Kotlin lambda学习
Table of Contents
什么是 Lambda?
Lambda 使用
在作用域中访问变量
成员引用
集合中使用 lambda
filter 和 map
all、any、count 和 find
groupBy:将列表转为分组
flatMap 和 flatten:处理嵌套集合
序列
创建序列
和 java 一起工作的 lambda
将 lambda 手动转换为函数式接口
with 和 apply
小结
什么是 Lambda?
Lambda 简答来说就是一小段代码块,并且我们可以将这个代码块在函数之间传递,这是函数式编程的一个重要特性。通常我们会需要一个函数,但是又不想定义一个函数那么费事,这个时候就可以使用 lambda 表达式来完成工作。这就是 lambda 函数,概念清晰简单。
Java 8 中非常重要的一个特性就是引入了 lambda,这受到广大工程师的热烈欢迎。为什么 Lambda 如此受欢迎,下面我们来一一解释下。
Lambda 使用
让我们先看一个例子,在 java 的开发中,通常会见到下面的代码:
button.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View view) {
// 点击后执行的动作
}
});对于这样的代码,我们早已司空见惯,习以为常,觉得这样的代码没啥毛病。但是,如果你看到 Lambda 版本的代码的话,可能就不这么想了:
button.setOnClickListener {
// 点击之后的操作
}看到没,是不是清爽很多了?下面我们就来看下在 kotlin 中的 lambda 的语法:
{ x: Int, y: Int -> x + y }上面的形式就是 kotlin 中定义个 lambda 的形式,有如下要点:
- lambda 始终被花括号包围
- 实参不用括号包围
- 使用箭头将参数列表和代码块分隔开
对于如上定义的 lambda,我们在 kotlin 中可以如下方式来使用:
val sum = { x: Int, y: Int -> x + y }我们可以定义个变量来保存 lambda,然后就像调用函数那样调用 lambda。另外你也可以直接调用 lambda:
println({ x: Int, y: Int -> x + y }(1, 2))不要怀疑,确实可以这样使用,lambda 后面的括号在 kotlin 中被称为 invoke 机制。
接下来,我们看一个例子来学习一下 lambda 的更多用法。
假设我们需要重一个人员列表中找到年龄最大的那一位,在 kotlin 中使用 lambda 可以如下实现:
val personList = listOf(
Person("Jack", 18),
Person("Tom", 19),
Person("Jim", 24))
val oldestPerson = personList.maxBy({ p: Person -> p.age })这里我们借用 kotlin 系统提供的集合扩展函数 maxBy 来实现查找,通过查看 maxBy 函数的定义我们知道,我们需要给它传递一个 lambda 即可,因此上面我们给他传递一个 lambda,这个 lambda 的类型是:
(Person) -> Int也即是将一个 Person 对象转换为 Int 类型,方便比较大小。因为我们是要找年龄最大的,因此我们只要将 Person 对象转为年龄值就行。
上面的调用虽然一目了然,但是确实有点啰嗦。首先过多的标点符号破坏了可读性,其次类型可以从上下文中推断出来,我们不用明显声明这是 Person 类型,最后这种情况下我们不需要给 lambda 分配一个参数名称,因为我们只有一个。
在kotlin 中有这样的约定,如果 lambda 表达式是函数的最后一个实参,他可以放到括号的外面,因此上面的调用简化如下:
val oldestPerson = personList.maxBy(){ p: Person -> p.age }当 lambda 是唯一的实参时,连圆括号都可以省略:
val oldestPerson = personList.maxBy { p: Person -> p.age }因为 lambda 表达式中的实参 Person 类型可以从 personList 中推断出来,因此我们还可以简化:
val oldestPerson = personList.maxBy { it.age }这里使用 it 表达形式,it 是 person 对象在 lambda 中的迭代元素,可以简单理解为:it 就是 personList 中的每一个 person 对象的代表。
以上四种形式功能完成等同,但是最后一种可读性是最好的,是最具有 kotlin style 的。
但是如果你有两个以上的 lambda 参数需要传递,那么你只能把最后一个 lambda 放到括号外面。通常这种情况下,常规的语法形式是比较好的选择。
到目前位置,我们看到的 lambda 都是单语句的形式,但是 lambda 中可以有多个语句,这种情况下,最后一个表达式的值就是 lambda 的结果,比如:
val sum = { x: Int, y: Int ->
println("hello world.")
