猫狗分类-kaggle数据集-小型卷积网络
猫狗分类
- 猫狗分类-(小型卷积神经网络-6层)
- 数据准备
- 数据集目录结构
- 网络模型
- 数据预处理
- 训练(利用生成器拟合模型)-30轮
- 训练可视化
- 数据增强
- 增加dropout层,防止过拟合
- 经过数据增强和增加dropout层后再拟合-100轮
- 结果
- 总结
- 参考:
猫狗分类-(小型卷积神经网络-6层)
数据来源:Kaggle在2013年公开的猫狗数据集,该数据集总共25000张图片,猫狗各12500张。
下载链接:https://www.kaggle.com/c/dogs-vs-cats/data
数据准备
import os,shutil
original_dataset_diar = '/home/u/notebook_workspase/datas/dogs-vs-cats/train'#原始数据解压目录
base_dir = '/home/u/notebook_workspase/datas/dogs-cats-small-dataset'#自己保留的小数据集
os.mkdir(base_dir)
#划分后的train,validation,test目录
train_dir = os.path.join(base_dir,'train')#将多个路径组合后返回
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')
os.mkdir(test_dir)
#猫和狗的train,validation,test图像目录
train_cats_dir = os.path.join(train_dir,'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir,'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
os.mkdir(test_dogs_dir)
# 复制1000猫到训练目录中
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_diar,fname)
dst = os.path.join(train_cats_dir,fname)
shutil.copyfile(src,dst)
# 500张猫的验证图片,依次类推
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_diar,fname)
dst = os.path.join(validation_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_diar,fname)
dst = os.path.join(test_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_diar,fname)
dst = os.path.join(train_dogs_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_diar,fname)
dst = os.path.join(validation_dogs_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_diar,fname)
dst = os.path.join(test_dogs_dir,fname)
shutil.copyfile(src,dst)
print(len(os.listdir(train_cats_dir)))
1000
print(len(os.listdir(train_dogs_dir)))
1000
print(len(os.listdir(validation_cats_dir)))
500
print(len(os.listdir(validation_dogs_dir)))
500
print(len(os.listdir(test_cats_dir)))
500
print(len(os.listdir(test_dogs_dir)))
500
数据集目录结构
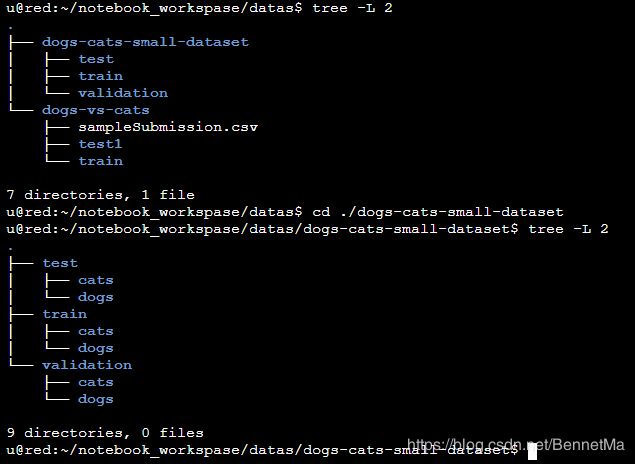
网络模型
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(150,150,3)))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu',))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu',))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
Using TensorFlow backend.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
# 编译
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr = 1e-4),
metrics=['acc'])
数据预处理
将像素图片信息转换成浮点数张量,对图片大小进行调整
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir, # 目标目录
target_size=(150, 150), # 所有图像调整为150x150
batch_size=20,
class_mode='binary') # 二进制标签
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
训练(利用生成器拟合模型)-30轮
history = model.fit_generator(
train_generator,#python 生成器
steps_per_epoch=100,#100批次
epochs=30,
validation_data=validation_generator,
validation_steps=50)
Epoch 1/30
100/100 [==============================] - 24s 242ms/step - loss: 0.6895 - acc: 0.5360 - val_loss: 0.6784 - val_acc: 0.5800
Epoch 2/30
100/100 [==============================] - 24s 240ms/step - loss: 0.6687 - acc: 0.5900 - val_loss: 0.6786 - val_acc: 0.5640
Epoch 3/30
100/100 [==============================] - 24s 240ms/step - loss: 0.6403 - acc: 0.6240 - val_loss: 0.6405 - val_acc: 0.6220
Epoch 4/30
100/100 [==============================] - 24s 239ms/step - loss: 0.5942 - acc: 0.6900 - val_loss: 0.6305 - val_acc: 0.6220
