google play store的app数据分析
google play store app数据源 提取码: 38jk
google play store的app数据分析
1. 加载数据
- 加载数据分析使用的库
- 加载数据前,先用文本编辑器简单浏览一下数据
- 加载好数据之后,第一步先分别使用shape、head、count、describe和info方法看下数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 加载文件
# 这次只分析'App', 'Category', 'Rating', 'Reviews', 'Size', 'Installs', 'Type'
df = pd.read_csv('./googleplaystore.csv', usecols=(0, 1, 2, 3, 4, 5, 6))
# 简单浏览下数据
print(df.head())
# 查看行列数量
print(df.shape)
# 查看各个列的非空数量
print(df.count())
# 使用describe和info方法看下数据的大概分布
print(df.describe())
print(df.info())
App Category Rating \
0 Photo Editor & Candy Camera & Grid & ScrapBook ART_AND_DESIGN 4.1
1 Coloring book moana ART_AND_DESIGN 3.9
2 U Launcher Lite – FREE Live Cool Themes, Hide ... ART_AND_DESIGN 4.7
3 Sketch - Draw & Paint ART_AND_DESIGN 4.5
4 Pixel Draw - Number Art Coloring Book ART_AND_DESIGN 4.3
Reviews Size Installs Type
0 159 19M 10,000+ Free
1 967 14M 500,000+ Free
2 87510 8.7M 5,000,000+ Free
3 215644 25M 50,000,000+ Free
4 967 2.8M 100,000+ Free
(10841, 7)
App 10841
Category 10841
Rating 9367
Reviews 10841
Size 10841
Installs 10841
Type 10840
dtype: int64
Rating
count 9367.000000
mean 4.193338
std 0.537431
min 1.000000
25% 4.000000
50% 4.300000
75% 4.500000
max 19.000000
RangeIndex: 10841 entries, 0 to 10840
Data columns (total 7 columns):
App 10841 non-null object
Category 10841 non-null object
Rating 9367 non-null float64
Reviews 10841 non-null object
Size 10841 non-null object
Installs 10841 non-null object
Type 10840 non-null object
dtypes: float64(1), object(6)
memory usage: 592.9+ KB
None
- 从上面的运行结果得出
- 数据一共有10841行
- Rating和Type数据有缺失
- Rating有一个19的异常值
- Size的‘M’和‘k’和Installs的‘+’都需要处理,方便进一步计算
2. 数据清洗 # App
- 查看有没有重复值
print(df['App'].unique().size)
9660
- 有重复值,先不着急删除,为了不把其他列的异常值留下,先处理数值异常的列
3. 数据清洗 # Categoery
print(df['Category'].value_counts(dropna=False))
print(df[df['Category'] == '1.9'])
FAMILY 1972
GAME 1144
TOOLS 843
MEDICAL 463
BUSINESS 460
PRODUCTIVITY 424
PERSONALIZATION 392
COMMUNICATION 387
SPORTS 384
LIFESTYLE 382
FINANCE 366
HEALTH_AND_FITNESS 341
PHOTOGRAPHY 335
SOCIAL 295
NEWS_AND_MAGAZINES 283
SHOPPING 260
TRAVEL_AND_LOCAL 258
DATING 234
BOOKS_AND_REFERENCE 231
VIDEO_PLAYERS 175
EDUCATION 156
ENTERTAINMENT 149
MAPS_AND_NAVIGATION 137
FOOD_AND_DRINK 127
HOUSE_AND_HOME 88
AUTO_AND_VEHICLES 85
LIBRARIES_AND_DEMO 85
WEATHER 82
ART_AND_DESIGN 65
EVENTS 64
COMICS 60
PARENTING 60
BEAUTY 53
1.9 1
Name: Category, dtype: int64
App Category Rating Reviews \
10472 Life Made WI-Fi Touchscreen Photo Frame 1.9 19.0 3.0M
Size Installs Type
10472 1,000+ Free 0
- 有一条异常值,观察发现应该是Category值缺失,所以这里删除这条数据
df.drop(index=10472, inplace=True)
4. 数据清洗 # Rating
print(df['Rating'].value_counts(dropna=False))
NaN 1474
4.4 1109
4.3 1076
4.5 1038
4.2 952
4.6 823
4.1 708
