Java - 从零学起(二)
目录
1 - Object类、常用API
1.1 - Object类
1.1.1 - 概述
1.1.2 - toString方法
1.1.3 - equals方法
1.1.4 - Objects类
1.2 - 日期时间类
1.2.1 - Date类
1.2.2 - DateFormat类
1.2.3 - Calendar类
1.3 - System类
1.3.1 - currentTimeMillis方法
1.3.2 - arraycopy方法
1.4 - StringBulider类
1.4.1 - 字符串拼接问题
1.4.2 - StringBulider概述
1.4.3 - 构造方法
1.4.4 - 常用方法
1.5 - 包装类
1.5.1 - 概述
1.5.2 - 装箱与拆箱
1.5.3 - 自动装箱与自动拆箱
1.5.4 - 基本类型与字符串之间的转换
2 - Collection、泛型
2.1 - Collection
2.1.1 - 集合概述
2.1.2 - 集合框架
2.1.3 -Collection常用功能
2.2 - Iterator迭代器
2.2.1 - Iterator接口
2.2.2 - 迭代器的实现原理
2.2.3 - 增强for
2.3 - 泛型
2.3.1 - 泛型概述
2.3.2 - 使用泛型的好处
2.3.3 - 泛型的定义与使用
2.3.4 - 泛型通配符
2.4 - 斗地主案例
2.4.1 - 案例介绍
2.4.2 - 案例分析
2.4.3 - 代码实现
3 - List、Set、数据结构、Collections
3.1 - 数据结构
3.1.1 - 数据结构有什么用
3.1.2 - 栈
3.1.3 - 队列
3.1.4 - 数组
3.1.5 - 链表
3.1.6 - 红黑树
3.2 - List集合
3.2.1 - List接口介绍
3.2.2 - List接口中的常用方法
3.3 - List的子类
3.3.1 - ArrayList集合
3.3.2 - LinkedList集合
3.4 - Set接口
3.4.1 - HashSet结合介绍
3.4.2 - HashSet结合存储数据的结构(哈希表)
3.4.3 - HashSet存储自定义类型元素
3.4.5 - LinkedHashSet
3.4.6 - 可变参数
3.5 - Collections
3.5.1 - 常用功能
3.5.2 - Comparator比较器
3.5.3 - 简述Comparable和Comparator两个接口的区别
3.5.4 - 练习
3.5.5 - 扩展
4 - Map
4.1 - Map集合
4.1.1 - 概述
4.1.2 - Map常用子类
4.1.3 - Map接口中的常用方法
4.1.4 - Map集合遍历键找值方式
4.1.5 - Entry键值对对象
4.1.6 - Map集合遍历键值对方式
4.1.7 - HashMap存储自定义类型键值
4.1.8 - LinkedHashMap
4.1.9 - Map练习
4.2 - 补充知识点
4.2.1 - JDK9对集合添加的优化
4.3 - 模拟斗地主洗牌发牌
4.3.1 - 案例介绍
4.3.2 - 案例需求分析
4.3.3 - 实现代码步骤
5 - 异常、线程
5.1 - 异常
5.1.1 - 异常概念
5.1.2 - 异常体系
5.1.3 - 异常分类
5.2 - 异常的处理
5.2.1 - 抛出异常throw
5.2.2 - Objects非空判断
5.2.3 - 声明异常throws
5.2.4 - 捕获异常try...catch
5.2.5 - finally代码块
5.2.6 - 异常注意体系
5.3 - 自定义异常
5.3.1 - 概述
5.3.2 - 自定义异常的练习
5.4 - 多线程
5.4.1 - 并发与并行
5.4.2 - 线程与进程
5.4.3 - 创建线程类
6 - 线程、同步
6.1 - 线程
6.1.1 - 多线程原理
6.1.2 - Thread类
6.1.3 - 创建线程方式二
6.1.4 - Thread和Runnable的区别
6.1.5 - 匿名内部类方式实现线程的创建
6.2 - 线程安全
6.2.1 - 线程安全
6.2.2 - 线程同步
6.2.3 - 同步代码块
6.2.4 - 同步方法
6.2.5 - Lock锁
6.3 - 线程状态
6.3.1 - 线程状态概述
6.3.2 - Timed Waiting(计时等待)
6.3.3 - BLOCKED(锁阻塞)
6.3.4 - Waiting(无限等待)
6.3.5 - 补充知识点
7 - 线程池、Lambda表达式
7.1 - 等待唤醒机制
7.1.1 - 线程间通信
7.1.2 - 等待唤醒机制
7.1.3 - 生产者与消费者问题
7.2 - 线程池
