未明学院:用excel不好吗?为什么还要学python?
原创: 未明学院

在互联网管理、金融、物流等领域,往往离不开数据处理、统计分析等辅助决策的操作。
传统的商业分析(Business Analysis),定性占比很大,以相对简单的数据处理为辅助,人们使用的分析工具主要是Excel;然而,自Excel2007版起,最大支持的工作表大小为16,384 列 × 1,048,576 行,超出最大行列数单元格中的数据将会丢失。
在大数据背景的今天,面对千万条以上动辄成百上千G的数据,单用excel难免显得力不从心,越来越多的人将关注点转向python。
1、易踩坑!Excel输给Python
(1)数据量级太大,报表来不及保存,Excel崩溃无响应
比如,工作中经常需要对一个表进行删除重复值处理,当工作表中格式过于复杂、数据量过于庞大时,Excel在计算时容易报错崩溃。

而python在数据处理的量级和性能上明显高于excel,对python来说,只需调用drop_duplicates方法就可以轻松处理大批量数据,无需担心软件崩溃异常退出。
Python的处理方法如下:
调用方法:
DataFrame.drop_duplicates(subset=None,keep='first', inplace=False)
————————————————
参数说明:
subset: column label or sequence of labels, optional
用来指定特定的列,默认所有列
keep :{‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项
inplace: boolean, default False
选择直接在原来数据上修改或是保留一个副本
—————————————————

删除重复行
(2)操作繁琐,人工处理容易粗心犯错
我们经常会遇到从一个Excel表格拷贝一些数据,粘贴到另一个Excel表格中去的情况;或者从多个表格中,合并含有重复列的旧表格为新表。
这些工作并不困难,却需要耗费大量人工审核的时间,且容易出错。

利用python,可以放心交给机器做运算,一行命令解决人工需点击上百次的工作。
Python处理方法如下:
设置循环遍历,匹配关键字,按照列名自动分割数据存储至本地

pandas自动分列操作
(3)重复性工作,效率低下
在做图表时,由于每个报表都需要做对应的图表,人工重复性操作N个报表,效率低下。
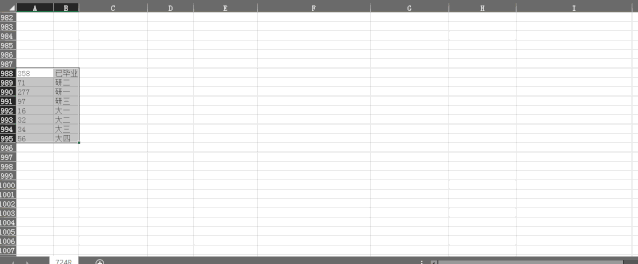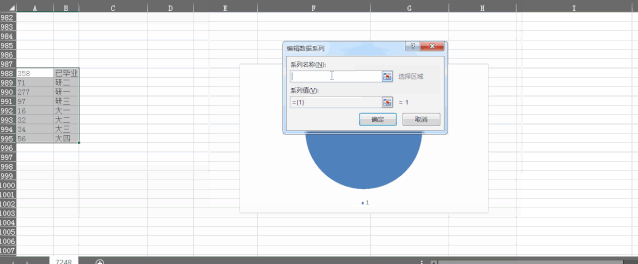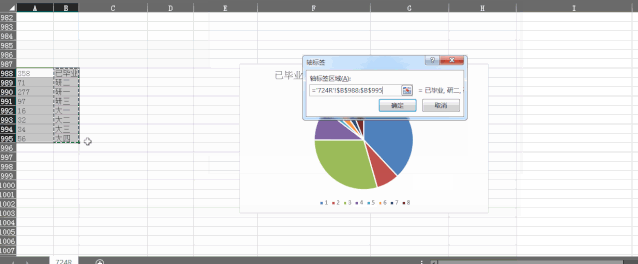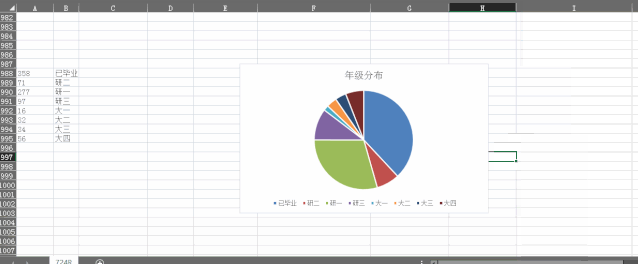
但是运用Python,可以调用已经集成好的工具包,自动化收集和清理数据,保存和刷新报表,对数据进行可视化展示。
Python处理方法如下:
对多个图表进行批量处理,并且轻松输出可视化内容,相比excel要高效得多。