4.0 568
4.7 499
3.9 386
3.8 303
5.0 274
3.7 239
4.8 234
3.6 174
3.5 163
3.4 128
3.3 102
4.9 87
3.0 83
3.1 69
3.2 64
2.9 45
2.8 42
2.6 25
2.7 25
2.5 21
2.3 20
2.4 19
1.0 16
2.2 14
1.9 13
2.0 12
1.8 8
1.7 8
2.1 8
1.6 4
1.5 3
1.4 3
1.2 1
Name: Rating, dtype: int64
- 一共有1474条NaN值,用平均值来填充
df['Rating'].fillna(value=df['Rating'].mean(), inplace=True)
5. 数据清洗 # Reviews
print(df['Rating'].value_counts(dropna=False))
print(df['Reviews'].str.isnumeric().sum())
4.193338 1474
4.400000 1109
4.300000 1076
4.500000 1038
4.200000 952
4.600000 823
4.100000 708
4.000000 568
4.700000 499
3.900000 386
3.800000 303
5.000000 274
3.700000 239
4.800000 234
3.600000 174
3.500000 163
3.400000 128
3.300000 102
4.900000 87
3.000000 83
3.100000 69
3.200000 64
2.900000 45
2.800000 42
2.700000 25
2.600000 25
2.500000 21
2.300000 20
2.400000 19
1.000000 16
2.200000 14
1.900000 13
2.000000 12
2.100000 8
1.800000 8
1.700000 8
1.600000 4
1.400000 3
1.500000 3
1.200000 1
Name: Rating, dtype: int64
10840
- 用value_counts看数据分布挺广,都是数字
- 把Reviews的数据类型转换成‘i8’,方便后面的分析
df['Reviews'] = df['Reviews'].astype('i8')
print(df.describe())
Rating Reviews
count 10840.000000 1.084000e+04
mean 4.191757 4.441529e+05
std 0.478907 2.927761e+06
min 1.000000 0.000000e+00
25% 4.100000 3.800000e+01
50% 4.200000 2.094000e+03
75% 4.500000 5.477550e+04
max 5.000000 7.815831e+07
6. 数据清洗 # Size
print(df['Size'].value_counts())
Varies with device 1695
11M 198
12M 196
14M 194
13M 191
15M 184
17M 160
19M 154
26M 149
16M 149
25M 143
20M 139
21M 138
10M 136
24M 136
18M 133
23M 117
22M 114
29M 103
27M 97
28M 95
30M 84
33M 79
3.3M 77
37M 76
35M 72
31M 70
2.9M 69
2.3M 68
2.5M 68
...
809k 1
39k 1
691k 1
241k 1
954k 1
378k 1
203k 1
887k 1
754k 1
253k 1
11k 1
787k 1
992k 1
626k 1
857k 1
54k 1
862k 1
743k 1
642k 1
234k 1
313k 1
82k 1
549k 1
400k 1
240k 1
778k 1
161k 1
478k 1
89k 1
154k 1
Name: Size, Length: 461, dtype: int64
- 数据中存在‘M’和‘k’需要处理,还存在字符串1695个‘Varies with device’
- 把‘Varies with device’用‘0’来替换
- 把Size数据类型转换成f8
- 然后再用平均值来填充‘0’值
df['Size'] = df['Size'].str.replace('M', 'e+6')
df['Size'] = df['Size'].str.replace('k', 'e+3')
# 转换剩下的字符串
df['Size'] = df['Size'].str.replace('Varies with device', '0')
# 转换数据类型
df['Size'] = df['Size'].astype('f8')
df['Size'].replace(0, df['Size'].mean(), inplace=True)
df['Size']
0 1.900000e+07
1 1.400000e+07
2 8.700000e+06
3 2.500000e+07
4 2.800000e+06
5 5.600000e+06
6 1.900000e+07
7 2.900000e+07
8 3.300000e+07
9 3.100000e+06
10 2.800000e+07
11 1.200000e+07
12 2.000000e+07
13 2.100000e+07
14 3.700000e+07
15 2.700000e+06
16 5.500000e+06
17 1.700000e+07
18 3.900000e+07
19 3.100000e+07
20 1.400000e+07
21 1.200000e+07
22 4.200000e+06
23 7.000000e+06
24 2.300000e+07
25 6.000000e+06
26 2.500000e+07
27 6.100000e+06
28 4.600000e+06
29 4.200000e+06
...
