举出一个 leader 执行编排任务。woker node 接受并执行由 manager node 派发的任务。默认配置下 manager node 同时也是一个 worker node,不过可以将其配置成 manager-only node,让其专职负责编排和集群管理工作。work node 会定期向 manager node 报告自己的状态和它正在执行的任务的状态,这样 manager 就可以维护整个集群的状态。
service:
service 定义了 worker node 上要执行的任务。swarm 的主要编排任务就是保证 service 处于期望的状态下。
举一个 service 的例子:在 swarm 中启动一个 http 服务,使用的镜像是 httpd:latest,副本数为 3。manager node 负责创建这个 service,经过分析知道需要启动 3 个 httpd 容器,根据当前各 worker node 的状态将运行容器的任务分配下去,比如 worker1 上运行两个容器,worker2 上运行一个容器。运行了一段时间,worker2 突然宕机了,manager 监控到这个故障,于是立即在 worker3 上启动了一个新的 httpd 容器。这样就保证了 service 处于期望的三个副本状态。
默认配置下 manager node 也是 worker node,所以 swarm-manager 上也运行了副本。如果不希望在 manager 上运行 service,可以执行如下命令:
docker node update --availability drain master
创建swarm集群
Swarm 集群由管理节点和工作节点组成。现在我们来创建一个包含一个管理节点和两个工作节点的最小 Swarm 集群。
初始化集群:
使用Docker Machine创建三个 Docker 主机,并加入到集群中
首先创建一个 Docker 主机作为管理节点:
docker-machine create -d virtualbox manger
使用 docker swarm init 在管理节点初始化一个 Swarm 集群
docker-machine ssh manger
docker@manger:~$ docker swarm init --advertise-addr 192.168.99.101
Swarm initialized: current node (fwh0yy8m8bygdxnsl7x1peioj) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-2acj2brip56iee9p4hc7klx3i6ljnpykh5lx6ea3t9xlhounnv-70knqo263hphhse02gxuvja12 192.168.99.101:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
docker@manger:~$
注意:如果你的 Docker 主机有多个网卡,拥有多个 IP,必须使用 --advertise-addr 指定 IP。
执行 docker swarm init 命令的节点自动成为管理节点。
增加工作节点:
在docker swarm init 完了之后,会提示如何加入新机器到集群,如果当时没有注意到,也可以通过下面的命令来获知 如何加入新机器到集群。
# docker swarm join-token worker [--quiet]
# docker swarm join-token manager [--quiet]
根据token的不同,我们来区分加入集群的是manager节点还是普通的节点。通过加入–quiet参数可以只输出token,在需要保存token的时候还是十分有用的。
上一步初始化了一个 Swarm 集群,拥有了一个管理节点,下面继续创建两个 Docker 主机作为工作节点,并加入到集群中。
# docker-machine create -d virtualbox worker1
# docker-machine ssh worker1
docker@worker1:~$ docker swarm join --token SWMTKN-1-2acj2brip56iee9p4hc7klx3i6ljnpykh5lx6ea3t9xlhounnv-70knqo263hphhse02gxuvja12 192.168.99.101:2377
This node joined a swarm as a worker.
docker@worker1:~$
# docker-machine create -d virtualbox worker2
# docker-machine ssh worker2
docker@worker2:~$ docker swarm join --token SWMTKN-1-2acj2brip56iee9p4hc7klx3i6ljnpykh5lx6ea3t9xlhounnv-70knqo263hphhse02gxuvja12 192.168.99.101:2377
This node joined a swarm as a worker.
docker@worker2:~$
查看集群:
在manager machine上执行 docker node ls 查看有哪些节点加入到swarm集群。
# docker-machine ssh manger
docker@manger:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
fwh0yy8m8bygdxnsl7x1peioj * manger Ready Active Leader 18.05.0-ce
0v6te4mspwu1d1b4250fp5rph worker1 Ready Active 18.05.0-ce
mld8rm9z07tveu1iknvws0lr1 worker2 Ready Active 18.05.0-ce
部署服务
使用 docker service 命令来管理 Swarm 集群中的服务,该命令只能在管理节点运行。
新建服务:
在上一节创建的 Swarm 集群中运行一个名为 nginx 服务:
docker@manger:~$ docker service create --replicas 3 -p 80:80 --name nginx nginx
khw3av021hlxs3koanq85301j
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
docker@manger:~$
使用浏览器,输入任意节点 IP ,即可看到 nginx 默认页面。
查看服务:
使用 docker service ls 来查看当前 Swarm 集群运行的服务。
docker@manger:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
khw3av021hlx nginx replicated 3/3 nginx:latest *:80->80/tcp
docker@manger:~$
使用 docker service ps 来查看某个服务的详情。
docker@manger:~$ docker service ps nginx
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
6b900c649xyp nginx.1 nginx:latest worker1 Running Running 5 minutes
n55uhpjdurxs nginx.2 nginx:latest worker2 Running Running 5 minutes ago
l2uiyggbegsf nginx.3 nginx:latest manger Running Running 5 minutes ago
docker@manger:~$
使用 docker service logs 来查看某个服务的日志:
docker@manger:~$ docker service logs nginx
服务伸缩:
可以使用 docker service scale 对一个服务运行的容器数量进行伸缩
当业务处于高峰期时,我们需要扩展服务运行的容器数量
$ docker service scale nginx=5
当业务平稳时,我们需要减少服务运行的容器数量
$ docker service scale nginx=2
删除服务:
使用 docker service rm 来从 Swarm 集群移除某个服务。
$ docker service rm nginx
使用 compose 文件
管理敏感数据
管理配置信息
更多swarm的资料可以参考:《每天5分钟玩转 Docker 容器技术》Docker Swarm部分
参考链接:
https://blog.csdn.net/wh211212/article/details/78686241
https://yeasy.gitbooks.io/docker_practice/content/swarm/
容器编排工具怎么选 Swarm kubernetes Mesos的优缺点
【编者的话】这篇文章对比了三大主流调度框架:Swarm、Kubernetes和Mesos。文章不仅从理论上讨论了各个框架的优缺点,还从两个实际的案例出发,分析了每个框架具体使用方法。
这篇文章对比了三大主流调度框架:Docker Swarm、Google Kubernetes和Apache Mesos(基于Marathon框架)。在解释了调度和容器的基本概念后,文章探讨了每个框架的特点,并从以下两个用例来对比他们:一个只使用了两个容器的网站应用,和一个能具有可扩展性的投票应用。
什么是调度(scheduling)?什么是容器(container)?
