重磅发布: 营销数据中台白皮书(附全文下载)


编者按:2018年,DMP、CDP、CEM、Data Lake突然引起市场关注,「数据中台」更是成为大中型广告主的数字营销标配。
秒针系统作为中国领先的营销数据技术供应商,先后为近百家头部广告主提供了数据中台服务。我们希望通过这份白皮书勾勒出我们对数据中台这个新兴事物的理解和解读,为行业提供一定参考与借鉴。
因篇幅有限,白皮书全文共11章,我们仅摘取了前6章解释数据中台「是什么」,若您想深入了解数据中台「怎么用」「怎么构建」「如何避免弯路」和「未来发展方向」,请移至文末查看完整版获取方式。
「数据中台」最早是由阿里提出,对标国外「Data Lake」(数据湖)的概念。该概念提出的背景是因为阿里生态系中淘宝、天猫、蚂蚁金服、盒马鲜生等业务板块每天产生大量有价值的数据,要实现在不同业务群间做到数据的互联互通,以及对数据价值的最大化挖掘,便需要对各业务群的数据进行整合以建立集团层面的「数据中台」,统一管理和应用数据。
对于大部分广告主而言,「数据」仍是一个较为陌生的词。尽管「数据驱动」代表了先进生产力,但在数据缺少的情况下,企业市场部也仍旧在正常运作,那花费大量成本搭建数据中台,对于广告主有何价值呢?
- ❶ -
广告主对营销数据中台的期望是什么?
「数据中台」作为营销技术中最奢侈的投入,是只有大型广告主才需要的资源,其价值在于:
1
赋予广告主数字营销的精细化操作能力,当市场部承接的数字营销预算大到一定程度时,便无法仅凭借营销人员的个人经验对营销活动进行微观操作。而在拥有数据中台后,便可依靠数据+技术,驱动整个营销体系的精细化操作;
2
提升营销执行的ROI:这是广告主最常规的诉求,市场部绝大部分预算都分配在营销执行层面。按照每年1亿的营销投入计算,如果能通过数据提升1%的精准度,就能为广告主节省100万的成本,这是能最直接看到的真金白银;
3
战略视角的营销策略:在打通生产、销售、电商、服务等数据后,市场部就能看到更加连贯的全局数据,可以站在更高维度审视营销在公司战略布局中的定位和作用;
4
提升市场部内部运营的整合度:当市场部内部职能划分过细,便需要通过数据来串接营销运营过程中的市场研究->市场策略->营销执行->效果考核,避免内部信息不对称,提升运营效率 ;
5
加强市场部和其他部门间协作:当企业内部组织架构达到一定复杂度,市场部需要通过数据对接其他部门的运作,在企业统一的考核体系下,于企业内部证明自身价值,争取更多资源;
6
支撑业务的数字化转型:「数字营销」已不再只是营销词汇,数据中台所拥有的资源(数据/IT设施/考核规则/运营人员),除了支持营销场景,还可用于构建各种数字化转型的业务场景,作为CMO和CEO/CGO/CDO对话的核心资本。有趣的是,今天讨论建立营销数据中台的,除了市场部和IT部门,很多需求是来自更高层的CEO、COO(首席运营官)、CGO(首席增长官),这些高层的诉求是通过「数据中台」来解决业务问题(例如产能过剩、人员效能、获客),支持企业的创新业务(例如新零售、金融科技、数字化管理)。
- ❷ -
和传统数据仓库对比,
数据中台有什么差别?
国外著名咨询公司Garnter把数据管理技术分为三大类:

●Data Warehouse - Supporting mostly known data (structured,transactional) and known questions (repeatable,for broad consumption) to deliver consensus for running the business.
●Data Lake - Supporting unknown data (less organized,raw and/or exogenous) and unknown questions (discovery- and data science-oriented) to enable exploration and innovation.
●Data Hub - Enabling manageable and governed sharing of data between producing and consuming systems and processes.

