Hive知识点总结
以hive 1.2.1版本为例。
1 Hive的安装
1.1 关于Hadoop
首先需要注意的是,Hive是一个基于Hadoop的数据仓库工具。所有要安装Hive,首先需要安装Hadoop。要使用Hive,首先需要保证Hadoop正常运行,然后再使用Hive。
在安装其他组件的时候,一定要注意软件版本的匹配问题。不然会报一堆摸不到头脑的错误。
1.2 关于元数据库
Hive默认的元数据是derby。但是许多人觉得derby不够方便,不如mysql更好,所以一般都将hive的元数据库换成mysql。
换成什么数据库都可以,必须注意的问题是,
1、在目标数据库中应该首先建立一个属于hive的数据库。然后在数据库中设置hive可以访问的权限。这样,在hive启动的时候,就可以使用配置的数据库进行初始化。所谓的初始化,就是hive将自己的元数据信息写入目标数据库。
2、在hive的配置文件中,指定配置数据库的连接信息。
3、还有一点需要注意的是,需要在hive的lib目录下面加入对应的数据库驱动的jar包,这样hive才可以顺利加载对应的类,才可以连接上对应的数据库。
1.3 关于jline
https://blog.csdn.net/windsor575/article/details/50977003?locationNum=1&fps=1
jline的包在hive是2.12版本的,但是在hadoop中是0.x版本的。把hadoop的jline,替换为hive中的jline即可。
2 Hive的体系结构
2.1 用户接口
Hive的用户接口主要有3个,命令行、JDBC和web。
一张经典的结构图。
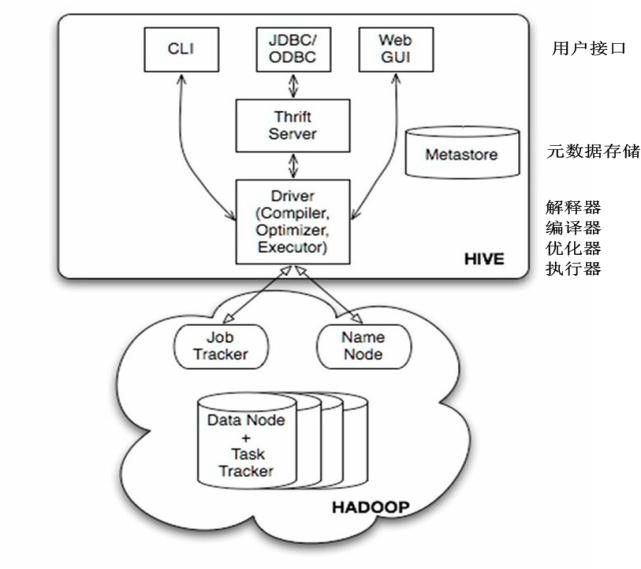
在客户端启动命令行连接hive的时候,该节点会启动一个单独的驱动实例。
Hive的JDBC接口启动时,需要一个Thrift服务。
Hive的元数据存储在指定的数据库中,Hive的数据存储在HDFS上。
Hive的驱动完成HQL语句的词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS上,随后由MapReduce执行。
2.2 Web界面的安装
安装hive软件的包里面是没有web包的。需要自己去下载web的源码包。
1、去下载apache-hive-1.2.1-src.tar.gz.
2、打成war包。将源码解压,将hwi/web目录下面的文件使用jar cvf hive-hwi-1.2.1.war ./*命令打成war包。
3、将打成的war包放入lib目录。具体的位置为${HIVE_HOME}/lib。
4、修改配置。就是修改${HIVE_HOME}/conf/hive-site.xml文件。
指定hwi监听的ip地址,端口号和war包的位置。
就是指定hive.hwi.listen.host、hive.hwi.listen.port、hive.hwi.war.file的属性,hive.hwi.war.file需要指定的位置为相对路径。
5、将${JAVA_HOME}/lib/tools.jar拷贝到${HIVE_HOME}/lib目录下。
6、启动服务。${HIVE_HOME}/bin/hive --service hwi。
7、访问。在浏览器中输入http://localhost:9999/hwi。即可访问。浏览器输入的ip和端口号和第四步中配置的属性一致。并且不要被节点的其他应用使用即可。需要注意的是,一定要在访问的url后面加上hwi才可以。
tips:修改xml完成以后,可以使用xmllint -noout FILENAME来检查修改的xml文件是否有错误。当然这个检查只是xml文件语法层面的。如果你的xml文件配置的属性和值有问题,还是可能检查不出来的。
2.3 命令行的使用
2.3.1 启动hive命令行可以使用的参数
进入hive的命令行,使用hive命令,或者使用hive --service cli,这两者是等价的。
hive -H :显示hive的帮助信息,该命令和hive --help是等效的。
hive -d
比如:
$ hive -d hive.exec.dynamic.partition=truehive --database
$ hive --database defaulthive -e
$ hive -e 'select * from hivetest.test'hive -f
hive --hiveconf
hive -i
hive -S:静默模式,不显示执行的进度,只显示最后的结果。和hive --silent的效果是一样的。
hive -v: 冗余模式,额外打印出执行的HQL语句。和hive --verbose的效果是一样的。
hive -h:连接hostname指定的远程hive服务。
tips 1:hive -f
tips 2:使用命令行时,hive运行时配置参数的优先级。
首先需要知道hive的运行时参数可以在哪几个地方配置。
第一个地方就是${HIVE_HOME}/conf/hive-default.xml文件。
第二个地方是${HIVE_HOME}/conf/hive-site.xml。
第三个地方是启动hive命令行时配置的运行时参数。
第四个地方是在hive中使用set命令设置的运行时参数。
知道了这几个地方,然后就要了解hive的运行。hive运行的时候,首先加载hive的默认配置,就是hive-default.xml文件中的参数。然后加载用户的配置,就是hive-site.xml,然后随着启动命令行时,使用hive --hiveconf
2.3.2 进入命令行可以使用的参数
进入hive的命令行以后,可以使用:
1、quit、exit。退出命令行模式。
2、reset:重置所有的hive运行时配置参数。会将配置参数的值恢复成hive-site.xml文件中的值。
3、set
4、set:输出当前的hive参数设置。和set -v命令是等效的。
5、add FILE[S]/JAR[S]/ARCHIVE[S]
比如使用add jar命令添加一个自定义udf函数。
hive> add jar /home/ancony/udf.jar;6、list FILE[S]/JAR[S]/ARCHIVE[S] :列出分布式缓存中的资源。
7、list FILE[S]/JAR[S]/ARCHIVE[S]
8、delete FILE[S]/JAR[S]/ARCHIVE[S] : 从分布式缓存中删除指定的资源。
9、!
例如列出当前文件夹中的文件:
hive> !ls;10、dfs
11、query :执行一个HQL。
12、source