CNN review: AlexNet;ResNet;Faster R-CNN;
The input of CNN
Some rgb image like 28*28*3 array( the resolution is 28*28 while *3 means r g b three chanel).
The output of CNN
The probability of several classes like (dog 10% cat 1% others ...)
The whole CNN looks like
input - > conv -> Relu -> conv -> ReLU->Pool -> ReLU -> Conv -> ReLU -> Pool ->FullyConnected
The conv layer
This layer uses filter to convolve the image. The block that is convolving is called receptive field. Each size of the step of the filter moving is called stride. For example, a*b*3 image and we use N c*c*3 filters to convolve this image we got (a-c+1)*(b-c+1)*N array which called activation map.
Each layer can extract some feature of the imgae. a FullyConnected layer looks at what high level features most strongly correlate to a particular class and has particular weights so that when you compute the products between the weights and the previous layer, you get the correct probabilities for the different classes.
Padding
Padding is used to prevent the message from losing by adding some zeros

It's used to preserve input dimension.
Max pooling
Pooling is used to help prevent overfitting.

Dropout layer
It's used to prevent overfitting by setting some neurons values into zero randomly during trainging process.
Relu layer
This layer include some neurons with function max(0,x) which do not change the dimension of the input and change all the negative values into postive one.
Connected layer
Asssume that we have a a*b*c input to the connected layer. The connected layer is a like a conv layer. Its kernel is the same size as the input which means in this example, the kernel is a * b * c and the amount of the filters is the amount of the classes.
Tranining
(1)stochastic gradient descent
we should set the following parameters to make it work
momentum usally set as 0.9,bigger data needs bigger momentum.
weight decay: the regularization leads to this term.
batch size:how many examples are we going to use to update the gradient.
Transfer learning
It can help us to reduce time to train the network by accepting other's network and freezing some layers then we can just train the some layers(For example output layer).
Mini-batch normalization
Mini-batch normalization means we use normalization to the hidden layers. After using mini-batch normalization, we can increase learning rate alpha a little bit to speed up the learning process.

ResNet
The above CNN net is called AlexNet, now we need to improve the depth of this network by making the stacked layers to approximate the following residual function : F(x):=H(x) - x. thus the original function becomes F(x) + x.(this x term is truly important here. With x, our network can become much deeper cuz in the worst situation F(x)=0 and the error will not accumulate corresponding to the network's depth)
10-crop casting
It's a way to measure validation error.REMEMBER !!! we should always plot the curve to know the performance of our network.
For example cost corresponding the iterations and so on.
deeper bottleneck architecture
A bottleneck layer is a layer that contains few nodes compared to the previous layers.
It can help to reduce the training time.
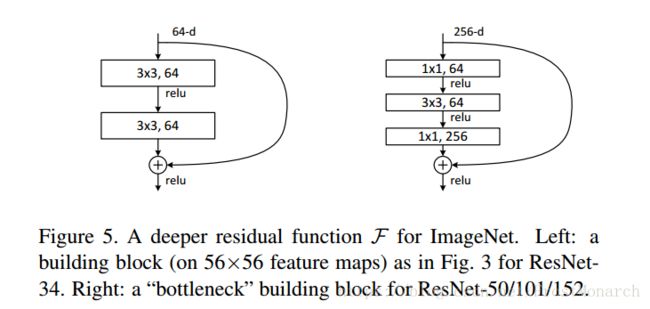
the bottlenet architecture shown above
FLOPS
It's used to describe the complexity of the algorithm.
Layer responses
We can compute the layer responses by computing standard deviation.
Faster R-CNN
The above architecture is called faster R-CNN. Dotted line box inside the R-CNN is the architecture of RPN.
RPN feature
RPN is used to produce region proposals.
The output of the Faster R-CNN is a box(from regressor) and its probability (from classification)of the foreground(detected object).

IN R-CNN we are freely to design the ratio of the anchor.
hyper-parameter
It was set before training.
IoU
area of overlap / area of union
Autoencoders
It's used to lower the dimension of the input like PCA.

sparsity
Also we can force the hidden layer close to 0 to learn some interesting feature.


where J(W,b) is:

Visualization
By maximally activating a hidden unit(For sigmoid function which means let the function close to 1), we can see what a input image looks like describing the feature this unit looks for.

Every hidden unit would have a image !
Local correspondence
It means how well we behave in image segmentation.
End to end training
It means we train the network just using the data set omitting any hand-crafted intermediary algorithm.
Dense
Also means fully connected.