x + y
}上面我们看到了 lambda 的基本用法,下面我们看下和 lambda 表达式息息相关的概念:从上下文中捕捉变量。
在作用域中访问变量
我们知道,lambda 的主要使用场景是在函数之间传递。假如我们将 lambda 作为参数传递给一个函数,然后我们在 lambda 中需要访问函数中定义的局部变量,例如参数,怎么办呢?在 kotlin 中,没关系,你可以直接访问。
为了说明,我们使用 kotlin 库函数中最常使用的 forEach 来展示这种行为,forEach 是最基本的集合操作函数之一,它需要一个 lambda 表达式,然后针对集合中的每一个元素都执行该表达式。下面是使用例子:
data class Person(val name: String, val age: Int)
fun main() {
val personList = listOf(
Person("Jack", 18),
Person("Tom", 19),
Person("Jim", 24))
printNames(personList, "Name")
}
fun printNames(personList: Collection, prefix: String) {
personList.forEach {
println("$prefix: ${it.name}")
}
} 在这个例子中,我们可以看到 kotlin 和 java 的一个显著区别就是,在 kotlin 中不会仅限于访问 final 类型的变量,我们在 lambda 中可以自由地访问参数变量。同时 lambda 不仅可以访问,还可以修改函数的局部变量值:
fun printNames(personList: Collection, prefix: String) {
var count = 0
personList.forEach {
count++
println("$prefix: ${it.name} at $count")
}
} 这里定义的非 final 变量 count,我们可以在 lambda 中自由访问,并且修改值。
从 lambda 中访问外部变量,在 kotlin 中称为 lambda 捕捉。在上面的例子中,forEach 中的 lambda 捕捉了 prefix 和 count 两个局部变量。
在默认情况下,函数局部变量的声明周期是限制在这个函数的内部的,一旦函数运行结束,这个变量在内存中也就是消失了。但是如果它被 lambda 捕捉了,使用这个变量的代码可以被存储并稍后在执行。这背后的原理很简单,就是被捕捉的值和 lambda 代码一起被存储了起来。对于 final 变量(val 类型)来说,他的值和使用的 lambda 一起存储起来;而对于非 final(var 类型)的变量来说,他的值被封装在一个特殊的包装器中,这样你就可以改变这个值,而这个包装器对象的引用就是一个 final 变量,它会和 lambda 一起被存储。
我们知道 kotlin 是可以运行在 jvm 上面的,因此在 jvm 这个层面上没有任何魔法。既然在 java 中不能在函数的匿名内部类对象访问非 final 类型的变量,那么 kotlin 是如何做到访问非 final 类型的变量呢?答案就在变量的包装类中,这个包装类的实现差不多如下:
class Ref (var value: T) 使用这样的包装类将数据包装起来,然后将这个包装类的对象引用变为 final 类型的,这个时候我们就可以在兼容 jvm 的同时又可以访问非 final 类型的变量了。
需要注意的是,如果 lambda 被用作事件处理器或者用在其他异步执行的情况,对布局的修改只会在 lambda 执行的时候发生,因此我们不可以使用如下的代码来统计按钮被点击的次数:
fun countClick(button: Button): Int {
var count = 0
button.onClick { count++ }
return count
}因为这里的 count 的累加操作是按钮被点击的时候才会触发的,所以这个函数每次调用都会返回 0。
成员引用
我们已经看到 lambda 是如何让你把代码块作为参数传递给函数,但是我们想要用作参数传递的代码已经被定义成了函数,这个时候我们怎么办呢?当然,我们可以传递一个调用这个函数的 lambda,但是这样显得有点蠢。在 kotlin 中提供了类似 C 中的解决方案,我们可以类似 C 中那样,使用一个变量来保存函数名称,然后访问这个变量就可以来访问这个函数了。例如:
// 定义函数
fun testFun() {
println("hello from funtion.")