调度
一个集群调度工具有多个目的:使得集群的资源被高效利用,支持用户提供的配置约束(placement constraint),能够迅速调度应用以此保证它们不会处于待定状态(pending state),有一定程度的“公平”(fairness),具有一定的鲁棒性和可用性。为了达到这些目的,在一篇关于Omega(一个由Google开发的,针对大型计算集群的可扩展调度框架)的白皮书中,提到了三个主要的调度架构[48]:
Schematic overview of scheduling architectures, © Google, Inc. [48]
一体式调度(Monolithic scheduling)
一体式调度框架由单一的调度代理(scheduling agent)组成,它负责处理所有的请求,这种框架通常应用于高性能计算。一体式框架通常实现了一个单一的算法来处理所有的作业(job),因此根据作业的类型来运行不同的调度逻辑是困难的。
Apache Hadoop YARN[55]是一个非常流行的架构,尽管它将许多调度功能都分发到每一个应用模块中,但它依然是一体式的调度架构,因为,实际上,所有的资源请求都会被发送到一个单一的全局调度模块。
两级调度(Two-level scheduling)
两级调度框架会利用一个中央协调器(central coordinator)来动态地决定各个调度模块可以调用多少资源。这项技术被应用于Mesos[50]和Hadoop-on-Demand(现在被YARN取代了)。
在这类架构里,分配器会将给定的资源一次性分配个一个框架,因此避免了资源使用的冲突,并且通过控制资源分配的顺序和大小来实现一种相对的资源公平分配。然而,一个资源每次只能被一个框架使用,因此并发控制被称之为悲观的(pessimistic),这种控制策略是不易于出错的(less error-prone),但是相对于将一个资源同时分配个多个框架的乐观并发式控制来说,速度是更慢的。
共享状态调度(Shared-state scheduling)
Omega 赋予了每一个调度器(scheduler)对整个集群的全部访问权限,也就是说调度器们可以自由地竞争。因为所有的资源分配都发生在各个调度器中,所以也就没有了中央资源分配器。也就是说,没有了中央策略引擎,每一个调度器能够自己做决定。
通过支持独立的调度器实现和公布整个资源分配的状况,Omega不仅支持扩展多个调度器,还能够支持它们自己的调度策略[54]
哪一个才是最好的调度架构?
世界上并不存在一个通用的唯一方案来解决集群计算的所有问题,因此不同的公司为了适应需求,各自开发了不同的产品。Google(Omege和Kubernetes的主要贡献者)假设开发者们会遵守关于作业优先级的规则,因此Google认为架构应该把控制权交给开发者;而Yahoo!(YARN的主要贡献者)更推崇强制容量、公平和截止时间的框架。
容器革命(The container revolution)
容器是虚拟机的一种替代品,它能够帮助开发者构建、迁移、部署和实例化应用[3]。一个容器是进程的集合,这些进程独立于包含有进程依赖的机器。
各个容器尽管共享了一个操作系统实例,但是它们独立运行,互不影响。容器并不需要一个完整的操作系统,这个特性使得它们比虚拟机更加轻量。
因为容器能够在数秒内启动(比虚拟机快多了),因此容器仅分配了少量的资源(少于2GB的RAM)并且能通过扩展来满足应用的需求。容器经常被应用于微服务(microservices),每一容器代表一个服务,这些服务通过网络来进行互联。这种架构使得每一个模块都能够被独立地部署和扩展。
资源的数量和所期望的容器生命周期是普通调度器和容器调度器的主要区别。传统集群设计,比如说Hadoop,更关注于运行大规模作业[55],然而容器集群则会运行几十个小的实例来解决问题,这些实例需要被组织化和网络化,以此来优化共享数据和计算的能力。
Docker
Docker是一个主流容器管理工具,它是第一个基于Linux容器(LXC)的[2],但是现在被runC[46]所取代了(runC是是一个由Open Containers Initiative开发的CLI工具,它能够创建和运行容器[36])。Docker容器支持分层的文件系统,因此它能够和宿主机共享系统内核。这个特性意味着即便一个Docker镜像基于一个1GB的操作系统,在同一个主机上运行10个容器实例并不需要消耗10GB的空间,相比之下,每一台虚拟机都需要一个完整的1GB操作系统。
Virtual machines architecture compared to containers, © Docker Inc. [23]
Docker的镜像可以理解为一个操作系统的快照。如果你想要创建一个新的镜像,你需要启动一个基础镜像,然后做一些修改,最后提交修改,形成新的镜像。这些镜像能够发布在私有或者公有的库上[10]供其他开发者使用,开发者只需要将镜像pull下来即可。
使用镜像可以非常方便的创建操作系统的快照,并且使用它们来创建新的容器,这些功能非常的轻量和易用,这些都是Docer CLI和商业模式的核心。[12]
容器包含了所有运行所需要的东西(代码,运行时,系统工具,库),因此Docker给予开发者一个轻量的,稳定的环境来快速地进行创建和运行作业。
容器调度简介(Description of container schedulers)
容器调度工具的主要任务就是负责在最合适的主机上启动容器,并且将它们关联起来。它必须能够通过自动的故障转移(fail-overs)来处理错误,并且当一个实例不足以处理/计算数据时,它能够扩展容器来解决问题。
这篇文章比较了三个主流容器调度框架:Docker Swarm [13], Apache Mesos (running the Marathon framework) [50] and Google Kubernetes [31]。在这一节,将会讨论各个框架的设计和特点。
Docker Swarm
Docker Swarm是一个由Docker开发的调度框架。由Docker自身开发的好处之一就是标准Docker API的使用[17]。Swarm的架构由两部分组成:
Docker Swarm architecture, ©Alexandre Beslic (Docker Inc.) [14]