与存储「已知」结构化数据,解决「已知问题」的传统数据仓库(Data Warehouse)相比,数据中台存储了大量「未知」的原始数据,利用数据科学(Data Science)可在应用层面进行更多探索,帮助企业解决更多「未知」的商业问题。
数字技术的革命,使得广告主可收集的数据在量级上产生了爆发,因为数据的「量变」,催生了数据管理和应用的「质变」,这是「数据中台」出现的主要原因。如果说传统的「数据仓库」面对的是「小数据」, 「数据中台」处理的则是真正的「大数据」。
回到5年前,广告主能收集到的营销数据大部分来自CRM,是基于消费者「人」的PII数据(Personal Identity information),这类传统营销数据是大致如下表一般:

这些数据源自广告主的运营过程,数据量级相对较小,每年所能收集的数据很难超过TB级别。数据的使用层面也相对简单,一个初级的数据分析师,可以依靠数据词典轻易读懂每条数据的含义,依靠传统统计学和算法工具就可以完成数据分析,支撑业务应用。
例如CMO想针对贡献了80%收入,但过去2周没有任何采购行为的高消费用户群体做一次campaign,不到10行SQL语句就能抽取这些目标消费者数据。
今天,广告主收集了大量描述消费者行为的「大」数据(在后文会详述数据中台的主要数据类型),这些数据是基于消费者「设备」的数字数据(Digital Data):

消费者使用的数字设备(手机、电脑、Pad等),每天都产生百万级的行为数据,广告主能轻易在数周内收集到TB级的数据。但这些大数据的管理和应用也对数据中台提出了更高的要求,主要技术革新包括以下三点:
数据中台的技术革新1:
数据治理的难度增加
传统营销数据大部分是基于email地址、手机号和姓名对消费者进行识别,不同数据源的打通难度较小。但消费者行为大数据基于多种ID(手机号、设备ID、Cookie ID、Mac等,具体在后文介绍),仅依靠广告主自有能力,很难实现ID的打通,打通的比率取决于广告主的数据量大小,在广告主的数据量没有达到足够海量前,需要依靠外部数据资源实现。
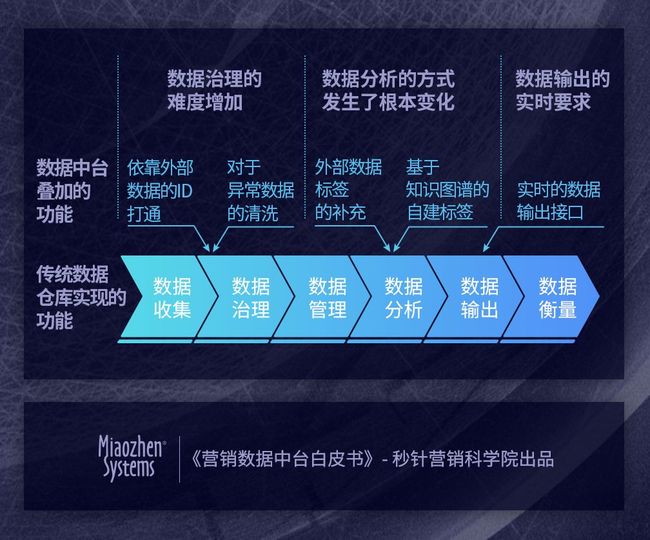
此外,消费者行为大数据中异常数据的比率远高于传统数据,例如广告主收集了1000万条浏览过自己主页的设备ID,这里面可能涉及到爬虫、虚假流量、无效浏览等多种场景,真正有价值的消费者数据量甚至会少于异常数据,这时需要通过算法或者外部数据资源对这些无意义的异常数据进行清洗。
数据中台的技术革新2:
数据分析的方式发生了根本变化
消费者行为大数据的解读没有以往这般「直接」,知道了消费者浏览的URL,知道了他们在每个页面的停留时间,知道了他们经常出现的经纬度,这些大数据如何和业务关联和使用呢?