Epoch 5/30
100/100 [==============================] - 24s 239ms/step - loss: 0.5524 - acc: 0.7170 - val_loss: 0.5780 - val_acc: 0.6980
Epoch 6/30
100/100 [==============================] - 24s 241ms/step - loss: 0.5211 - acc: 0.7380 - val_loss: 0.5681 - val_acc: 0.6990
Epoch 7/30
100/100 [==============================] - 24s 240ms/step - loss: 0.4850 - acc: 0.7605 - val_loss: 0.5977 - val_acc: 0.6950
Epoch 8/30
100/100 [==============================] - 24s 241ms/step - loss: 0.4586 - acc: 0.7830 - val_loss: 0.5704 - val_acc: 0.6940
Epoch 9/30
100/100 [==============================] - 24s 240ms/step - loss: 0.4260 - acc: 0.8070 - val_loss: 0.6525 - val_acc: 0.6660
Epoch 10/30
100/100 [==============================] - 24s 241ms/step - loss: 0.4002 - acc: 0.8090 - val_loss: 0.5683 - val_acc: 0.7160
Epoch 11/30
100/100 [==============================] - 24s 240ms/step - loss: 0.3780 - acc: 0.8335 - val_loss: 0.5480 - val_acc: 0.7360
Epoch 12/30
100/100 [==============================] - 24s 242ms/step - loss: 0.3463 - acc: 0.8535 - val_loss: 0.5492 - val_acc: 0.7370
Epoch 13/30
100/100 [==============================] - 24s 241ms/step - loss: 0.3184 - acc: 0.8695 - val_loss: 0.6162 - val_acc: 0.7220
Epoch 14/30
100/100 [==============================] - 24s 240ms/step - loss: 0.2958 - acc: 0.8720 - val_loss: 0.5597 - val_acc: 0.7500
Epoch 15/30
100/100 [==============================] - 24s 241ms/step - loss: 0.2705 - acc: 0.8885 - val_loss: 0.6376 - val_acc: 0.7270
Epoch 16/30
100/100 [==============================] - 24s 241ms/step - loss: 0.2544 - acc: 0.8950 - val_loss: 0.6072 - val_acc: 0.7450
Epoch 17/30
100/100 [==============================] - 24s 243ms/step - loss: 0.2280 - acc: 0.9115 - val_loss: 0.6055 - val_acc: 0.7360
Epoch 18/30
100/100 [==============================] - 24s 242ms/step - loss: 0.2038 - acc: 0.9225 - val_loss: 0.6182 - val_acc: 0.7350
Epoch 19/30
100/100 [==============================] - 24s 241ms/step - loss: 0.1780 - acc: 0.9425 - val_loss: 0.6381 - val_acc: 0.7340
Epoch 20/30
100/100 [==============================] - 24s 242ms/step - loss: 0.1610 - acc: 0.9365 - val_loss: 0.7002 - val_acc: 0.7380
Epoch 21/30
100/100 [==============================] - 24s 242ms/step - loss: 0.1458 - acc: 0.9490 - val_loss: 0.7561 - val_acc: 0.7380
Epoch 22/30
100/100 [==============================] - 24s 241ms/step - loss: 0.1279 - acc: 0.9530 - val_loss: 0.7437 - val_acc: 0.7180
Epoch 23/30
100/100 [==============================] - 24s 242ms/step - loss: 0.1125 - acc: 0.9620 - val_loss: 0.8394 - val_acc: 0.7170
Epoch 24/30
100/100 [==============================] - 24s 242ms/step - loss: 0.0994 - acc: 0.9660 - val_loss: 0.8185 - val_acc: 0.7300
Epoch 25/30
100/100 [==============================] - 24s 243ms/step - loss: 0.0820 - acc: 0.9765 - val_loss: 0.9172 - val_acc: 0.7300
Epoch 26/30
100/100 [==============================] - 24s 241ms/step - loss: 0.0715 - acc: 0.9795 - val_loss: 0.9022 - val_acc: 0.7380
Epoch 27/30
100/100 [==============================] - 24s 241ms/step - loss: 0.0570 - acc: 0.9855 - val_loss: 0.9709 - val_acc: 0.7210
Epoch 28/30
100/100 [==============================] - 24s 241ms/step - loss: 0.0561 - acc: 0.9810 - val_loss: 0.9760 - val_acc: 0.7240
