CTR 预测理论(二十三):推荐系统用户兴趣特征表征方式
在推荐系统场景中,关于用户兴趣特征的表征对于提升最终模型点击率预估具有重要意义,结合已有资料,于此文对目前主流用户特征表征方式进行一次梳理。
引言
深度学习应用于推荐算法,经典操作就是将高维、稀疏categorical/id类特征通过embedding映射成一个低维、稠密向量(将原来高维、稀疏的categorical/id类特征的“精确匹配”,变为向量之间的“模糊查找”,从而提高了可扩展性)。
但是,表达用户兴趣时,用户的历史行为往往涉及多个categorical/id特征,比如点击过的多个商品、看过的多个视频、输入过的多个搜索词,需要各这些id特征embedding之后的多个低维向量,“合并”成一个向量,作为用户兴趣的表示,喂入DNN,这个“合并”就是所谓Pooling。
1. 现有用户兴趣特征表征方式
围绕着这个Pooling过程,各家有各家的高招:
-
Youtube DNN这篇论文中,Youtube的做法最简单、直观,就是将用户看过的视频embedding向量、搜索过的关键词embedding向量,做一个简单的平均。
-
Neural Factorization Machine中,使用如下公式,将n个(n=特征数)k维向量压缩成一个k维向量,取名为bi-interaction pooling。既完成pooling,也实现了特征间的二阶交叉。
f B I ( V x ) = ∑ i = 1 n ∑ j = i + 1 n x i v i ⊙ x j v j = 1 2 [ ( ∑ i = 1 n x i v i ) 2 − ∑ i = 1 n ( x i v i ) 2 ] f_{B I}\left(\mathcal{V}_{x}\right)=\sum_{i=1}^{n} \sum_{j=i+1}^{n} x_{i} \mathbf{v}_{i} \odot x_{j} \mathbf{v}_{j}=\frac{1}{2}\left[\left(\sum_{i=1}^{n} x_{i} \mathbf{v}_{i}\right)^{2}-\sum_{i=1}^{n}\left(x_{i} \mathbf{v}_{i}\right)^{2}\right] fBI(Vx)=i=1∑nj=i+1∑nxivi⊙xjvj=21⎣⎡(i=1∑nxivi)2−i=1∑n(xivi)2⎦⎤ -
DIN用各embedding向量的加权平均实现了pooling,而”权重”由attention机制计算得到。
-
基于深度学习的文本分类,同样面临着如何将一段话中的多个词向量压缩成一个向量来表示这段话的问题。常用的方法,就是将多个词向量喂入RNN,最后一个时刻RNN的输出向量就代表了多个词向量的“合并”结果。显然,DIEN则借鉴了这一思路,并且改造了GRU的构造,利用attention score来控制门。
- DIN与DIEN的相同之处,都是通过Attention来实现Pooling,使用户兴趣的向量表示,根据候选物料的不同而不同,实现用户兴趣的“千物千面”。
- 不同之处在于:DIN没有考虑用户历史之间的时序关系, DIEN则使用了GRU来建模用户历史的时间序列
2. 用户兴趣的千物千面
解释一下“用户兴趣的千物千面”,它也是DIN的创新之处。比如,一个用户之前买过奶粉与泳衣,当展示给她泳镜时,显然更会唤起她买过的泳衣的记忆;而当展示给她尿不湿时,显然更唤起她买过的奶粉的记忆。
DIN用attention机制实现了以上过程,用户兴趣向量 V u V_u Vu 是历史上接触过的item embedding向量的加权平均,而第i个历史item的权重 W i W_i Wi 由该历史 item 的 embedding 向量 V i V_i Vi 与候选物料的 embedding 向量 V a V_a Va 共同决定(函数g)。可见同一个用户当面对不同候选物料时,其兴趣向量也不相同,从而实现了“千物千面”。
V u = f ( V a ) = ∑ i = 1 N w i ∗ V i = ∑ i = 1 N g ( V i , V a ) ∗ V i V_{u}=f\left(V_{a}\right)=\sum_{i=1}^{N} w_{i} * V_{i}=\sum_{i=1}^{N} g\left(V_{i}, V_{a}\right) * V_{i} Vu=f(Va)=i=1∑Nwi∗Vi=i=1∑Ng(Vi,Va)∗Vi
上式就是DIN中用户兴趣的向量表示。
3. DIEN的兴趣表征方式
DIEN基本思路:
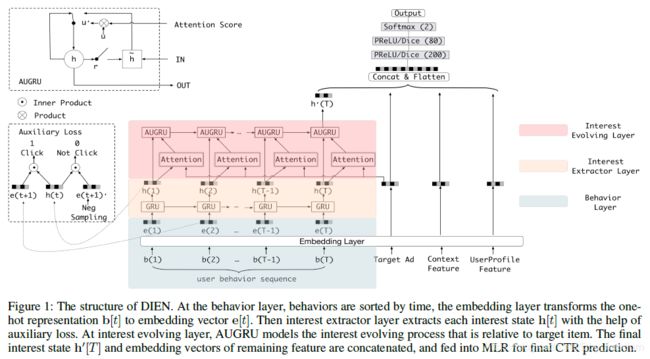
- 用户历史肯定是一个时间序列,将其喂入RNN,则最后一个状态可以认为包含了所有历史信息。因此,作者用一个双层的GRU来建模用户兴趣。
- 将用户历史接触过的item embedding微量,喂进第一层GRU,输出的就是用户各时刻的兴趣。这一层被称为Interest Extraction Layer
- 将第一层的输出,喂进第二层GRU,并用attention score(基于第一层的输出向量与候选物料计算得出)来控制第二层的GRU的update gate。这一层叫做Interest Evolving Layer。
- Interest Evolving Layer的最后一个状态作为用户兴趣的向量表示,与ad, context的特征一同喂入MLP,预测点击率。
参考文献
[1] https://zhuanlan.zhihu.com/p/54838663