超参数优化模块神器的实践

作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
在机器学习、深度学习的很多任务中必不可少我们要接触到模型参数调优的工作,这里有很多参数调优的方法,比如最常用最好理解的网格调参,简单带来的就是时间消耗和计算量的增加,今天给大家推荐一款非常不错的超参数优化模块hyperparameter_hunter,我也是最近才接触到的这款神器,实践使用了一下感觉还是很不错的,值得推荐学习一下,这里给出来一些我的学习理解和实践demo。
相应的介绍和说明我都放在代码里面了,可以有选择性地去学习使用,下面是具体的实现内容:
功能:
hyperparameter_hunter 超参数优化模块实践
官方地址:https://github.com/HunterMcGushion/hyperparameter_hunter
文档地址:https://hyperparameter-hunter.readthedocs.io
如何使用HyperparameterHunter:HyperparameterHunter视为另一个优化库,只有在它进行超参数优化时才会显示出来。当然,它会进行优化,但最好将HyperparameterHunter视为个人机器学习工具箱/助手。使用HyperparameterHunter越多,结果就越好。如果你只是用它来进行优化,当然,它会做你想要的,但这就错过了HyperparameterHunter。如果一直在项目的整个过程中使用它进行实验和优化,那么当决定进行超参数优化时,HyperparameterHunter已经记录了已经完成的所有操作,而且当HyperparameterHunter做了非凡的事情时。它不会像其他库一样从头开始优化。它会从已经完成的所有实验和之前的优化轮次开始。
hyperparameter_hunter输出文件结构:HyperparameterHunterAssets / Experiments子目录中,该子目录由experiment_id命名每个实验还会向HyperparameterHunterAssets / Leaderboards / GlobalLeaderboard.csv添加一个条目自定义通过Environment的file_blacklist和do_full_save kwargs创建的文件。
HyperparameterHunterAssets
| Heartbeat.log
|
└───Experiments
| |
| └───Descriptions
| | | .json
| |
| └───Predictions
| | | .csv
| |
| └───Heartbeats
| | | .log
| |
| └───ScriptBackups
| | .py
|
└───Leaderboards
| | GlobalLeaderboard.csv
| | .csv
|
└───TestedKeys
| | .json
|
└───KeyAttributeLookup
|
个人理解:
#!usr/bin/env python
#encoding:utf-8
from hyperparameter_hunter import Environment, CVExperiment, BayesianOptPro, Integer, Real, Categorical
from hyperparameter_hunter import optimization as opt
from hyperparameter_hunter.utils.learning_utils import get_breast_cancer_data
from xgboost import XGBClassifier
import os
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import StratifiedKFold
from keras.wrappers.scikit_learn import *
from keras.callbacks import *
from keras.layers import *
from sklearn.svm import LinearSVC
from sklearn.ensemble import *
#结果数据存储路径
resDir='demoResult/'
if not os.path.exists(resDir):
os.makedirs(resDir)
def func1():
'''
环境使用
hyperparameter_hunter的实例化都是从环境的创建初始化开始的
'''
data = load_breast_cancer()
df = pd.DataFrame(data=data.data, columns=data.feature_names)
df['target'] = data.target
env = Environment(
train_dataset=df,
results_path=resDir,
metrics=['roc_auc_score'], #sklearn.metrics 相关的指标都可以
cv_type=StratifiedKFold, #sklearn.model_selection 相关的策略都可以
cv_params=dict(n_splits=5, shuffle=True, random_state=32)
)
def func2():
'''
独立实验分析【XGBClassifier分类器模型+环境】
'''
data = load_breast_cancer()
df = pd.DataFrame(data=data.data, columns=data.feature_names)
df['target'] = data.target
env = Environment(
train_dataset=df,
results_path=resDir,
metrics=['roc_auc_score'], #sklearn.metrics 相关的指标都可以
cv_type=StratifiedKFold, #sklearn.model_selection 相关的策略都可以
cv_params=dict(n_splits=5, shuffle=True, random_state=32)
)
experiment = CVExperiment(
model_initializer=XGBClassifier,
model_init_params=dict(objective='reg:linear',
max_depth=3, n_estimators=100, subsample=0.5)
)
def build_fn(input_shape):
'''
Keras模型参数定义模块
'''
model = Sequential([Dense(100, kernel_initializer='uniform', input_shape=input_shape,
activation='relu'), Dropout(0.5),
Dense(1, kernel_initializer='uniform', activation='sigmoid')])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
def func3():
'''
独立实验分析【KerasClassifier分类器模型+环境】
'''
data = load_breast_cancer()
