Elasticsearch的由来
思考:大规模数据如何检索?
如:当系统数据量上了10亿、100亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑问题:
1)用什么数据库好?(mysql、sybase、oracle、达梦、神通、mongodb、hbase…)
2)如何解决单点故障;(lvs、F5、A10、Zookeep、MQ)
3)如何保证数据安全性;(热备、冷备、异地多活)
4)如何解决检索难题;(数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5)如何解决统计分析问题;(离线、近实时)
传统数据库的应对解决方案
解决要点:
1)通过主从备份解决数据安全性问题;
2)通过数据库代理中间件心跳监测,解决单点故障问题;
3)通过代理中间件将查询语句分发到各个slave节点进行查询,并汇总结果
非关系型数据库的解决方案
对于Nosql数据库,以mongodb为例,其它原理类似:
解决要点:
1)通过副本备份保证数据安全性;
2)通过节点竞选机制解决单点问题;
3)先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果
ES定义
ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ES主要解决问题:
1)检索相关数据;
2)返回统计结果;
3)速度要快。
ES核心概念
1)Cluster:集群。
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为节点。
3)Shard:分片。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4)Replia:副本。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5)全文检索。
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
ES数据架构的主要概念(与关系数据库Mysql对比)
(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type),
(3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
Elasticsearch与关系数据的类比对应关系如下:
Relational DB ⇒ Databases ⇒ Tables ⇒ Rows ⇒ Columns
Elasticsearch ⇒ Indices ⇒ Types ⇒ Documents ⇒ Fields
实例:新浪是如何分析处理32亿条实时日志的
http://dockone.io/article/505
什么是一个Shard?
Shard就是一个Lucene Index
Index需要多少个Shard?
Shard数 = Node数?
总体上说,当我们节点数和Shard数相等时,ElasticSearch集群的性能可以达到最优。即,对于一个3节点集群,我们为每个集群节点分配一个Shard,总共3个Shard。但是由于ElasticSearch的不可变性(Immutable)的限制,系统无法对Shard进行重新拆分分配,除非重新索引这个文件集合。所以,当我们需要增加更多节点的时候,又希望Shard能利用到增加节点带来的系统性能提升时,我们就不得不进行重新索引,由于重索引开销巨大,这是我们不希望看到的。
如果需要重新建立索引,将会是一个巨大的开销,为了支持未来可能的水平扩展,我们会为集群分配比node数更多的shard数,也就是说每个节点会有多个Shard。
如果单个node分配多个shard,就会引入另外一系列的性能问题,我们知道对于任意一次完整的搜索,ElasticSearch会分别对每个shard进行查询,最后进行汇总。当节点数和shard数是一对一的时候,所有的查询可以并行运行。但是,对于具有多个shard的节点,如果磁盘是15000RPM或SSD,可能会相对较快,但是这也会存在等待响应的问题,所以通常不推荐一个节点超过2个shard。
3节点6shard,即每个节点2shard,这可以使我们在未来轻松的横向扩展到6个节点,应对许多极端的场景。
Replicas数呢?
Replica也是Shard,与shard不同的是,replica只会参与读操作,同时也能提高集群的可用性。对于Replica来说,它的主要作用就是提高集群错误恢复的能力,所以replica的数目与shard的数目以及node的数目相关,与shard不同的是,replica的数目可以在集群建立之后变更,切代价较小,所以相比shard的数目而言,没有那么重要。
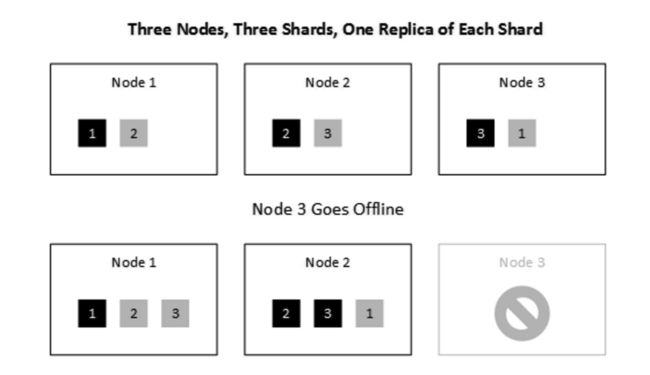
例子:
3 node, 3 shard, 1 replica (each)
一个节点宕机