如果把这些原始数据比喻成蔬菜,在端上饭桌实际应用前,需要经过一个「烹调」的过程,即把原始大数据简化成业务侧能读懂的标签,「烹调」的方式有2种:
a. 基于广告主收集的ID,到外部直接采购现成标签:例如广告主收集到浏览过自己官网的设备ID,想知道这些设备ID背后的消费者画像,可以对接外部数据源,对这些ID补充年龄、收入等标签,这个过程被称为Data enrichment
b. 通过「知识图谱」进行数据结构化处理后,建立自定义标签:例如广告主收集了某消费者一天1000条位置数据,如果手上有全国所有小区的经纬度位置,便能知道这个消费者晚上住在哪个小区。如果有每个小区房价,就能去猜测这个消费者的收入水平。如果有全国办公楼经纬度位置,就能知道这个消费者的大致工作。如果有全国高尔夫球场经纬度,就能知道这个消费者是否有打高尔夫的习惯….
以上这些对于原始数据结构化的「词典」,就被称为「知识图谱」(在后文会有单独有一章节进行解释),有趣的是,同样的行为数据,在连接不同知识图谱后,能获得不同的洞察结果和客户标签体系。知识图谱是广告主解读大数据、建立自己洞察体系的那把「钥匙」。
数据中台的技术革新3:
数据输出的实时要求
传统从大型数据库中提取数据需要花费数分钟甚至数小时,而今很多大数据的应用场景都是毫秒级别,例如某广告主想让不同消费者浏览自己主页时,看到不同的内容(千人千面),从技术上便需要实现毫秒级别完成以下动作:
消费者ID识别->消费者画像提取->展示图片匹配->图片加载
当以上闭环无法在毫秒级完成,无法实现实时输出,便会出现消费者数秒内打不开企业官网,从而失去耐心直接选择关闭的情况。
- ❸ -
什么是「知识图谱」
在数据中台搭建过程中,最难的不是IT层面的数据管理,而是将海量大数据化繁为简,变成业务侧能看懂的标签的「分析」过程。
上文提及了分析的两种方式,现在绝大部分广告主大走的都是第一条路线:对于数据收集主要集中在消费者ID,再基于这些ID到外部匹配可用标签。
这种模式的好处是能快速落地,缺点是外部标签成本高昂,而且由于外部供应商缺少行业理解,标签缺乏精准度。从中长期来看,广告主在使用外部标签遇到瓶颈后,必定会转向建立自身标签体系的第二条路线。
和传统基于统计学的分析不同,基于大数据的分析的第一步并不是「算法」,而是借助「知识图谱」对于底层数据的进行结构化处理,下面是一个例子:

某广告主收集到了消费者的三条行为数据:
● 访问了某URL,并停留了120秒(网站分析数据)
● 在微信某小程序中,点击了某个对话框(小程序监测)
● 出现在某线下销售门店中(智能探针数据)
通过「知识图谱」,发现第一条数据的URL代表的是产品A的介绍;第二条数据,这个小程序的对话框是产品A的询价;第三条数据,是专门销售产品A的线下门店,从定性角度已经可以初步判断这个消费者对于产品A的高度兴趣,但是有这样行为的消费者可能成千上万,在页面停留120秒,和在线下门店停留15分钟,这样的数据如何定量呢?
