pdf文本和表格处理——pdfplumber的安装与简单使用
pdf的文本和表格处理用多种方式可以实现, 本文介绍pdfplumber对文本和表格提取。这个库在GitHub上星300多,不过使用起来很方便, 效果也很好,可以满足对pdf中信息的提取需求。
文章目录
- pdfplumber简介
- pdfplumber安装
- 简单使用
- 一些常用的方法
- Visual Debugging可视化调试
pdfplumber简介
Pdfplumber是一个可以处理pdf格式信息的库。可以查找关于每个文本字符、矩阵、和行的详细信息,也可以对表格进行提取并进行可视化调试。
pdfplumber安装
安装直接采用pip即可。命令行中输入
pip install pdfplumber
如果要进行可视化的调试,则需要安装ImageMagick。
Pdfplumber GitHub: https://github.com/jsvine/pdfplumber
ImageMagick地址:
http://docs.wand-py.org/en/latest/guide/install.html#install-imagemagick-windows
(官网地址没有6x, 6x地址:https://imagemagick.org/download/binaries/)
(注意:我在装ImageMagick,使用起来是报错了, 网上参照了这里 了解到应该装6x版,7x版会报错。故找了6x的地址如上。)
在使用to_image函数输出图片时,如果报错DelegateException。则安装GhostScript 32位。(注意,一定要下载32位版本,哪怕Windows和python的版本是64位的。)1
GhostScript: https://www.ghostscript.com/download/gsdnld.html
简单使用
最基本的用法如下,读取pdf中的某一页。
import pdfplumber
with pdfplumber.open("path/to/file.pdf") as pdf:
first_page = pdf.pages[0]
print(first_page.chars[0])
pdfplumber.pdf中包含了.metadata和.pages两个属性。
.metadata是一个包含pdf信息的字典。
.pages是一个包含页面信息的列表。
每个pdfplumber.page的类中包含了几个主要的属性。
.page_number 页码
.width 页面宽度
.height 页面高度
.objects/.chars/.lines/.rects 这些属性中每一个都是一个列表,每个列表都包含一个字典,每个字典用于说明页面中的对象信息, 包括直线,字符, 方格等位置信息。
一些常用的方法
.extract_text() 用来提页面中的文本,将页面的所有字符对象整理为的那个字符串
.extract_words() 返回的是所有的单词及其相关信息
.extract_tables() 提取页面的表格
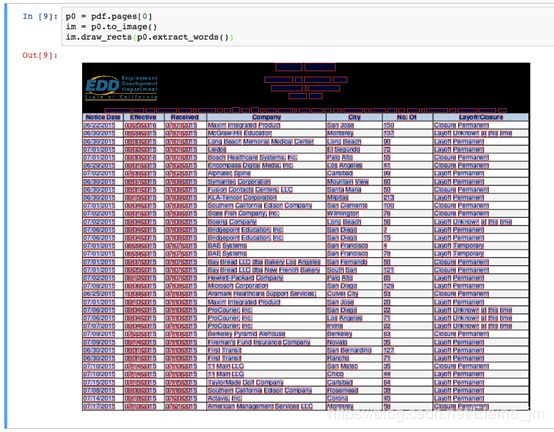
.to_image() 用于可视化调试时,返回PageImage类的一个实例
import pdfplumber
import pandas as pd
with pdfplumber.open("中新科技:2015年年度报告摘要.PDF") as pdf:
page = pdf.pages[1] # 第一页的信息
text = page.extract_text()
print(text)
table = page.extract_tables()
for t in table:
# 得到的table是嵌套list类型,转化成DataFrame更加方便查看和分析
df = pd.DataFrame(t[1:], columns=t[0])
print(df)
显示文本:

显示表格:
![]()
Visual Debugging可视化调试
Pdfplumber提供的图形debug功能,能够获取pdf页面中的表格,并对识别的信息用框框起来,并进行调整,以优化识别的情况。
具体可参照GitHub上给出的示例。
在 https://github.com/jsvine/pdfplumber/tree/master/examples
https://blog.csdn.net/blmoistawinde/article/details/82051915 ↩︎