7.2.1 - 线程池思想概述
7.2.2 - 线程池的概念。
7.2.3 - 线程池的使用
7.3 - Lambda表达式
7.3.1 - 函数式编程思想概述
7.3.2 - 冗余的Runnable代码
7.3.3 - 编程思想转换
7.3.4 - 体验Lambda更优化写法
7.3.5 - 回顾匿名内部类
7.3.6 - Lambda标准格式
7.3.7 - 练习
7.3.8 - Lambda的参数和返回值
7.3.9 - 练习
7.3.10 - Lambda省略格式
7.3.11 - Lambda的使用前提
8 - File类、递归
8.1 - File类
8.1.1 - 概述
8.1.2 - 构造方法
8.1.3 - 常用方法
8.1.4 - 目录的遍历
8.2 - 递归
8.2.1 - 概述
8.2.2 - 递归累加求和。
8.2.3 - 递归求阶乘
8.2.4 - 递归打印多级目录
8.3 - 综合案例
8.3.1 - 文件搜索
8.3.2 - 文件过滤器优化
8.3.3 - Lambda优化
9 - 字节流、字符流
9.1 - IO概述
9.1.1 - 什么是IO
9.1.2 - IO的分类
9.1.3 - 顶级父类们
9.2 - 字节流
9.2.1 - 一切皆为字节
9.2.2 - 字节输出流【OutputStream】
9.2.3 - FileOutputStream类
9.2.4 - 字节输入流【InputStream】
9.2.5 - FileInputStream类
9.2.6 - 字节流练习:图片复制
9.3 - 字符流
9.3.1 - 字符输入流【Reader】
9.3.2 - FileReader类
9.3.3 - 字符输出流【Writer】
9.3.4 - FileWriter类
9.4 - IO异常的处理
9.4.1 - JDK7 前处理
9.4.2 - JDK7 处理
9.4.3 - JDK9 改进
9.5 - 属性集
9.5.1 - 概述
9.5.2 - Properties类
10 - 缓冲流、转换流、序列化流
10.1 - 缓冲流
10.1.1 - 概述
10.1.2 - 字节缓冲流
10.1.3 - 字符缓冲流
10.1.4 - 练习:文本排序
10.2 - 转换流
10.2.1 - 字符编码和字符集
10.2.2 - 编码引出的问题
10.2.3 - InputStreamReader类
10.2.4 - OutputStreamWriter类
10.2.5 - 练习:转换文件编码
10.3 - 序列化
10.3.1 - 概述
10.3.2 - ObjectOutputStream类
10.3.3 - ObjectInputStream类
10.3.4 - 练习:序列化集合
10.4 - 打印流
10.4.1 - 概述
10.4.2 - PrintStream类
11 - 网络编程
11.1 - 网络编程入门
11.1.1 - 软件结构
11.1.2 - 网络通信协议
11.1.3 - 协议分类
11.1.4 - 网络编程三要素
11.2 - TCP通信程序
11.2.1 - 概述
11.2.2 - Socket类
11.2.3 - ServerSocket类
11.2.4 - 简单的TCP网络程序
11.3 - 综合案例
11.3.1 - 文件上传案例
12 - 函数式接口
12.1 - 函数式接口
12.1.1 - 概念
12.1.2 - 格式
12.1.3 - @FunctionalInterface注解
12.1.4 - 自定义函数式接口
12.2 - 函数式编程
12.2.1 - Lambda的延迟执行
12.2.2 - 使用Lambda作为参数和返回值
12.3 - 常用的函数式接口
12.3.1 - Supplier接口
12.3.2 - 练习:求数组元素最大值
12.3.3 - Consumer接口
12.3.4 - 练习:格式化打印信息
12.3.5 - Predicate接口
12.3.6 - 练习:集合信息筛选
12.3.7 - Function接口
12.3.8 - 练习:自定义函数模型拼接
13 - Stream流、方法引用
13.1 - Stream流
13.1.1 - 传统集合的多步遍历代码
13.1.2 - 循环遍历的弊端
13.1.3 - Stream的更优写法
13.1.4 - 流式思想概述
13.1.5 - 根据Collection获取流
13.1.6 - 根据Map获取流
13.1.7 - 根据数组获取流
13.1.8 - 逐一处理:forEach
13.1.9 - 过滤:filter
13.1.10 - 映射:map
13.1.11 - 统计个数:count
13.1.12 - 取用前几个:limit
13.1.13 - 跳过前几个:skip
13.1.14 - 组合:concat
13.1.15 - 练习:集合元素处理(传统方式)