通过「算法」,可以发现有这样行为的消费者:在未来30天内进行购买A产品的可能性是70%。「A产品」+「70%」是业务侧最终能读懂的,并且横向比较应用的标签。
在今天的数字技术收集的大数据中,常规营销用的「知识图谱」包括:
● 网页URL的知识图谱
● APP行为的知识图谱
● 第三方平台(例如微信公众号)行为的知识图谱
● 地理位置的知识图谱
● 广告主自身产品标签化的知识图谱
不同颗粒度的「知识图谱」在解读同一条行为数据时候,得到的洞察深度也会不同,例如:
● 这个消费者正在看我的竞品
● 这个消费者正在看我的竞品的产品A
● 这个消费者正在看我的竞品的产品A,最新的促销
● 这个消费者正在看我的竞品的产品A,促销价格比我的对标产品低15%
「知识图谱」的建立过程,往往是基于消费者全量数据,用穷举法去作分析得到的,考虑到数据的多样性,高精度的「知识图谱」必定是借助AI实现的,例如掌握了消费者访问的海量URL数据,需要运用爬虫工具去获取所有URL对应页面上的文字,并通过「语义识别」技术,给每个URL贴上对应标签。
- ❹ -
数据中台的系统架构
下图是数据中台的大致模型,从IT层面有以下几个模块:
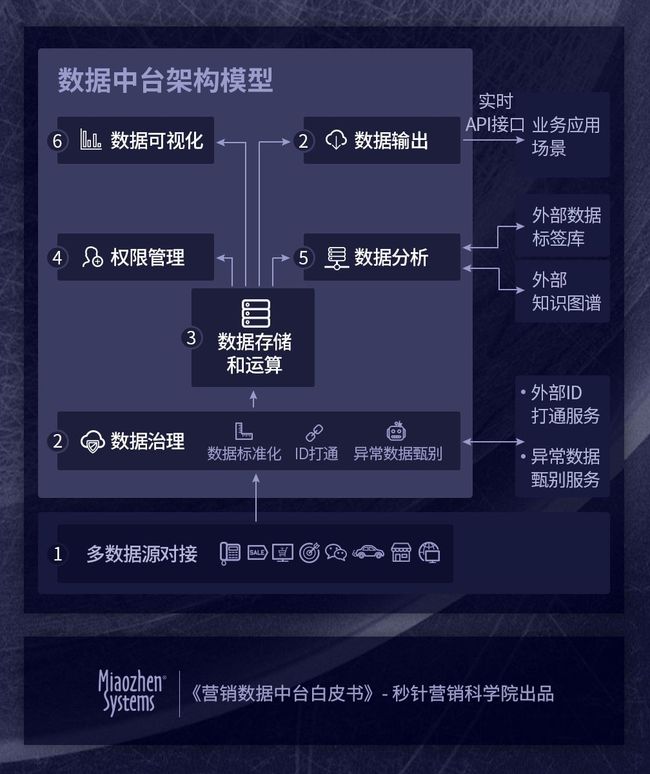
1
多数据源对接
从各种数据源提取数据,放入数据中台,数据类型包括
● 第一方数据:广告主自身系统上产生的数据,例如CRM、售后服务、会员系统等;
● 第二方数据:广告主在外部系统上产生的数据,由外部系统通过API提供,例如电商数据、广告监测数据、微信公众号数据等;
● 第三方数据:广告主直接购买的外部数据资源。需要强调的是,和业外人想象的不同,第三方数据交易并非一手交钱一手交数据。目前数据生态圈的法律合规要求,第三方数据交易不允许广告主直接采购消费者的ID,数据服务商智能基于广告主提供的消费者ID提供数据服务。
2
数据治理
在获取不同数据后,对数据的治理包括三个任务
A. 数据标准化:例如不同数据源对于消费者性别的描述有「男-女」,「先生-女士」等多种写法,在做数据整合的时候,需要统一不同数据源对于相同含义的描述值;
B. ID打通:上文也描述过,不同数据源对于消费者的识别是基于不同ID的,数据源的拼合需要ID打通。对于大部分广告主来说,无法拥有像BAT那样的数据量,BAT每天能收集十亿级别ID发生的千亿级别的行为数据,他们的确能做到依靠自身数据打通不同数据源。大部分广告主在没有如此大量数据和消费者活跃度的情况下,ID打通需要依赖外部数据源;
C. 异常数据甄别:和ID打通一样,异常数据的甄别在广告主自身数据不够庞大的情况下,同样依赖外部数据。例如某个ID每天会点击2次某广告主的广告,这个行为相对正常。但是如果放到全行业,这个ID也许每天会点击1万次各个广告主的广告,这就很明显是流量作弊了。
3
数据存储和运算
