大白话解析模拟退火算法、遗传算法入门
优化算法入门系列文章目录(更新中):
1. 模拟退火算法
2. 遗传算法
一. 爬山算法 ( Hill Climbing )
介绍模拟退火前,先介绍爬山算法。爬山算法是一种简单的贪心搜索算法,该算法每次从当前解的临近解空间中选择一个最优解作为当前解,直到达到一个局部最优解。
爬山算法实现很简单,其主要缺点是会陷入局部最优解,而不一定能搜索到全局最优解。如图1所示:假设C点为当前解,爬山算法搜索到A点这个局部最优解就会停止搜索,因为在A点无论向那个方向小幅度移动都不能得到更优的解。

图1
二. 模拟退火(SA,Simulated Annealing)思想
爬山法是完完全全的贪心法,每次都鼠目寸光的选择一个当前最优解,因此只能搜索到局部的最优值。模拟退火其实也是一种贪心算法,但是它的搜索过程引入了随机因素。模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。以图1为例,模拟退火算法在搜索到局部最优解A后,会以一定的概率接受到E的移动。也许经过几次这样的不是局部最优的移动后会到达D点,于是就跳出了局部最大值A。
模拟退火算法描述:
若J( Y(i+1) )>= J( Y(i) ) (即移动后得到更优解),则总是接受该移动
若J( Y(i+1) )< J( Y(i) ) (即移动后的解比当前解要差),则以一定的概率接受移动,而且这个概率随着时间推移逐渐降低(逐渐降低才能趋向稳定)
这里的“一定的概率”的计算参考了金属冶炼的退火过程,这也是模拟退火算法名称的由来。
根据热力学的原理,在温度为T时,出现能量差为dE的降温的概率为P(dE),表示为:
P(dE) = exp( dE/(kT) )
其中k是一个常数,exp表示自然指数,且dE<0。这条公式说白了就是:温度越高,出现一次能量差为dE的降温的概率就越大;温度越低,则出现降温的概率就越小。又由于dE总是小于0(否则就不叫退火了),因此dE/kT < 0 ,所以P(dE)的函数取值范围是(0,1) 。
随着温度T的降低,P(dE)会逐渐降低。
我们将一次向较差解的移动看做一次温度跳变过程,我们以概率P(dE)来接受这样的移动。
关于爬山算法与模拟退火,有一个有趣的比喻:
爬山算法:兔子朝着比现在高的地方跳去。它找到了不远处的最高山峰。但是这座山不一定是珠穆朗玛峰。这就是爬山算法,它不能保证局部最优值就是全局最优值。
模拟退火:兔子喝醉了。它随机地跳了很长时间。这期间,它可能走向高处,也可能踏入平地。但是,它渐渐清醒了并朝最高方向跳去。这就是模拟退火。
下面给出模拟退火的伪代码表示。
三. 模拟退火算法伪代码

 代码
代码
* J(y):在状态y时的评价函数值
* Y(i):表示当前状态
* Y(i+1):表示新的状态
* r: 用于控制降温的快慢
* T: 系统的温度,系统初始应该要处于一个高温的状态
* T_min :温度的下限,若温度T达到T_min,则停止搜索
*/
while( T > T_min )
{
dE = J( Y(i+1) ) - J( Y(i) ) ;
if ( dE >=0 ) //表达移动后得到更优解,则总是接受移动
Y(i+1) = Y(i) ; //接受从Y(i)到Y(i+1)的移动
else
{
// 函数exp( dE/T )的取值范围是(0,1) ,dE/T越大,则exp( dE/T )也
if ( exp( dE/T ) > random( 0 , 1 ) )
Y(i+1) = Y(i) ; //接受从Y(i)到Y(i+1)的移动
}
T = r * T ; //降温退火 ,0
/*
* 若r过大,则搜索到全局最优解的可能会较高,但搜索的过程也就较长。若r过小,则搜索的过程会很快,但最终可能会达到一个局部最优值
*/
i ++ ;
}
四. 使用模拟退火算法解决旅行商问题
旅行商问题 ( TSP , Traveling Salesman Problem ) :有N个城市,要求从其中某个问题出发,唯一遍历所有城市,再回到出发的城市,求最短的路线。
旅行商问题属于所谓的NP完全问题,精确的解决TSP只能通过穷举所有的路径组合,其时间复杂度是O(N!) 。
使用模拟退火算法可以比较快的求出TSP的一条近似最优路径。(使用遗传算法也是可以的,我将在下一篇文章中介绍)模拟退火解决TSP的思路:
1. 产生一条新的遍历路径P(i+1),计算路径P(i+1)的长度L( P(i+1) )
2. 若L(P(i+1)) < L(P(i)),则接受P(i+1)为新的路径,否则以模拟退火的那个概率接受P(i+1) ,然后降温
3. 重复步骤1,2直到满足退出条件
产生新的遍历路径的方法有很多,下面列举其中3种:
1. 随机选择2个节点,交换路径中的这2个节点的顺序。
2. 随机选择2个节点,将路径中这2个节点间的节点顺序逆转。
3. 随机选择3个节点m,n,k,然后将节点m与n间的节点移位到节点k后面。
五. 算法评价
模拟退火算法是一种随机算法,并不一定能找到全局的最优解,可以比较快的找到问题的近似最优解。 如果参数设置得当,模拟退火算法搜索效率比穷举法要高。