Epoch 29/30
100/100 [==============================] - 24s 240ms/step - loss: 0.0489 - acc: 0.9870 - val_loss: 1.1146 - val_acc: 0.7170
Epoch 30/30
100/100 [==============================] - 24s 242ms/step - loss: 0.0371 - acc: 0.9880 - val_loss: 1.0006 - val_acc: 0.7390
model.save('cat-dog-small-1.h5')#保存模型
训练可视化
import matplotlib.pyplot as plt
%matplotlib inline
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(1,len(acc)+1)
plt.plot(epochs,acc,'bo',label = 'Training acc')
plt.plot(epochs,val_acc,'b',label = 'Validation acc')
plt.title('Training and validation accuracy')
plt.legend()#显示标签
plt.figure()
plt.plot(epochs,loss,'bo',label = 'Training loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title("Training and validation loss")
plt.legend()
plt.show()

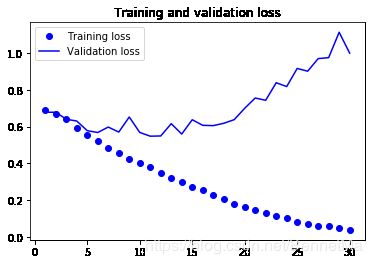
数据增强
datagen = ImageDataGenerator(
rotation_range=40, # 图像随机旋转的角度范围
width_shift_range=0.2, # 水平或垂直平移范围,相对总宽度或总高度的比例的比例
height_shift_range=0.2,
shear_range=0.2, # 随机错切变换角度换角度
zoom_range=0.2, # 随机缩放范围
horizontal_flip=True, # 一半图像水平翻转
fill_mode='nearest' # 填充新创建像素的方法
)
from keras.preprocessing import image#图像预处理工作的模块
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
img_path = fnames[3] # 选择一张图片进行增强
img = image.load_img(img_path, target_size=(150, 150)) # 读取图像并调整大小
x = image.img_to_array(img) # 形状转换为(150,150,3)的Numpy数组
x = x.reshape((1,) + x.shape)
i = 0
# 生成随机变换后图像批量,循环是无限生成,也需要我们手动指定终止条件
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()


增加dropout层,防止过拟合
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(150,150,3)))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu',))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu',))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))#droput层
model.add(layers.Dense(512,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr = 1e-4),
metrics=['acc'])
经过数据增强和增加dropout层后再拟合-100轮
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1./255) # 验证集不用增强
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50
)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Epoch 1/100
100/100 [==============================] - 38s 380ms/step - loss: 0.6900 - acc: 0.5275 - val_loss: 0.6996 - val_acc: 0.5076
Epoch 2/100
100/100 [==============================] - 38s 378ms/step - loss: 0.6808 - acc: 0.5622 - val_loss: 0.6590 - val_acc: 0.5850
Epoch 3/100
100/100 [==============================] - 38s 378ms/step - loss: 0.6648 - acc: 0.5938 - val_loss: 0.6516 - val_acc: 0.5984
Epoch 4/100
100/100 [==============================] - 38s 378ms/step - loss: 0.6458 - acc: 0.6209 - val_loss: 0.6017 - val_acc: 0.6681
Epoch 5/100
100/100 [==============================] - 38s 378ms/step - loss: 0.6165 - acc: 0.6559 - val_loss: 0.6296 - val_acc: 0.6339
Epoch 6/100
100/100 [==============================] - 38s 383ms/step - loss: 0.6096 - acc: 0.6622 - val_loss: 0.6326 - val_acc: 0.6390
Epoch 7/100
100/100 [==============================] - 38s 381ms/step - loss: 0.6025 - acc: 0.6731 - val_loss: 0.5814 - val_acc: 0.6827
Epoch 8/100
100/100 [==============================] - 38s 383ms/step - loss: 0.5904 - acc: 0.6881 - val_loss: 0.5842 - val_acc: 0.6840
Epoch 9/100
