不带穷字但一听就是很穷的话----爬取微博评论
目录
过程
代码
结果
昨天逛微博的时候看到热门上有一条我很感兴趣的话题---不带穷字但一听就是很穷的话,点进去看笑了半天出不来,里面的人还真是个个都是人才,说话又好听,真的超喜欢在这里的。

下面我分享几条高赞的回答,第一个真的绝了,
看完评论我笑了,然后把手机还给了朋友--赞[87381]
自从垃圾分类之后,食物好找多了--赞[50931]
看了标签放下衣服,不必试穿了--赞[40559]
打微信通话吧,快欠费了--赞[26617]
时间就是金钱,你们去吧,我没时间--赞[17623]
我家里还有点事,我先回去了--赞[11676]
可以用花呗吗?--赞[14167]
我爱豆是SM的 --赞[11655]
拼多多帮我点一下--赞[11544]
你们吃吧我不饿--赞[11697]
啥?人民币都出到100块了?--赞[9440]
为了坐一块钱的公交,我走了二十分钟--赞[8034]
试穿了,不是很合身呢--赞[7474]
我钱包掉了,有个人捡到帮我送到了物业,我去拿的时候物业阿姨对我说:“证件都还在,就是里面钱没有了.” 从物业出来后,我坐在路边的长椅上,心里有点难过. 其实一分也没有少.--赞[6997]
我可以vx付一部分,zfb付一部分,然后剩下的用现金付吗--赞[6810]
你怕不是姓韦斯莱--赞[3627]
我这个还能用,不需要买新的。--赞[4067]
幸亏评论不要钱--赞[3950]
一元钱在你那边能买什么?--赞[5916]
自从垃圾分类之后,食物好找多了--赞[50944]
看了标签放下衣服,不必试穿了--赞[40566]
打微信通话吧,快欠费了--赞[26620]
时间就是金钱,你们去吧,我没时间--赞[17625]
我不喜欢喝奶茶,你们喝吧--赞[2808]
你的饭还吃的完吧,吃不完就让我来处理吧,在家里边追剧边用了款 变美了太多!集美加油 --赞[3260]
稍稍往旁边站站 挡着我喝西北风了--赞[2911]
要不是空气免费我根本活不到现在--赞[2437]
你们点你们的,我就不去了--赞[1344]
我爱上了拼夕夕 卸载了 --赞[1061]
外卖点满减最多 配送费最低--赞[1103]
过程
一开始是不想耗费精力去爬的,就搞了个微博API,但是发现更鬼麻烦,返回的token时间有效贼短,运行一次又要登录一次,返回的数据还是按时间排序的,而我想要的是前十页左右热门的,返回的数据还最多就800多条,听说是API限制的原因,一个小时1000条,我勒个去,API1000条数据拿来干嘛,还不如自己爬了。。。。返回的数据格式还花里胡哨的,不过可能大厂就是大厂,评论表涉及的内容众多。
这条路走不通就走小道了,以前试过爬取微博移动端的,只需要网页端扫码登录一下,然后把网址改到移动端,找到保存自己的cookie保存,几行代码就可以搞定了,不过实践证明有问题,数据是返回了,但是不知是不是运行速度问题,很多时候下一页的内容还是上一页的,所以导致了很多内容重复,不过没关系,我只是要前几页的,试了下爬200页,每页十条数据,最后去重只有480多条。这还是加了6秒的睡眠。一开始加1秒睡眠才100多条,也许是实时更新的,点赞数每一秒都在变化。。。。
这是网址构造:https://weibo.cn/comment/hot/IFz1niHwT?rl=1&page=9 需要网页端先登录,不然进不去,会自动重定向到网页端。
这是移动端的查找页面:https://weibo.cn/search/?tf=5_012
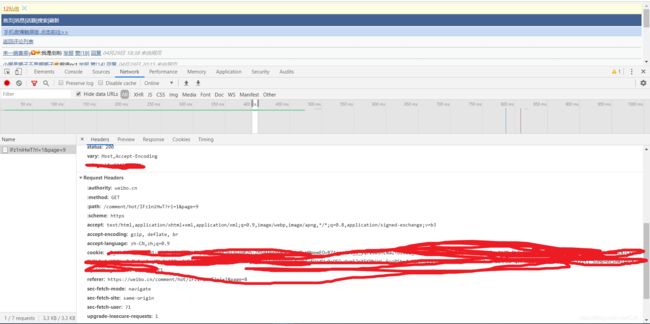
cookie
按F12打开network->headers,下面画了的就是cookie,保存下来要用。
代码
import requests,time,re
headers={
"cookie": "你的cookie",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"
}
file = open('不带穷字但一听就很穷的话_2.0.txt', 'a+',encoding='utf-8')
for i in range(1,201):
time.sleep(1)
res=requests.get("https://weibo.cn/comment/hot/IFz1niHwT?rl=1&page=%s"%i,headers=headers)
# print(res.text)
a=re.findall(r'(.*?)<',res.text)
b=re.findall(r'f">赞(.*?)',res.text)
all_comment=[]
for j in range(len(a)):
c=''
c+=a[j]+"--赞"+b[j]
all_comment.append(c)
# print(all_comment)
for j in all_comment:
file.write(str(j)+'\n')
time.sleep(2)
print('第%s页--ok'%i)
file.close() 结果

本文纯属瞎闹,各位看官笑了就点个赞再走吧!
我也来一句我的:一块钱一包的优乐美,一星期只敢喝一包。
不过说真的很多时候网友还真的是很有才,把中国文字体现的淋漓尽致,句句精妙绝伦,不得不说一个字:强!