其中一个机器运行了一个Swarm的镜像(就像运行其他Docker镜像一样),它负责调度容器[4],在图片上鲸鱼代表这个机器。Swarm使用了和Docker标准API一致的API,这意味着在Swarm上运行一个容器和在单一主机上运行容器使用相同的命令。尽管有新的flags可用,但是开发者在使用Swarm的同时并不需要改变他的工作流程。
Swarm由多个代理(agent)组成,把这些代理称之为节点(node)。这些节点就是主机,这些主机在启动Docker daemon的时候就会打开相应的端口,以此支持Docker远程API[5]。其中三个节点显示在了图上。这些机器会根据Swarm调度器分配给它们的任务,拉取和运行不同的镜像。
当启动Docker daemon时,每一个节点都能够被贴上一些标签(label),这些标签以键值对的形式存在,通过标签就能够给予每个节点对应的细节信息。当运行一个新的容器时,这些标签就能够被用来过滤集群,具体的细节在后面的部分详谈。
策略(Strategies)
Swarm采用了三个策略(比如说,策略可以是如何选择一个节点来运行容器)[22]:
策略名:节点选择
- spread:最少的容器,并且忽视它们的状态
- binpack:最拥挤(比如说,拥有最少数量的CPU/RAM)
- random:随机选择
如果多个节点被选中,调度器会从中随机选择一个。在启动管理器(manager)时,策略需要被定义好,否则“spread”策略会被默认使用。
过滤器(Filters)
为了在节点子集中调度容器,Swarm提供了两个节点过滤器(constraint和health),还有三个容器配置过滤器(affinity,dependency和port)。
约束过滤器(Constraint filter)
每一个节点都关联有键值对。为了找都某一个关联多个键值对的节点,你需要在docker daemon启动的时候,输入一系列的参数选项。当你在实际的生产环境中运行容器时,你可以指定约束来完成查找,比如说一个容器只会在带有环境变量key=prod的节点上运行。如果没有节点满足要求,这个容器将不会运行。
一系列的标准约束已经被设置,比如说节点的操作系统,在启动节点时,用户并不需要设置它们。
健康过滤器(Health filter)
健康过滤器用来防止调度不健康的节点。在翻看了Swarm的源代码后,只有少量关于这个概念的信息是可用的。
吸引力过滤器(Affinity filter)
吸引力过滤器是为了在运行一个新的容器时,创建“吸引力”。涉及到容器、镜像和标签的吸引力存在有三类。
对容器来说,当你想要运行一个新的容器时,你只需要指定你想要链接的容器的名字(或者容器的ID),然后这些容器就会互相链接。如果其中一个容器停止运行了,剩下的容器都会停止运行。
镜像吸引力将会把想要运行的容器调度到已经拥有该镜像的节点上。
标签吸引力会和容器的标签一起工作。如果想要将某一个新的容器紧挨着指定的容器,用户只需要指定一个key为container,value为
吸引力和约束的语法接受否定和软强制(soft enforcement),即便容器不可能满足所有的需求。[18]
依赖过滤器(Dependency filter)
依赖过滤器能够用来运行一个依赖于其他容器的容器。依赖意味着和其他容器共享磁盘卷,或者是链接到其他容器,亦或者和其他容器在同一个网络栈上。
端口过滤器(Port filter)
如果你想要在具有特定开发端口的节点上运行容器,你就可以使用端口过滤器了。如果集群中没有任何一个节点该端口可用的话,系统就会给出一个错误的提示信息。
Apache Mesos & Mesosphere Marathon
Mesos的目的就是建立一个高效可扩展的系统,并且这个系统能够支持很多各种各样的框架,不管是现在的还是未来的框架,它都能支持。这也是现今一个比较大的问题:类似Hadoop和MPI这些框架都是独立开的,这导致想要在框架之间做一些细粒度的分享是不可能的。[35]
因此Mesos的提出就是为了在底部添加一个轻量的资源共享层(resource-sharing layer),这个层使得各个框架能够适用一个统一的接口来访问集群资源。Mesos并不负责调度而是负责委派授权,毕竟很多框架都已经实现了复杂的调度。
取决于用户想要在集群上运行的作业类型,共有四种类型的框架可供使用[52]。其中有一些支持原生的Docker,比如说Marathon[39]。Docker容器的支持自从Mesos 0.20.0就已经被加入到Mesos中了[51]。
我们接下来将会重点关注如何在让Mesos和Marathon一起工作,毕竟Marathon主要是由Mesosphere维护[41],并且提供了很多关于调度的功能,比如说约束(constraints)[38],健康检查(health checks)[40],服务发现(service discovery)和负载均衡(load balancing)[42]。
Apache Mesos architecture using Marathon, © Adrian Mouat [49]
我们可以从图上看到,集群中一共出现了4个模块。ZooKeeper帮助Marathon查找Mesos master的地址[53],同时它具有多个实例可用,以此应付故障的发生。Marathon负责启动,监控,扩展容器。Mesos maser则给节点分配任务,同时如果某一个节点有空闲的CPU/RAM,它就会通知Marathon。Mesos slave运行容器,并且报告当前可用的资源。
约束(Constraints)
约束使得操作人员能够操控应用在哪些节点上运行,它主要由三个部分组成:一个字段名(field name)(可以是slavve的hostname或者任何Mesos slave属性),一个操作符和一个可选的值。5个操作符如下:
操作符:角色(role)
- UNIQUE:使得属性唯一,比如说越苏[“hostname”,”UNIQUE”]使得每个host上只有一个应用在运行。
- CLUSTER:使得运行应用的slaves必须共享同一个特定属性。比如说约束 [“rack id”, “CLUSTER”, “rack-1”] 强制应用必须运行在rack-1上,或者处于挂起状态知道rack-1有了空余的CPU/RAM。