100/100 [==============================] - 38s 379ms/step - loss: 0.5795 - acc: 0.7019 - val_loss: 0.5563 - val_acc: 0.7138
Epoch 10/100
100/100 [==============================] - 38s 384ms/step - loss: 0.5790 - acc: 0.6966 - val_loss: 0.5558 - val_acc: 0.7157
Epoch 11/100
100/100 [==============================] - 38s 385ms/step - loss: 0.5757 - acc: 0.7025 - val_loss: 0.5203 - val_acc: 0.7354
Epoch 12/100
100/100 [==============================] - 38s 383ms/step - loss: 0.5617 - acc: 0.7106 - val_loss: 0.5224 - val_acc: 0.7430
Epoch 13/100
100/100 [==============================] - 38s 384ms/step - loss: 0.5537 - acc: 0.7109 - val_loss: 0.5642 - val_acc: 0.7056
Epoch 14/100
100/100 [==============================] - 38s 382ms/step - loss: 0.5558 - acc: 0.7213 - val_loss: 0.5112 - val_acc: 0.7354
Epoch 15/100
100/100 [==============================] - 38s 382ms/step - loss: 0.5424 - acc: 0.7175 - val_loss: 0.5241 - val_acc: 0.7424
Epoch 16/100
100/100 [==============================] - 38s 381ms/step - loss: 0.5413 - acc: 0.7287 - val_loss: 0.5520 - val_acc: 0.6992
Epoch 17/100
100/100 [==============================] - 38s 384ms/step - loss: 0.5379 - acc: 0.7237 - val_loss: 0.4994 - val_acc: 0.7519
Epoch 18/100
100/100 [==============================] - 38s 385ms/step - loss: 0.5231 - acc: 0.7353 - val_loss: 0.5167 - val_acc: 0.7392
Epoch 19/100
100/100 [==============================] - 38s 380ms/step - loss: 0.5260 - acc: 0.7391 - val_loss: 0.4932 - val_acc: 0.7627
Epoch 20/100
100/100 [==============================] - 38s 384ms/step - loss: 0.5163 - acc: 0.7447 - val_loss: 0.5080 - val_acc: 0.7430
Epoch 21/100
100/100 [==============================] - 39s 385ms/step - loss: 0.5140 - acc: 0.7441 - val_loss: 0.4786 - val_acc: 0.7627
Epoch 22/100
100/100 [==============================] - 38s 381ms/step - loss: 0.5182 - acc: 0.7447 - val_loss: 0.4706 - val_acc: 0.7728
Epoch 23/100
100/100 [==============================] - 38s 384ms/step - loss: 0.5219 - acc: 0.7444 - val_loss: 0.4658 - val_acc: 0.7665
Epoch 24/100
100/100 [==============================] - 39s 387ms/step - loss: 0.5085 - acc: 0.7534 - val_loss: 0.4738 - val_acc: 0.7646
Epoch 25/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4974 - acc: 0.7525 - val_loss: 0.4935 - val_acc: 0.7621
Epoch 26/100
100/100 [==============================] - 39s 386ms/step - loss: 0.5058 - acc: 0.7509 - val_loss: 0.4741 - val_acc: 0.7709
Epoch 27/100
100/100 [==============================] - 38s 383ms/step - loss: 0.5000 - acc: 0.7534 - val_loss: 0.4685 - val_acc: 0.7722
Epoch 28/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4850 - acc: 0.7613 - val_loss: 0.5037 - val_acc: 0.7430
Epoch 29/100
100/100 [==============================] - 38s 380ms/step - loss: 0.5006 - acc: 0.7556 - val_loss: 0.4832 - val_acc: 0.7646
Epoch 30/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4967 - acc: 0.7641 - val_loss: 0.4926 - val_acc: 0.7551
Epoch 31/100
100/100 [==============================] - 38s 381ms/step - loss: 0.4820 - acc: 0.7756 - val_loss: 0.4464 - val_acc: 0.7995
Epoch 32/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4812 - acc: 0.7647 - val_loss: 0.4561 - val_acc: 0.7900
Epoch 33/100
100/100 [==============================] - 38s 383ms/step - loss: 0.4702 - acc: 0.7719 - val_loss: 0.4407 - val_acc: 0.8008