10811 3.900000e+06
10812 1.300000e+07
10813 2.700000e+06
10814 3.100000e+07
10815 4.900000e+06
10816 6.800000e+06
10817 8.000000e+06
10818 1.500000e+06
10819 3.600000e+06
10820 8.600000e+06
10821 2.500000e+06
10822 3.100000e+06
10823 2.900000e+06
10824 8.200000e+07
10825 7.700000e+06
10826 1.815209e+07
10827 1.300000e+07
10828 1.300000e+07
10829 7.400000e+06
10830 2.300000e+06
10831 9.800000e+06
10832 5.820000e+05
10833 6.190000e+05
10834 2.600000e+06
10835 9.600000e+06
10836 5.300000e+07
10837 3.600000e+06
10838 9.500000e+06
10839 1.815209e+07
10840 1.900000e+07
Name: Size, Length: 10840, dtype: float64
print(df.describe())
Rating Reviews Size
count 10840.000000 1.084000e+04 1.084000e+04
mean 4.191757 4.441529e+05 2.099045e+07
std 0.478907 2.927761e+06 2.078345e+07
min 1.000000 0.000000e+00 8.500000e+03
25% 4.100000 3.800000e+01 5.900000e+06
50% 4.200000 2.094000e+03 1.800000e+07
75% 4.500000 5.477550e+04 2.600000e+07
max 5.000000 7.815831e+07 1.000000e+08
7. 数据清洗 # Installs
- 先查看分布
print(df['Installs'].value_counts())
1,000,000+ 1579
10,000,000+ 1252
100,000+ 1169
10,000+ 1054
1,000+ 907
5,000,000+ 752
100+ 719
500,000+ 539
50,000+ 479
5,000+ 477
100,000,000+ 409
10+ 386
500+ 330
50,000,000+ 289
50+ 205
5+ 82
500,000,000+ 72
1+ 67
1,000,000,000+ 58
0+ 14
0 1
Name: Installs, dtype: int64
- 分布比较少,直接替换
df['Installs'] = df['Installs'].str.replace('+', '')
df['Installs'] = df['Installs'].str.replace(',', '')
- 转换数据类型为‘i8’
df['Installs'] = df['Installs'].astype('i8')
print(df.describe())
Rating Reviews Size Installs
count 10840.000000 1.084000e+04 1.084000e+04 1.084000e+04
mean 4.191757 4.441529e+05 2.099045e+07 1.546434e+07
std 0.478907 2.927761e+06 2.078345e+07 8.502936e+07
min 1.000000 0.000000e+00 8.500000e+03 0.000000e+00
25% 4.100000 3.800000e+01 5.900000e+06 1.000000e+03
50% 4.200000 2.094000e+03 1.800000e+07 1.000000e+05
75% 4.500000 5.477550e+04 2.600000e+07 5.000000e+06
max 5.000000 7.815831e+07 1.000000e+08 1.000000e+09
8. 数据清洗 # Type
- info信息中查看到有na值,这里需要dropna参数
print(df['Type'].value_counts(dropna=False))
print(df[df['Type'].isnull()])
Free 10039
Paid 800
NaN 1
Name: Type, dtype: int64
App Category Rating Reviews Size \
9148 Command & Conquer: Rivals FAMILY 4.191757 0 1.815209e+07
Installs Type
9148 0 NaN
- 删除这条数据
df.drop(index=9148, inplace=True)
- 最后删除App重复的行
df.drop_duplicates('App', inplace=True)
- 数据清洗完毕,可以开始分析了
- 整体情况
print(df.describe())
Rating Reviews Size Installs