df = pd.DataFrame(data=data.data, columns=data.feature_names)
df['target'] = data.target
env = Environment(
train_dataset=df,
results_path=resDir,
metrics=['roc_auc_score'], #sklearn.metrics 相关的指标都可以
cv_type=StratifiedKFold, #sklearn.model_selection 相关的策略都可以
cv_params=dict(n_splits=5, shuffle=True, random_state=32)
)
experiment = CVExperiment(
model_initializer=KerasClassifier,
model_init_params=build_fn,
model_extra_params=dict(
callbacks=[ReduceLROnPlateau(patience=5)],
batch_size=32, epochs=10, verbose=0
)
)
def func4():
'''
独立实验分析【SKLearn模型+环境】
'''
data = load_breast_cancer()
df = pd.DataFrame(data=data.data, columns=data.feature_names)
df['target'] = data.target
env = Environment(
train_dataset=df,
results_path=resDir,
metrics=['roc_auc_score'], #sklearn.metrics 相关的指标都可以
cv_type=StratifiedKFold, #sklearn.model_selection 相关的策略都可以
cv_params=dict(n_splits=5, shuffle=True, random_state=32)
)
experiment = CVExperiment(
model_initializer=LinearSVC,
model_init_params=dict(penalty='l2', C=0.9)
) ##这里可以换成自己想用的模型模型对应的参数配置信息
def build_fn_opt(input_shape):
'''
Keras模型参数定义模块【调优】
'''
model = Sequential([
Dense(Integer(50, 150), input_shape=input_shape, activation='relu'),
Dropout(Real(0.2, 0.7)),
Dense(1, activation=Categorical(['sigmoid', 'softmax']))
])
model.compile(
optimizer=Categorical(['adam', 'rmsprop', 'sgd', 'adadelta']),
loss='binary_crossentropy', metrics=['accuracy']
)
return model
def func5():
'''
超参数优化
'''
data = load_breast_cancer()
df = pd.DataFrame(data=data.data, columns=data.feature_names)
df['target'] = data.target
env = Environment(
train_dataset=df,
results_path=resDir,
metrics=['roc_auc_score'],
cv_type=StratifiedKFold,
cv_params=dict(n_splits=5, shuffle=True, random_state=32)
)
optimizer = opt.RandomForestOptPro(iterations=7)
optimizer.forge_experiment(
model_initializer=KerasClassifier,
model_init_params=build_fn_opt,
model_extra_params=dict(
callbacks=[ReduceLROnPlateau(patience=Integer(5, 10))],
batch_size=Categorical([32, 64]),
epochs=10, verbose=0
)
)
optimizer.go()
def func6():
'''
超参数优化
'''
data = load_breast_cancer()
df = pd.DataFrame(data=data.data, columns=data.feature_names)
df['target'] = data.target
env = Environment(
train_dataset=df,
results_path=resDir,
metrics=['roc_auc_score'],
cv_type=StratifiedKFold,
cv_params=dict(n_splits=5, shuffle=True, random_state=32)
)
optimizer = opt.DummyOptPro(iterations=42)
optimizer.forge_experiment(
model_initializer=AdaBoostClassifier, # (Or any of the dozens of other SKLearn algorithms)
model_init_params=dict(
n_estimators=Integer(75, 150),
learning_rate=Real(0.8, 1.3),
algorithm='SAMME.R'
)
)
optimizer.go()
if __name__ == '__main__':
func1()
func2()
func3()
func4()
func5()
func6()这里我们以func1()为例简单进行说明,这个模块的使用与我以往使用到的模块有所不同, 以往的模块在执行完成计算之后都会有大量的结果输出,这里是没有的,func1的运行结果如下所示:
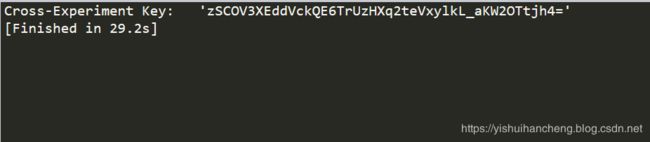
运行结束后,代码的统计目录多了demoResult文件夹,进入文件夹后的文件截图如下所示:

进入HyperparameterHunterAssets文件夹后的文件截图如下所示:

进入KeyAttributeLookup文件夹后的文件截图如下所示:

可以看到,这个模块与以往模块不同点,它不仅在模型的每次训练计算过程中会保存交叉验证试验的参数数据和评价指标数据,还保存下来了本次模型训练所用的数据集【存储在train_dataset文件夹中】,这个对于复现实验来说是非常有帮助的。
简单看了一下官方的教程和说明,发现该模块还有一个很强大的地方在于:如果使用该模块有一定的时间积累后, 模型的参数优化会越来越快,因为它不会像简单笨拙的网格调参一样,每次都是从头开始计算,因为它会在每次实验结束后保存实验的相关数据,在参数优化计算的过程中它会从上一次最优的参数开始计算,个人感觉这一点就是比较强大的了。
至于更多地功能后面会再找时间去挖掘和实践,今天就先到这里!
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击成为社区注册会员 「在看」一下,一起PY