Flume相关知识的总结
1.概述
1.1什么是flume
1、 Apache Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统,和Sqoop 同属于数据采集系统组件,但是 Sqoop 用来采集关系型数据库数据,而 Flume 用来采集流动型数据。
2、 Flume 名字来源于原始的近乎实时的日志数据采集工具,现在被广泛用于任何流事件数据的采集,它支持从很多数据源聚合数据到 HDFS。
3、 一般的采集需求,通过对 flume 的简单配置即可实现。Flume 针对特殊场景也具备良好的自定义扩展能力,因此,flume 可以适用于大部分的日常数据采集场景
4、 Flume 最初由 Cloudera 开发,在 2011 年贡献给了 Apache 基金会,2012 年变成了 Apache的顶级项目。Flume OG(Original Generation)是 Flume 最初版本,后升级换代成 Flume NG(Next/New Generation)
5、 Flume 的优势:可横向扩展、延展性、可靠性
1.2 FLUME-NG
1.x之后的版本就是flume-NG N就是new的意思
0.9之前的版本就是flume-OG O就是Old的意思
1.3flume的数据来源和数据输出
- 数据来源
Flume 提供了从 console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail).syslog(syslog 日志系统,支持 TCP 和 UDP 等 2 种模式),exec(命令执行)等数据源上收集数据的能力,在我们的系统中目前使用 exec 方式进行日志采集。
- 数据输出
Flume 的数据接受方,可以是 console(控制台)、text(文件)、dfs(HDFS 文件)、RPC(Thrift-RPC)和 syslogTCP(TCP syslog 日志系统)等。最常用的是 Kafka
2.flume的体系结构和核心组件
2.1体系结构
- 工作流程
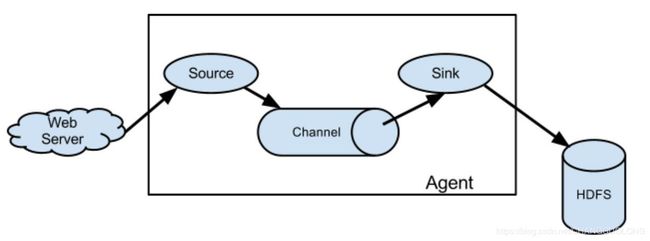
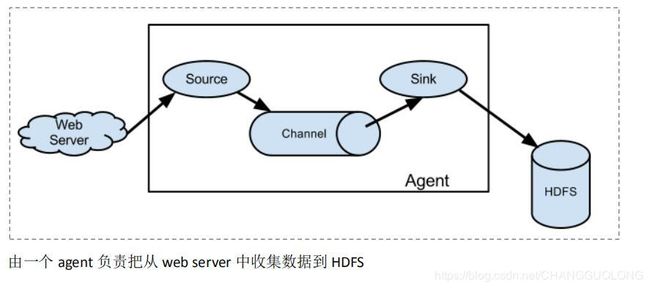
Flume 的数据流由事件(Event)贯穿始终。事件是 Flume 的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些 Event 由 Agent 外部的 Source 生成,当 Source 捕获事件后会进行特定的格式化,然后 Source 会把事件推入(单个或多个)Channel 中。你可以把Channel 看作是一个缓冲区,它将保存事件直到 Sink 处理完该事件。Sink 负责持久化日志或者把事件推向另一个 Source。
Flume 以 agent 为最小的独立运行单位。
一个 agent 就是一个 JVM。
单 agent 由 Source、Sink 和 Channel 三大组件构成。
2.2flume的三大核心组件
-
Event
Event 是 Flume 数据传输的基本单元。
Flume 以事件的形式将数据从源头传送到最终的目的地。
Event 由可选的 header 和载有数据的一个 byte array 构成。
载有的数据度 flume 是不透明的。
Header 是容纳了 key-value 字符串对的无序集合,key 在集合内是唯一的。
Header 可以在上下文路由中使用扩展 -
Client
Client 是一个将原始 log 包装成 events 并且发送他们到一个或多个 agent 的实体目的是从数据源系统中解耦 Flume, 在 Flume 的拓扑结构中不是必须的。
Client 实例
flume log4j Appender
可以使用 Client SDK(org.apache.flume.api)定制特定的 Client -
Agent
一个 Agent 包含 source,channel,sink 和其他组件。
它利用这些组件将 events 从一个节点传输到另一个节点或最终目的地
agent 是 flume 流的基础部分。
flume 为这些组件提供了配置,声明周期管理,监控支持。 -
Agent 之 Source
Source 负责接收 event 或通过特殊机制产生 event,并将 events 批量的放到一个或多个
包含 event 驱动和轮询两种类型。
不同类型的 Source:
与系统集成的 Source:Syslog,Netcat,监测目录池
自动生成事件的 Source:Exec
用于 Agent 和 Agent 之间通信的 IPC source:avro,thrift
source 必须至少和一个 channel 关联 -
Agent 之 Channel
Channel 位于 Source 和 Sink 之间,用于缓存进来的 event
当 sink 成功的将 event 发送到下一个的 channel 或最终目的 event 从 channel 删除
不同的 channel 提供的持久化水平也是不一样的
Memory Channel:volatile(不稳定的)
File Channel:基于 WAL(预写式日志 Write-Ahead Logging)实现
JDBC Channel:基于嵌入式 database 实现
channel 支持事务,提供较弱的顺序保证
可以和任何数量的 source 和 sink 工作
- Agent 之 Sink
Sink 负责将 event 传输到吓一跳或最终目的地,成功后将 event 从 channel 移除
不同类型的 sink
存储 event 到最终目的地终端 sink,比如 HDFS,HBase
自动消耗的 sink 比如 null sink
用于 agent 间通信的 IPC:sink:Avro
必须作用于一个确切的 channel
-
Iterator
作用于 Source,按照预设的顺序在必要地方装饰和过滤 events
-
Channel Selector
允许 Source 基于预设的标准,从所有 channel 中,选择一个或者多个 channel
-
Sink Processor
多个 sink 可以构成一个 sink group
sink processor 可以通过组中所有 sink 实现负载均衡
也可以在一个 sink 失败时转移到另一个

