前言:本博文摘抄自中国慕课大学上的课程《Python数据分析与展示》,推荐刚入门的同学去学习,这是非常好的入门视频。
继续一个新的库,Pandas库。Pandas库围绕Series类型和DataFrame类型这两种数据结构,提供了一种高效便捷的数据处理方式。
- Series 类型创建
Series类型是一组数据及与之相关的数据索引组成
自动索引:
a = pd.Series([9, 8, 7, 6]) 构造一个Series对象a 
自定义索引:
a = pd.Series([9, 8, 7, 6], index = [‘a’, ‘b’, ‘c’, ‘d’]) 
- 从标量值创建:
s = pd.Series(25, index = [‘a’, ‘b’, ‘c’]) 
- 从字典类型创建:
键值对中的键是索引
d = pd.Series({‘a’:9, ‘b’:8, ‘c’:7}) 

- 从ndarray类型创建:
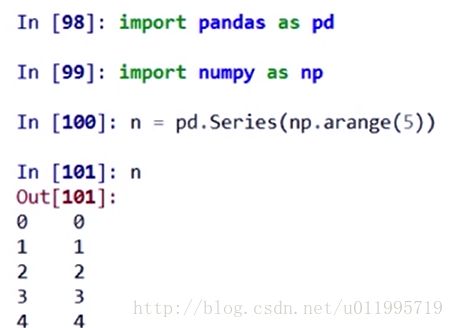

- Series类型基本操作
- ,index 获得索引 .values 获得数据


Series类型会自动生成默认索引,当自动索引和自定义索引并存,全当自定义索引。 
只索引,得到值。做切片,得到还是Series类型数据。 
in : 判断“键”是否在字段中 返回 True / False
b.get(‘f’, 100) 获取b的索引为‘f’的数据,若不存在,返回100
Series类型对齐操作 
索引一致的,对应元素相加,无一致的索引,数据为NaN
Series类型的name属性 
- DataFrame类型创建
DataFrame是表格型类,可理解为二维代表签数据类型, 其由共用相同索引的一组列组成: index(axis=0),colum(axis=1)
从ndarray创建DataFrame类型
d= pd.DataFrame(np.arange(10).reshape(2,5)) 
从字典创建DataFrame类型 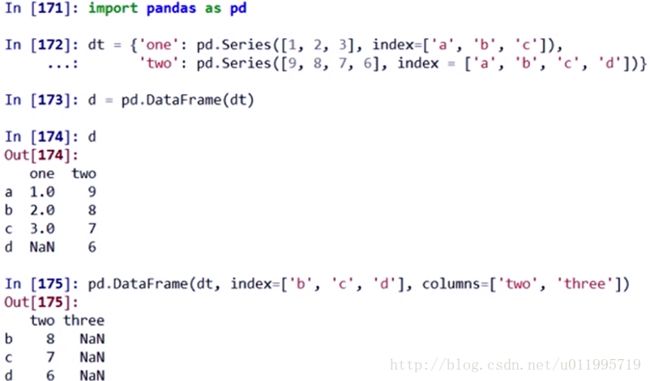
字典中的键,默认为列索引;
只选取字典中有的索引所对应的值,没有的自动补齐
从列表创建DataFrame类型 
d[‘one’] 获得新的DataFrame类型
d.ix[‘b’] 获得d的 b这一列
d[‘one’][‘b’] 获得 数据 2 注意:必须先[‘one’]后[‘b’],先列后行
- Pandas数据类型操作
重新索引
reindex(index=None, columns=None,…)方法 可改变或重排Series和DataFrame索引
reindex(index=None, columns=None,…)
index, colums 新的行列自定义索引
fill_value 在重新索引,用于填充缺失位置的值
method 填充方法,ffill当前值向前填充, bfill向后填充
limit 最大填充量
copy 默认为True,生成新的对象,False时,新旧相等,但不复制
d.reindex(index = [‘d’, ‘c’, ‘b’, ‘a’ ])
d.reindex(colums = [‘two’, ‘one’]) 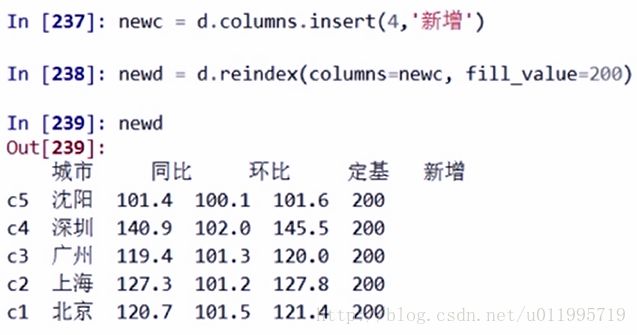
newc = d.colums.insert( 4, ‘新增’) newc为一个colums
- 索引类型常用方法
.append(idx) 连接另外一个Index对象,产生新的Index对象
.diff(idx) 计算差集,产生新的Index对象
.intersection(idx) 计算交集,产生新对象
.union(idx) 计算并集
.delete(loc) 删除loc位置处的元素
.insert(loc, e) 在loc位置增加一各元素e 
删除指定索引对象
.drop()可删除Series或DataFrame制定的行或列
d.drop([‘c1’, ‘c2’]) # 此处生成新对象,原对象d不改变
d.drop(‘one’,axis=1) 要删除列,需要加上axis = 1.
- Pandas库数据类型运算
算术运算法则
根据行列索引进行运算,补齐(NaN)后运算,运算默认产生浮点数
二维和一维、一维和零维时,采用广播运算,即低的于高的每一维运算
算术运算方法形式的运算
.add(d, **argws) .sub(d, **argws) .mul(d, **argws) .div(d, **argws)
**argws为可选参数:
fill_value,补齐时填充的值;
广播运算时,一维的列默认作用到二维的行(axis=1),要更改到列,则需要增加参数
a.add(b, axis=0 )
比较运算
同维度需要有相同的shape
不同维度时,默认为在1轴运算
- 数据排序
.sort_index()方法在指定轴上根据索引进行排序,默认升序。
.sort_index(axis=0,ascending = True) ascending是指递增排序
.sort_values()方法在指定轴上根据数值进行排序,默认升序。
Serier.sort_values(axis= 0, ascending=True)
DataFrame.sort_values(by, axis = 0, ascending = True)
by: 只对axis轴上的某个 索引 或 索引列表 进行排序 
NaN空值,保持在排序末尾
- Pandas统计分析函数
.sum() 计算数据总和,按0轴计算
.count() 非NaN值的数量
.mean() .median() 计算算术平均值、算术中位数
.var() .var() 计算方差、标准差
.min() .max 计算最小、大值
.argmin() .argmax() 计算最大、小值所在位置的索引(针对自动索引的)(适用于Series类型:)
.idxmin() .idxmax() 计算最大、小值所在位置的索引(针对自定义索引的)(适用于Series类型:)
.describe() 针对0轴(各列)的统计汇总 

- 数据的相关性
.cov() 计算协方差矩阵
.corr() 计算相关系数矩阵 