count 9658.000000 9.658000e+03 9.658000e+03 9.658000e+03
mean 4.176046 2.166150e+05 2.011053e+07 7.778312e+06
std 0.494383 1.831413e+06 2.040865e+07 5.376100e+07
min 1.000000 0.000000e+00 8.500000e+03 0.000000e+00
25% 4.000000 2.500000e+01 5.300000e+06 1.000000e+03
50% 4.200000 9.670000e+02 1.600000e+07 1.000000e+05
75% 4.500000 2.940800e+04 2.500000e+07 1.000000e+06
max 5.000000 7.815831e+07 1.000000e+08 1.000000e+09
9. 数据分析 # Category&App
- 分类的个数
print(df.Category.unique().size)
33
- 每个分类的App数量,排序,可以得出哪些分类的App最受开发者欢迎
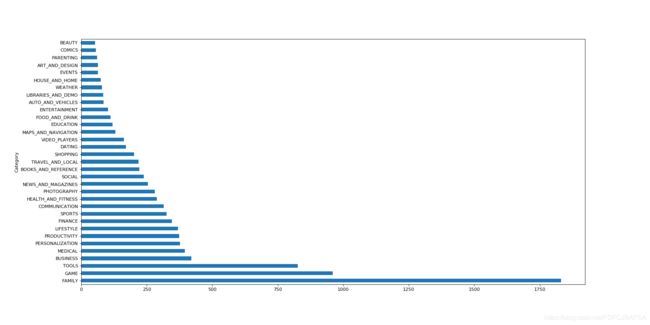
Category_App_count = df.groupby('Category').count().sort_values('App', ascending=False)['App']
print(Category_App_count)
plt.figure(figsize=(20,10),dpi=80)
Category_App_count.plot(kind='barh')
plt.savefig('./Category_App_count.png')
plt.show()
Category
FAMILY 1831
GAME 959
TOOLS 827
BUSINESS 420
MEDICAL 395
PERSONALIZATION 376
PRODUCTIVITY 374
LIFESTYLE 369
FINANCE 345
SPORTS 325
COMMUNICATION 315
HEALTH_AND_FITNESS 288
PHOTOGRAPHY 281
NEWS_AND_MAGAZINES 254
SOCIAL 239
BOOKS_AND_REFERENCE 222
TRAVEL_AND_LOCAL 219
SHOPPING 202
DATING 171
VIDEO_PLAYERS 163
MAPS_AND_NAVIGATION 131
EDUCATION 119
FOOD_AND_DRINK 112
ENTERTAINMENT 102
AUTO_AND_VEHICLES 85
LIBRARIES_AND_DEMO 84
WEATHER 79
HOUSE_AND_HOME 74
EVENTS 64
ART_AND_DESIGN 64
PARENTING 60
COMICS 56
BEAUTY 53
Name: App, dtype: int64
- 33个分类App的数据可视化
- App数量排名前十分类的数据可视化
count_top_10 = df.groupby('Category').count()['App'].sort_values(ascending=False)[:10]
print(count_top_10)
plt.figure(figsize=(20,10),dpi=80)
x = count_top_10.index
y = count_top_10.values
# 添加数据标签
for a, b in zip(x, y):
plt.text(a, b, b, ha='center', va='bottom', fontsize=12)
plt.bar(x, y, width=0.5)
plt.savefig('./count_top_10.png')
plt.show()
Category
FAMILY 1831
GAME 959
TOOLS 827
BUSINESS 420
MEDICAL 395
PERSONALIZATION 376
PRODUCTIVITY 374
LIFESTYLE 369
FINANCE 345
SPORTS 325
Name: App, dtype: int64

10. 数据分析 # Category&Installs
- 33种分类的安装量排序
- 安装量前10分类的可视化
# 33种分类的安装量排序
Category_Installs_mean = df.groupby('Category').mean()['Installs'].sort_values( ascending=False)
print(Category_Installs_mean)
# 安装量前10分类的可视化
mean_top_10 = df.groupby('Category').mean()['Installs'].sort_values( ascending=False)[:10]
print(mean_top_10)
plt.figure(figsize=(20,10),dpi=80)
x = mean_top_10.index
y = mean_top_10.values.astype('i8')
# 添加数据标签
for a, b in zip(x, y):
plt.text(a, b, b, ha='center', va='bottom', fontsize=12)
plt.bar(x, y, width=0.5)
plt.savefig('./mean_top_10.png')