13.1.16 - 练习:集合元素处理(Stream方式)
13.2 - 方法引用
13.2.1 - 冗余的Lambda场景
13.2.2 - 问题分析
13.2.3 - 用方法改进代码
13.2.4 - 方法引用符
13.2.5 - 通过对象名引用成员方法
13.2.6 - 通过类名引用静态方法
13.2.7 - 通过super引用成员方法
13.2.8 - 通过this引用成员方法
13.2.9 - 类的构造器引用
13.2.10 - 数组的构造器引用
1 - Object类、常用API
1.1 - Object类
1.1.1 - 概述
java.lang.Object 类是Java语言中的根类,即所有类的父类。它中描述的所有方法子类都可以使用。在对象实例
化的时候,最终找的父类就是Object。
如果一个类没有特别指定父类, 那么默认则继承自Object类。例如:
public class MyClass /*extends Object*/ {
// ...
}Object类当中包含的方法有11个。主要学习其中的2个:
-
public String toString() :返回该对象的字符串表示。
-
public boolean equals(Object obj) :指示其他某个对象是否与此对象“相等”。
1.1.2 - toString方法
方法摘要
- public String toString() :返回该对象的字符串表示。
toString方法返回该对象的字符串表示,其实该字符串内容就是对象的类型+@+内存地址值。
由于toString方法返回的结果是内存地址,而在开发中,经常需要按照对象的属性得到相应的字符串表现形式,因
此也需要重写它
覆盖重写
如果不希望使用toString方法的默认行为,则可以对它进行覆盖重写。例如自定义的Person类:
public class Person {
private String name;
private int age;
@Override
public String toString() {
return "Person{" + "name='" + name + '\'' + ", age=" + age + '}';
}
// 省略构造器与Getter Setter
}在IntelliJ IDEA中,可以点击 Code 菜单中的 Generate... ,也可以使用快捷键 alt+insert ,点击 toString() 选
项。选择需要包含的成员变量并确定。
在我们直接使用输出语句输出对象名的时候,其实通过该对象调用了其toString()方法。
1.1.3 - equals方法
方法摘要
- public boolean equals(Object obj) :指示其他某个对象是否与此对象“相等”。
调用成员方法equals并指定参数为另一个对象,则可以判断这两个对象是否是相同的。这里的“相同”有默认和自定
义两种方式。
默认地址比较
如果没有覆盖重写equals方法,那么Object类中默认进行 == 运算符的对象地址比较,只要不是同一个对象,结果
必然为false。
对象内容比较
如果希望进行对象的内容比较,即所有或指定的部分成员变量相同就判定两个对象相同,则可以覆盖重写equals方
法。例如:
import java.util.Objects;
public class Person {
private String name;
private int age;
@Override
public boolean equals(Object o) {
// 如果对象地址一样,则认为相同
if (this == o)
return true;
// 如果参数为空,或者类型信息不一样,则认为不同
if (o == null || getClass() != o.getClass())
return false;
// 转换为当前类型
Person person = (Person) o;
// 要求基本类型相等,并且将引用类型交给java.util.Objects类的equals静态方法取用结果
return age == person.age && Objects.equals(name, person.name);
}
}这段代码充分考虑了对象为空、类型一致等问题,但方法内容并不唯一。大多数IDE都可以自动生成equals方法的
代码内容。在IntelliJ IDEA中,可以使用 Code 菜单中的 Generate… 选项,也可以使用快捷键 alt+insert ,并选
择 equals() and hashCode() 进行自动代码生成。
1.1.4 - Objects类
在刚才IDEA自动重写equals代码中,使用到了 java.util.Objects类,这个类是什么呢?