- GROUP_BY:根据某个特性的属性,将应用平均分配到节点上,比如说特定的host或者rack。
- LIKE:使得应用只运行在拥有特定属性的slaves上。尽管只有CLUSTER可用,但由于参数是一个正则表达式,因此很多的值都能够被匹配到。
- UNLIKE:和LIKE相反。
健康检查(Health checks)
健康检查是应用依赖的,需要被手动实现。这是因为只有开发者知道他们自己的应用如何判断健康状态。(这是一个Swarm和Mesos之间的不同点)
Mesos提供了很多选项来声明每个健康检查之间需要等待多少秒,或者多少次连续的健康检查失败后,这个不健康的任务需要被终结。
服务发现和负载均衡(Service discovery and load balancing)
为了能够发送数据到正在运行的应用,我们需要服务发现。Apache Mesos提供了基于DNS的服务发现,称之为Mesos-DNS[44],它能够在多个框架(不仅仅是Marathon)组成的集群中很好的工作。
如果一个集群只由运行容器的节点组成,Marathon足以承当起管理的任务。在这种情况下,主机可以运行一个TCP的代理,将静态服务端口的连接转发到独立的应用实例上。Marathon确保所有动态分配的服务端口都是唯一的,这种方式比手动来做好的多,毕竟多个拥有同样镜像的容器需要同一个端口,而这些容器可以运行在同一个主机上。
Marathon提供了两个TCP/HTTP代理。一个简单的shell脚本[37]还有一个更复杂的脚本,称之为marathon-ld,它拥有更多的功能[43]。
Google Kubernetes
Kubernetes是一个Docker容器的编排系统,它使用label和pod的概念来将容器换分为逻辑单元。Pods是同地协作(co-located)容器的集合,这些容器被共同部署和调度,形成了一个服务[28],这是Kubernetes和其他两个框架的主要区别。相比于基于相似度的容器调度方式(就像Swarm和Mesos),这个方法简化了对集群的管理.
Kubernetes调度器的任务就是寻找那些PodSpec.NodeName为空的pods,然后通过对它们赋值来调度对应集群中的容器[32]。相比于Swarm和Mesos,Kubernetes允许开发者通过定义PodSpec.NodeName来绕过调度器[29]。调度器使用谓词(predicates)[29]和优先级(priorites)[30]来决定一个pod应该运行在哪一个节点上。通过使用一个新的调度策略配置可以覆盖掉这些参数的默认值[33]。
命令行参数plicy-config-file可以指定一个JSON文件(见附录A)来描述哪些predicates和priorities在启动Kubernetes时会被使用,通过这个参数,调度就能够使用管理者定义的策略了。
Kubernetes architecture (containers in grey, pods in color), © Google Inc. [31]
谓词(Predicates)
谓词是强制性的规则,它能够用来调度集群上一个新的pod。如果没有任何机器满足该谓词,则该pod会处于挂起状态,知道有机器能够满足条件。可用的谓词如下所示:
- Predicate:节点的需求
- PodFitPorts:没有任何端口冲突
- PodFitsResurce:有足够的资源运行pod
- NoDiskConflict:有足够的空间来满足pod和链接的数据卷
- MatchNodeSelector:能够匹配pod中的选择器查找参数。
- HostName:能够匹配pod中的host参数
优先级(Priorities)
如果调度器发现有多个机器满足谓词的条件,那么优先级就可以用来判别哪一个才是最适合运行pod的机器。优先级是一个键值对,key表示优先级的名字,value就是该优先级的权重。可用的优先级如下:
- Priority:寻找最佳节点
- LeastRequestdPriority:计算pods需要的CPU和内存在当前节点可用资源的百分比,具有最小百分比的节点就是最优的。
- BalanceResourceAllocation:拥有类似内存和CPU使用的节点。
- ServicesSpreadingPriority:优先选择拥有不同pods的节点。
- EqualPriority:给所有集群的节点同样的优先级,仅仅是为了做测试。
结论
以上三种框架提供了不同的功能和归来来自定义调度器的逻辑。从这节来看,显而易见,由于Swarm的原生API,Swarm是三个中最容易使用的。
以Docker的方式来运行容器[15]意味着一个容器是短暂存在的,并且每一个容器只运行一个进程。根据这条原则,多个容器提供一个服务或者代表一个应用是极度正常的。
因此编排和调度容器成为了最应当解决的问题,这也解释了为什么,即便这项技术不是很成熟,但仍有那么多的调度器被开发出来,并且提供了不同的功能和选项。
调度器对比
从上一节我们可以看到,为了让容器一起协调工作,成为一个真正的服务,在很多情况下,容器调度器都是有必要存在的。
首先,我们会从一个简单的例子(只有两个容器运行)来对比每个调度器。为了方便,我们使用Docker提供的初学者教程中的案例项目,这个项目会运行一个快餐车的网站[47],并且将它部署到集群上。
然后,我们会从另外一个例子来对比不同调度器的扩展性:基于AWS的投票应用。这个例子基于Docker提供的“try Swarm at scale”教程[7]。应用中所有的模块都运行在容器中,而容器运行在不同的节点,并且这个应用被设计成可扩展的:
Voting application architecture, © Docker Inc [7]
负载均衡负责管理运行Flask应用[1]的web服务器和关联队列的数量。Worker层扫描Redis队列,将投票出列,并且将重复项提交到运行在其他节点的Postgres容器。
快餐车应用(Food Trucks Application)
在这一节我们主要对比每个调度器的默认配置,比如说由于用户需求极速增长所带来的单容器瓶颈问题,还有如何处理一个需要重启的容器。
我们想要运行的多容器环境是由一个运行拥有Flask进程的容器[1],和其他运行有Elasticsearch进程的容器组成。