plt.show()
Category
COMMUNICATION 3.504215e+07
VIDEO_PLAYERS 2.409143e+07
SOCIAL 2.296179e+07
ENTERTAINMENT 2.072216e+07
PHOTOGRAPHY 1.654501e+07
PRODUCTIVITY 1.548955e+07
GAME 1.447229e+07
TRAVEL_AND_LOCAL 1.321866e+07
TOOLS 9.675661e+06
NEWS_AND_MAGAZINES 9.327629e+06
BOOKS_AND_REFERENCE 7.504367e+06
SHOPPING 6.932420e+06
WEATHER 4.570893e+06
PERSONALIZATION 4.075784e+06
HEALTH_AND_FITNESS 3.972300e+06
MAPS_AND_NAVIGATION 3.841846e+06
SPORTS 3.373768e+06
EDUCATION 2.965983e+06
FAMILY 2.418319e+06
FOOD_AND_DRINK 1.891060e+06
ART_AND_DESIGN 1.786533e+06
BUSINESS 1.659916e+06
LIFESTYLE 1.365375e+06
FINANCE 1.319851e+06
HOUSE_AND_HOME 1.313682e+06
DATING 8.241293e+05
COMICS 8.032348e+05
LIBRARIES_AND_DEMO 6.309037e+05
AUTO_AND_VEHICLES 6.250613e+05
PARENTING 5.253518e+05
BEAUTY 5.131519e+05
EVENTS 2.495806e+05
MEDICAL 9.669159e+04
Name: Installs, dtype: float64
Category
COMMUNICATION 3.504215e+07
VIDEO_PLAYERS 2.409143e+07
SOCIAL 2.296179e+07
ENTERTAINMENT 2.072216e+07
PHOTOGRAPHY 1.654501e+07
PRODUCTIVITY 1.548955e+07
GAME 1.447229e+07
TRAVEL_AND_LOCAL 1.321866e+07
TOOLS 9.675661e+06
NEWS_AND_MAGAZINES 9.327629e+06
Name: Installs, dtype: float64
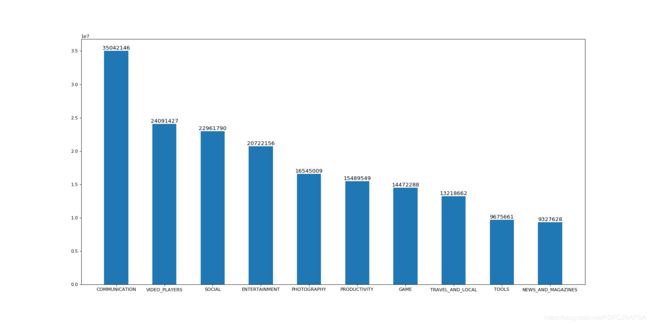
- 得出结论:娱乐社交类安装量最多
11. 数据分析 # Category&Reviews
- 33种分类的评论数量排序
- 评论数量前10分类的可视化
# 33种分类的评论数量排序
Category_Reviews_mean = df.groupby('Category').mean()['Reviews'].sort_values(ascending=False)
print(Category_Reviews_mean)
# 33种分类的评论数量排序
top_mean_10 = df.groupby('Category').mean()['Reviews'].sort_values(ascending=False)[:10]
print(top_mean_10)
plt.figure(figsize=(20,10),dpi=80)
x = top_mean_10.index
y = top_mean_10.values.astype('i8')
# 添加数据标签
for a, b in zip(x, y):
plt.text(a, b, b, ha='center', va='bottom', fontsize=12)
plt.bar(x, y, width=0.5)
plt.savefig('./top_mean_10.png')
plt.show()
Category
SOCIAL 953672.807531
COMMUNICATION 907337.676190
GAME 648903.763295
VIDEO_PLAYERS 414015.754601
PHOTOGRAPHY 374915.551601
ENTERTAINMENT 340810.294118
TOOLS 277335.644498
SHOPPING 220553.118812
WEATHER 155634.987342
PRODUCTIVITY 148638.098930
PERSONALIZATION 142401.808511
MAPS_AND_NAVIGATION 135337.007634
TRAVEL_AND_LOCAL 122464.570776
EDUCATION 112303.764706
SPORTS 108765.578462
NEWS_AND_MAGAZINES 91063.889764
FAMILY 78550.239214
BOOKS_AND_REFERENCE 75321.234234
HEALTH_AND_FITNESS 74171.371528
FOOD_AND_DRINK 56473.464286
COMICS 41822.696429
FINANCE 36701.756522
LIFESTYLE 32066.859079
HOUSE_AND_HOME 26079.013514
BUSINESS 23548.202381