在JDK7中,添加了一个Objects工具类,它提供了一些方法来操作对象。它由一些静态的实用方法组成,这些方法是null-save(空指针安全的)或者null-tolerant(容忍空指针的),用于计算对象的hashcode,返回对象的字符串表示形式,比较两个对象。
在比较两个对象的时候,Object的equals方法容易抛出空指针异常,而Objects类中的equals方法就优化了这个问题。方法如下:
- public static boolean equals(Object a, Ojbect b) : 判断两个对象是否相等。
public static boolean equals(Object a, Object b){
return (a == b) || (a != null && a.equals(b));
}1.2 - 日期时间类
1.2.1 - Date类
概述
java.util.Date类,表示特定的瞬间,精确到毫秒。
继续查阅Date类的描述,发现Date拥有多个构造函数,只是部分已经过时,但是其中没有过时的构造函数可以把毫秒转换成日期对象。
- public Date():分配Date对象并初始化此对象,以表示分配它的时间(精确到毫秒)。
- public Date(long date):分配Date对象并初始化此对象,一表示自从标准基时间(1970/1/1/00:00:00)以来指定的毫秒数。
简单来说,使用无参构造,可以自动设置当前系统时间的毫秒时刻;指定long类型的构造参数,可以自定义毫秒时刻。
import java.util.Date;
public class Demo01Date{
public static void main(String[] args){
// 创建日期对象,获取当前时间
System.out,println(new Date());
// 创建日期对象,把当前的毫秒值转换成日期对象
System.out,println(new Date(0L));
}
}在使用println()方法时,会自动调用Date类中的toString()方法,Date类对Object类中的toString方法进行了覆盖重写,所以结果为指定格式的字符串。
常用方法
Date类中的多数方法已经过时,常用的方法有:
- public long getTime():把日期对象转换成对应的时间毫秒值。
1.2.2 - DateFormat类
java.text.DateFormat 是日期/时间格式化子类的抽象类,我们通过这个类可以帮我们完成日期和文本之间的转换,也就是可以在Date对象与String对象之间进行来回转换。
- 格式化:按照指定的格式,从Date对象转换为String对象。
- 解析:按照指定的格式,从String对象转换为Date对象。
构造方法
由于DateFormat为抽象类,不能直接使用,所以需要常用的子类 java.text.SimpleDateFormat。这个类需要一个模式(格式)来指定格式化或者解析的标准。构造方法为:
- public SimpleDateFormat(String pattern):用给定的模式和默认语言环境的日期格式符号构造。
参数pattern是一个字符串,代表日期时间的自定义格式。
格式规则
常用的格式规则为:
| 表示字母(区分大小写) | 含义 |
|---|---|
| y | 年 |
| M | 月 |
| d | 日 |
| H | 时 |
| m | 分 |
| s | 秒 |
创建SimpleDateFormat对象的代码:
import java.text.DateFormat;
import java.text.SimpleDateFormat;
public class Demo2SimpleDateFormat{
public static void main(String[] args){
DateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
}
}常用方法
DateFromat类常用的方法有:
- public String format(Date date):将Date对象格式化为字符串。
- public Date parse(String source):将字符串解析为Date对象。
format方法
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
public class Demo3{
public static void main(String[] args){
Date date = new Date();
// 创建日期格式化对象,在获取格式化对象时可以指定风格
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
String str = df.format(date);
Sytstem.out.println(str);
}
}parse方法
import java.util.Date;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.text.ParseException;
public class Deme4{
public static void main(String[] args){
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
String str = "2018年12月11日";
Date date = df.parse(str);
System.out.println(date);
}
}练习
/*
* 使用日期相关API,计算出一个人已经出生了多少天
*/
public static void function() throws Expetion{
System.out.println("请输入出生日期 格式 YYYY‐MM‐dd");
// 获取出生日期,键盘输入
String birthdayString = new Scanner(System.in).next();
// 将字符串日期,转成Date对象
// 创建SimpleDateFormat对象,写日期模式
SimpleDateFormat sdf = new SimpleDateFormat("yyyy‐MM‐dd");
