新手福利, 正经爬虫教学, 手把手抓取壳蛋网所有文章!
简介
首先看下我们的小白鼠站点: 壳蛋网,这是一个博客,主要是发布个人文章或者收录网上优质文章, 包含SEO丶网赚丶编程技术等内容。

接下来就通过实践一步一步的将整站文章抓取下来。
页面分析
观察这张图片:

可以发现其实导航栏就是一个分类来的, 所以我们要做的就算将右侧分类目录下的分类先抓取下来。

查看该图可以发现,分类是包含在一个class="widget_categories"的标签里面的。

里面的li标签对应的a标签链接,就是分类目录了,先将这些分类链接抓取下来。
随便点击一个文章多一点的分类: 随便点击一篇文章: 接下来就可以实战写代码了。 通过访问首页去解析分类div块内容,获取所有分类的名称和url。

可以看到尾页的页码和链接包裹在

文章列表均在article标签里面。
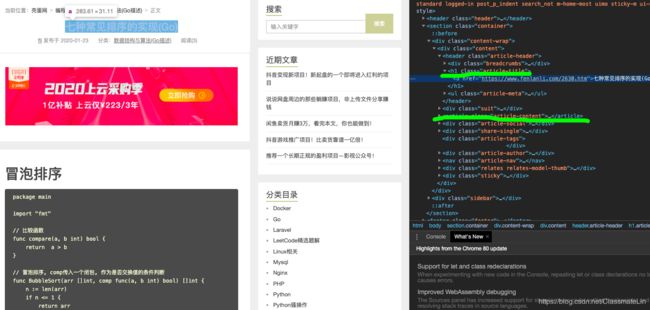
可以发现标题包裹在: 中, 文章内容题包裹在中。实战
爬取分类
import requests
from bs4 import BeautifulSoup
def fetch_html(url):
"""
获取网页html源码
:return:
"""
try:
response = requests.get(url)
return response.text
except Exception as e:
print(e.args)
return None
def get_category(url='https://www.fenlanli.com/'):
"""
:return:
"""
res = []
html = fetch_html(url)
soup = BeautifulSoup(html, 'html.parser')
category_div = soup.find('div', {'class': 'widget_categories'})
a_tag_list = category_div.find_all('a') # 查找分类块下所有的分类a标签
for a_tag in a_tag_list:
res.append({
'title': a_tag.text, # 取分类名称
'url': a_tag.attrs['href'] # 取分类链接
})
return res
if __name__ == '__main__':
categories = get_category()
print(categories)
爬取文章列表
def get_article_list(category: dict):
"""
获取文章链接
:return:
"""
articles = []
url = category['url']
title = category['title']
print('正在获取分类:{} 下的文章列表...'.format(title))
html = fetch_html(url)
# 正则表达式搜索尾页页码
search_page = re.findall('尾页
爬取文章详情
def save_article(q):
"""
:return:
"""
while not q.empty():
data = q.get()
save_dir = os.path.join(os.getcwd(), data['cate_name'])
if not os.path.exists(save_dir):
os.makedirs(save_dir)
title = data['title']
save_path = os.path.join(save_dir, title + '.html')
save_path.replace('/', r'\/') # 将/转义
print('正在获取文章: 《{}》内容...'.format(title))
url = data['url']
text = fetch_html(url)
soup = BeautifulSoup(text, 'html.parser')
# 将文章体保存, 文章标题跟之前拿到的是一样的,无需再提取
article_content = soup.find('article', {'class': 'article-content'})
with open(save_path, 'w') as f:
f.write(str(article_content))
完整代码
# _*_coding:utf8_*_
# Project: kdw_spider
# File: main.py
# Author: ClassmateLin
# Email: [email protected]
# Time: 2020/3/30 4:55 下午
# DESC:
import requests
from bs4 import BeautifulSoup
import re
import os
import queue
def fetch_html(url):
"""
获取网页html源码
:return:
"""
try:
response = requests.get(url)
return response.text
except Exception as e:
print(e.args)
return None
def get_category(url='https://www.fenlanli.com/'):
"""
:return:
"""
res = []
html = fetch_html(url)
soup = BeautifulSoup(html, 'html.parser')
category_div = soup.find('div', {'class': 'widget_categories'})
a_tag_list = category_div.find_all('a') # 查找分类块下所有的分类a标签
for a_tag in a_tag_list:
res.append({
'title': a_tag.text, # 取分类名称
'url': a_tag.attrs['href'] # 取分类链接
})
return res
def get_article_list(category: dict):
"""
获取文章链接
:return:
"""
articles = []
url = category['url']
title = category['title']
print('正在获取分类:{} 下的文章列表...'.format(title))
html = fetch_html(url)
# 正则表达式搜索尾页页码
search_page = re.findall('尾页共 (.*?) 页