遗传算法 ( GA , Genetic Algorithm ) ,也称进化算法 。 遗传算法是受达尔文的进化论的启发,借鉴生物进化过程而提出的一种启发式搜索算法。因此在介绍遗传算法前有必要简单的介绍生物进化知识。
一.进化论知识
作为遗传算法生物背景的介绍,下面内容了解即可:
种群(Population):生物的进化以群体的形式进行,这样的一个群体称为种群。
个体:组成种群的单个生物。
基因 ( Gene ) :一个遗传因子。
染色体 ( Chromosome ) :包含一组的基因。
生存竞争,适者生存:对环境适应度高的、牛B的个体参与繁殖的机会比较多,后代就会越来越多。适应度低的个体参与繁殖的机会比较少,后代就会越来越少。
遗传与变异:新个体会遗传父母双方各一部分的基因,同时有一定的概率发生基因变异。
简单说来就是:繁殖过程,会发生基因交叉( Crossover ) ,基因突变 ( Mutation ) ,适应度( Fitness )低的个体会被逐步淘汰,而适应度高的个体会越来越多。那么经过N代的自然选择后,保存下来的个体都是适应度很高的,其中很可能包含史上产生的适应度最高的那个个体。
二.遗传算法思想
借鉴生物进化论,遗传算法将要解决的问题模拟成一个生物进化的过程,通过复制、交叉、突变等操作产生下一代的解,并逐步淘汰掉适应度函数值低的解,增加适应度函数值高的解。这样进化N代后就很有可能会进化出适应度函数值很高的个体。
举个例子,使用遗传算法解决“0-1背包问题”的思路:0-1背包的解可以编码为一串0-1字符串(0:不取,1:取) ;首先,随机产生M个0-1字符串,然后评价这些0-1字符串作为0-1背包问题的解的优劣;然后,随机选择一些字符串通过交叉、突变等操作产生下一代的M个字符串,而且较优的解被选中的概率要比较高。这样经过G代的进化后就可能会产生出0-1背包问题的一个“近似最优解”。
编码:需要将问题的解编码成字符串的形式才能使用遗传算法。最简单的一种编码方式是二进制编码,即将问题的解编码成二进制位数组的形式。例如,问题的解是整数,那么可以将其编码成二进制位数组的形式。将0-1字符串作为0-1背包问题的解就属于二进制编码。
遗传算法有3个最基本的操作:选择,交叉,变异。
选择:选择一些染色体来产生下一代。一种常用的选择策略是 “比例选择”,也就是个体被选中的概率与其适应度函数值成正比。假设群体的个体总数是M,那么那么一个体Xi被选中的概率为f(Xi)/( f(X1) + f(X2) + …….. + f(Xn) ) 。比例选择实现算法就是所谓的“轮盘赌算法”( Roulette Wheel Selection ) ,轮盘赌算法的一个简单的实现如下:
轮盘赌算法
* 按设定的概率,随机选中一个个体
* P[i]表示第i个个体被选中的概率
*/
int RWS()
{
m =0;
r =Random(0,1); //r为0至1的随机数
for(i=1;i<=N; i++)
{
/* 产生的随机数在m~m+P[i]间则认为选中了i
* 因此i被选中的概率是P[i]
*/
m = m + P[i];
if(r<=m) return i;
}
}
交叉(Crossover):2条染色体交换部分基因,来构造下一代的2条新的染色体。例如:
交叉前:
00000|011100000000|10000
11100|000001111110|00101
交叉后:
00000|000001111110|10000
11100|011100000000|00101
染色体交叉是以一定的概率发生的,这个概率记为Pc 。
变异(Mutation):在繁殖过程,新产生的染色体中的基因会以一定的概率出错,称为变异。变异发生的概率记为Pm 。例如:
变异前:
000001110000000010000
变异后:
000001110000100010000
适应度函数 ( Fitness Function ):用于评价某个染色体的适应度,用f(x)表示。有时需要区分染色体的适应度函数与问题的目标函数。例如:0-1背包问题的目标函数是所取得物品价值,但将物品价值作为染色体的适应度函数可能并不一定适合。适应度函数与目标函数是正相关的,可对目标函数作一些变形来得到适应度函数。
三.基本遗传算法的伪代码
基本遗传算法伪代码
* Pc:交叉发生的概率
* Pm:变异发生的概率
* M:种群规模
* G:终止进化的代数
* Tf:进化产生的任何一个个体的适应度函数超过Tf,则可以终止进化过程
*/
初始化Pm,Pc,M,G,Tf等参数。随机产生第一代种群Pop
do
{
计算种群Pop中每一个体的适应度F(i)。
初始化空种群newPop
do
{
根据适应度以比例选择算法从种群Pop中选出2个个体
if ( random ( 0 , 1 ) < Pc )
{
对2个个体按交叉概率Pc执行交叉操作
}
if ( random ( 0 , 1 ) < Pm )
{
对2个个体按变异概率Pm执行变异操作
}
将2个新个体加入种群newPop中
} until ( M个子代被创建 )
用newPop取代Pop
}until ( 任何染色体得分超过Tf, 或繁殖代数超过G )
四.基本遗传算法优化