2、小白学Python,压力大吗?
听起来Python是不是很高大上的样子?但事实上,即便是小白也能驾驭这样的“高大上”技能!
简单易学,速度快,正是学习Python的优点之一。Python说明文档极其简单,它更专注于解决问题而不是研究计算机语言本身,所以小白也能轻松上手!
![]()
以Python使用openpyxl读写excel文件为例:
导入相关函数:
from openpyxl import load_workbook
加载表格:
wb = load_workbook('XX.xlsx')
# 读取当前sheet最大行
print(sheet.max_row)
# 在A1单元格处写入特定值
sheet['A1']= 'good'
# 在单元格B9内写入平均值公式
sheet['B9']= '=AVERAGE(B2:B8)'
你看,阅读Python代码,就像在阅读高中英语文章!
3、精力,得放到数据分析上来
当下,熟练运用数据分析工具只是数据分析师的技术能力要求,更多的,在业务上,要有通过数据发现问题和解决问题的能力,参与到产品的设计、运营、销售整个流程,从数据中反馈结论。
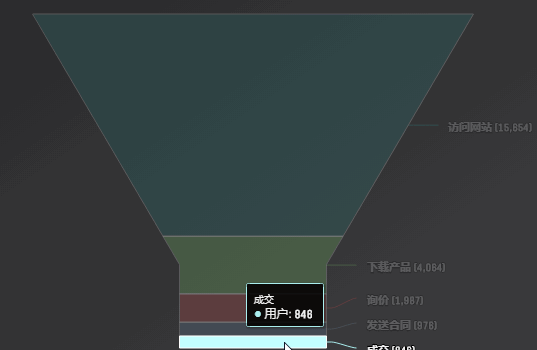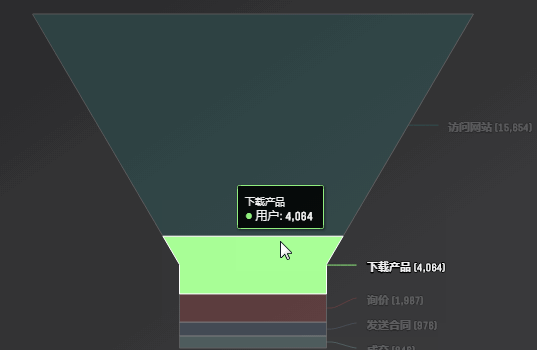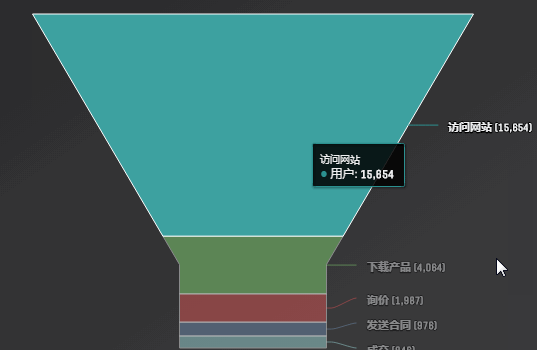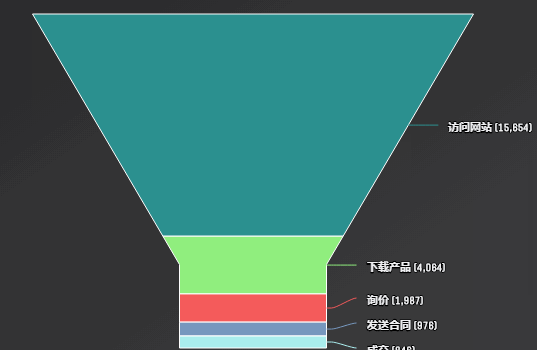
漏斗图
用excel做数据处理,VBA函数晦涩难懂上手慢,大部分人仅停留在能够绘制基本图形的水平,天天统计报表,浪费了太多精力,几乎没有时间进行任何实际的分析或预测。
但是学习Python,简单的代码就能替代机械操作和纯体力劳动,可以让我们把更多时间转到数据分析上来。

响应式图表
![]()
想象这样的场景:当你把10多个sheet的数据分别做excel图表,人工粘贴到powerpoint中,再调颜色、格式、大小,还要写一堆注释进行说明,而团队还嫌逻辑混乱……
你还有什么理由不来学习python呢?