}
// 引用函数
val funRef = ::testFun
// 通过引用调用函数
funRef()需要说明的是,当我们引用函数的时候,需要使用 :: 的形式来访问,这种表达式在 kotlin 中称为「成员引用」,它的使用方式如下:
className::fieldName or funName使用方式非常简单,需要说明是双冒号后面可以是字段名称或者函数名称,因为字段其实对应了该字段的 getter 访问器。
重要的是,成员引用和调用该函数的 lambda 具有一样的类型,所以刚才我们寻找年龄最大的例子可以写成这样:
personList.maxBy(Person::age)这里针对 age 字段的成员引用相当于上面我们使用的 lambda 表达式。当然,上面的例子还可以写成这样:
personList.maxBy{ Person::name.get(it) }但是这样又啰嗦,又麻烦,没有必要。
当我们引用顶层函数(不是类成员)的时候,我们可以省略双冒号前面的部分,就像上面我们引用 testFun 函数那样。
构造方法作为一个特殊的函数,我们页可以引用,如下:
val createPerson = ::Person
val person = createPerson("CreateChance", 26)我们还可以引用扩展函数:
fun Person.isAdult() = age >= 18
val predicate = Person::isAdult尽管 isAdult 不是 Person 类的成员,还是可以通过引用来访问的。
这里我们需要问一个问题,当我们使用成员引用的方式创建变量类型是什么呢?引用字段和函数的类型分别如下:
KPropertyN
FunctionN 这两种类型都是 kotlin 内置的类型,其中 KProperty 是一种字段的反射类型, FunctionN 中的 N 表示具体的数字,范围:0 ~ 22,表示参数的个数,定义在 kotlin.jvm.functions.Functions.kt 中。
集合中使用 lambda
Lambda 为我们操作集合提供了极大的方便,配合方便的系统库函数我们可以使用区区几行代码完成复杂的功能。需要说明的是,下面我们介绍的函数并不是 kotlin 特有的,而是 kotlin 从其他支持函数式编程的语言中借鉴过来的。
filter 和 map
filter 和 map 函数是操作集合的最基本的函数,很多复杂的功能都是从这两个函数出发的。
filter 函数的功能就是将一个列表通过一个判断条件将列表中符合条件的元素留下,将留下的组成一个新的列表返回,它的签名如下:
fun Iterable.filter(predicate: (T) -> Boolean): List filter 函数是列表类的拓展函数,它的参数只需要一个将范型类型 T 转为 Boolean 类型的 lambda,然后返回是一个新的列表。
使用也很简单,一个简单的例子,还是以我们之前的 personList 为例,如果我们想从其中过滤出成年人,可以如下操作:
val personList = listOf(
Person("Jack", 16),
Person("Tom", 19),
Person("Jim", 24))
val adultList = personList.filter { it.age >= 18 }可以看到,操作十分简单,我们只要将判断年龄是不是超过 18 岁的判断 lambda 传递给 filter 函数即可完成。
filter 函数可以将列表中你不关心的元素全部剔除出去,但是不会改变列表中的值,如果需要改变列表中的元素值就需要使用 map 函数了。
map 函数意思就是转换,就是通过一个规则将一个元素转为另外一个元素,这个规则就是 lambda 表达式,我们看下 kotlin 中 map 函数的定义:
fun Iterable.map(transform: (T) -> R): List map 函数的参数依然是一个 lambda,这个 lambda 将一个 T 类型的数据转换为 R 类型的数据。
如果我们想要从 personList 列表中获取所有人的名称列表,可以如下操作:
val personList = listOf(
Person("Jack", 16),
Person("Tom", 19),
Person("Jim", 24))
val nameList = personList.map { it.name }这样我们就会得到一个 List
如果我们想要输出所有成年人的名字,那么我们可以综合 filter 和 map 两个函数:
val personList = listOf(
Person("Jack", 16),
Person("Tom", 19),
Person("Jim", 24))
val adultNameList = personList.filter { it.age >= 18 }.map { it.name }这一个链式调用看是来是不是很爽啊~
在使用链式调用的时候,切记不要在 lambda 中嵌入另外一个列表操作函数,因为这样很低效。假如我们需要找到 personList 中所有年龄最大人的名字列表,下面分别展示的低效和高效的做法:
// 低效的
var oldestNameList = personList.filter { it.age == personList.maxBy(Person::age)?.age ?: 0 }.map(Person::name)
