【读论文】基于YOLOv3的红外行人小目标检测技术研究
摘要
基于 YOLOv3 中分类准确率仍有不足的情况,借鉴 SENet 中对特征进行权重重标定的思路,将 SE block 引入 YOLOv3 中,提升了网络的特征描述能力。通过对自行收集实际复杂场景下的红外图像进行目标 检测,试验验证了算法的可行性,实验结果表明本文提出的改进网络拥有更高的准确率和更低的虚警 率,同时保持了原有算法的实时性。
关键词:行人检测;红外小目标;深度学习;卷积神经网络
0.引言(关于Yolo的部分)
深度学习将图像领域中个个问题的处理精度都提升到了一个更高的水平,在目标检测领域,主要分为两类方法,一类通过区域打分来预测目标区域,然后通过神经网络来对区域进行分类,这类方法以R-CNN系列为代表,包括后续的fast R-CNN,faster R-CNN以及SSD等;另一类方法通过回归得出目标区域再通过神经网络分类,这类方法以YOLO,YOLO9000和YOLOv3为代表,这一系列的算法都在红外图像处理中有很多应用。
现有的检测算法中,以深度学习的目标检测算法 为优秀,不过 SSD、R-CNN 系列的网络复杂度过 高,即使使用运算速度非常高的 GPU 也仍然运行缓 慢,而 YOLO 系列的方法解决了网络复杂度过高的问 题,在主流的 GPU 上算法的运行速度达到 60 fps 以 上,能够满足实时性要求。本次研究中就以增强了小 目标检测能力的 YOLOv3 为主要网络,通过对网络进 行改进,进一步增强了特征描述能力,使其能够在实 际的红外小目标处理问题中得到应用。
1.原理
a.YOLOv3算法简介
(1)与同期的 fast R-CNN,faster R-CNN 等算法使用 区域建议网络预测目标可能的位置不同**,YOLO 直接 一次回归得出所有目标的可能位置**
(2) YOLOv3 在目标位置预测方面引入了 faster R-CNN 中使用锚点框(anchor box)的思想,在每一 个特征图上预测 3 个锚点框
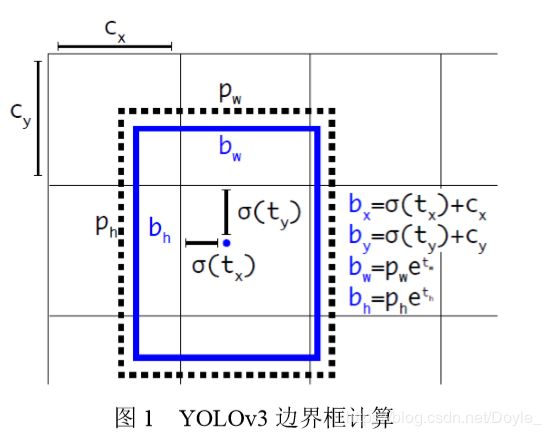
bw和 bh为边界框宽高,而 pw和 ph为锚点框的预测结果宽 高。 σ 是 sigmoid 函数,tx、ty、tw、th为网络预测的目标中心坐 标和宽高,cx、cy为当前网格左上角坐标
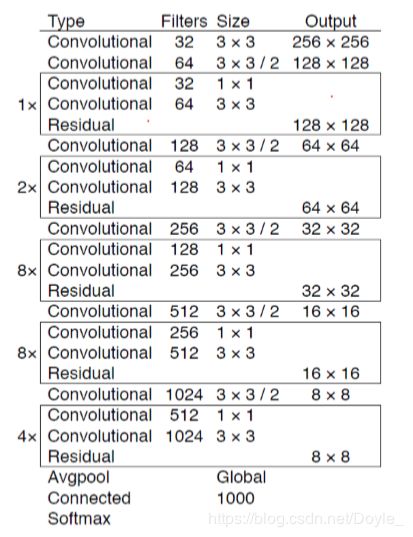
(3)YOLOv3 在目标的分类上使用了比之前深度更 大的神经网络,其网络中大量 3×3 和 1×1 的卷积核 保证了良好的特征提取,使用多尺度预测提升了小目 标的检测精度。更深的网络意味可以提取更复杂的特征,但训练难度也会相应增大,准确率也会下降。