下面的方法可优化遗传算法的性能。
精英主义(Elitist Strategy)选择:是基本遗传算法的一种优化。为了防止进化过程中产生的最优解被交叉和变异所破坏,可以将每一代中的最优解原封不动的复制到下一代中。
插入操作:可在3个基本操作的基础上增加一个插入操作。插入操作将染色体中的某个随机的片段移位到另一个随机的位置。
五. 使用AForge.Genetic解决TSP问题
AForge.NET是一个C#实现的面向人工智能、计算机视觉等领域的开源架构。AForge.NET中包含有一个遗传算法的类库。
AForge.NET主页:http://www.aforgenet.com/
AForge.NET代码下载:http://code.google.com/p/aforge/
介绍一下AForge的遗传算法用法吧。AForge.Genetic的类结构如下:
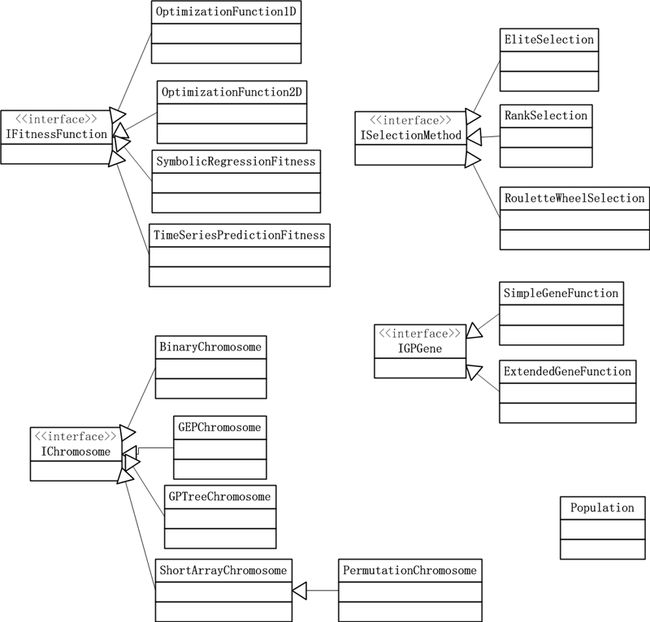
图1. AForge.Genetic的类图
下面用AForge.Genetic写个解决TSP问题的最简单实例。测试数据集采用网上流传的中国31个省会城市的坐标:
36391315
41772244
37121399
34881535
33261556
32381229
41961004
4312790
4386570
30071970
25621756
27881491
23811676
1332695
37151678
39182179
40612370
37802212
36762578
40292838
42632931
34291908
35072367
33942643
34393201
29353240
31403550
25452357
27782826
23702975
操作过程:
(1) 下载AForge.NET类库,网址:http://code.google.com/p/aforge/downloads/list
(2) 创建C#空项目GenticTSP。然后在AForge目录下找到AForge.dll和AForge.Genetic.dll,将其拷贝到TestTSP项目的bin/Debug目录下。再通过“Add Reference...”将这两个DLL添加到工程。
(3) 将31个城市坐标数据保存为bin/Debug/Data.txt 。
(4) 添加TSPFitnessFunction.cs,加入如下代码:
TSPFitnessFunction类
using AForge.Genetic;
namespace GenticTSP
{
///
/// Fitness function for TSP task (Travaling Salasman Problem)
///
publicclass TSPFitnessFunction : IFitnessFunction
{
// map
privateint[,] map =null;
// Constructor
public TSPFitnessFunction(int[,] map)
{
this.map = map;
}
///
/// Evaluate chromosome - calculates its fitness value
///
publicdouble Evaluate(IChromosome chromosome)
{
return1/ (PathLength(chromosome) +1);
}
///
/// Translate genotype to phenotype
///
publicobject Translate(IChromosome chromosome)
{
return chromosome.ToString();
}
///
/// Calculate path length represented by the specified chromosome
///
publicdouble PathLength(IChromosome chromosome)
{
// salesman path
ushort[] path = ((PermutationChromosome)chromosome).Value;
// check path size
if (path.Length != map.GetLength(0))
{
thrownew ArgumentException("Invalid path specified - not all cities are visited");
}
// path length
int prev = path[0];
int curr = path[path.Length -1];
// calculate distance between the last and the first city
double dx = map[curr, 0] - map[prev, 0];
double dy = map[curr, 1] - map[prev, 1];
double pathLength = Math.Sqrt(dx * dx + dy * dy);