3.flume的几种部署的方案
- 单agent
- 多agent串联

- 多agent合并串联

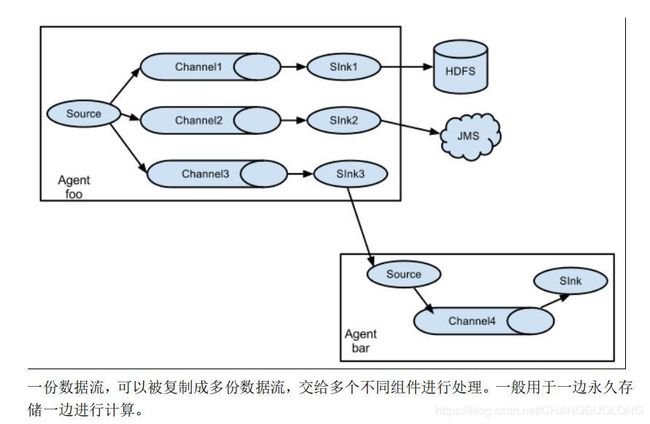
- 多路复用
4.flume实战的案例
单agent 监视新文件生成
需求:
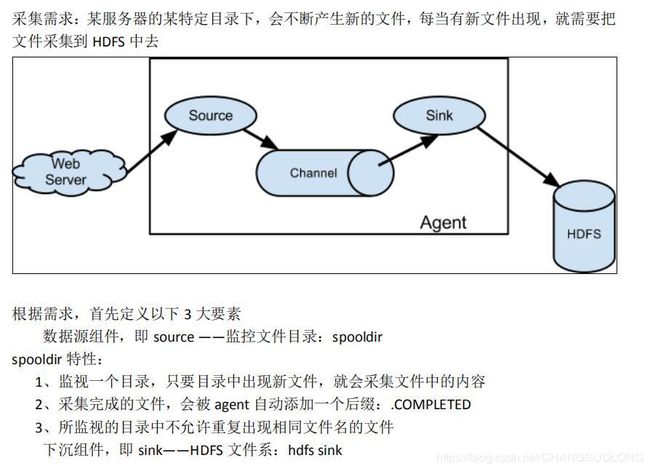
- 第一步创建一个配置文件
#source sink channels 分别命名
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置 source 组件 类型是spooldir用来监视文件夹中文件的创建 spoolDir 是配置监视的文件夹的路径
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/hadoop/flumelogs/
agent1.sources.source1.fileHeader = false
# 配置 sink 组件
agent1.sinks.sink1.type = hdfs #类型是hdfs将文件写入的hdfs
agent1.sinks.sink1.hdfs.path=hdfs://hadoop02/flume_log/%y-%m-%d/%H-%M #写入到hdfs文件的路径%y-%m-%d/%H-%M 这是根据系统的时间增加上的年月日时分的信息
agent1.sinks.sink1.hdfs.filePrefix = events #在hdfs中生成的文件的前缀是events
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000 #最大打开文件的数目是5000
agent1.sinks.sink1.hdfs.batchSize= 100 #每个批次刷新到hdfs上的event的数量
agent1.sinks.sink1.hdfs.fileType = DataStream #文件格式,包括:SequenceFile, DataStream,CompressedStream 当使用DataStream时候,文件不会被压缩,不需要设置hdfs.codeC;当使用CompressedStream时候,必须设置一个正确的hdfs.codeC值;
agent1.sinks.sink1.hdfs.writeFormat =Text #写sequence文件的格式。包含:Text, Writable(默认)
agent1.sinks.sink1.hdfs.rollSize = 102400 #当临时文件达到102400bytes的时候转换成正式文件
agent1.sinks.sink1.hdfs.rollCount = 1000000 #档events达到这个数量的时候,临时文件转换成正式文件
agent1.sinks.sink1.hdfs.rollInterval = 60 #间隔60s将临时文件转换成正式文件
#agent1.sinks.sink1.hdfs.round = true #是否启用时间舍弃
#agent1.sinks.sink1.hdfs.roundValue = 10 #时间舍弃的值
#agent1.sinks.sink1.hdfs.roundUnit = minute #时间舍弃的单位
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true#是否使用本地时间戳,如果没有增加时间拦截器的话,可以使用它来增加sink文件的时间戳目录
# 设置channel
agent1.channels.channel1.type = memory #内存的方式