// 高效的
val oldestAge = personList.maxBy(Person::age)?.age ?: 0
oldestNameList = personList.filter { it.age == oldestAge }.map(Person::name)低效的方法之所以低效,是因为在 filter 的 lambda 参数中又调用了 maxBy 函数,这会导致每次 filter 的时候都会找一次最大的年龄!而高效的做法是,首先找到最大的年龄值,然后在 filter 的时候直接使用这个值,不用每查找。
all、any、count 和 find
一种比较常见的任务就是查看集合中的所有元素是否符合某个条件,在 kotlin 中我们可以通过 all 和 any 来完成,count 用来表示有多少个满足条件,find 表示查找第一个符合条件的元素。
比如我们需要在 personList 中查看大家是不是都成年了,可以这样:
val isAllAdult = personList.all { it.age >= 18 }all 函数用来查看列表中的所有元素是不是满足指定的条件,它的定义如下:
fun Iterable.all(predicate: (T) -> Boolean): Boolean 我们需要提供一个 lambda 来指定判断条件,lambda 将一个 T 类型转为 Boolean 类型,然后结果返回一个 Boolean 类型表示是否满足条件。
或者我们需要查看 personList 中是否至少存在一个元素满足我们的条件,比如我们看看这个列表中是否有成年人:
val hasAdult = personList.any { it.age >= 18 }any 函数用来判断列表中是否至少存在一个元素满足指定的条件,它的定义如下:
fun Iterable.any(predicate: (T) -> Boolean): Boolean 定义看起来和 all 差不多,我们需要指定一个 lambda,lambda 将一个 T 类型转为 Boolean 类型,然后结果返回一个 Boolean 类型表示是否满足条件。
注意,!any 表示「不是所有」,可以使用 any 加上相反的条件等价替换。
如果我们想知道列表中有多少元素满足条件,可以使用 count 函数,假设我们想要知道列表中有多人已经成年:
val numberOfAdults = personList.count { it.age >= 18 }count 用来查找列表中满足条件的元素个数,它的定义如下:
fun Iterable.count(predicate: (T) -> Boolean): Int 我们需要提供一个条件 lambda,这个 lambda 将一个 T 类型转为 Boolean 类型,然后返回一个 Int 类型表示满足的个数。
有的时候,我们可以使用列表的 size 方法来替代 count,例如上面我们查找列表中多少人已经成年,可以这样完成:
val numberOfAdults = personList.filter { it.age >= 18 }.size这种方式也能完成我们的工作,但是并不是很高效。因为这种方式会生成一个新的列表,我们是查看这个新的列表的 size 来获取成年人的数量的,但是 count 就不会。通常而言,count 只关心数量不关心具体的元素数据,size 是关心具体数据的。我们需要根据具体的需求,来确定使用哪种方式完成工作。
上面我们介绍的 all、any 和 count 都是返回是否满足条件或者满足条件的的元素格式,如果我们想要获得满足条件的第一个元素的话,可以使用 find 函数,假如我们想要找到第一个成年人的信息:
val firstAdult = personList.find { it.age >= 18 }find 函数用来查找列表中第一个满足条件的元素,它的定义如下:
fun Iterable.find(predicate: (T) -> Boolean): T? 这里我们需要提供一个条件 lambda,lambda 将一个 T 类型转为 Boolean 类型,结果返回一个 T 类型。注意,这里返回的是一个 T 类型的可空类型,因为我们有可能找不到满足条件的元素,因此下面在使用的时候需要注意可空类型的判断。
groupBy:将列表转为分组
groupBy 函数,从名字上就可以看出,它是通过某个条件将列表进行分组的函数。因此,从本质上讲,groupBy 也是一种 map,这种 map 的输入是一个集合,输出的是一个或者多个集合。
例如,我们将 personList 按照年龄段进行分组,成年的一组,未成年的一组:
val personList = listOf(
Person("Jack", 16),
Person("Tom", 19),
Person("Jim", 24))
val groupedPerson = personList.groupBy { it.age >= 18 }这里如果我们打印 groupedPerson 的话可以看到:
{false=[Person(name=Jack, age=16)], true=[Person(name=Tom, age=19), Person(name=Jim, age=24)]}groupedPerson 是一个 map 集合,其中 key 为 Boolean 类型,value 类型为列表。其中 true 字段的列表表示成年人的列表,false 字段的列表表示未成年人的列表。