// 调用方法parse,字符串转成日期对象
Date birthdayDate = sdf.parse(birthdayString);
// 获取今天的日期对象
Date todayDate = new Date();
// 将两个日期转成毫秒值,Date类的方法getTime
long birthdaySecond = birthdayDate.getTime();
long todaySecond = todayDate.getTime();
long secone = todaySecond‐birthdaySecond;
if (secone < 0){
System.out.println("还没出生呢");
} else {
System.out.println(secone/1000/60/60/24);
}
}1.2.3 - Calendar类
概念
java.util.Calendar 是日历类,在Date后出现,替换掉了许多Date方法,该类将所有可能用到的时间信息封装为静态成员变量,方便获取。日历类就是方便获取各个时间属性的。
获取方式
Calendar为抽象类,由于语言敏感性,Calendar在创建对象时并非直接创建,而是通过静态方法创建,返回子类对象。如下:
Calendar静态方法:
- public static Calendar getInstance():使用默认时区和语言环境获得一个日历。
import java.util.Calendar;
public class Demo6{
public static void main(String[] args){
Calendar cal = Calendar.getInstance();
}
}常用方法
根据Calendar类的API文档,常用方法有:
- public int get(int field):返回给定日历字段的值。
- public void set(int field, int value):将给定的日历字段设置为给定值。
- public abstract void add(int field, int amount):根据日历规则,为给定的日历字段添加或减去指定的时间量。
- public Date getTime():返回一个表示此Calendar时间值(从历元到现在的毫秒偏移量)的Date对象。
Calendar类中提供很多成员常量,代表给定的日历字段:
| 字段值 | 含义 |
|---|---|
| YEAR | 年 |
| MONTH | 月(从零开始,可以+1使用) |
| DAY_OF_MONTH | 月中的天(几号) |
| HOUR | 时(12小时制) |
| HOUR_OF_DAY | 时(24小时制) |
| MINUTE | 分 |
| SECOND | 秒 |
| DAY_OF_WEEK | 周中的天(周几,周日为1,可以-1使用) |
get/set方法
get方法用来获取指定字段值,set方法用来设置指定字段的值,代码使用:
import java.util.Calendar;
public class CalendarDemo{
public static void main(String[] args){
// 创建Calendar对象
Calendar cal = Calendar.getInstance();
// 设置年
int year = cal.get(Calendar.YEAR);
// 设置月
int month = cal.get(Calendar.MONTH) + 1;
// 设置日
int dayOfMonth = cal.get(Calendar.DAY_OF_MONTH);
System.out.println(year + "年 " + month + "月 " + dayOfMonth + "日");
}
}import java.util.Calendar;
public class CalendarDemo2{
public static void main(String[] args){
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, 2020);
System.out.println(year + "年 " + month + "月 " + dayOfMonth + "日");
}
}add方法
add方法可以对指定日历字段的值进行加减操作,如果第二个参数为整数则加上偏移量,如果为负数则减去偏移量。
import java.util.Calendar;
public class Demo{
public static void main(String[] args){
Calendar cal = Calendar.getInstance();
System.out.println(year + "年 " + month + "月 " + dayOfMonth + "日");
// 使用add方法
cal.add(Calendar.DAY_OF_MONTH, 2); // 加两天
cal.add(Calendar.YEAR, -3); // 减三年
System.out.println(year + "年 " + month + "月 " + dayOfMonth + "日");
}
}getTime方法
Calendar中的getTime方法并不是获取毫秒时,而是拿到对应的Date对象。
import java.util.Calendar;
import java.util.Date;
public class Demo{
public static void main(String[] args){
Calendar cal = Calendar.getInstance();
Date date = cal.getTime();
System.out.println(date);
}
}西方星期的开始为周日,中国为周一。
在Calendar类中,月份的表示时以0-11代表1-12月
日期是有大小关系的,时间靠后,时间越大
1.3 - System类
java.lang.System 类中提供了大量的静态方法,可以获取与系统有关的信息或系统级操作,在System类的API文档中,常用的方法有:
- public static long currentTimeMillis():返回以毫秒为单位的当前时间
- public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length):将数组中指定的数据拷贝到另一个组中。
1.3.1 - currentTimeMillis方法
实际上,currentTimeMillis方法就是获取当前系统时间与1970年01月01日00:00点之间的毫秒差值
import java.util.Date;
public class Demo{
public static void main(String[] args){
System.out.println(System.currentTimeMillis());
}
}
// for循环打印数字1-9999所需要的时间
public class Demo {
public static void main(String[] args){
long start = System.currentTimeMillis();
for(int i = 0; i <= 9999; i++){
System.out.println(i);
}
long end = System.currentTimeMillis();
System.out.println("共耗时毫秒:" + (end - start));
}
}1.3.2 - arraycopy方法
- public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length):将数组中指定的数据拷贝到另一个数组中。
数组的拷贝动作是系统级的,性能很高。System.arraycopy方法具有五个参数,含义分别为:
| 参数序号 | 参数名称 | 参数类型 | 参数含义 |
|---|---|---|---|
| 1 | src | Object | 源数组 |
| 2 | srcPos | int | 源数组索引起始位置 |
| 3 | dest | Object | 目标数组 |
| 4 | destPos | int | 目标数组索引起始位置 |
| 5 | length | int | 复制元素个数 |
练习
将src数组中前三个元素,复制到dest数组的前三个位置上。复制元素前,src数组元素[1,2,3,4,5],dest数组元素[6,7,8,9,10]。复制元素后,src数组元素[1,2,3,4,5],dest数组元素[1,2,3,9,10]
public class Demo {
public static void main(String[] args){
int[] src = new int[]{1,2,3,4,5};
int[] dest = new int[]{6,7,8,9,10};
System.arraycopy(src, 0, dest, 0, 3);
for(int i = 0; i <= dest.length; i++){
System.out.println(dest[i]);
}
}
}1.4 - StringBulider类
1.4.1 - 字符串拼接问题
由于String类的对象内容不可改变,所以每当进行字符串拼接时,总是会在内存中创建一个新的对象。例如:
public class StringDemo{
public static void main(String[] args){
String s = "Hello";
s += "World";
System.out.println(s);
}
}在API中对String类有这样的描述:字符串是常量,它们的值在创建后不能被更改。
根据这句话分析我们的代码,其实总共产生了三个字符串,即“Hello”、“World”、“HelloWorld”。引用变量s首先指向Hello对象,最终指向并拼接出来的新字符串对象,即“HelloWorld”。
由此可知,如果对字符串进行拼接操作,每次拼接,都会构建一个新的String对象,既耗时,又浪费空间,为了解决这一问题,可以使用 java.lang.StringBulider类。
1.4.2 - StringBulider概述
查阅java.lang.StringBulider的API,StringBulider又称为可变字符序列,它是一个类似于String的字符串缓冲区,通过某些方法调用可以改变该序列的长度和内容。
原来StringBulider是个字符串的缓冲区,即它是一个容器,容器中可以装很多字符串,并且能够对其中的字符串进行各种操作。
它的内部拥有一个数组用来存放字符串内容,进行字符串拼接时,直接在数组中加入新内容,StringBulider会自动维护数组的扩容。默认16字符空间,超过自动扩充。
1.4.3 - 构造方法
根据StringBulider的API文档,常用构造方法有两个:
-
public StringBulider():构造一个空的StringBulider容器。
-
public StringBulider(String str):构造一个StringBulider容器,并将字符串添加进去。
public class Demo{
public static void main(String[] args){
StringBulider sb1 = new StringBulider();
System.out.println(sb1); // 空白
StringBulider sb2 = new StringBulider("itcast");
System.out.println(sb2); // itcast
}
}1.4.4 - 常用方法
StingBulider常用的方法有两个:
- public StringBulider append(...):添加任意类型数组的字符串形式,并返回当前对象自身。
- public String toString():将当前StringBulider对象转换为String对象。
append方法:
append方法具有多种重载形式,可以接收任意类型的参数。任何数据作为参数都会将对应的字符出啊你内容添加到StringBulider中。
public class Demo{