Epoch 34/100
100/100 [==============================] - 38s 379ms/step - loss: 0.4872 - acc: 0.7594 - val_loss: 0.4652 - val_acc: 0.7906
Epoch 35/100
100/100 [==============================] - 39s 386ms/step - loss: 0.4808 - acc: 0.7625 - val_loss: 0.4555 - val_acc: 0.7862
Epoch 36/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4796 - acc: 0.7688 - val_loss: 0.4382 - val_acc: 0.7912
Epoch 37/100
100/100 [==============================] - 38s 383ms/step - loss: 0.4508 - acc: 0.7859 - val_loss: 0.4970 - val_acc: 0.7570
Epoch 38/100
100/100 [==============================] - 38s 380ms/step - loss: 0.4689 - acc: 0.7856 - val_loss: 0.5921 - val_acc: 0.7265
Epoch 39/100
100/100 [==============================] - 38s 383ms/step - loss: 0.4558 - acc: 0.7812 - val_loss: 0.4416 - val_acc: 0.7931
Epoch 40/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4583 - acc: 0.7850 - val_loss: 0.5170 - val_acc: 0.7506
Epoch 41/100
100/100 [==============================] - 39s 386ms/step - loss: 0.4608 - acc: 0.7734 - val_loss: 0.4385 - val_acc: 0.8090
Epoch 42/100
100/100 [==============================] - 38s 383ms/step - loss: 0.4542 - acc: 0.7909 - val_loss: 0.4886 - val_acc: 0.7678
Epoch 43/100
100/100 [==============================] - 38s 380ms/step - loss: 0.4517 - acc: 0.7869 - val_loss: 0.4325 - val_acc: 0.8001
Epoch 44/100
100/100 [==============================] - 38s 383ms/step - loss: 0.4531 - acc: 0.7800 - val_loss: 0.4700 - val_acc: 0.7912
Epoch 45/100
100/100 [==============================] - 38s 384ms/step - loss: 0.4426 - acc: 0.7837 - val_loss: 0.4365 - val_acc: 0.7931
Epoch 46/100
100/100 [==============================] - 38s 381ms/step - loss: 0.4481 - acc: 0.7913 - val_loss: 0.4306 - val_acc: 0.8033
Epoch 47/100
100/100 [==============================] - 38s 380ms/step - loss: 0.4460 - acc: 0.7935 - val_loss: 0.4442 - val_acc: 0.7874
Epoch 48/100
100/100 [==============================] - 38s 383ms/step - loss: 0.4287 - acc: 0.7991 - val_loss: 0.4348 - val_acc: 0.8084
Epoch 49/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4377 - acc: 0.7984 - val_loss: 0.4195 - val_acc: 0.8084
Epoch 50/100
100/100 [==============================] - 38s 385ms/step - loss: 0.4309 - acc: 0.8006 - val_loss: 0.4137 - val_acc: 0.8058
Epoch 51/100
100/100 [==============================] - 38s 384ms/step - loss: 0.4348 - acc: 0.7959 - val_loss: 0.4420 - val_acc: 0.7874
Epoch 52/100
100/100 [==============================] - 38s 385ms/step - loss: 0.4260 - acc: 0.8072 - val_loss: 0.4242 - val_acc: 0.8122
Epoch 53/100
100/100 [==============================] - 38s 379ms/step - loss: 0.4165 - acc: 0.8109 - val_loss: 0.4257 - val_acc: 0.8198
Epoch 54/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4220 - acc: 0.8075 - val_loss: 0.5893 - val_acc: 0.7221
Epoch 55/100
100/100 [==============================] - 39s 386ms/step - loss: 0.4106 - acc: 0.8069 - val_loss: 0.4268 - val_acc: 0.8065
Epoch 56/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4111 - acc: 0.8062 - val_loss: 0.5441 - val_acc: 0.7538
Epoch 57/100
100/100 [==============================] - 38s 382ms/step - loss: 0.4129 - acc: 0.8091 - val_loss: 0.4482 - val_acc: 0.7963