agent1.channels.channel1.keep-alive = 120 #设置从channel中写入和读出events的超时的时间
agent1.channels.channel1.capacity = 500000 #设置channel中最大的event的数量
agent1.channels.channel1.transactionCapacity = 600 #channel的事务中包含多少个events 这个事务对source的存和sink的取都有效
# 配置source sink channel的关系
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
- 第二步 启动
bin/flume-ng agent -c conf -f agentconf/spooldir-hdfs.properties -n agent1 -Dflume.root.logger=INFO,console - 第三步 测试
1、如果 HDFS 集群是高可用集群,那么必须要放入 core-site.xml 和 hdfs-site.xml 文件到$FLUME_HOME/conf 目录中
2、查看监控的/home/hadoop/flumelogs 文件夹中的文件是否被正确上传到 HDFS 上
3、在该目录中创建文件,或者从其他目录往该目录加入文件,验证是否新增的文件能被自动的上传到 HDFS
在该目录下创建文件 发现flume的日志发生改变
创建文件

日志文件发生改变

查看hdfs发现多了文件

监视的文件夹中新创建的文件增加了complete的后缀

至此单agent的部署全部完成
单agent监视日志文件的增加
需求

编制配置文件
#命名
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 设置source 类型是exec 指令
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /home/hadoop/flumelogs/catalina.out #监视该文件的增加
agent1.sources.source1.channels = channel1
# 设置sink
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path =hdfs://myha01/weblog/flume-event/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = tomcat_
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
agent1.sinks.sink1.hdfs.round = true
agent1.sinks.sink1.hdfs.roundValue = 10
agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# 设置channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
启动:
bin/flume-ng agent -c conf -f agentconf/tail-hdfs.properties -n agent1 -Dflume.root.logger=INFO,console
测试
在文件中追加内容,hdfs中会增加内容
3.多agent串联
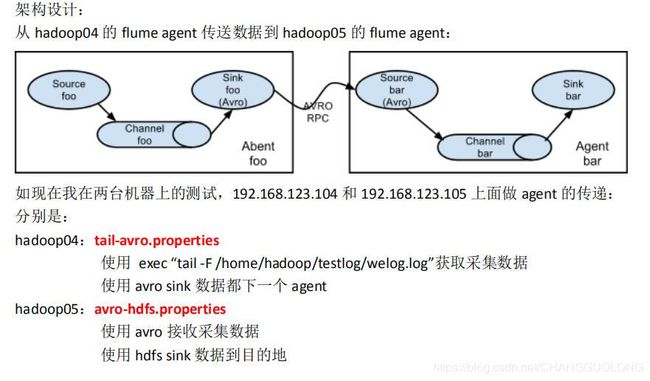
编写发送端的配置文件