ART_AND_DESIGN 22175.046875
DATING 21190.315789
PARENTING 15972.183333
AUTO_AND_VEHICLES 13690.188235
LIBRARIES_AND_DEMO 10795.607143
BEAUTY 7476.226415
MEDICAL 2994.863291
EVENTS 2515.906250
Name: Reviews, dtype: float64
Category
SOCIAL 953672.807531
COMMUNICATION 907337.676190
GAME 648903.763295
VIDEO_PLAYERS 414015.754601
PHOTOGRAPHY 374915.551601
ENTERTAINMENT 340810.294118
TOOLS 277335.644498
SHOPPING 220553.118812
WEATHER 155634.987342
PRODUCTIVITY 148638.098930
Name: Reviews, dtype: float64

- 得出结论:社交游戏视频评论多
12. 数据分析 # Category&Rating
- 分类的打分数据
Category_Rating_mean = df.groupby('Category').mean()['Rating'].sort_values(ascending=False)
print(Category_Rating_mean)
Category
EVENTS 4.363178
EDUCATION 4.362956
ART_AND_DESIGN 4.349614
BOOKS_AND_REFERENCE 4.308393
PERSONALIZATION 4.303077
PARENTING 4.281960
BEAUTY 4.260553
GAME 4.244643
SOCIAL 4.238926
WEATHER 4.238510
HEALTH_AND_FITNESS 4.235199
SHOPPING 4.225835
SPORTS 4.211275
AUTO_AND_VEHICLES 4.190601
PRODUCTIVITY 4.185022
COMICS 4.181848
LIBRARIES_AND_DEMO 4.181371
FAMILY 4.181137
FOOD_AND_DRINK 4.175461
MEDICAL 4.173252
PHOTOGRAPHY 4.159614
HOUSE_AND_HOME 4.156771
NEWS_AND_MAGAZINES 4.135385
ENTERTAINMENT 4.135294
COMMUNICATION 4.134647
BUSINESS 4.133347
FINANCE 4.125060
LIFESTYLE 4.111489
TRAVEL_AND_LOCAL 4.087380
TOOLS 4.059615
VIDEO_PLAYERS 4.058137
MAPS_AND_NAVIGATION 4.051854
DATING 4.018100
Name: Rating, dtype: float64
12. 数据分析 # Category&Type
- 分type数据
print(df.groupby('Type')['App'].count())
print(df.groupby('Type').sum()['Installs'].sort_values(ascending=False))
Type
Free 8902
Paid 756
Name: App, dtype: int64
Type
Free 75065572646
Paid 57364881
Name: Installs, dtype: int64
- 免费占比大,收费占比小,免费仍然是主流
- Category和Type一起分析
df.groupby(['Type', 'Category']).sum()['Reviews'].sort_values(ascending=False)
Type Category
Free GAME 620725858
COMMUNICATION 285727154
TOOLS 229184641
SOCIAL 227927559
FAMILY 140192916
PHOTOGRAPHY 105236039
VIDEO_PLAYERS 67471201
PRODUCTIVITY 55418928
PERSONALIZATION 53249927
SHOPPING 44551246
SPORTS 35198178
ENTERTAINMENT 34752641
TRAVEL_AND_LOCAL 26801668
NEWS_AND_MAGAZINES 23130027
HEALTH_AND_FITNESS 21315562
MAPS_AND_NAVIGATION 17721960
BOOKS_AND_REFERENCE 16719518
EDUCATION 13329503
FINANCE 12638908
WEATHER 12158723
LIFESTYLE 11785249
BUSINESS 9865113
FOOD_AND_DRINK 6321631
Paid FAMILY 3632572
Free DATING 3621936
COMICS 2342071
HOUSE_AND_HOME 1929847
Paid GAME 1572851
Free ART_AND_DESIGN 1417037
MEDICAL 1162965
...
