python学习——pandas基础学习
最基础、最简陋的pandas入门学习
目的是为了记录所使用的方法,帮助我复习
要学好还是要看官方文档传送门
目录
一、常用数据类型
- Series
1.series创建
2.series的属性
3.series切片 - DataFrame
1.DataFrame的创建
2.基本属性与整体情兄查询
3.DataFrame元素的取拿
二、常用的方法
- 排序方法
- 常用统计方法
- 字符事处理方法
- 合并操作
- 分类与聚合
- 空数值处理
- 其他
三、索引和复合索引
8. 简单的索引操作
2. 复合索引
四、时间序列
- 生成一段时间
- 重采样
- PeriodIndex
五、读取文件
一.常用数据类型
I.Series
Series为一维,,基于Numpy的ndarray 结构
数据类型具体为pandas.core.series.Series
1.series创建
pd.Series(data=None, index=None, dtype=None, name=None, copy=False) 方法。其中常用的
data 为所传入数据,此数据可以为numpy中的数组,也可以为python中的列表和字典
index 为索引,可以传入字符串列表
dtype 为data的类型,可以通过传入新的值修改
# 插入numpy数组
t = pd.Series(np.arange(10))
# 插入列表
t = pd.Series([10, 20, 30, 40, 50])
# 插入字典序
d = {'a':10,'b':20,'c':30,'d':40,'e':50}
t = pd.Series(d)
# 示例:
t = pd.Series(np.arange(10), index=list(string.ascii_uppercase[:10]))
2.series的属性
- obj.values值
- obj.index索引
类似于字典
3.series切片
series的索引与切片与numpy的操作类似,唯一的区别就是在对索引的调用

在我自己的运行中发现传入没有事先定义的索引会标错,也就是最后传入的“g”并不会给定结果nan
II.DataFrame
DataFrame为二维,是Series容器。
DataFrame对象既有行索引,又有列索引:
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
1.DataFrame的创建
pd.DataFrame([data, index, columns, dtype, copy])
- 使用字典创建:如果是字典-列表,那么行索引就是从0开始的数字
- 传递data、行索引、列索引,即用函数标准创建
# 两层字典嵌套
d = {'a': {'tp': 2, 'fp': 11},
'b': {'tp': 6, 'fp': 91},
'c': {'tp': 3, 'fp': 4}}
df = pd.DataFrame(d)
# 函数标准创建
df = pd.DataFrame(np.arange(6).reshape(2, 3), index=list("ab"), columns=list("efg"))
2.基本属性与整体情况查询
# 基础属性
df.shape # 行数 列数
df.dtypes # 列数据类型
df.ndim # 数据维度
df.index # 行索引
df.columu # 列索引
df.values # 对象值,二维ndarray数组
# 整体情况查询
df.head(5) # 显示开头几行,默认5行
df.tail(3) # 显示末尾几行,默认5行
df.info() # 相关信息概览:行数、列数、列索引、列非空值个数等等
df.describe() # 快速综合统计结果:计数、均值、标准差、最大值、四分位数、最小值
3.DataFrame元素的取拿
- 大类的索引
- 切片
整个方法和numpy中数组对应的方法一致,但是切片只能作用到行索引而不能作用到列索引,所以需要选择列索引来选择
# 列索引内只能放一个,多了会报错
df[:100][" Count_AnimalName "]
- 使用内置方法
df.loc() 通过标签索引行数据
df.iloc() 通过位置获取行数据
- dt.lit() 实际应用

- dt.ilit() 实际应用
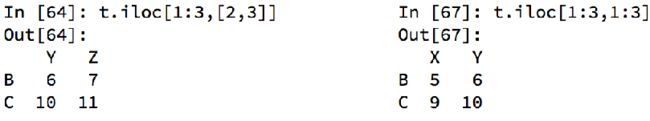
- bool索引
还可用条件与、条件或、条件否
如df_len = df1[(df1[“Row_Labels”].str.len() > 4) & (df1[“Count_AnimalName”] > 700)]
df = pd.DataFrame({'a': range(7),
'b': range(7, 0, -1),
'c': ['one', 'one', 'one', 'two', 'two', 'two', 'two'],
'd': [0, 1, 2, 0, -1, -2, -3]})
print(df)
print("*"*20)
print(df[df["d"] > 0])
print(df["d"] > 0)
# 输出结果
# a b c d
# 0 0 7 one 0
# 1 1 6 one 1
# 2 2 5 one 2
# 3 3 4 two 0
# 4 4 3 two -1
# 5 5 2 two -2
# 6 6 1 two -3
# ********************
# a b c d
# 1 1 6 one 1
# 2 2 5 one 2
0 False
1 True
2 True
3 False
4 False
5 False
6 False
Name: d, dtype: bool
二.常用的方法
1. 排序方法
Series.sort_values(ascending=True)
常用的是ascending,选择排序方式
# 排序方法
t = pd.Series({'ac':10,'b':20,'c':3,'d':12,'e':50})
print(t.sort_values(ascending=True))
# # c 3
# # ac 10
# # d 12
# # b 20
# # e 50
# # dtype: int64
2. 常用统计方法
- 描述性统计
Series.value_counts()
# 计算、描述性统计
t = pd.Series({'ac':10,'b':20,'c':10,'d':12,'e':50})
print(t.value_counts())
# 结果是 值-数量
# 10 2
# 12 1
# 20 1
# 50 1
# dtype: int64
- 统计方法
df["d"].mean() # 平均值
df["d"].max() # 最大值
df["d"].min() # 最小值
df["d"].argmax() # 最大值行索引
df["d"].argmin() # 最小值行索引
df["d"].median() # 中值
3. 字符串处理方法
各方法加个括号直接用,用之前进源码看看怎么传数据