编写接收端配置文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# Describe k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path =hdfs://myha01/testlog/flume-event/%y-%m-%d/%H-%M
a1.sinks.k1.hdfs.filePrefix = date_
a1.sinks.k1.hdfs.maxOpenFiles = 5000
a1.sinks.k1.hdfs.batchSize= 100
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat =Text
a1.sinks.k1.hdfs.rollSize = 102400
a1.sinks.k1.hdfs.rollCount = 1000000
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

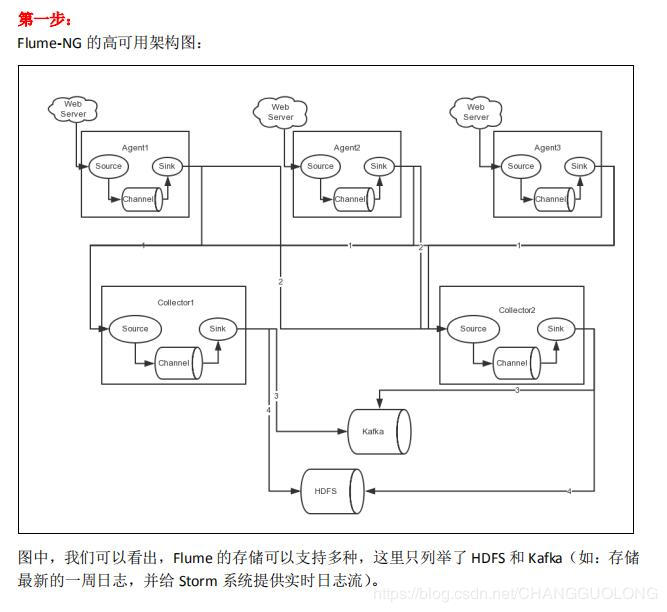
4.高可用部署
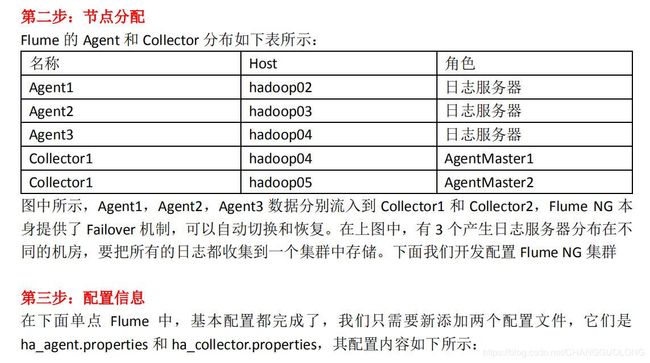
ha_agent.properties 配置:
#agent name: agent1
agent1.channels = c1
agent1.sources = r1
#set gruop
agent1.sinkgroups = g1
#set sinks 有两个sink
agent1.sinks = k1 k2
#set sink group 两个sink是一组
agent1.sinkgroups.g1.sinks = k1 k2
#set failover 设置高可用
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10 #K1是主sink 优先级是10
agent1.sinkgroups.g1.processor.priority.k2 = 1 #K2是备用sink 优先级是1
agent1.sinkgroups.g1.processor.maxpenalty = 10000 #最长等待10s转移故障
#set channel设置channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec #设置监视指令
agent1.sources.r1.command = tail -F /home/hadoop/testlog/testha.log #监视追加的内容
agent1.sources.r1.interceptors = i1 i2 #设置两个拦截器
agent1.sources.r1.interceptors.i1.type = static #i1拦截器是静态拦截器
agent1.sources.r1.interceptors.i1.key = Type #i1拦截器的key是Type
agent1.sources.r1.interceptors.i1.value = LOGIN #i1拦截器的value是LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp #i2拦截器是timestamp
# set sink1 设置sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro #avro网络端口模式
agent1.sinks.k1.hostname = hadoop04 #目标主机hadoop04
agent1.sinks.k1.port = 52020 #端口号
# set sink2设置sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro #avro网络端口模式
agent1.sinks.k2.hostname = hadoop05 #目标主机hadoop05
agent1.sinks.k2.port = 52020 #端口号
- ha_collector.properties
#set agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
## 当前主机为什么,就修改成什么主机名 就是说监视自己的端口 所以写自己的主机名
a1.sources.r1.bind = hadoop04
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
## 当前主机为什么,就修改成什么主机名 这个意思是将自己的主机名加入到头文件中
a1.sources.r1.interceptors.i1.value = hadoop04
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path= hdfs://myha01/flume_ha/loghdfs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
a1.sinks.k1.channel=c1
注意:在把 ha_collector.properties 文件拷贝到另外一台 collector 的时候,记得更改该配置文件中的主机名。在该配置文件中有注释
- 启动
先启动 hadoop04 和 hadoop05 上的 collector 角色:
bin/flume-ng agent -c conf -f agentconf/ha_collector.properties -n a1 -Dflume.root.logger=INFO,console
然后启动 hadoop02,hadoop03,hadoop04 上的 agent 角色:
bin/flume-ng agent -c conf -f agentconf/ha_agent.properties -n agent1 -
Dflume.root.logger=INFO,console
测试的时候借助之前的脚本的文件自动生成时间的方法,可以手动将主sink的进程kill掉来观察切换的状况
但是经过测试发现在测试高可用切换的时候回出现数据的丢失的现象,切换的过程大致应该是这样:
1.hadoop04 在hdfs中生成临时文件,临时文件还没有转换成正式文件
2.这时候hadoop04宕机了,
3.hadoop05上线了,hadoop04生成的最后一个临时文件自动生成了正式文件,hadoop05开始生成正式文件.
4.但是这个切换过程中有可能丢失一部分文件(也可能和配置有关)
5.当hadoop04 上线之后会自动抢占工作机会,hadoop05将下线
5.综合案例
案例场景/需求
A、B 两台日志服务机器实时生产日志主要类型为 access.log、nginx.log、web.log
现在要求:
把 A、B 机器中的 access.log、nginx.log、web.log 采集汇总到 C 机器上然后统一收集到 HDFS中。
但是在 hdfs 中要求的目录为:
/source/logs/主机的地址/20160101/**
/source/logs/nginx/20160101/**
/source/logs/web/20160101/**
场景分析

