python爬取豆瓣Top250电影导入csv和MySQL中
1. 准备工作
最近在写毕业课设,需要一些电影的信息,所以网上找了一些代码自己做了修改。在爬取之前先在你的数据库建立movie表,以下是我自己建的表,你可以根据自己需求设计字段。
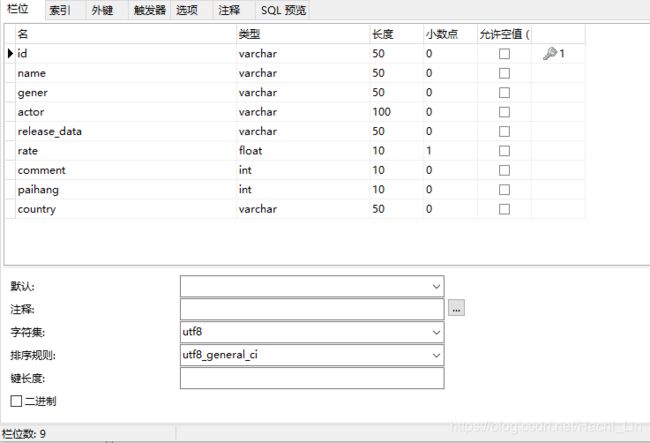
细心的网友会发现字段paihang为啥不用rank显得高大尚一点,我也想用,但是在插入数据的时候会插入不成功,然后把字段改成paihang就竟然插入成功了。这个奇葩的错误我刚开始以为表的字段太多了,发现只要改名就行了。如果有知道原因的网友,希望可以在我的评论区留言。
2. 测试数据库是否能插入数据
有了数据库表格后,你需要测试一下你的表是否能插入数据。
def test_SQinsert():
db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='root', db='paper', charset='utf8')
# 创建数据库游标
cursor = db.cursor()
sql = "INSERT INTO movie(name,id,actor,gener,country,release_data,rate,paihang,comment) \
VALUES ('%s','%s','%s','%s','%s','%s','%f','%d','%d')" % \
('Mac', 'Mo22222', 'Mohan', 'Mohan', 'Mohan', 'dd', 1.2, 99,88)
try:
# 执行sql语句
cursor.execute(sql)
db.commit()
print("insert ok")
except pymysql.Error as e:
# 发生错误时回滚
db.rollback()
print('no OK')
# 打印错误
print(e)
3. python爬虫
# coding:utf-8
import csv
import requests
from lxml import html
from lxml import etree
from urllib.request import urlopen,Request
import pymysql
def list_douban_top250():
db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='lin936144524', db='paper', charset='utf8')
# 创建数据库游标
cursor = db.cursor()
#创建CSV文件,并写入表头信息
fp = open('movie.csv','a',newline='',encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('movie_id','电影名','电影类型','导演演员信息','发行日期','制片国家','评分','评论数','排名'))
print('正在获取豆瓣TOP250影片信息并存入数据库...')
index = 1
page_count = 10
all_link = []
for i in range(page_count):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i * 25)
# 模拟浏览器访问
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36",}
ret = Request(url, headers=headers)
res = urlopen(ret)
# 内容节点
doc = etree.HTML(res.read())
# 获取电影链接作为movie表格id
url_list=doc.xpath('//div[@class="pic"]/a/@href')
for url in url_list:
if 'https://movie.douban.com/subject/' in str(url):
all_link.append(url)
for y in doc.xpath('//div[@class="info"]'):
# 影片名称
name = y.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
# 影片详情
move_content = y.xpath('div[@class="bd"]/p[1]/text()')
# 导演演员信息
actor = move_content[0].replace(" ", "").replace("\n", "").replace("\xa0","")
# 上映日期
date = move_content[1].replace(" ", "").replace("\n", "").replace("\xa0","").split("/")[0]
# 制片国家
country = move_content[1].replace(" ", "").replace("\n", "").replace("\xa0","").split("/")[1]
# 影片类型
gener = move_content[1].replace(" ", "").replace("\n", "").replace("\xa0","").split("/")[2]
# 评分
rate = y.xpath('div[@class="bd"]/div[@class="star"]/span[2]/text()')[0]
# 评论人数
com_count = y.xpath('div[@class="bd"]/div[@class="star"]/span[4]/text()')[0].replace('人评价', '')
# 执行log
print('TOP%s--%s--评分%s--人数%s' % (str(index), name, rate, com_count))
# 写入csv
writer.writerow((all_link[index-1],name,gener,actor,date,country,rate,com_count,index))
# 写入MySQL
sql = "INSERT INTO movie(id,name,gener,actor,release_data,country,rate,comment,paihang) \
VALUES ('%s','%s','%s','%s','%s','%s','%f','%d','%d')"% \
(all_link[index-1],str(name),str(gener),str(actor),str(date),str(country),round(float(rate),1),int(com_count),index)
try:
cursor.execute(sql)
db.commit()
print("结果已提交")
except pymysql.Error as e:
db.rollback()
print("数据已回滚",e)
index += 1
print('任务执行完成!')
cursor.close()
db.close()
fp.close()
list_douban_top250()
4. 结果显示
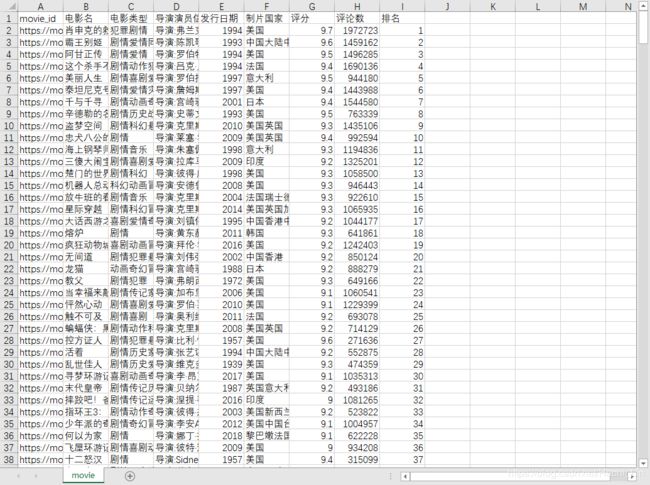
- csv
打开会发现是乱码,用文本文档打开,改一下编码格式为ANSI就可以了。
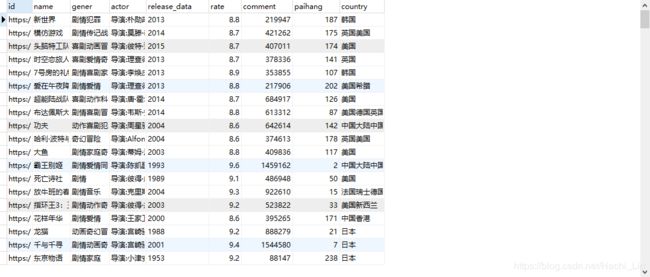
- movie表
5. 参考文献
- https://www.jianshu.com/p/e49bdec40cac
- https://www.bbsmax.com/A/l1dybyM9ze/