groupBy 函数接受一个条件 lambda,并且将指定的列表按照这个条件进行分组,它的定义如下:
fun Iterable.groupBy(keySelector: (T) -> K): Map> 我们指定一个条件 lambda,这个 lambda 将一个 T 类型转为 K 类型,并且返回一个 K 为 key ,T 为 value 的map。
flatMap 和 flatten:处理嵌套集合
flatMap 的概念稍微抽象点,我们从一个例子出发,假如我们手上有一个字符串的列表,现在我们想要获得这个列表中所有字符串中字母组成的列表,我们可以这样完成:
val strings = listOf("abc", "def")
val letterList = strings.flatMap { it.toList() }
println(letterList)
运行输出:
[a, b, c, c, d, e, f]我们首先将字符串列表中的每一个字符串都转为字符列表,这样我们就可以得到两个列表,然后再将这两个列表进行拼接,这个操作就是 flatMap 的操作。
flatMap 可以将一个列表的列表进行「打平」操作,也就是将列表的列表变成列表。这么说有点费劲,我们可以将列表的列表想象成列表的数组,在空间上是二维的,通过 flatMap 操作可以将这个二维的数组转为一字排开的一位数组,如下图:
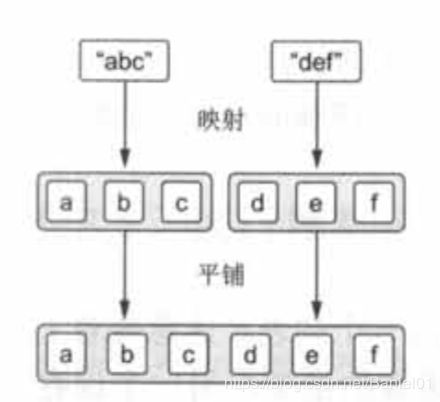
从上图中可以看出,flatMap 函数包含两种操作:先 map 后 flat。 首先是 map 映射操作,通过 map 操作将列表转换为目标列表的中间状态,然后通过 flat 平铺操作将列表进行拼接。
flatMap 函数的定义如下:
fun Iterable.flatMap(transform: (T) -> Iterable): List 我们需要指定一个 lambda,这个 lambda 将一个 T 类型转为 R 类型的列表,然后返回一个拼接好的 R 列表。
这里我们举个实际的例子,我们从一个书籍列表中输出所有作者姓名的集合 Set:
val bookList = listOf(
Book("BookA", listOf("Jack", "Tom")),
Book("BookB", listOf("Tim", "BiShop")),
Book("BookC", listOf("Jack", "BiShop"))
)
val authorsSet = bookList.flatMap { it.authors }.toSet()
println(authorsSet)运行结果:
[Jack, Tom, Tim, BiShop]有的时候,我们不需要 map 操作,只想要 flat 的「打平」操作,我们可以使用 flatten 函数,例如:
val listOfList = listOf(
"hello".toList(),
"world".toList(),
"nice to meet you".toList())
val flattenList = listOfList.flatten()
println(flattenList)运行结果:
[h, e, l, l, o, w, o, r, l, d, n, i, c, e, , t, o, , m, e, e, t, , y, o, u]这里只是简单的 flat 操作,并没有任何 map 操作。
序列
前面我们使用了很多链式操作集合的例子,例如 filter 和 map 函数。这些函数都会尽早地创建中间集合,也就是说每一步的中间结果都会存放在一个临时的列表中,这无形之间增加了内存的开销。
在 kotlin 中我们还有另外一种选择:序列。使用序列可以避免创建这些临时中间对象的开销,先看个例子:
val personList = listOf(
Person("Jack", 16),
Person("Tom", 19),
Person("Jim", 24))
val adultNamesList = personList.asSequence()
.filter {
it.age >= 18
}
.map {
it.name
}
.toList()
println(adultNamesList)运行结果:
[Tom, Jim]还是那个例子,我们在 personList 中寻找成年人的名字列表。这次我们使用了 asSequence 函数先将列表转换为序列,然后使用同样的操作完成查找,最后我们使用 toList 函数将序列再次转换为列表返回。
在 kotlin 中,序列的另一个名字就是惰性集合,它的入口就是 Sequence 接口,定义如下:
public interface Sequence {
/**
* Returns an [Iterator] that returns the values from the sequence.
*
* Throws an exception if the sequence is constrained to be iterated once and `iterator` is invoked the second time.