Swarm
Docker公司提供了多个工具,我们已经看到了Docker引擎和Swarm,但Doccker Compose才是多容器环境的关键。有了这个工具,我们能够仅仅使用一个文件来定义和运行多个容器。
对于我们现在的例子,我们可以使用一个docker-compose.yml文件来指定两个需要运行的镜像(一个定制的Flask镜像和一个Elasticsearch镜像)和Swarm之间的关联。
一个主要的问题就是Swarm可以像单主机Docker实例一样,从一个Dockerfile来构建镜像,但是构建的镜像只能在单一节点上运行,而不能够被分布到集群上的其他节点上。因此,应用被认为是一个容器,这种方式不是细粒度的。
如果我们使用docker-compose scale来扩展其中一个容器(附录 B),这个新的容器将会根据调度器规则进行调度。如果容器负载过重,Docker Swarm并不会自动扩展容器,这对于我们的例子来说是一个大问题:我们必须经常去检查下用户访问量是否达到瓶颈。
如果一个容器宕机了,Swarm并不会跟踪一个服务应该有多少个实例在运行,因此它不会创建一个新的容器。其外,想要在某些容器上滚动更新也是不可能的,一个符合Docker思想的特性是非常有用的:能够快速启动和停止无状态的容器。
Mesos & Marathon
与直接使用docker-compose.yml文件不同,我们需要给Marathon一个具体的定义。第一个定义应用于Elasticsearch(附录C),我们使用所有的默认配置,并不使用调度器的特性;在这种情况下,定义非常的简单,并且类似于我们之间的docker-compose.yml文件。应用于Flask的定义(附录D)使用了更多Mesos的特性,包括指定CPU/RAM信息和健康检查。
Mesos提供了一个更加强大的定义文件,因为容器和需求都可以被描述。相比于Swarm,这种方式并不简单,但是它能够很简单的扩展服务,比如说,通过修改应用定义中的容器实例来扩展。(在Flask定义中设置数量为2)
Kubernetes
Kubernetes在YAML或者JSON(附录E)中使用了另外一种描述来表示pod。它包含了一个ReplicationController来保证应用至少有一个实例在运行。当我们在Kubernetes集群中创建了一个pod时,我们需要创建一个叫做负载均衡的Kubernetes服务,它负责转发流量到各个容器。如果只有一个实例,使用这种服务也是非常有用的,因为它能否将流量准确的转发到拥有动态IP的pod上。
相比于Swarm,Kubernetes添加了pod和replica的逻辑。这个更加复杂的结构为调度器和编排工具提供了更加丰富的功能,比如说负载均衡,扩展或者收缩应用的能力。并且你还能够更新正在运行中的容器实例,这是一个非常有用的、符合Docker哲学的功能。
结论
Docker Compose是调度多容器环境的标准方式,Docker Swarm直接使用这种方式。而对于Mesos和Kubernetes,它们提供了一个额外的描述文件,它整合了标准描述和额外的信息,因此它能够为用户提供更好的调度。
我们可以看到,Mesos的调度器能够和Docker容器很好的工作,但是对于我们当前的用例来说,Kubernetes才是最适合运行这种微服务架构的框架。通过提供类似于Compose的描述,同时提供relication controller,Kubernetes能够为用户提供一个稳定的服务,并且具有可扩展性。
投票系统(Voting application)
这个部署架构同样是来自Docker的教程[7],为了构建集群,我们创建了一个Amazon Virtual Public Cloud(VPC)并且在VPC上部署节点。我们之所以使用Amazon的服务,是因为它能够支持这三个调度器,并且在Amazon上,Docker能通过一个部署文件来启动一个Docker式的集群。
Swarm
创建集群的主要步骤有:连接集群中所有的节点,创建一个网络使得节点之间能够便捷地交流(类似于Kubernetes自动提供的),通过在每个特定容器上运行镜像来完成最后部署。
Voting application organization, © Docker Inc [7]
EC2 machines to run the scalable application in a cluster.
我们使用命令行参数restart=unless-stopped来运行docker daemon能够在某一个容器意外停止时重启它。如果一整个节点崩了,那么节点上的容器并不会在其他节点上重新启动。
这个集群拥有一个负载均衡器[25],它能防止将请求转发到一个不再存在的节点上,因此如果frontend1崩了,所有的请求就会自动流向frontend2。因为负载均衡器本身就是一个容器,通过参数restart=unless-stopped能够确保它意外停止时能够重启。
这个集群部署的主要问题就是,Postgres节点是单一的,如果这个节点崩了,那么整个应用程序就崩了。为了提高集群的故障容错率,我们需要添加另外一个Swarm的管理器,以防止前一个崩溃了。
这个调度器的效率类似于直接在单个机器上运行容器。Swarm的调度策略非常的简单(我们从上一节可以看出),因此调度器选择节点时非常的迅速,仿佛集群中只有一台机器。如果想要看到进一步的性能测试,可以参考Docker在Swarm上运行3000个容器的扩展测试[16]。
Mesos & Marathon
Mesos & Marathon是商业产品,因此也提供了部署的服务。Mesosphere[45]提供了一个社区版本在几分钟内创建一个高可用性的集群。我们只需要给出master的数量,公开的代理节点,私有的代理节点,然后一个Mesos集群就诞生了。
Mesos集群的配置相比于Swarm复杂的多,这是因为它有很多的模块(Mesos marathon,Mesos slaves,Marathon和Zookeeper实例等)。因此提前配置好的集群是一个不错的方法,并且能够直接运行一个高可用的集群(有三个master)对于建立高容错的集群来说很有帮助。
Deploying a cluster using Mesos & Marathon can be done in 2 minutes.