详细部署
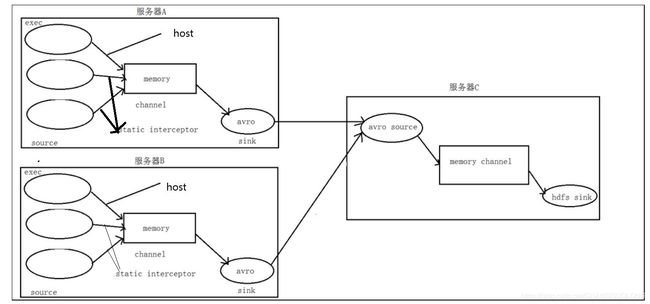
- AB两台机器中的flume配置文件
# 指定各个核心组件
2 a1.sources = r1 r2 r3
3 a1.sinks = k1
4 a1.channels = c1
5 # 准备数据源
6 ## static 拦截器的功能就是往采集到的数据的 header 中插入自己定义的 key-value 对
7 #设置access.log的监听
a1.sources.r1.type = exec #监视指令的结果
8 a1.sources.r1.command = tail -F /home/hadoop/flume_data/access.log
9 a1.sources.r1.interceptors = i1 i11 #设置两个拦截器
10 a1.sources.r1.interceptors.i1.type = host #主机名拦截器
11 a1.sources.r1.interceptors.i1.hostHeader=host
12
13 a1.sources.r1.interceptors.i11.type = timestamp #时间戳拦截器
14 a1.sources.r1.interceptors.i11.headerName = timestamp #header中的名字就叫做timestamp
##设置nginx.log的监听
15 a1.sources.r2.type = exec
16 a1.sources.r2.command = tail -F /home/hadoop/flume_data/nginx.log
17 a1.sources.r2.interceptors = i2 i22 #设置两个拦截器 一个是static 一个是timestamp
18 a1.sources.r2.interceptors.i2.type = static
19 a1.sources.r2.interceptors.i2.key = type
20 a1.sources.r2.interceptors.i2.value = nginx
21 a1.sources.r2.interceptors.i22.type = timestamp
22 a1.sources.r2.interceptors.i22.headerName = timestamp
#设置web.log的监听器 设置两个监听器
23 a1.sources.r3.type = exec
24 a1.sources.r3.command = tail -F /home/hadoop/flume_data/web.log
25 a1.sources.r3.interceptors = i3 i33
26 a1.sources.r3.interceptors.i3.type = static
27 a1.sources.r3.interceptors.i3.key = type
28 a1.sources.r3.interceptors.i3.value = web
29 a1.sources.r3.interceptors.i33.type = timestamp
30 a1.sources.r3.interceptors.i33.headerName = timestamp
31 # Describe the sink设置输出sink 目标主机是hadoop03 avro 41414端口
32 a1.sinks.k1.type = avro
33 a1.sinks.k1.hostname = hadoop03
34 a1.sinks.k1.port = 41414
#设置channel
35 # Use a channel which buffers events in memory
36 a1.channels.c1.type = memory
37 a1.channels.c1.capacity = 20000
38 a1.channels.c1.transactionCapacity = 10000
39 # Bind the source and sink to the channel
#设置关联的关系
40 a1.sources.r1.channels = c1
41 a1.sources.r2.channels = c1
42 a1.sources.r3.channels = c1
43 a1.sinks.k1.channel = c1
- 设置C点的配置文件
1 #定义 agent 名,source、channel、sink 的名称