*/
public operator fun iterator(): Iterator
} 这个接口中只定义了一个方法,kotlin 框架通过这个方法来获得可以迭代操作的迭代器,然后次序进行流式操作。
Sequence 的真正强大之处,就在于它不会创建中间结果,它的内存开销是比较小的,尤其是当列表及其巨大的时候优势十分明显。当你的列表十分巨大的时候,你可以考虑下序列操作。
现在我们来看一个问题,就是序列为什么叫「惰性集合」?为了说明问题,我们修改下上面的例子代码:
val personList = listOf(
Person("Jack", 16),
Person("Tom", 19),
Person("Jim", 24))
val adultNamesList = personList.asSequence()
.filter {
println("Age: ${it.age}")
it.age >= 18
}
.map {
println("Map: ${it.name}")
it.name
}
println(adultNamesList)运行结果:
kotlin.sequences.TransformingSequence@6d311334什么?这里只是得到了一个对象,日志没有任何输出?这说明了什么?这说明这里的序列压根儿就没有执行!那咋么让他执行呢?只要在 map 调用后面调用 toList 函数即可。现在你明白为什么序列叫「惰性集合」了吧!
序列的操作分为两种:
- 中间操作
- 结尾操作
上面的 filter 和 map 等等操作都是中间操作,只有 toList 操作才是结尾操作。toList 是结尾操作并不是因为他在最后一个,而是因为只有调用了它真个序列才能开始工作,可以将 toList 函数理解为整个序列的消费者,只有这个消费者出现了,才会真正地开始生产。
我们再次看下开始的那个例子的输出:
Age: 16
Age: 19
Map: Tom
Age: 24
Map: Jim
[Tom, Jim]如果你足够细心的话,你会发现列表中的第一个 person 对象并没有执行到 map 这一步,因为他不满足 filter 操作的条件。在序列中,如果上一步的操作将某些元素剔除了,后续的操作是不会执行的,因为没有执行的必要了。
因此,我们可以得出一个初步的结论:尽早执行 filter 操作,将一些不满足条件的元素排除,减少执行的时间。
创建序列
上面我们通过一些列表的 asSequence 函数来生成序列,除此之外,我们还可以通过 generateSequence 函数来直接生成序列:
val seq = generateSequence(0) { it + 1 }
println(seq)
val numbersTo100 = seq.takeWhile { it <= 100 }
println(numbersTo100)
println(numbersTo100.sum())执行结果:
kotlin.sequences.GeneratorSequence@568db2f2
kotlin.sequences.TakeWhileSequence@2d98a335
5050第一步我们通过 generateSequence 来生成一个从 0 开始不断加 1 的序列生成器,然后我们使用 takeWhile 函数来生成一个 0 ~ 100 的序列,最后我们使用 sum 函数作为结尾操作驱动整个序列开始工作,将每一个值进行加和,我们得到正确结果:5050。
下面我们在看一个更加实际的例子,我们根据一个 File 对象来判断他是不是在隐藏目录下,我们如下做:
// 定一个 File 扩展函数
fun File.isInHiddenFolder() = generateSequence(this) { it.parentFile }.any { it.isHidden }
// 使用定义的函数判断
val testFile = File(".idea", "misc.xml")
println(testFile.isInHiddenFolder())这里我使用 android studio 中的工程文件目录 .idea 目录下的文件做测试,运行结果:
true和 java 一起工作的 lambda
在实际的项目中,我们的很多的代码还是使用 java 编写的,因此 kotlin 中的 lambda 肯定不可避免地要和 java api 打交道。
在 android 中,我们通常会给一个 button 绑定一个点击监听器,这在 kotlin 中可以如下完成:
val button = Button(context)
button.setOnClickListener { v: View? -> println("I'm clicked!") }这里我们使用了一个 lambda 来替代传统 java 中的新建匿名内部类对象的方式。之所以能这么调用的原因是 OnClickLisntener 接口只有一个方法,这种接口被称为「函数式接口」,或者 SAM(Single Abstract Method)接口。在 Java 中可以看到很多这类型的接口,例如 Runnable、Callable 等等。
我们可以将 lambda 传递给任何期望函数式接口对象的方法,假设我们有这样一个 Java 方法:
public void doSomethingLater(long delay, Runnable task)在 kotlin 中我们可以这样调用:
doSomeThingLater(1000) { println("Running task......") }这里的第二个参数我们直接传递了一个 lambda,kotlin 编译器会自动把它转换为一个 Runnable 的实例,这个实例的 run 方法执行体就是 lambda 的执行体。
当然,我们还可以这样调用:
doSomeThingLater(1000, object : Runnable {
override fun run() {
println("Running task......")