BEAUTY 396240
Paid PERSONALIZATION 293153
TOOLS 171937
PRODUCTIVITY 171721
Free EVENTS 161018
Paid SPORTS 150635
WEATHER 136441
PHOTOGRAPHY 115231
COMMUNICATION 84214
LIFESTYLE 47422
HEALTH_AND_FITNESS 45793
EDUCATION 34645
BUSINESS 25132
FINANCE 23198
MEDICAL 20006
TRAVEL_AND_LOCAL 18073
VIDEO_PLAYERS 13367
ENTERTAINMENT 10009
PARENTING 8366
MAPS_AND_NAVIGATION 7188
AUTO_AND_VEHICLES 4163
FOOD_AND_DRINK 3397
ART_AND_DESIGN 2166
BOOKS_AND_REFERENCE 1796
DATING 1608
SHOPPING 484
SOCIAL 242
NEWS_AND_MAGAZINES 201
LIBRARIES_AND_DEMO 4
EVENTS 0
Name: Reviews, Length: 63, dtype: int64
- 评论安装比
Type_Category = df.groupby(['Type', 'Category']).mean()
print((Type_Category['Reviews'] / Type_Category['Installs']).sort_values(ascending=False))
Type Category
Paid VIDEO_PLAYERS 0.188268
FAMILY 0.175913
WEATHER 0.168031
PARENTING 0.166986
DATING 0.141674
ART_AND_DESIGN 0.135375
FINANCE 0.124988
PRODUCTIVITY 0.121611
SPORTS 0.121107
BUSINESS 0.118115
TOOLS 0.099533
TRAVEL_AND_LOCAL 0.098727
HEALTH_AND_FITNESS 0.096587
PERSONALIZATION 0.089958
AUTO_AND_VEHICLES 0.083011
BOOKS_AND_REFERENCE 0.077029
GAME 0.074898
COMMUNICATION 0.061920
PHOTOGRAPHY 0.061334
MAPS_AND_NAVIGATION 0.059356
EDUCATION 0.057550
FOOD_AND_DRINK 0.056617
Free COMICS 0.052068
Paid ENTERTAINMENT 0.050045
SHOPPING 0.047921
Free GAME 0.044792
SOCIAL 0.041533
Paid SOCIAL 0.040333
LIFESTYLE 0.040218
LIBRARIES_AND_DEMO 0.040000
...
Free MAPS_AND_NAVIGATION 0.035221
PERSONALIZATION 0.034821
WEATHER 0.033747
SPORTS 0.032138
SHOPPING 0.031815
FAMILY 0.031809
MEDICAL 0.030903
PARENTING 0.030185
FOOD_AND_DRINK 0.029856
TOOLS 0.028648
FINANCE 0.027768
COMMUNICATION 0.025888
DATING 0.025703
LIFESTYLE 0.023446
PHOTOGRAPHY 0.022645
AUTO_AND_VEHICLES 0.021844
HOUSE_AND_HOME 0.019852
HEALTH_AND_FITNESS 0.018640
VIDEO_PLAYERS 0.017182
LIBRARIES_AND_DEMO 0.017111
ENTERTAINMENT 0.016443
BEAUTY 0.014569
BUSINESS 0.014155
ART_AND_DESIGN 0.012395
EVENTS 0.010081
BOOKS_AND_REFERENCE 0.010036
NEWS_AND_MAGAZINES 0.009763
PRODUCTIVITY 0.009569
TRAVEL_AND_LOCAL 0.009259
Paid EVENTS 0.000000
Length: 63, dtype: float64
- 收费的App评论比率高
13. 数据分析 # 相关性 corr
print(df.corr())
Rating Reviews Size Installs
Rating 1.000000 0.054337 0.052751 0.039245
Reviews 0.054337 1.000000 0.080578 0.625164
Size 0.052751 0.080578 1.000000 0.050675
Installs 0.039245 0.625164 0.050675 1.000000
- 评论数和安装数强相关,其他的连0.1都不到,可以认为是不相关(0.5以上可以认为是相关的,0.3以上可以认为是弱相关)