Redis学习日记(五):内存管理
1、查看现在redis内存使用情况:使用 info memory 即可查看。
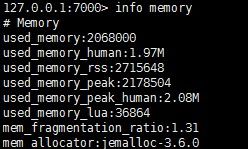
这里有3个内容我们得注意 : ①:used_memory :物理使用的内存空间(1.97M)。
② :user_memory_rss :操作系统认为Redis使用的内存空间。这里是(2.59M)。
③:mem_fragmentstion_ratio:② / ① 的值
> 1 表示内存碎片化严重; < 1 说明redis内存存在硬盘化情况
2、要管理内存先看下我们要管理什么内存,下面是内存的分类:
①:Redis 进程 本身所占的内存,这部分内存不大,可以暂时不考虑。
②:对象内存 ,这部分是主要的内存。
③:缓存内存,包括客户端输入输出缓存,AOF缓存(重写的时候写入命令),部分复制时的缓存(默认1M)
上述的3种内存之和就是 used_memory,那就有问题了,为什么会有 操作系统认为的内存(used_memory_rss)大于真正的内存呢?这里就牵扯到了redis的内存分配器了,我们可以看到 info memory 的最后一项:men_allocator :jemalloc 。jemalloc是默认的内存分配器,它分配内存的时候按照 小、大、巨大三个范围分配,举例说 我们要存储 5KB的内容,jemalloc分配的内存块大小可能就是8KB,这时3KB的内存就是内存碎片,这部分不能继续分配给其他对象。
知道了为什么碎片的来源,我们就知道了 used_memory + 碎片内存 = used_memory_rss 。 mem_fragmentstion_ratio 的意义:这个值越大,说明内存空间碎片化越严重。
3、知道了有哪些内存,我们就得去考虑怎么管理这些内存。
主要手段有两种:控制内存上限 和 控制内存回收策略。
控制内存上限
控制内存上限很简单,就是限制单点Redis 的最大使用内存量,这里的最大内存指的是 真正使用的内存量,也就是 used_memory,因为碎片内存的存在,所以实际消耗的内存量会大于 maxmemory。
设置 maxmemory 参数的值即可, 如动态的修改: config set maxmemory 4GB
内存回收
什么时候触发内存回收呢?
这里有两种情况:第一是在删除过期key的时候;第二是内存达到 maxmemory 触发内存回收策略。
删除过期key的内存有两种策略:
①:惰性删除:过期的key不主动删除,在客户端使用这个key 的时候读取key的过期时间,超时后删除key并返回空值。这种策略节省了 CPU 的消耗,但是也容易造成内存泄漏,key长时间不用但是一直保存在内存中,所以有了下面的这种删除过期key的策略。
②:定时任务删除:默认每秒运行10次定时任务,每次定时任务都会随机检查20个键,删除过期的key。定时任务还启用自适应算法来根据键的过期时间比例和快慢两种模式来回收键。
maxmemory-policy 控制的内存回收策略:
①:noeviction:默认策略,当达到内存上限的时候拒绝客户端写入,并报错,但是读命令还是能进行。
②:volatile-lru:根据LRU(Least Recently Used)删除 过期 key,当过期key没有时,回退到 noeviction 。
③:allkeys-lru :根据LRU 删除 key,直到腾出足够空间。
④:volatile-random:随机删除 过期 key ,直到腾出足够空间;
⑤:allkeys-random:随机删除 key,直到腾出足够空间
⑥:volatile-ttl:根据键值对象的 ttl 属性 ,删除最近要过期的key,如果没有,则回退到 noevicion。