一但集群开始运行,Meoso master提供了一个Web的接口来显示所有的集群信息。在集群上运行容器的操作类似于Swarm和之间的例子。
相比于Swarm,Mesos的容错性更强,这是因为Mesos能够在JSON文件中对某个应用使用监看检查。因为自动扩展功能是商业版独有的,因此这里集群并不能自动扩展,但是我们还是有其他的办法来实现它,比如说Amazon EC2 Auto Scaling Groups。
Kubernetes
Kubernetes拥有一套命令行管理工具和一个集群启动脚本。Kubernetes也提供了一个用户接口(类似于Mesossphere提供的)[34],但这个接口并没有拆分开来,而是属于调度器的一部分。
我们需要创建一个replication controller来定义pod的容器和pod的最小运行数量。从第一个案例来看,我们可以在一个文件中描述所有集群关于replications的信息。
集群可以通过调度器策略(policies)来扩展,并且Google声明Kubernetes能够支持100个节点,每个几点上有30个pod,每个pod拥有1-2个容器[27]。Kubernetes的性能要比Swarm差,是因为它拥有更加复杂的架构,性能比Mesos差,是因为它结构层次更深(less bare metal),但是很多人在正在努力提升它的性能。
未来要做的
由于我们比较的调度器都比较新颖,暂时还没有可用的基准工具来评价它们之间的扩展性如何。因此,未来还需要在这么一个环境中对比调度器:有多个集群,集群时常出现问题,但是集群间又有大量的连接。
这里对比的调度器主要是用来创建可扩展的Web服务,这个用例要求调度器有高容错性,但是没有提到当处理成千上万容器时,调度器的速度如何。比如说,在关于Mesos&Marathon的可扩展性测试上,并没有具体的数字来说明容器数量。唯一的用例提到了拥有80个节点和640个虚拟CPU的集群。
在同样硬件上对比同样的案例,一个基准程序(benchmark)意味着同一时间段运行的大量节点和应用能够被较为公平的比较。这个新的基准程序能够告诉我们不同调取器在其他案例上的具体信息,比如说批处理。
结论
Docker Swarm是最简单的调取器,它拥有易于理解的策略和过滤器,但是由于它不能处理节点的失败问题,所以在实际的生产环境中,不推荐使用。Swarm和Docker环境很好的结合在一起,它使用了Docker引擎一样的API,并且能够和Docker Compose很好的一起工作,因此它非常适合那些对其他调度器不太了解的开发者。
Swarm非常轻量,并且提供了多个驱动,使得它它能够和未来所有的集群解决方式一起工作[11]。Swarm是一个调度解决方案,非常易于使用,比如它为开发者提供了高纬度的配置方式,让他们能够快速实现具体的工作流。Docker Swarm并没有绑定到某一个具体的云服务提供商,它是完全开源的,并且拥有一个非常强劲的社区。
如果你已经拥有一个Mesos 集群,Mesos & Marathon将会是一个完美的组合方案。它能够像其他Mesos框架一样调度行任务,同时拥有一个类似于Docker Compose的描述文件来制定任务,这些特性使得它成为在集群上运行容器的极佳方案。Mesosphere[45]提供的完整解决方案同样也是一个适合生产环节的、简单而强大的方式。
尽管Kubernetes的逻辑和标准的Docker哲学不同,但是它关于pod和service的概念让开发者在使用容器的同时思考这些容器的组合是什么,真是非常有趣的。Google在它的集群解决方案上[26]提供了非常简单的方式来使用Kubernetes,这使得Kubernetes对于那些已经使用了Google生态环境的开发者来说,是一个合理的选择。
Swarm frontends, © Docker Inc. [6]
容器的调度并不存在一个最佳的方案,从Swarm frontends可以看到[20],这个项目使得Kubernetes和Mesos+Marathon能够部署在Swarm之上,并且它将会逐步支持Cloud Foundry,Nomad,和其他的容器器。具体选择哪个调取器,还是取决于你的需求和集群。
从最后一张图片可以看到,Swarm集群能够被其它调取器管理,其中容器会分配到不同的集群中。这些组合使得容器能够按照你所想的被调度和编排。
Appendix
A — policy-config-file.json
{
"kind": "Policy",
"apiVersion": "v1",
"predicates": [
{
"name": "PodFitsPorts"
},
{
"name": "PodFitsResources"
},
{
"name": "NoDiskConflict"
},
{
"name": "MatchNodeSelector"
},
{
"name": "HostName"
}],
"priorities": [
{
"name": "LeastRequestedPriority",
"weight": 1
},
{
"name": "BalancedResourceAllocation",
"weight": 1
},
{
"name": "ServiceSpreadingPriority",
"weight": 1
},
{
"name": "EqualPriority",
"weight": 1
}]
} B — docker-compose.yml
es:
image: elasticsearch
container_name: "es"
web:
image: prakhar1989/foodtrucks-web
command: python app.py
ports:
- "5000:5000"
volumes:
- .:/codeC — Mesos app definition (Elasticsearch)
{
"id": "es",
"container": {
"type": "DOCKER",
"docker": {
"network": "HOST",
"image": "elasticsearch"
}
}
}D — Appendix — Mesos app definition (Flask)
{
"id": "web",
"cmd": "python app.py",
"cpus": 0.5,
"mem": 64.0,
"instances": 2,
"container": {
"type": "DOCKER",
"docker": {
"image": "prakhar1989/foodtrucks-web",
"network": "BRIDGE",
"portMappings": [
{ "containerPort": 5000, "hostPort": 0, "servicePort": 5000, "protocol": "tcp" }
]
},
"volumes": [
{
"containerPath": "/etc/code",
"hostPath": "/var/data/code",
"mode": "RW"
}
},
"healthChecks": [
