python爬取套图的基本教程
这是一个比较简单的爬虫,所以选择的是一个不会有反爬虫的网页,不需要设置伪头之类的
1,首先打开多玩图库,打开手机壁纸
可知道网址为:http://tu.duowan.com/m/bizhi
首先创建下载器,用程序查看下源代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#创建下载器,查看网址源代码
import requests
#爬虫类
class Spider:
def __init__(self):
self.session = requests.Session()
#下载器
def download(self,url):
response = self.session.get(url)
#print(response)#返回是否可以运行200
print(response.text)#返回网页源代码
if __name__ == '__main__':
spider = Spider()
spider.download('http://tu.duowan.com/m/bizhi')执行成功将打印源代码在终端
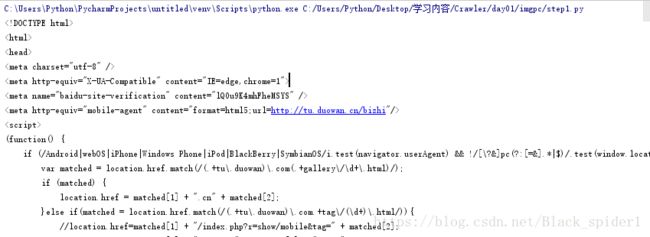
2,分析网页,获取id,并打印去重
打开网页,点手机壁纸,按F12,然后ctrl+shift+c查看图片找到a标签
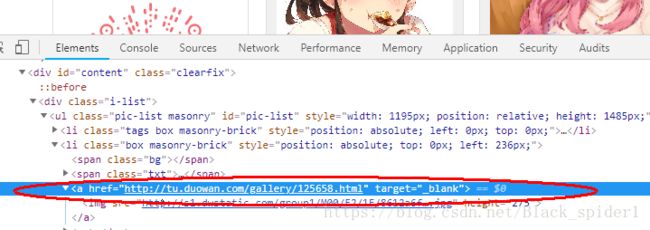
然后我们分析URL用正则表达式表示出来
代码如下:
#获取网址id,打印并去重 import requests import re #爬虫类 class Spider: def __init__(self): self.session = requests.Session() def run(self,start_url): img_ids = self.get_img_item_ids(start_url) print(img_ids) #下载器 def download(self,url): try: return self.session.get(url) except Exception as e: print(e) #返回套图id列表 def get_img_item_ids(self,start_url): ##向start_url发送请求,下载html response = self.download(start_url) if response: # 获取html的原码 html = response.text #提取所有的a标签 #href="http://tu.duowan.com/gallery/125658.html" ids = re.findall( r'http://tu.duowan.com/gallery/(\d+).html',html) #set(ids)去重 return set(ids) if __name__ == '__main__': spider = Spider() start_url = 'http://tu.duowan.com/m/bizhi' spider.run(start_url)
结果:

3,获取图片信息,用json库解码

找到图上所在位置,然后点Headers

复制网页URL:http://tu.duowan.com/index.php?r=show/getByGallery/&gid=125658&_=1530105895754
代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#获取图片信息,用json库解码
import requests
import re
import time
import json
#爬虫类
class Spider:
def __init__(self):
self.session = requests.Session()
def run(self,start_url):
img_ids = self.get_img_item_ids(start_url)
#print(img_ids)
for img_id in img_ids:
img_item_info = self.get_img_item_info(img_id)
exit()
#下载器
def download(self,url):
try:
return self.session.get(url)
except Exception as e:
print(e)
#返回套图id列表
def get_img_item_ids(self,start_url):
##向start_url发送请求,下载html
response = self.download(start_url)
if response:
# 获取html的原码
html = response.text
#提取所有的a标签
ids = re.findall(
r'http://tu.duowan.com/gallery/(.+).html',html)
#set(ids)去重
return set(ids)
# 根据套图id获取套图信息
def get_img_item_info(self,img_id):
#http://tu.duowan.com/index.php?r=show/getByGallery/&gid=125658&_=1530092793909
img_item_url = \
"http://tu.duowan.com/index.php?r=show/getByGallery/&gid=%s&_=%s"\
%(img_id,int(time.time()*1000))
response = self.download(img_item_url)
if response:
data = json.loads(response.text)
print(data)
if __name__ == '__main__':
spider = Spider()
start_url = 'http://tu.duowan.com/m/bizhi'
spider.run(start_url)
4,获取指定文件内容
代码如下:
#获取指定文件内容
import requests
import re
import time
import json
#爬虫类
class Spider:
def __init__(self):
self.session = requests.Session()
def run(self,start_url):
img_ids = self.get_img_item_ids(start_url)
#print(img_ids)
for img_id in img_ids:
img_item_info = self.get_img_item_info(img_id)
#通过img_item_info保存图片
self.save_img(img_item_info)
#下载器
def download(self,url):
try:
return self.session.get(url)
except Exception as e:
print(e)
#返回套图id列表
def get_img_item_ids(self,start_url):
##向start_url发送请求,下载html
response = self.download(start_url)
if response:
# 获取html的原码
html = response.text
#提取所有的a标签
ids = re.findall(
r'http://tu.duowan.com/gallery/(.+).html',html)
#set(ids)去重
return set(ids)
# 根据套图id获取套图信息
def get_img_item_info(self,img_id):
#http://tu.duowan.com/index.php?r=show/getByGallery/&gid=125658&_=1530092793909
img_item_url = \
"http://tu.duowan.com/index.php?r=show/getByGallery/&gid=%s&_=%s"\
%(img_id,int(time.time()*1000))
response = self.download(img_item_url)
if response:
return json.loads(response.text)
# 根据套图的信息,持久化
def save_img(self,img_item_info):
dir_name = img_item_info['gallery_title']
print(dir_name)
if __name__ == '__main__':
spider = Spider()
start_url = 'http://tu.duowan.com/m/bizhi'
spider.run(start_url)打印结果:

5,下载图片,存储到文件夹,清除掉系统非文字的字符串
代码如下(完整代码):
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import re
import time
import json
import os
def strip(path):
"""
:param path:需要清理的文件夹名称
:return: 清理掉windows系统非文件夹名字的字符串
"""
path = re.sub(r'[?\\*|"<>:/]','',str(path))
return path
#爬虫类
class Spider:
def __init__(self):
self.session = requests.Session()
def run(self,start_url):
img_ids = self.get_img_item_ids(start_url)
#print(img_ids)
for img_id in img_ids:
img_item_info = self.get_img_item_info(img_id)
#通过img_item_info保存图片
# print(img_item_info)
# exit()
self.save_img(img_item_info)
#下载器
def download(self,url):
try:
return self.session.get(url)
except Exception as e:
print(e)
#返回套图id列表
def get_img_item_ids(self,start_url):
##向start_url发送请求,下载html
response = self.download(start_url)
if response:
# 获取html的原码
html = response.text
#提取所有的a标签
ids = re.findall(
r'http://tu.duowan.com/gallery/(.+).html',html)
#set(ids)去重
return set(ids)
# 根据套图id获取套图信息
def get_img_item_info(self,img_id):
#http://tu.duowan.com/index.php?r=show/getByGallery/&gid=125658&_=1530092793909
img_item_url = \
"http://tu.duowan.com/index.php?r=show/getByGallery/&gid=%s&_=%s"\
%(img_id,int(time.time()*1000))
response = self.download(img_item_url)
if response:
return json.loads(response.text)
# 根据套图的信息,持久化
def save_img(self,img_item_info):
dir_name = strip(img_item_info['gallery_title'])
if not os.path.exists(dir_name):
os.makedirs(dir_name)
#picInfo里面为图片内容
for img_info in img_item_info['picInfo']:
#图片名称在title里
img_name = strip(img_info['title'])
#图片地址在url里
img_url = img_info['url']
#后缀
pix = (img_url.split('/')[-1]).split('.')[-1]
#图片的全路径
img_path = os.path.join(dir_name,"%s.%s"%(img_name,pix))
#print(img_path)
if not os.path.exists(img_path):
response = self.download(img_url)
print(img_url)
if response:
img_data = response.content
with open(img_path,'wb') as f:
f.write(img_data)
if __name__ == '__main__':
spider = Spider()
start_url = 'http://tu.duowan.com/m/bizhi'
spider.run(start_url)打印结果:

程序已经完成,希望大家喜欢的点个赞!