Epoch 58/100
100/100 [==============================] - 38s 385ms/step - loss: 0.4062 - acc: 0.8088 - val_loss: 0.4665 - val_acc: 0.7773
Epoch 59/100
100/100 [==============================] - 38s 381ms/step - loss: 0.4165 - acc: 0.8053 - val_loss: 0.4314 - val_acc: 0.8033
Epoch 60/100
100/100 [==============================] - 38s 380ms/step - loss: 0.4103 - acc: 0.8069 - val_loss: 0.3969 - val_acc: 0.8192
Epoch 61/100
100/100 [==============================] - 38s 383ms/step - loss: 0.4030 - acc: 0.8200 - val_loss: 0.4414 - val_acc: 0.7760
Epoch 62/100
100/100 [==============================] - 38s 383ms/step - loss: 0.3964 - acc: 0.8119 - val_loss: 0.4476 - val_acc: 0.8027
Epoch 63/100
100/100 [==============================] - 38s 379ms/step - loss: 0.4014 - acc: 0.8141 - val_loss: 0.4013 - val_acc: 0.8306
Epoch 64/100
100/100 [==============================] - 38s 385ms/step - loss: 0.4007 - acc: 0.8181 - val_loss: 0.4153 - val_acc: 0.8287
Epoch 65/100
100/100 [==============================] - 39s 385ms/step - loss: 0.4067 - acc: 0.8156 - val_loss: 0.3896 - val_acc: 0.8217
Epoch 66/100
100/100 [==============================] - 39s 386ms/step - loss: 0.4067 - acc: 0.8109 - val_loss: 0.4179 - val_acc: 0.8096
Epoch 67/100
100/100 [==============================] - 38s 383ms/step - loss: 0.3868 - acc: 0.8213 - val_loss: 0.4078 - val_acc: 0.8160
Epoch 68/100
100/100 [==============================] - 39s 386ms/step - loss: 0.3939 - acc: 0.8178 - val_loss: 0.4518 - val_acc: 0.7881
Epoch 69/100
100/100 [==============================] - 38s 383ms/step - loss: 0.3888 - acc: 0.8150 - val_loss: 0.4129 - val_acc: 0.8198
Epoch 70/100
100/100 [==============================] - 38s 383ms/step - loss: 0.3969 - acc: 0.8216 - val_loss: 0.4260 - val_acc: 0.8154
Epoch 71/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3791 - acc: 0.8262 - val_loss: 0.4023 - val_acc: 0.8217
Epoch 72/100
100/100 [==============================] - 39s 385ms/step - loss: 0.3710 - acc: 0.8284 - val_loss: 0.3893 - val_acc: 0.8357
Epoch 73/100
100/100 [==============================] - 38s 383ms/step - loss: 0.3962 - acc: 0.8150 - val_loss: 0.4341 - val_acc: 0.8058
Epoch 74/100
100/100 [==============================] - 39s 386ms/step - loss: 0.3727 - acc: 0.8341 - val_loss: 0.4034 - val_acc: 0.8274
Epoch 75/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3810 - acc: 0.8156 - val_loss: 0.4382 - val_acc: 0.8160
Epoch 76/100
100/100 [==============================] - 39s 385ms/step - loss: 0.3875 - acc: 0.8184 - val_loss: 0.4864 - val_acc: 0.7906
Epoch 77/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3717 - acc: 0.8269 - val_loss: 0.4506 - val_acc: 0.7906
Epoch 78/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3754 - acc: 0.8275 - val_loss: 0.4060 - val_acc: 0.8338
Epoch 79/100
100/100 [==============================] - 38s 379ms/step - loss: 0.3764 - acc: 0.8284 - val_loss: 0.4460 - val_acc: 0.7728
Epoch 80/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3608 - acc: 0.8347 - val_loss: 0.3987 - val_acc: 0.8299
Epoch 81/100
100/100 [==============================] - 39s 386ms/step - loss: 0.3670 - acc: 0.8362 - val_loss: 0.4359 - val_acc: 0.8154
Epoch 82/100
