用户复购行为预测--数据挖掘分析案例(天池/python)
–阿里天池新人赛中的一个,记录分享。
Repeat Buyers Prediction-Challenge the Baseline-天池大赛-阿里云天池
第一次提交:8简单特征,随机森林模型,score:0.5507327,排名:278
第二次提交:13特征,随机森林模型,score:0.5980033,排名:251
第三次提交:13特征,lightgbm模型,score:0.648646,排名:179
其实不止三次,控制变量提交过很多次,U. U。
用户复购行为预测
1.项目介绍
1.1背景和目的
淘宝卖家会做一系列营销活动以增长用户,但许多情况下,新增用户大多不会复购,不利于卖家的长远利益。因此对于卖家来说,定位较大概率会复购的用户很重要,可以降低营销成本并提高ROI。
阿里天池提供了在“双十一”期间的一组卖家及其相应的新买家数据集,包括这些新买家在前半年的购物行为日志,以及在后半年是否有复购的记录。
通过对上述数据集的挖掘分析,预测新用户的复购行为,为店铺运营提供高效的营销决策。
1.2数据集范围和结构
数据集来自淘宝抽取的一组某年双11期间店铺的新买家,并采集了这批用户的前半年用户日志、用户信息

基于上述数据集的关系,在处理数据时要注意以下几点:
(1)用户日志及信息是基于用户匹配的,所以user_log中的店铺数量要多于format中的;
(2)由于是新卖家,所以format表中与log表中基于用户和店铺的购买信息并无交集;
(3)train_format和test_format基于用户和店铺是无交集的,但是基于用户是有交集的;
2.分析思路和方法
案例运用特征工程的方法论进行用户复购行为预测,以下是三个挖掘分析重点:
(1)理解分析业务逻辑
用户复购行为,考虑用户自身因素和商家因素,一般来说是商家提供的产品和服务能较好地满足用户需求;