// calculate the path length from the first city to the last
for (int i =1, n = path.Length; i < n; i++)
{
// get current city
curr = path[i];
// calculate distance
dx = map[curr, 0] - map[prev, 0];
dy = map[curr, 1] - map[prev, 1];
pathLength += Math.Sqrt(dx * dx + dy * dy);
// put current city as previous
prev = curr;
}
return pathLength;
}
}
}
(5) 添加GenticTSP.cs,加入如下代码:
GenticTSP类
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using AForge;
using AForge.Genetic;
namespace GenticTSP
{
class GenticTSP
{
staticvoid Main()
{
StreamReader reader =new StreamReader("Data.txt");
int citiesCount =31; //城市数
int[,] map =newint[citiesCount, 2];
for (int i =0; i < citiesCount; i++)
{
string value = reader.ReadLine();
string[] temp = value.Split('');
map[i, 0] =int.Parse(temp[0]); //读取城市坐标
map[i, 1] =int.Parse(temp[1]);
}
// create fitness function
TSPFitnessFunction fitnessFunction =new TSPFitnessFunction(map);
int populationSize = 1000; //种群最大规模
/*
* 0:EliteSelection算法
* 1:RankSelection算法
* 其他:RouletteWheelSelection 算法
* */
int selectionMethod =0;
// create population
Population population =new Population(populationSize,
new PermutationChromosome(citiesCount),
fitnessFunction,
(selectionMethod ==0) ? (ISelectionMethod)new EliteSelection() :
(selectionMethod ==1) ? (ISelectionMethod)new RankSelection() :
(ISelectionMethod)new RouletteWheelSelection()
);
// iterations
int iter =1;
int iterations =5000; //迭代最大周期
// loop
while (iter < iterations)
{
// run one epoch of genetic algorithm
population.RunEpoch();
// increase current iteration
iter++;
}
System.Console.WriteLine("遍历路径是: {0}", ((PermutationChromosome)population.BestChromosome).ToString());
System.Console.WriteLine("总路程是:{0}", fitnessFunction.PathLength(population.BestChromosome));
System.Console.Read();
}
}
}
网上据称这组TSP数据的最好的结果是 15404 ,上面的程序我刚才试了几次最好一次算出了15402.341,但是最差的时候也跑出了大于16000的结果。
我这还有一个版本,设置种群规模为1000,迭代5000次可以算出15408.508这个结果。源代码在文章最后可以下载。
总结一下使用AForge.Genetic解决问题的一般步骤:
(1) 定义适应函数类,需要实现IFitnessFunction接口
(2) 选定种群规模、使用的选择算法、染色体种类等参数,创建种群population
(3)设定迭代的最大次数,使用RunEpoch开始计算
本文源代码下载
from: http://www.cnblogs.com/heaad/archive/2010/12/20/1911614.html
http://www.cnblogs.com/heaad/archive/2010/12/23/1914725.html