Kafka个人笔记后篇(自定义拦截器及监控,与flume对接)
Kafka个人笔记后篇
- 自定义interceptor
- interceptore原理
- interceptor实现
- 第一个时间戳interceptor
- 第二个计数器interceptor
- 创建producerinterceptor
- 结果
- Kafka监控
- Kafka Eagle
- Flume对接Kafka
自定义interceptor
interceptore原理
Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。
对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor,其定义的方法包括:
(1)configure(configs)
获取配置信息和初始化数据时调用。
(2)onSend(ProducerRecord):
该方法封装进KafkaProducer.send方法中,即它运行在用户主线程中。Producer确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响目标分区的计算。
(3)onAcknowledgement(RecordMetadata, Exception):
该方法会在消息从RecordAccumulator成功发送到Kafka Broker之后,或者在发送过程中失败时调用。并且通常都是在producer回调逻辑触发之前。onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率。
(4)close:
关闭interceptor,主要用于执行一些资源清理工作
如前所述,interceptor可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个interceptor,则producer将按照指定顺序调用它们,并仅仅是捕获每个interceptor可能抛出的异常记录到错误日志中而非在向上传递。这在使用过程中要特别留意。
interceptor实现
需求:
1.实现双interecptor组成的拦截链
2.第一个在消息发送前添加时间戳
3.第二个记录消息发送的失败成功次数
第一个时间戳interceptor
public class Timeinterceptor implements ProducerInterceptor {
//设置时间拦截器(在数据前增加时间戳)
public ProducerRecord onSend(ProducerRecord record) {
return new ProducerRecord(record.topic(),record.partition(),record.key(),System.currentTimeMillis()+record.value().toString());
}
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
public void close() {
}
public void configure(Map configs) {
}
}
第二个计数器interceptor
public class countinterceptor implements ProducerInterceptor {
int sucess = 0;
int error = 0;
public ProducerRecord onSend(ProducerRecord record) {
return record;
}
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if(metadata != null){
sucess++;
}else{
error++;
}
}
public void close() {
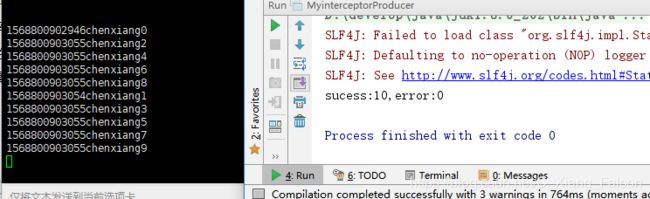
System.out.println("sucess:"+sucess+",error:"+error);
}
public void configure(Map configs) {
}
}
创建producerinterceptor
public class MyinterceptorProducer {
public static void main(String[] args) {
//配置信息
Properties props = new Properties();
//指定连接kafka的集群
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop120:9092");
//指定ack
props.put(ProducerConfig.ACKS_CONFIG, "all");
//指定重试次数
props.put(ProducerConfig.RETRIES_CONFIG, 3);
//指定批次大小
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//指定数据的延时
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
//缓冲区大小
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
//指定kv的序列化
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
//指定自定义拦截器链
ArrayList interceptors = new ArrayList();
interceptors.add("com.alibaba.interceptor.Timeinterceptor");
interceptors.add("com.alibaba.interceptor.countinterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
//构建生产者
KafkaProducer producer = new KafkaProducer(props);
//发送数据
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord("first", "chenxiang" + i));
};
//关闭连接
producer.close();
}
}
结果
Kafka监控
Kafka Eagle
1.修改kafka启动命令
先关闭kafka集群
修改kafka-server-start.sh命令中
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
注意:修改之后在启动Kafka之前要分发之其他节点
2.上传压缩包kafka-eagle-bin-1.3.7.tar.gz到集群/opt/software目录
3.解压到本地
[Diao@hadoop120 software]$ tar -zxvf kafka-eagle-bin-1.3.7.tar.gz
4.进入刚才解压的目录
[Diao@hadoop120 kafka-eagle-bin-1.3.7]$ ll
总用量 82932
-rw-rw-r--. 1 atguigu atguigu 84920710 8月 13 23:00 kafka-eagle-web-1.3.7-bin.tar.gz
5.将kafka-eagle-web-1.3.7-bin.tar.gz解压至/opt/module
[Diao@hadoop120 kafka-eagle-bin-1.3.7]$ tar -zxvf kafka-eagle-web-1.3.7-bin.tar.gz -C /opt/module/
6.修改名称
[Diao@hadoop120 module]$ mv kafka-eagle-web-1.3.7/ eagle
7.给启动文件执行权限
[Diao@hadoop120 eagle]$ cd bin/
[Diao@hadoop120 bin]$ ll
总用量 12
-rw-r--r--. 1 atguigu atguigu 1848 8月 22 2017 ke.bat
-rw-r--r--. 1 atguigu atguigu 7190 7月 30 20:12 ke.sh
[Diao@hadoop120 bin]$ chmod 777 ke.sh
8.修改配置文件 conf/system-config.properties
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop120:2181,hadoop121:2181,hadoop122:2181
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://hadoop120:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=000000
9.添加环境变量
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
注意:source /etc/profile
10.启动
[Diao@hadoop120 eagle]$ bin/ke.sh start
... ...
... ...
*******************************************************************
* Kafka Eagle Service has started success.
* Welcome, Now you can visit 'http://192.168.9.102:8048/ke'
* Account:admin ,Password:123456
*******************************************************************
* ke.sh [start|status|stop|restart|stats]
* https://www.kafka-eagle.org/
*******************************************************************
[Diao@hadoop120 eagle]$
注意:启动之前需要先启动ZK以及KAFKA
11.登录页面查看监控数据
http://192.168.9.102:8048/ke
Flume对接Kafka
1)配置flume(flume-kafka.conf)
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /opt/module/data/flume.log
a1.sources.r1.shell = /bin/bash -c
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2) 启动kafkaIDEA消费者
3) 进入flume根目录下,启动flume
$ bin/flume-ng agent -c conf/ -n a1 -f jobs/flume-kafka.conf
4) 向 /opt/module/data/flume.log里追加数据,查看kafka消费者消费情况
$ echo hello >> /opt/module/data/flume.log