Mining Data Streams(1)——数据流挖掘学习笔记
概述
数据流不同于数据库,有几个特点:数据流的实时性,导致其需要被立即处理,否则会永远消失。同时一般数据量太大太快,动态存储无法存储全部数据。所以在处理数据流的时候,一般会采用两种算法:1、利用采样和过滤的思想对流实时处理,去除不必要的元素。2、存储固定长度的窗口,对进入窗口的元素进行整合、计算,然后再利用估计和概率提供近似的答案。
数据流模型

可以看到这个模型中有数据数据流、流处理器、动态存储和档案存储、标准查询和临时查询、输出数据流。流与数据库的区别在于,一个到达数据速率可控,一个到达数据速率不可控。
流查询分为标准查询和临时查询。标准查询是内置在流处理器中,并且永久的被执行,隔一定时间输出结果。我认为标准查询是可以通过计算每一个进入的新元素得出答案,例如筛选出最大值、求最新24个元素的平均值等。临时查询是针对当前数据流的状态,准确的回答需要计算整个流的情况。例如统计过去一个月某网站不重复的用户数量。
在流中采样数据
首先讨论对于流的一个子集进行查询,其结果具有的代表性的概率,也就是通过子集得到整个流的情况的正确概率。
例如,搜索引擎中,我们想要知道,在过去一个月,常规用户的重复询问比例是多少。并且假设我们能够存储1/10的流元素。如何选择1/10的元素,我们可以用随机数,对每一个元组赋予0-9的随机数,并选一个数字的元组进行存储。但是这种方式在回答一个用户的重复问题的平均次数这 个问题,答案是错误的。具体概率计算如下:
个问题,答案是错误的。具体概率计算如下:
假设一个用户在一个月中有s条查询出现一次,d条查询出现两次,并且没有多于两次的查询。所以会有![]() 条出现,
条出现,![]() 条出现两次,
条出现两次,![]() 条出现一次。重复查询出现的正确概率应该是
条出现一次。重复查询出现的正确概率应该是![]() ,而我们推测出的答案为
,而我们推测出的答案为 ,即
,即![]() 。所以通过计算可以知道,对问题进行抽样不能很好的回答我们这个随机问题,因此我们选择对用户进行抽样。
。所以通过计算可以知道,对问题进行抽样不能很好的回答我们这个随机问题,因此我们选择对用户进行抽样。
首先我们对用户进行存储,每当新一个查询流进来,我们检查该用户是否在样本里,如果在样本中则存储。如果这个用户之前没有出现过,我们可以对其0-9赋值,决定其是否在样本中。这个方法很有限,但是需要我们能够在主存中存储所有用户列表和他们是否在样本中的标志,因为数据流很快,我们没有时间对硬盘进行读写。但是主存空间很宝贵,存储大量的用户也不符合实际。
所以我们通过哈希函数来代替存储用户名列表。把哈希函数当成随机数发生器,对每一个用户名进行计算,计算值对应0-9的10个桶,相同的用户名需要得到同样的结果,利用这个放弃存储,实现快速抽样和存储。
关于采样的其他问题
1、利用哈希函数进行采样需要针对关键字,不同的关键字,不同的采样频率需要设置不同的哈希函数。
2、随着新数据流的进入和新用户被判定为样本,我们保留的查询数据会越来越多。如果我们对于存储的元组有预算,那么随着时间变化,键值的比例需要一步步降低。为了确保在任何时候样本均由键值子集中的所有元组组成,我们维持一个阈值,该阈值最初可以是最大的存储桶数![]() 。在任何时候,样本都由键
。在任何时候,样本都由键 满足
满足![]() 的那些元组组成。当且仅当满足条件的流中的新元组才添加到样本中。如果样本的存储元组数超过了分配的空间,我们将降低到
的那些元组组成。当且仅当满足条件的流中的新元组才添加到样本中。如果样本的存储元组数超过了分配的空间,我们将降低到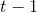 并从样本中删除所有键哈希值为的元组。为了提高效率,每当需要从样本中抛出一些键值时,我们可以将降低1以上,并删除具有多个最高哈希值的元组。通过在散列值上维护索引可以获得更高的效率,因此我们可以找到其键快速散列到特定值的所有那些元组。
并从样本中删除所有键哈希值为的元组。为了提高效率,每当需要从样本中抛出一些键值时,我们可以将降低1以上,并删除具有多个最高哈希值的元组。通过在散列值上维护索引可以获得更高的效率,因此我们可以找到其键快速散列到特定值的所有那些元组。
流过滤
我们希望从流中筛选出符合一定条件的元组,但是困难在集合太大难以存储,因此这里介绍“Bloom filtering”算法。通过一个例子来结束,我们假设有一个包含一亿邮箱地址的集合S,这些邮箱都不是垃圾邮箱,都是可信任的邮箱,流中包含元素为:一个邮箱地址和邮件本身。我们需要将新收的邮件和S集合进行对比,将垃圾邮件剔除,所以需要对流进行过滤。在这个例子中,通常一个邮箱地址有20字节,因此在主存中存储S集合所有数据是不可能的。
Bloom filtering
假设我们有1GB的动态存储空间,将其看成一个比特(位)数组,在这种情况下,我们就用8亿比特的空间。设计一个哈希函数h,将S的每一个地址计算成一比特,并在主存中将这一位设置为1,其余所有位不变。因为我们有一亿的邮箱,因此大约![]() 的位会是1。实际上被设置为1的位会略少于
的位会是1。实际上被设置为1的位会略少于![]() ,因为存在两个地址哈希值相同。当新元素进入的时候,我们对其邮箱地址哈希计算,如果结果位是0,那么可以肯定这个地址不在集合S中,将其丢弃。不幸的是,会有一些垃圾邮件通过。大约有
,因为存在两个地址哈希值相同。当新元素进入的时候,我们对其邮箱地址哈希计算,如果结果位是0,那么可以肯定这个地址不在集合S中,将其丢弃。不幸的是,会有一些垃圾邮件通过。大约有![]() 不在S中的邮件会通过,但考虑到收到邮件的主体(约80%)是垃圾邮件,因此能够过滤
不在S中的邮件会通过,但考虑到收到邮件的主体(约80%)是垃圾邮件,因此能够过滤![]() 的垃圾邮件也是很有成效的。此外,在应用的时候可以利用级联的方式一层一层过滤,每一次都会过滤掉
的垃圾邮件也是很有成效的。此外,在应用的时候可以利用级联的方式一层一层过滤,每一次都会过滤掉![]() 。
。
Bloom filter需要包含三个成分:
- 一个n位数组,初始全为0。
- 哈希函数集合
 ,
,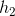 ,...