如何解决:Resnet
YOLOv3借鉴Resnet的思想,引入了多个Resnet模块,设计了一个新的层数更多并且分类准确率更高的网络,由于其包含 53 个卷积层,作 者将其命名为 darknet-53
b.SENet简介
能够显著提高网络性能的新型网络模型。
前人做的工作:有从统计角度出发的方法,例如 dropout 通过随机减少网络间的连接来减少过拟合;有 从空间维度层面寻找提升的方法,例如 Inception 结构 嵌入多尺度信息,聚合多种不同感受野上的特征来获 得性能提升
SENet从特征通道间的关系出发,提出了一种特征重标定策略,这种 略通过显示建模特征通道间的相互依赖关系实现,可 以通过学习来获取到每个特征通道的重要程度,然后 根据这个主要程度来提升重要特征的权重并抑制不重要的特征。
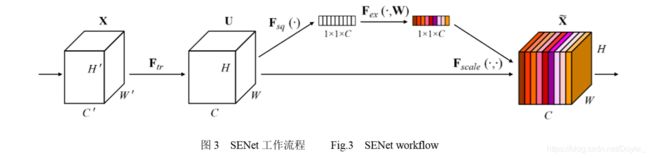
SENet包含两个关键操作,压缩和激励
压缩操作顺着空间维度来对提取到的特征进行压缩,将 每个二维的特征通道换算为一个实数
激励操作类似于循环神经网络中的门的机 制,通过学习参数 w 来为每个特征通道生成权重
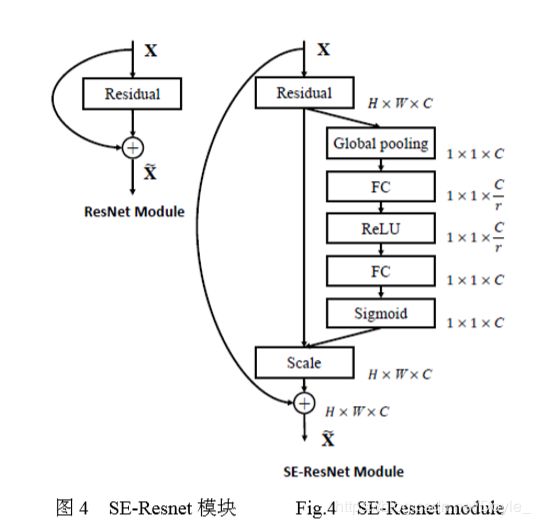
SENet作用的位置:插入在Resnet之后,,得到一个SE-Resnet 模块。
经过验证,在不同规模的Resnet上引入SENet,均能够大幅提升网络的准确率。
2.改进YOLOv3网络
在实际的红外行人小目标 数据中,直接使用 YOLOv3 对数据进行训练,后得 到的模型具有良好的召回率,但是准确率不够。
为了得到一个具有实时性,同时目标检测的准确率和虚警率都良好的算法模型,以 YOLOv3 为基础网络,结合 SENet 以提升分类网络的准确率 是一个可行的思路。
a.直接在卷积层后面接SENet可能遇到的问题:
网络本身含有大量的卷积层并且参数巨大,这样添加SENet模块增加的参数量大,且需要大量实验来确定哪些卷积层后面加入新模块。
b.用加入了 SENet 的模块替换原有网络中的 inception 或者 residual 层
这类方法替换位置较为明确,需要反复试验的可能性比较小
结论:因为在YOLOv3 中含有较多的 Residual 层,于是对网络的改进采取引入 SE-Resnet 模块的方法
如何使用
第一步:压缩操作