2 a1.sources = r1
3 a1.sinks = k1
4 a1.channels = c1
5 #定义 source source就是本机的avro的41414端口 0.0.0.0也能代表本机
6 a1.sources.r1.type = avro
7 a1.sources.r1.bind = 0.0.0.0
8 a1.sources.r1.port =41414
9 #添加时间拦截器
10 #a1.sources.r1.interceptors = i1
11 #a1.sources.r1.interceptors.i1.type=org.apache.flume.interceptor.TimestampInterceptor$Builder
12 #定义 channels
13 a1.channels.c1.type = memory
14 a1.channels.c1.capacity = 20000
15 a1.channels.c1.transactionCapacity = 10000
16 #定义 sink
17 a1.sinks.k1.type = hdfs
#设置目录,这时候就能用AB中定义的拦截器的信息了
#/%{type}%{host}/代表的意思是如果拦截器中有type的话就取出type的value将值作为目录,如果有host的话就将主机名作为目录 /%Y%m%d/这里的这个时间使用的是C点的时间拦截器的时间戳
18 a1.sinks.k1.hdfs.path=hdfs://高可用组名/source/logs/%{type}%{host}/%Y%m%d/
19 a1.sinks.k1.hdfs.filePrefix =events
20 a1.sinks.k1.hdfs.fileType = DataStream
21 a1.sinks.k1.hdfs.writeFormat = Text
22 #时间类型
23 a1.sinks.k1.hdfs.useLocalTimeStamp = true
24 #生成的文件不按条数生成
25 a1.sinks.k1.hdfs.rollCount = 0
26 #生成的文件按时间生成
27 a1.sinks.k1.hdfs.rollInterval = 30
28 #生成的文件按大小生成
29 a1.sinks.k1.hdfs.rollSize = 10485760
30 #批量写入 hdfs 的个数
31 a1.sinks.k1.hdfs.batchSize = 20
32 #flume 操作 hdfs 的线程数(包括新建,写入等)
33 a1.sinks.k1.hdfs.threadsPoolSize=10
34 #操作 hdfs 超时时间
35 a1.sinks.k1.hdfs.callTimeout=30000
36 #组装 source、channel、sink
37 a1.sources.r1.channels = c1
38 a1.sinks.k1.channel = c1
- 启动
配置完成之后,在服务器 A 和 B 上的/home/hadoop/data 有数据文件 access.log、nginx.log、web.log。
先启动服务器 C(hadoop05)上的 flume,启动命令:在 flume 安装目录下执行:
bin/flume-ng agent -c conf -f agentconf/avro_source_hdfs_sink.properties -name a1 -Dflume.root.logger=DEBUG,console
然后在启动服务器上的 A(hadoop03)和 B(hadoop04),启动命令:在 flume 安装目录下执行:
bin/flume-ng agent -c conf -f agentconf/exec_source_avro_sink.properties -name a1 -Dflume.root.logger=DEBUG,console
- 测试
分别在三个日志文件中追加内容,查看hdfs的指定目录中内容的变化
hdfs中的三个日志文件的目录如下
 可以看出三个文件 access.log是按照主机名生成的目录,其余的文件是按照type的值生成的目录
可以看出三个文件 access.log是按照主机名生成的目录,其余的文件是按照type的值生成的目录
每个目录中的内容是什么样的呢
![]()
是按照时间戳生产成的年月日的目录
那真正的文件是什么样子的呢
![]()
按照指定的规则以events开头的文件,这个是正式的文件