}
})虽然效果一样,但是在本质上是有区别的。当你显示地创建对象的时候,每次调用的时候都会生成一个新的 Runnable 实例。而使用 lambda 则不同,如果 lambda 没有捕捉任何函数中的变量的话,那么这个匿名实例是可以在多次调用之间重用的,可以减少对象创建的开销。
我们前面提到了每一个 lambda 都会由 kotlin 编译器来创建一个对象,现在我们通过反编译 kotlin 代码来看下,在 android studio 中可以在 tools 中 选择 Show Kotlin Bytecode 来查看 kotlin 字节码,然后点击 Decompile 按钮可以看到对应的 java 代码。上面的调用:
fun withJava() {
val javaApi = JavaApi()
javaApi.doSomeThingLater(1000) { println("Running task......") }
}其中 JavaApi 是 java 提供的一个 api 实现,我们不必关心,我们看下这段代码对应的代码:
L0
LINENUMBER 71 L0
NEW com/createchance/newtechdemo/kotlin/lambda/JavaApi
DUP
INVOKESPECIAL com/createchance/newtechdemo/kotlin/lambda/JavaApi. ()V
ASTORE 0
L1
LINENUMBER 72 L1
ALOAD 0
LDC 1000
// 这里使用了 lambda 的实例
GETSTATIC com/createchance/newtechdemo/kotlin/lambda/MainKt$withJava$1.INSTANCE : Lcom/createchance/newtechdemo/kotlin/lambda/MainKt$withJava$1;
CHECKCAST java/lang/Runnable
INVOKEVIRTUAL com/createchance/newtechdemo/kotlin/lambda/JavaApi.doSomeThingLater (JLjava/lang/Runnable;)V
L2
LINENUMBER 79 L2
RETURN
L3
LOCALVARIABLE javaApi Lcom/createchance/newtechdemo/kotlin/lambda/JavaApi; L1 L3 0
MAXSTACK = 4
MAXLOCALS = 1
@Lkotlin/Metadata;(mv={1, 1, 15}, bv={1, 0, 3}, k=2, d1={"\u0000\n\n\u0000\n\u0002\u0010\u0002\n\u0002\u0008\u0002\u001a\u0006\u0010\u0000\u001a\u00020\u0001\u001a\u0006\u0010\u0002\u001a\u00020\u0001\u00a8\u0006\u0003"}, d2={"main", "", "withJava", "app_debug"})
// access flags 0x18
// lambda 实例定义
final static INNERCLASS com/createchance/newtechdemo/kotlin/lambda/MainKt$withJava$1 null null
// compiled from: Main.kt 我们可以看到这里 lambda 对应了 MainKt$withJava$1 这类的实例,这个类就是我们的 lambda 对应的实现类,我们使用的时候是用的 MainKt$withJava$1.INSTANCE 这种形式来访问的,这里可以看到这个类是单例实现的,也就是说这个实例会在多次调用的时候复用。
如果我们不想每一个 lambda 都创建一个新的类,我们可以将这个函数声明为 inline 的,其实很多系统框架也是这么做的。
将 lambda 手动转换为函数式接口
SAM 构造方法是在编译时生成的函数,让你可以自动完成将 lambda 转换为函数式接口的实现实例。可是有的时候,你需要一个方法来返回某个函数式接口的实现,然后在上下文中使用。这种情况下不能直接返回一个 lambda,因为 kotlin 编译器的转换操作是内部屏蔽的,你只能被动使用,不能主动使用。这是我们可以使用 kotlin 编译器为我们生成的 SAM 构造方法来完成,还是以上面的那个例子:
// 定义函数
fun getTask(): Runnable {
return Runnable {
println("Running task......")