在数据完成治理后,统一放入数据库进行管理和运算。由于数据量过大,在单一服务器上无法完成存储和运算,就涉及到大数据的分布式运算,云计算等复杂IT层面的管理。
按照数据存储和计算的地方,可分为营销云(数据存在第三方的云平台上),自有云(广告主自己的IT环境内),混合模式(非敏感数据存放在第三方云,敏感数据在自有平台),以上不同的方式有着不同的成本,数据安全和合规要求等。
4
权限管理
数据中台的目标是支撑市场部甚至全公司不同业务场景,这也意味着从公司高层到底层外包员工都需要从数据中台提取数据,为了防止数据泄露等问题的发生,需要对不同用户、不同场景进行权限分级管理。例如负责接听电话的客服人员,在客服系统中就不可以看到消费者的全名和实际手机号。
5
数据分析
上文也有描述,在使用「营销大数据」前,需要对数据通过分析,生成业务侧用户能够理解的标签,分析的过程包括非实时的传统数据挖掘,依靠AI人工智能的实时分析等。在分析过程中,广告主很难在短期内积累自身的知识图谱和高质量的标签,需要依赖外部的数据能力。
6
数据可视化
虽然数据中台是由技术背景的团队进行运维,但是实际使用的是对数据缺乏感知的业务侧人员。对比成亿条原始数据,业务侧也许只需要一个饼图就能得到商业结论,因此可视化是真正让业务侧使用数据中台的基本工具。
7
数据输出
数据中台的产出,除了数据可视化展现的洞察外,还会对接不同的业务系统,通过数据来驱动业务场景,例如程序化广告、新零售、动态定价等诸多业务场景需要毫秒级的查询和输出,也是IT层面需要解决的技术问题。
- ❺ -
数据中台的数据源
今天广告主常规的数据源包括四大类:


⓵ 基于设备ID、cookie的网站分析和广告监测数据:描述的是消费者对于互联网广告,以及广告主官网、APP等自由平台的浏览和点击行为;
② 基于手机号的PII数据:包括会员系统、CRM数据等,描述的是消费者的会员信息,历史采购记录等;
⓷ 基于Mac#和人脸识别的线下数据:通过智能探针技术、摄像头+人像识别技术,收集到的消费者线下行为数据;
⓸ 基于外部平台ID的平台数据:包括微信的Open ID、各个大数据方的自建Super ID等。

这些数据的打通虽然有很多技术途径,例如在微信中建立SCRM会员体系,消费者在微信公众号中进行手机的实名认证,就能打通手机号和微信Open ID;再例如一个消费者在手机和电脑上用同一个用户名登录了某个APP,就知道手机的设备ID和电脑浏览器的Cookie是同一个人等等。
考虑到一个消费者可能有多个终端、多个手机号,会经常换手机(设备ID变化),会借用别人终端登录APP,还有网吧共享电脑等复杂形式的存在,当广告主自身数据量不够大的时候,很难依靠以上这些技术手段达到很好的数据打通效果。
- ❻ -
数据中台的三种形式
Data Lake,CDP,DMP
今天营销数据中台在技术上分为三种:
● Data Lake(数据湖):技术难度最重的一种,定位是企业业务层面的数据大集市,会整合全公司各种数据源,支撑的不只是营销场景,还包括企业个性化的业务场景,往往由企业的最高层直接领导,目标是帮助企业进行数字化转型。由于在数据对接和数据处理层面需要处理大量定制化数据源,因此构建过程往往以年为时间单位;
● CDP(Customer Data Platform):技术难度稍低的数据中台,定位是营销层面的数据大集市,目标是支撑各种利用广告主自有数据的营销场景。因为CDP通常只对接标准化数据源(例如两个广告主用的是同一款标准化CRM,他们的底层数据结构都是一样的),数据治理和数据管理相对容易,因此实施周期以月为单位;
● DMP(Data Management Platform):定位是支撑以程序化广告为主的实时营销场景,和Data Lake,CDP的最大不同是毫秒级数据输出。因为DMP主要用到的是广告监测数据、网站分析数据和第三方大数据,数据格式相对固定,因此实施难度最低。
因为在程序化广告的运营过程中,DMP的数据会暴露在公网上,被外部供应商和媒体调用,因此只能存放广告投放使用的匿名数据(ID和标签),不能存放其他敏感信息(姓名、手机号、地址、历史购买等),投放的标签也需要脱敏(例如某ID的标签是A,实际代表着过去3周没有购买的高消费客户,但这个定义只有广告主内部数据分析团队知道)。
在数据存储和运算中,DMP可以构建在广告主自己的IT环境里(称为第一方DMP),也可以放在第三方营销云上(称为SAAS DMP,或者第三方DMP)。因为第三方DMP会预先对接媒体,自带算法、标签和数据治理模块,能把DMP的实施时间缩小到几周,可以大大降低实施成本。
而由于Data Lake 和CDP上存储了广告主的敏感数据和商业机密(例如历史采购信息),因此只能构建在广告主自己的IT环境下,从技术角度而言更加复杂,成本也更高。
通过下表简单列举三种技术、四种形式的主要差别(第一方和第三方DMP分开叙述)
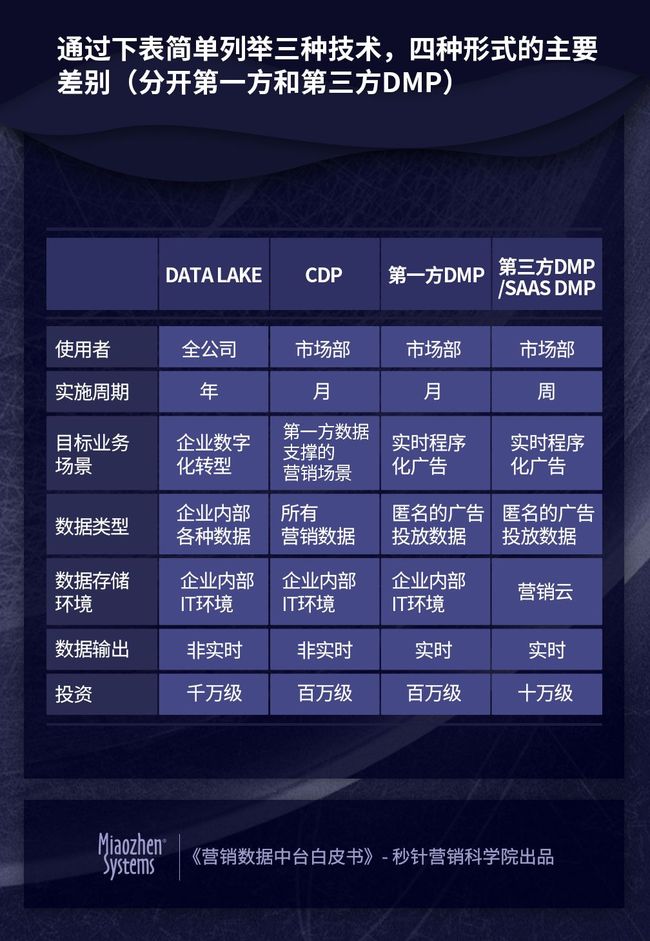
通过上表可见,Data Lake和CDP相对复杂,但是在应用场景上有更多遐想空间,而DMP则就是为程序化广告而生,是最轻量的营销数据中台技术。三种形式不存在谁优谁劣,各有各自的适用对象或场景:
● DMP:适合在广告投放领域投入大量预算的广告主,例如快消、汽车、化妆品、娱乐等;
● CDP:适合消费者复购比率高,自有体系可以收集大量消费者数据的广告主,例如奶粉、零售、运动用品、化妆品等;
● Data Lake:适用于有大量数据驱动应用场景的广告主,例如快消、零售、汽车。
《营销数据中台白皮书》共11章,
因篇幅有限,我们仅摘取了前6章,
附白皮书目录:

如您对白皮书完整版感兴趣
请关注微信公众号
回复“中台白皮书”关键字获取下载地址
温馨提示:
请识别二维码关注公众号,点击原文链接或历史文章获取更多中台和技术资料总结。