{
"protocol": "HTTP",
"portIndex": 0,
"path": "/",
"gracePeriodSeconds": 5,
"intervalSeconds": 20,
"maxConsecutiveFailures": 3
}
]
}E — Kubernetes pod definition
apiVersion: v1
kind: ReplicationController
metadata:
name: app
labels:
name: app
spec:
replicas: 1
selector:
name: app
template:
metadata:
labels:
name: app
spec:
containers:
- name: es
image: elasticsearch
ports:
- containerPort: 6379
- name: web
image: prakhar1989/foodtrucks-web
command:
- python app.py
volumeMounts:
- mountPath: /code
name: code
ports:
- containerPort: 5000
Swarm,Fleet,Kubernetes,Mesos -编排工具的对比
【编者的话】此篇文章是《Using Docker》一书的作者 Adrian Mouat 编写,详细对比分析了Swarm、Fleet、K8s以及Mesos的区别。
大部分软件系统是随时间演进的,新旧功能会交替,不断变化的用户需求意味着一个高效的系统必须能够迅速扩展或收缩资源。为了达到接近零宕机的需求,一个单独的数据中心需要自动地将故障转移到预设的备份系统。
在此之上,一些大型企业经常会运行多个这样的系统或是偶尔需要运行一些独立于主系统的任务,比如数据挖掘,但是又需要更多资源而且需要和现存系统交互。
当使用多个资源时,重要的是确保他们得到有效地使用,而不是被闲置,但还可以应对需求高峰。成本效益与迅速扩展的规模之前的权衡是困难的任务,但是可以用各种方式加以处理。
所有这一切都意味着一个非凡系统的运行充满了各种管理任务、挑战以及不应低估的复杂性。很快在个体层面一个接一个地修补和更新某个机器将变为不可能,他们必须同等对待。当一台机器发生问题时,它应该被摧毁并更换,而不是调养修复后再上线。
当前有各种工具和解决方案能够帮助解决这些挑战,这里主要集中讲解几个编排工具,这些工具能帮助我们以集群方式在主机上启动容器,并能够彼此连接,同时也考虑到了扩展性和自动故障转移的重要特性。
Swarm
Swarm是Docker的原生集群工具,Swarm使用标准的Docker API,这意味着容器能够使用docker run命令启动,Swarm会选择合适的主机来运行容器,这也意味着其他使用Docker API的工具比如Compose和bespoke脚本也能使用Swarm,从而利用集群而不是在单个主机上运行。
Swarm的基本架构很简单:每个主机运行一个Swarm代理,一个主机运行Swarm管理器(在测试的集群中,这个主机也可以运行代理),这个管理器负责主机上容器的编排和调度。Swarm能以高可用性模式(etcd、Consul 或ZooKeeper 中任何一个都可以用来将故障转移给后备管理器处理)运行。当有新主机加入到集群,有几种不同的方式来发现新加的主机,在Swarm中也就是discovery。默认情况下使用的是token,也就是在Docker Hub上会储存一个主机地址的列表。
Fleet
Fleet是一个来自CoreOS的集群管理工具,自诩为“底层的集群引擎”,也就意味着它有望形成一个“基础层”的更高级别的解决方案,如Kubernetes。
Fleet最显著的特点是基于systemd(systemd提供单个机器的系统和服务初始化)建立的,Fleet将其扩展到集群上,Fleet能够读取systemd单元文件,然后调度单个机器或集群。
每个机器运行一个引擎和一个代理,任何时候在集群中只激活一个引擎,但是所有代理会一直运行,Systemd单元文件被提交给引擎,然后在 least-loaded机器上调度任务,单元文件会简单运行一个容器,代理会启动单元和报告状态,Etcd用来激活机器间的通讯以及存储集群和单元的状态。
这个架构用来设计容错的,如果一个机器宕机了,这个机器上的所有单元会在新的主机上被重新启动。
Fleet支持各种调度提示与约束。在最基本的层面,单元的调度可以是全局的:一个实例将在所有机器上运行,或者作为一个单独的单元运行在一台机器上。全局调度对于如日志和监控容器任务非常实用。支持各种关联类型约束,因此,例如规定在应用服务器上运行健康检查的容器。元数据也可以连接到主机用于调度,所以你可以让你的容器在某一区域或某些硬件设备上运行。
由于Fleet是基于systemd的,它也支持socket activation概念;容器可以绑定到一个给定端口的连接响应上。这样做的主要优点是进程可以即时创建而不是闲置等待某些任务。有可能涉及到sockets管理的其他好处,如容器重启的消息不丢失。
Kubernetes
Kubernetes是一个由google基于他们上个世纪容器产品化的经验而推出的容器编排工具,Kubernetes有些固执己见对于容器如何组织和网络强制了一些概念,你需要了解的主要概念有:
- Pods – Pods是容器一起部署与调度的群体。Pods与其他系统的单一容器相比,它组成了Kubernetes中调度的原子单元。Pod通常会包括1-5个一起提供服务的容器。除了这些用户容器,Kubernetes还会运行其他容器来提供日志和监控服务。在Kubernetes中Pods寿命短暂;随着系统的进化他们不断地构建和销毁。
- Flat Networking Space – Kubernetes的网络是跟默认的Docker网络不同。在默认Docker网络中, 容器存在于一个私有子网络中,它需要赚翻主机上的端口或者使用代理才能与其他主机上的容器通讯。在Kubernetes,pod中的容器会分享一个IP地址,但是该地址空间跟所有的pods是“平”的,这意味着所有pods不用任何网络地址转换(NAT)就可以互相通讯。这就使得多主机群集更容易管理,不支持链接的代价使得建立单台主机(更准确地说是单个pod)网络更为棘手。由于在同一个pod中的容器共享一个IP,它们可以通过使用本地主机地址端口进行通信(这并不意味着你需要协调pod内的端口使用)。
- Labels – Labels是附在Kubernetes对象(主要是pods)上用于描述对象的识别特征的键值对,例如版本:开发与层级:前端。通常Labels不是唯一的;它们用来识别容器组。Labels选择器可以用来识别对象或对象组,例如设置所有在前端层的pods与环境设置为