SE-Resnet 模块中,用 Global average pooling 层做 压缩操作,将每个特征通道变换成一个实数值,使== C 个特征图后变成一个 1×1×C 的实数序列==。被处理 的多个特征图可以被解释为从图像中提取到的局部 特征描述子的集合,每个特征图无法利用到其他特征 图的上下文信息。使用 Global average pooling 可以使 其拥有全局的感受野,从而让低层网络也能利用全局 信息。
第二步:激活操作
使用两个全连接层(full connected layer)结合ReLU函数去建模各个通道之间的相关性,并且其输出的权重数与输 入的特征数相同。
经过一个ReLU后经过一个全连接层升维到原来的维数
为了减少参数并且增强泛化能力,第一个全连接层将参数降维r倍。
第二个全连接层后使用sigmoid激活函数作为阈值门限,得到了一个 1×1×C 的序列,即每个特 征通道的权重。
每个特 征通道的权重。后将权重直接用乘法叠加到开始的 特征通道上,即完成了所有特征通道的权重重标定。
应该注意的点:SENet 模块的激活操作的实现中包含两个全连接 层,全连接层的参数量相对其他类型的网络层是大 的,因此添加过多的 SENet 模块将会导致网络参数规 模增大,影响目标检测算法的时间效率
根据作者的经验,添加在网络末端的SE模块对准确率的影响较小,所以末端的几个Residual块不做处理。
总结:
引入SENet的SE-Resnet模块可以简化表示为一个 Residual 模块下添加了一个 SE 模块。

YOLOv3 包含 23 个 Residual 块,从减少模型参数量优化避免 增加太多算法运行时间的角度考虑,只对每组卷积和残差层的后一个残差层进行替换。
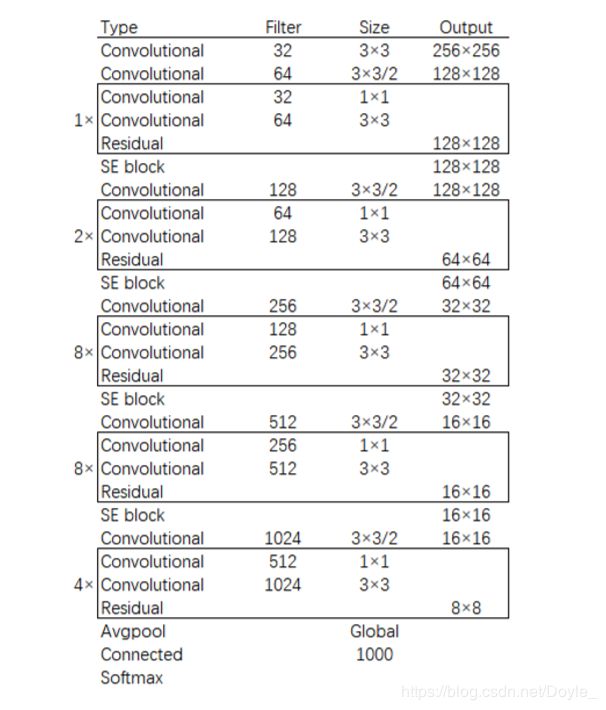
3.实验过程与结果
a.数据的收集与处理
b.模型训练
实验平台使用 Linux 16.04 LTS 系统,CPUX5670 @ 2.93GHz,GPU 为NVIDIA Quadro 5000,16 G 内存。 模型训练主要思路是使用已经在大规模数据集上训 练好的模型进行 fine-tune,在新数据集上继续训练模 型。以 YOLO 原作者在 COCO 和 VOC 上训练好的 darknet53 模型为基础模型,随机选取自建数据集中的 1710张图像作为训练集,其余的570张图像为测试集, 训练时初始学习率为 0.001,衰减系数为 0.0005,对 于 YOLOv3 原网络和改进后的网络都进行训练。
c.实验结果
数据集只有一类目标,采用召回率(recall)和准确率(precision)作为模型的评价标准。
准确率为网络预测的所有目标中真目标的比例,表征此网络的分类准确率;召回率为==网络预测 成功的真目标数与实际存在的真目标数的比值=,表征 此网络的查全率