4. 合并操作
- 在df1后面添加与df1行索引相同的df2的列数据
df1.join(df.2,on=None, how=“left”, lsuffix="", rsuffix="", sort=False)
在how中设置数据保存方式,outer保留全部,空余部分用nan填充
df1 = pd.DataFrame({'a': range(3), 'b': range(3, 0, -1)}, index=list("abc"))
df2 = pd.DataFrame({'c': range(4, 0, -1), 'd': range(4)}, index=list("efgh"))
df = df2.join(df1, how='outer', sort=True)
# c d a b
# a NaN NaN 0.0 3.0
# b NaN NaN 1.0 2.0
# c NaN NaN 2.0 1.0
# e 4.0 0.0 NaN NaN
# f 3.0 1.0 NaN NaN
# g 2.0 2.0 NaN NaN
# h 1.0 3.0 NaN NaN
- 与join方法一样的merge方法
on: 需要指定左右两边的某列索引作为参考- on=[" “,” "],指定一个或者两个不同的都可以
- left_on=“a”, right_on=“a”, 方别指定也可以
具体的合并方式由how控制,
合并原理参考笛卡尔积
df1 = pd.DataFrame({'a': range(3), 'b': range(3, 0, -1)})
df2 = pd.DataFrame({'a': range(4, 0, -1), 'd': range(4)})
df = pd.merge(df1, df2, left_on="a", right_on="a", how="outer")
# a b d
# 0 0 3.0 NaN
# 1 1 2.0 3.0
# 2 2 1.0 2.0
# 3 4 NaN 0.0
# 4 3 NaN 1.0
5.分类与聚合
DataFrame.groupby(self, by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False)
- by :映射关系, 函数, 标签或标签列表,可迭代
- axis :0为横向的行, 1为竖向的列, 默认为0,用于区分应用于行数据,还是列数据
- level : 整型, 索引名, 默认是None,多级索引的情况下, 函数或方法应用于哪一级的索引,
- sort :是否排序, 默认为True
- queeze :是否压缩, 默认为False, 可以理解为降维
df = pd.DataFrame([
{'date': '2018-12-01', 'total': 105, 'total2': 133.03},
{'date': '2018-12-01', 'total': 105, 'total2': 2032.13},
{'date': '2018-12-01', 'total': 109, 'total2': 1312.32},
{'date': '2018-12-01', 'total': 109, 'total2': 33120.23},
{'date': '2018-12-02', 'total': 103, 'total2': 13123.23},
{'date': '2018-12-02', 'total': 103, 'total2': 231232.13},
])
grouped = df.groupby(by=['date'])
print(grouped.mean())
可以直接调用的聚合方法

6. 空数值处理
空数值也就是nan,性质与numpy的nan一样
- 判断数据是否为NaN:pd.isnull(df) , pd.notnull(df)
- 处理
- 删除NaN所在的行列:dropna (axis=0, how=‘any’, inplace=False)
- 填充数据: 填入平均值、中值、0
t.fillna(t.mean())
t.fiallna(t.median())
t.fillna(0)
- 处理为0的数据:t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
只是注意计算平均值等情况,nan是不参与计算的,但是0会
7.其他
- contain() 方法,判断是否包含cate该方法解释博客
三.索引和复合索引
1.简单的索引操作
- 获取index:
df.index - 指定index :
df.index = [‘x’,‘y’] - 重新设置index :
df.reindex(list(“abcedf”))
print(df.index)
df.index = [list("abcedfg")]
# 需要接收不能直接在原来的基础上修改
print(df.reindex([list("gfdecba")]))
2.复合索引
1. 设置复合索引
- 一个或者多个列转化为行索引:
df.set_index(“Country”,drop=False)
其中drop为True时删去原有的列 - 行索引转化为一个或者多个列
reset_index(“a”) - 返回index的唯一值:
df.set_index(“Country”).index.unique()
# 把列索引"a"作为行索引,drop为是否保留原来的"a"列
print(df.set_index(["a", "d"], drop=True))
# 不唯一时则返回列表
print(df.set_index(["a", "d"]).index.unique())
# 输出结果索引有顺序区别
print(df.set_index(["a", "c"], drop=True))
print(df.set_index(["c", "a"], drop=True))
2. 读取复合索引
- Series:
s1[“a”][“c”] - DataFrame:
df.loc[“a”].loc[“c”] - 交换内外层索引
x.swaplevel().loc
四.时间序列
数据类型是DatetimeIndex,即:
pandas.core.indexes.datetimes.DatetimeIndex
1.生成一段时间
- df = pd.date_range(start=None, end=None, periods=None, freq=‘D’)
star:开始的时间
end:结束的时间
perids:获取的个数
freq: 获取时间的频率
这个4个主要参数中只能有3个 - df = pd.to_datetime(“20200101”, format="%Y%m%d")
格式化时间,format为传入的格式
重采样
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样
resample方法
有点像group分组
dft = pd.date_range(start="20200101", end="20200201", freq='D')
df = pd.DataFrame(range(32), index=dft)
print(df.resample("10D").mean())
# 0
# 2020-01-01 4.5
# 2020-01-11 14.5
# 2020-01-21 24.5
# 2020-01-31 30.5
3.PeriodIndex
时间段
将Periodindex中的时间数据提取出来,并转化成时间数值列表数据
五.读取文件
在pb.read_ 后面有很多文件类型,读取文件时选择对应的文件类型就好了

举例读取csv中的文件
file_path = "I:/trySomething/python/pandas/fifa/players_15.csv"
df = pd.read_csv(file_path)