100/100 [==============================] - 38s 380ms/step - loss: 0.3786 - acc: 0.8288 - val_loss: 0.4325 - val_acc: 0.8046
Epoch 83/100
100/100 [==============================] - 38s 381ms/step - loss: 0.3759 - acc: 0.8313 - val_loss: 0.4142 - val_acc: 0.8160
Epoch 84/100
100/100 [==============================] - 38s 379ms/step - loss: 0.3577 - acc: 0.8400 - val_loss: 0.4096 - val_acc: 0.8261
Epoch 85/100
100/100 [==============================] - 38s 383ms/step - loss: 0.3427 - acc: 0.8544 - val_loss: 0.4037 - val_acc: 0.8312
Epoch 86/100
100/100 [==============================] - 38s 381ms/step - loss: 0.3692 - acc: 0.8384 - val_loss: 0.4221 - val_acc: 0.8255
Epoch 87/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3533 - acc: 0.8475 - val_loss: 0.4291 - val_acc: 0.8135
Epoch 88/100
100/100 [==============================] - 38s 382ms/step - loss: 0.3543 - acc: 0.8475 - val_loss: 0.4662 - val_acc: 0.8058
Epoch 89/100
100/100 [==============================] - 38s 382ms/step - loss: 0.3548 - acc: 0.8447 - val_loss: 0.4602 - val_acc: 0.8103
Epoch 90/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3567 - acc: 0.8413 - val_loss: 0.4759 - val_acc: 0.7963
Epoch 91/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3466 - acc: 0.8481 - val_loss: 0.3770 - val_acc: 0.8407
Epoch 92/100
100/100 [==============================] - 38s 382ms/step - loss: 0.3392 - acc: 0.8472 - val_loss: 0.4025 - val_acc: 0.8338
Epoch 93/100
100/100 [==============================] - 38s 377ms/step - loss: 0.3377 - acc: 0.8503 - val_loss: 0.4343 - val_acc: 0.8255
Epoch 94/100
100/100 [==============================] - 38s 383ms/step - loss: 0.3385 - acc: 0.8525 - val_loss: 0.4129 - val_acc: 0.8090
Epoch 95/100
100/100 [==============================] - 38s 381ms/step - loss: 0.3457 - acc: 0.8516 - val_loss: 0.4227 - val_acc: 0.8128
Epoch 96/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3503 - acc: 0.8403 - val_loss: 0.4037 - val_acc: 0.8376
Epoch 97/100
100/100 [==============================] - 38s 379ms/step - loss: 0.3298 - acc: 0.8584 - val_loss: 0.4056 - val_acc: 0.8293
Epoch 98/100
100/100 [==============================] - 38s 385ms/step - loss: 0.3392 - acc: 0.8556 - val_loss: 0.4208 - val_acc: 0.8357
Epoch 99/100
100/100 [==============================] - 38s 384ms/step - loss: 0.3345 - acc: 0.8528 - val_loss: 0.4641 - val_acc: 0.8185
Epoch 100/100
100/100 [==============================] - 38s 381ms/step - loss: 0.3374 - acc: 0.8516 - val_loss: 0.3796 - val_acc: 0.8382
model.save('cat-dog-small-2.h5')
结果
import matplotlib.pyplot as plt
%matplotlib inline
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(1,len(acc)+1)
plt.plot(epochs,acc,'bo',label = 'Training acc')
plt.plot(epochs,val_acc,'b',label = 'Validation acc')
plt.title('Training and validation accuracy')
plt.legend()#显示标签
plt.figure()
plt.plot(epochs,loss,'bo',label = 'Training loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title("Training and validation loss")
plt.legend()
plt.show()
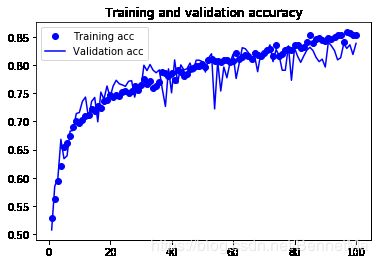
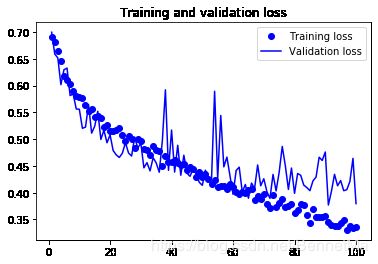
总结
在小型数据集上,不使用预训练模型的情况下,数据增强,dropout层,正则化等防止过拟合的措施是提升模型泛化能力的有效措施,最后的模型训练中,可以看出训练70轮,准确率可以达到稳定的80%。
参考:
《Deep Learning With Python》