}
}
// 通过定义的函数获取执行任务
doSomeThingLater(1000, getTask())注意,我们的 Runnable 是一个接口,本质上是没有构造方法的,我们这里使用了 kotlin 为 SAM 接口生成的构造函数来生成实例的。
在 android 中我们可以利用这个特性,完成多个 button 的点击事件的绑定:
// 定义监听器
val listener = View.OnClickListener{v: View ->
val text = when(v.id) {
R.id.button1 -> "Button1"
R.id.button2 -> "Button2"
else -> "Unknown"
}
toast(text)
}
// 绑定监听器
button1.setOnClickListener(listener)
button2.setOnClickListener(listener)listener 会检查点击的来源,然后根据来源的不同作出不同的动作,这里利用了 SAM 构造方法实现了更加简洁的代码。
这里需要注意的是,lambda 内部没有匿名对象那样的 this,没有办法拿到 lambda 转换后实例的 this,kotlin 将这一切屏蔽了。所以,如果你还需要在 listener 内部反注册自己是做不到的。
with 和 apply
with 和 apply 函数是两个非常有用的标准库函数,利用这两个函数我们可以在 lambda 函数体内调用一个不同对象的方法,并且无需借用任何额外限定符,这样的功能在 java 中是很难实现的。
我们从 with 函数开始,还是以创建 personList 列表为例,我们可以如下创建列表:
val personList = mutableListOf()
with(personList) {
add(Person("Jack", 16))
add(Person("Tom", 19))
add(Person("Jim", 24))
println(this)
} 我们首先创建一个空的列表,然后使用 with 函数拿着这个空的列表,在 with 的lambda 参数中,我们直接调用列表的方法,仿佛就在列表类的内部一样,最后我们打印列表输出,注意我们打印的时候使用的对象是 this,这里的 this 表示列表。
我们看下 with 函数的定义:
fun with(receiver: T, block: T.() -> R): R with 函数接受两个参数,第一个是接受者对象,第二个是接受者类型转为 R 类型的 lambda,返回一个 R 类型结果。
这里的 lambda 作用于第一个接受者对象上,然后 lambda 表达式的值就是 with 函数的返回值。
所以我们如果想要知道前面创建的列表是不是一个人数较多的列表,我们可以这样:
val isBiggerList = with(personList) {
add(Person("Jack", 16))
add(Person("Tom", 19))
add(Person("Jim", 24))
println(this)
size > 4
}这里的 isBiggerList 的类型是一个 Boolean 类型,因为 lambda 的最后一句话的值是 Boolean 类型的。
有的时候你想要是接受者对象作为返回,而不是 lambda 执行的结果,这时你就可以使用 apply 函数了。
apply 的使用几乎和 with 函数一样,唯一的区别就在于返回值。with 函数返回值是 lambda 表达式的值,而 apply 返回的是它的接受者对象。
现在,我们使用 apply 来构建刚才的 personList:
val personList = mutableListOf().apply {
add(Person("Jack", 16))
add(Person("Tom", 19))
add(Person("Jim", 24))
println(this)
} 还是首先创建了一个空的列表,然后在这个列表上调用 apply 函数,然后 lambda 中的执行方式和 with 是一样的,最后 apply 返回了一个新建的 personList。
现在看下 apply 的定义:
fun T.apply(block: T.() -> Unit): T 可以看到,定义和 with 的却别就是少了 receiver 参数,因为 apply 在哪个对象上调用,哪个对象就是它的接收者。同时,我们注意到了,apply 函数是一个指定范型 T 的扩展函数,这使得我们可以在任意的对象上调用 apply 函数!
apply 在很多时候用于对象的初始化上,比如在 android 中,如果我们初始化一个 TextView 对象的话,我们可以这样:
TextView(context).apply {
text = "This is text view."
textSize = 20f
setTextColor(Color.RED)
textLocale = Locale.CHINA
}这种代码简单易懂,易于阅读。
小结
- lambda 允许你吧代码当作参数传递给函数
- kotlin 可以把 lambda 放在括号外面传递给函数,而且可以使用 it 引用单个 lambda 参数
- lambda 中的代码可以访问和修改包含这个 lambda 调用的函数中的变量
- 通过在函数名称前加上 :: ,可以创建方法、构造方法及属性的引用,并用这些引用代替 lambda 传递给函数
- 使用 filter、map、app、any等函数,大多数公共的集合操作不需要手动迭代元素就能完成操作
- 序列允许你合并一个集合上的多次操作,而不需要创建新的集合来保存中间结果
- 可以把 lambda 作为参数传递给接收 java 函数式接口(SAM 接口)的方法
- 带接收者的 lambda 是一种特殊的 lambda,可以在这种 lambda 中直接访问一个特殊接收者对象的方法
- with 标准库函数允许你调用一个对象的多个方法,而不需要反复写出这个对象的引用。apply 函数让你使用构建者风格的 API 创建和初始化任何对象