对于上述商品需求、消费水平等都是定性因素,我们需要将其分解成尽量多的可量化的业务数据指标,这些指标需要逻辑上可解释、可计算,数据表现有差异和各指标间相对独立;
(2)挖掘复购行为的特征
经探索性数据分析后,通过对比分析,相关性分析,降维,构造等方式,筛选指标生成特征,并将特征数据转换成合适的类型(常见的有log变换,u变换,比例等)用于建模。发现或构造特征比较有意思的,有创造性的工作很香,但最基本的是要考虑周全,先有锦,再添花。
一种蠢蠢的但是又不错的方式是考虑所有的维度的相互组合和限制:比如说案例中的用户消费行为,从统计方面上可以考虑次数,平均数,最大最小值,比例等;与时间维度组合可以考虑XX时间范围内的购买次数,XX时间范围内的购买频率加权等,与商品大类维度组合可考虑用户商品需求方向等。
需要注意的是,很多维度的数据需要同时考虑绝对值及比例,不然容易出现著名的辛普森悖论
(3)选择合适的模型
比较过多元线性回归、随机森林及lightgbm,发现lightgbm在运行时间及预测准确度上都高于其他,故使用lightgbm(其实为什么好这么多,我也不是很清楚原理哈哈哈哈,会开车的人也不一定会造车,不过后面一定得补上,不然容易翻车-. -)。
3.探索性数据分析 (关键步骤和方法)
3.1探索数据结构/缺失值/异常值
(1)数据大小和特征
user_log.shape #数据行列
user_log.dtypes #字段数据类型
user_log.nunique() #字段去重值
(2)缺失值处理
user_log.isnull().sum()
#发现年龄性别上有NaN,因有明确意义,所以不处理
#发现brandid有空值,不处理,它代表的是它没有品牌或者品牌没有收录到官方数据中
(3)异常值处理
#从上面的nunique()中看到没什么异常值
#时间维度上是5月11-11月21,很正常
#商品,店铺等字段数据类型都一样,认为其没有异常值
3.2数据对比分析
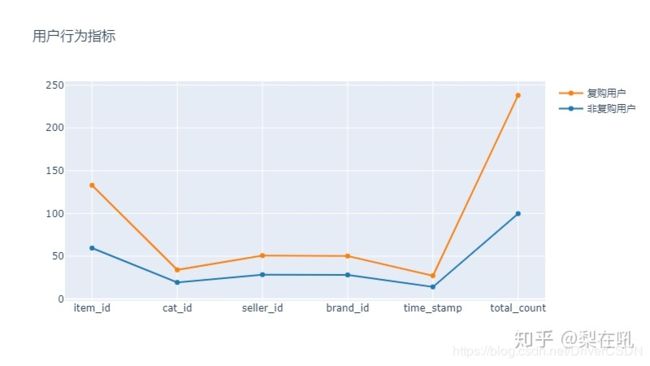
由于目标是预测复购行为,那么基于用户是否有在同一店铺复购过,将user_log分成半年内复购过的用户群及无复购的用户群进行对比分析,对比发现差异。
(1)各维度数据描述统计对比分析
(2)年龄性别对比分析
从均值和方差上看,复购用户各项均值都明显高于不复购用户,说明复购群体浏览更多类别,商店,登录次数更多,从方差上看,复购群体方差也明显大,说明复购行为用户群数据差异大,推测这些指标都是“弱指标”。
#该板块用到的方法或函数:
#isin(),用于筛选字段值的方法之一,a[a[b].isin(c)],返回a的b字段含有c的行,相反的用法a[~(a[b].isin(c))]
#groupby(),对dataframe进行分组,后可加上聚合函数;
#nunique(),聚合函数之一,统计字段中的的唯一值
#count(),聚合函数之一,统计字段中的个数
#describe(),描述字段的统计性数据
#drop_duplicates(),按一定的方式去除字段中的重复值
#pd.merge(),dataframe的连接函数
#reset_index(),重置dataframe的index
#rename(),改字段,索引等名
#assign(),添加新字段,可以避免dataframe的copywarning问题
3.3复购数据分析
除了将用户分群,对比分析各维度数据外,从逻辑上看,用户的本身的复购行为次数,店铺的销售数与重复销售数,以及用户与店铺之间的匹配度对预测的贡献应该更大。
(1)复购用户数据分析
a.用户在同一店铺复购次数
b.在多少个店铺复购过
c.店铺复购率
d.复购平均次数
(2)店铺销售与重销售分析
a.店铺的销售数量
b.店铺重销售数量
c.重销售比例
(3)用户-店铺匹配分析
a.新复购用户在之前在同类店铺的购买次数
#可以考虑将店铺根据商品大类聚类后计算销售比例,但由于数据的局限性且不可溯源,这里就没这样做。
#该板块用到的方法或函数与上面基本相同,都是一些处理dataframe的函数。
4.整理特征
经上述分析后,已经基本可以确定哪些因素跟复购是有联系的,在复购和不复购的群体中是有差别,接下来就是要对这些数据进行计算处理
4.1数据变换
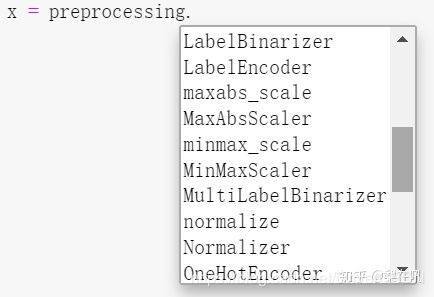
scikit-learn库中的preproccessing类,提供了很多数据变换的方法,如:标准化:StandardScaler(),区间化:MinMaxScaler()等,
4.2相关性分析
特征处理好后,可以用相关性来进行特征筛选,python中有简便的函数corr(),求相关系数,相关系数越大认为与预测结果越相关。店铺重销售率、新用户此前在同类商店中购买次数及店铺重销售数的与复购行为相关性较高,其实也挺符合常理的。

5.跑模型
选lightgbm的原因上面有提到,但是这个模型让我惊艳之处是:

6.小结:
模型算法能大大推动实际业务,实现更精准、高效的营销,以此案例为例,根据预测结果可采取下述措施:
1.对经预测的高概率复购的用户发放更大额的优惠券,提高复购用户的转化率和长期收益。
2.根据自身用户的复购周期,对预测高概率高的,超出复购周期还没复购的用户,与预测概率低的用户,做差异化的召回活动。
3.持续跟进复购行为,挖掘更多更好的特征。
不足之处(仅限于我察觉到的不足):
1.理论上无法对对半年内的新用户(数据日志很少)进行预测。
2.特征不够细致,如上面提到的店铺分类可能效果更好
3.数据维度不够多,如消费金额,购买时有无用优惠券,各店铺是否包邮等