,...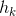 ,每一个哈希函数映射键值到
,每一个哈希函数映射键值到 个桶中,因为数组有n位。
个桶中,因为数组有n位。 - 一个集合S,其中包含m个键值。
当新键值进入流,对所有哈希函数进行计算,![]() ,
,![]() ,...,
,...,![]() ,所有的结果位都为1的时候让这个元素通过,只要有一位是0就丢弃。
,所有的结果位都为1的时候让这个元素通过,只要有一位是0就丢弃。
Bloom filtering的概率分析
把每一个比特当成目标,S中的元素当成飞镖,那么一个比特位被置1的概率等同于一个目标被一个或多个飞镖击中的概率。S集合中有一亿元素,即![]() ,有8亿的比特位,即
,有8亿的比特位,即![]() 。因此一个确定的目标没有被击中的概率为
。因此一个确定的目标没有被击中的概率为![]() 即
即![]() ,被击中的概率就是
,被击中的概率就是![]() ,计算下来就是0.1175。我们可以将这个结论推广,目标的数量是
,计算下来就是0.1175。我们可以将这个结论推广,目标的数量是![]() ,飞镖的数量是
,飞镖的数量是![]() ,那么一个比特位仍然是0的概率是
,那么一个比特位仍然是0的概率是![]() 。
。
在流中统计不同的元素个数
我们提出第三个问题,想知道流中有多少个不同的元素,从流的第一个或中间某个地方开始。具体的例子:一个网站有多少不重复的用户?输入是网站的登陆集合流。
在解决这个问题,我们需要规定一个策略,即仅估计不同元素的数量,但使用的内存少于不同元素的数量。通过将集合的元素散列为足够长的位串,可以估计不同元素的数量。位串的长度必须足够长,以使散列函数的结果可能比集合的元素更多。我们将选择许多不同的哈希函数,并使用这些哈希函数对流的每个元素进行哈希处理。哈希函数的重要属性是,当应用于同一元素时,它始终会产生相同的结果。
Flajolet-Martin Algorithm
算法的思想是:如果流中有很多不同元素,那么就会有很多不同的哈希值,就有可能出现其中一个值是不寻常的。而这个不寻常的值我们可以发现是以许多0结尾的。
当我们对流元素 应用哈希函数
应用哈希函数 ,结果
,结果![]() 会以一定数量的0结尾。我们将这个数量称为和的尾巴长度,并设置
会以一定数量的0结尾。我们将这个数量称为和的尾巴长度,并设置 为流中任一元素的最大尾巴长度。然后我们可以估计流中不同元素的数量为
为流中任一元素的最大尾巴长度。然后我们可以估计流中不同元素的数量为![]() 个。一个给定的流元素的哈希函数值
个。一个给定的流元素的哈希函数值![]() 以至少
以至少 个0结尾的概率是
个0结尾的概率是![]() ,假设流中有
,假设流中有 个不同的元素,那么这些元素中没有一个的尾巴长度至少是的概率是
个不同的元素,那么这些元素中没有一个的尾巴长度至少是的概率是![]() ,我们可以将这个概率重写为
,我们可以将这个概率重写为![]() 。这个表达式可以变成
。这个表达式可以变成![]() 的形式,这个式子大约是
的形式,这个式子大约是 。
。
因此,找不到一个有r个0结尾的流元素的概率是![]() 。我们可以归纳出下面两点:1、如果的值比
。我们可以归纳出下面两点:1、如果的值比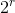 大得多,那么我们找到尾巴长度至少为r的概率接近1。2、如果如果的值比小得多,那么我们找到尾巴长度至少为r的概率接近0。
大得多,那么我们找到尾巴长度至少为r的概率接近1。2、如果如果的值比小得多,那么我们找到尾巴长度至少为r的概率接近0。