频繁进行内存的回收成本非常大,主要包括查找符合的可回收键和删除可回收键。这里如果有从节点,还要考虑主节点的删除会使从节点也进行同步,放大了主节点的写操作。
4、了解了怎么管理内存,我们下一步就得考虑怎么优化内存了
①:针对key 和value 的缩减对象键值对象大小方法
简单的来说就是让key 和value 的长度小一些,在一个key能描述业务的情况下越短越好,如 user:{userId}:name 可以变成 u:{userId}:n 。 针对value 可以去掉不必要存储的数据,其次可以将value 序列化存储,采用高效的序列化方式,如protostuff ,kryo等。
②:使用共享对象池
Redis内部维持了一个 【0 ~ 9999】的整数对象池,当数据大量存在 【0 ~ 9999】 的数据的时候共享对象池能节省大量内存。但是这个共享对象池在 redis 使用 maxmemory + LRU 回收策略的时候失效,为什么呢?每隔 redis 对象都有一个属性叫做 lru,它记录了这个对象最后的使用时间,对象共享意味着 多个 引用共享同一个 对象,导致lru也被共享。如果没有设置maxmemory,那么就不会触发 LRU回收,所以这时共享对象池也是可以使用的。共享对象池只有在 maxmemory + LRU 模式下才会失效。
③:字符串优化
字符串采用简单动态字符串(SDS)的数据结构,内部存在预分配机制。
预分配机制通俗来说是个什么回事呢? 在 对字符串操作的时候,具体 删减字符串长度的时候不释放删减的空间,而是当做预分配的空间保留,对 字符串追加 的时候多分配一倍空间当做预分配空间(如 60字节的字符串追加60字节,最后至少240字节大小,这里多出来的120字节就是预分配空间),那这样的预分配有啥好处呢?好处就是减少了内存分配的次数。
对于字符串的预分配机制,我们应该小心它带来的空间浪费。
尽量减少字符串的追加操作,如append 和 setrange,改为直接使用set修改字符串。
字符串重构,如Json这样的结构的数据改为使用如使用 hash结构来存储,但是使用hash又会遇到一些问题需要注意,下面也会写到。
④:编码优化
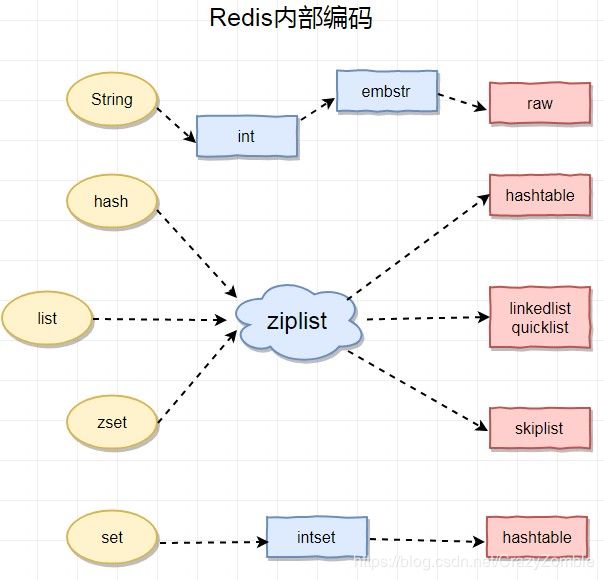
上图是Redis 内部编码的方式,这个编码类型在数据写入的时候即完成,随着数据的变化编码结构可能变化,但是编码结构只能从小变大,并且不可逆。其实从编码结构的变化也可以看做是由时间效率与空间效率的协调。
举个例子,list 类型 最开始的编码类型是ziplist,ziplist 的结构是带有头尾指针的连续内存空间,可以模拟为双向链表。存取的时间复杂度为 O(N^2),在数据量小的时候采用ziplist编码,这时因为数据量小即使时间复杂度为O(N^2)也有较高的时间效率,而ziplist的内存是非常小的,非常适合数据量小的时候使用,而当数据量大的时候,list编码就会变成linkedlist来提高相应的时间效率,而牺牲空间效率(因为链表的内存占用肯定比ziplist大)。
对于hash,list,zset 三种我们可以通过指定 {hash / list / zset}-max-ziplist-value (value最大空间)和 {hash / list / zset}-max-ziplist-entries (元素个数)来控制 编码从 ziplist 到后一种编码的转换时机。
而对于set 的编码优化,对于 整数类型的数据存储时 set使用intset的编码存储,它的内存和写入效率都非常高。当set类型的长度大于 set-max-intset-entries 或者不是整数类型的时候使用hashtable编码。所以用set来存储整数类型非常合适,可以把 set-max-intset-entries 设置大一些。
⑤:控制键的数量
使用ziplist 的hash类型来存储同等数量的 String类型的数据。