production。使用Labels可以很容易地处理分组任务,例如分配pods到负载均衡组或者在组织之间移动pods。 - Services – Services是通过名称来定位的稳定的节点。Services使用label选择器来连接pods,比如“缓存”Service可以连接到标识为label选择器“type”为“redis”的某些“redis”pods。该service将在这些pods之间自动循环地请求。以这种方式,Services可用于连接一个系统各部件。使用Services会提供一个抽象层,这意味着应用程序并不需要知道他们调用的service的内部细节,例如pods内部运行的应用程序只需要知道调用的数据库service的名称和接口,它不必关心有多少pods组成了那个数据库,或者上次它调用了哪个pod。 Kubernetes会为集群建立一个DNS服务器,用于监视新的services并允许他们在应用程序代码和配置文件中按名称定位。它也可以设置services不指向pods而是指向其他已经存在的services,比如外部API或数据库。
- Replication Controllers - Replication controllers是Kubernetes实例化pods的正常方式(通常情况下,在Kubernetes中不使用Docker CLI)。它们为service来控制和监视运行的pods数量(称为
replicas)。例如,一个replication controller可以负责维持5个Redis的pods的运行。如果一个失败,它会立即启动一个新的。如果replicas的数量减少,它会停止多余的pods。虽然使用Replication Controllers来实例化所有pods会增加一层额外的配置,但是它显著提高容错性和可靠性。
Mesos 和 Marathon
Apache Mesos是一个开源的集群管理器。它是为涉及数百或数千台主机的大规模集群而设计的。 Mesos支持在多租户间分发工作负载,一个用户的Docker容器运行紧接着另一个用户的Hadoop任务。
Apache Mesos始于加州大学伯克利分校的一个项目,用来驱动Twitter的底层基础架构,并且成为许多大公司如eBay和Airbnb的重要工具。后来Mesosphere(共同创办人之一:Ben Hindman - Mesos原始开发人员 )做了很多持续性的Mesos开发和支持工具(如Marathon)。
Mesos的体系结构是围绕高可用性和弹性而设计的。在一个Mesos群集的主要组成部分是:
- Mesos Agent Nodes - 负责实际的运行任务。所有代理向Master提交其可用资源。通常会有数十到上千的节点。
- Mesos Master - 负责给Agents发送任务。它维护一个现有资源的列表并且将此“提供”给Frameworks。Master基于分配策略来决定提供多少资源。通常会有2个或4个备用Master来接替故障的Master。
- ZooKeeper - 用于选择和查找当前Master地址。通常情况下会运行3个或5个ZooKeeper实例以确保可用性和故障处理。
- Frameworks - 与Master协调调度任务到Agent节点。Frameworks由两部分组成:executor进程会运行代理并维护运行的任务以及那些已注册的寄存器,还可以选择使用那些基于来自主机提供的资源。Mesos集群为不同种类的任务可以运行多种Frameworks。用户希望与frameworks交互来提交任务而不是和Mesos交互。
上图中我们可以看到Mesos集群使用framework作为调度器。Marathon调度器使用ZooKeeper来定位当前要提交任务的Mesos master。无论是Marathon调度器还是Mesos master都有备用以便当前master不可用的时候使用。
通常情况下,ZooKeeper,作为Mesos master以及备用,它会运行在同一台主机上。在一个小的集群中,这些主机也可以运行代理,但是更大的集群做这些就不可行,因为它们需要与master通信。Marathon也可以运行在同一个主机上,或者运行在存在于网络边界的独立主机上,而且还可以为客户端形成接入点,从而保持客户端与Mesos集群分离。
Marathon(来自Mesosphere)是为开启、监控以及扩展长期运行应用程序规模而设计的。Marathon启动应用程序的设计是灵活的,它甚至可以启动其他互补的frameworks,如Chronos(数据中心的“cron”)。可以选择使用framework来运行Docker容器,Marathon直接支持这样做。就像我们见过的其他编排架构,Marathon支持各种亲和与约束规则。客户端通过REST API与Marathon交互。其他功能还包括支持健康检查以及可用于与负载平衡器或分析指标交互的事件流。
结论
编排、集群以及管理容器显然有多种选择。话虽如此,但这些选择一般都是高度分化的。在编排方面,我们可以说:
- Swarm具有使用标准Docker接口的优势(及劣势)。虽然这样使得它与现有的工作流程交互起来简单易用,但也可能对于支持更为复杂的定义在定制接口的调度变得更加困难。
- Fleet是底层级的而且相当简单的编排层,它被于运行更高级别的编排工具,例如Kubernetes或者自定义系统。
- Kubernetes是带有服务发现和复制的编排工具。它可能需要重新设计一些现有的应用程序,但是正确地使用可以提供一个可容错和可扩展的系统。
- Mesos是一种底层级、久经沙场的调度器,对于容器的编排,它支持多种frameworks,包括Marathon、Kubernetes、和Swarm。在写这篇文章的时候,Kubernetes和Mesos比Swarm开发的更多以及更为稳定。在规模上,只有Mesos已经证明了支持成百上千个节点的大型系统。但是,对于小的集群比方说,还不到十几个节点的集群,用Mesos可能过于复杂。
借鉴
Swarm,Fleet,Kubernetes,Mesos -编排工具的对比 http://dockone.io/article/823
Docker三剑客:Compose,Machine和Swarm https://blog.csdn.net/wfs1994/article/details/80601027
容器编排工具怎么选 Swarm kubernetes Mesos的优缺点 https://blog.csdn.net/huakai_sun/article/details/79896132
微服务架构 https://www.cnblogs.com/imyalost/p/6792724.html
持续集成,持续交付,持续部署(CI/CD)简介 https://blog.csdn.net/yuanjunliang/article/details/81211684
DevOps详解 https://kb.cnblogs.com/page/567947/
如何理解Devops https://www.cnblogs.com/yibutian/p/9561657.html
在有关微服务、DevOps、Cloud-native、系统部署等的讨论中,蓝绿部署、AB 测试、灰度发布、滚动发布、红黑部署等概念经常被提到,它们有什么区别呢?
http://note.youdao.com/noteshare?id=d84a443c79ab4eaf05bbc1c95053287b&sub=8E6CFF81283F444698D897E0D3E530DA