public static void main(String[] args){
// 创建对象
StringBulider bulider = new StringBulider();
// public StringBuilder append(任意类型)
StringBulider bulider2 = bulider.append("hello");
// 对比一下
System.out.println("bulider:" + bulider);
System.out.println("bulider2:" + bulider2);
System.out.println(bulider == bulider2); // true
// 可以添加任何类型
builder.append("hello");
builder.append("world");
builder.append(true);
builder.append(100);
// 在我们开发中,会遇到调用一个方法后,返回一个对象的情况。然后使用返回的对象继续调用方法。
// 这种时候,我们就可以把代码现在一起,如append方法一样,代码如下
//链式编程
builder.append("hello").append("world").append(true).append(100);
System.out.println("builder:"+builder);
}
}toString方法:
通过toString方法,StringBulider对象将会转换为不可变的String对象,如:
public class Demo{
public static void main(String[] args){
StringBulider sb = new StringBulider("Hello").append(" World").append(" Java.");
String str = sb.toString();
System.out.println(str);
}
}1.5 - 包装类
1.5.1 - 概述
Java提供了两个类型系统,基本类型与引用类型,使用基本类型在于效率,然而很多情况,会创建对象使用,因为对象可以做更多的功能,如果想要我们的基本类型像对象一样操作,就可以使用基本类型对应的包装类。
| 基本类型 | 对应的包装类(位于java.lang包中) |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
1.5.2 - 装箱与拆箱
基本类型与对应的包装对象之间,来回转换的过程称为“装箱”与“拆箱”
- 装箱:从基本类型转换为对应的包装类对象。
- 拆箱:从包装类对象转换为对应的基本类型。
用Integer与int为例:
// 基本数值 -> 包装对象
Integer i = new Integer(3); // 使用构造函数
Integer iii = Integer.valueOf(3); // 使用后包装类中的valueOf方法
// 包装对象 -> 基本数值
int num = i.intValue();1.5.3 - 自动装箱与自动拆箱
由于我们经常要做基本类型与包装类之间的转换,从Java 5(JDK 1.5)开始,基本类型与包装类的装箱、拆箱动作
可以自动完成。
Integer i = 4;//自动装箱。相当于Integer i = Integer.valueOf(4);
i = i + 5;//等号右边:将i对象转成基本数值(自动拆箱) i.intValue() + 5;
//加法运算完成后,再次装箱,把基本数值转成对象。1.5.4 - 基本类型与字符串之间的转换
基本类型转换String总共有三种方式,查看课后资料可以得知,这里只讲最简单的一种方式:
基本类型直接与””相连接即可;如:34+""String转换成对应的基本类型
除了Character类之外,其他所有包装类都具有parseXxx静态方法可以将字符串参数转换为对应的基本类型
- public static byte parseByte(String s) :将字符串参数转换为对应的byte基本类型。
- public static short parseShort(String s) :将字符串参数转换为对应的short基本类型。
- public static int parseInt(String s) :将字符串参数转换为对应的int基本类型。
- public static long parseLong(String s) :将字符串参数转换为对应的long基本类型。
- public static float parseFloat(String s) :将字符串参数转换为对应的float基本类型。
- public static double parseDouble(String s) :将字符串参数转换为对应的double基本类型。
- public static boolean parseBoolean(String s) :将字符串参数转换为对应的boolean基本类型
代码使用:
public class Demo18WrapperParse {
public static void main(String[] args) {
int num = Integer.parseInt("100");
}
}如果字符串参数的内容无法正确转换为对应的基本类型,则会抛出 java.lang.NumberFormatException
异常。
2 - Collection、泛型
2.1 - Collection
2.1.1 - 集合概述
集合:集合是Java中提供的一种容器,可以用来存储多个数据。
集合和数组的区别:
- 数组的长度是固定的,集合的长度是可变的。
- 数组中存储的是同一类型的元素,可以存储基本数据类型值。集合存储的都是对象,而且对象的类型可以不同,在开发中一般当对象多的时候,使用集合进行存储。
2.1.2 - 集合框架
JavaSe提供了满足各种需求的API,在使用这些API之前,先了解其继承与接口操作架构,才能了解何时采用哪个类,以及类之间如何彼此合作,从而达到灵活运用。
集合按照其存储结构可以分为两大类,分别是单列集合java.util.Collection和双列集合java.util.Map。
Collection:单列集合的根类,用于存储一系列符合某种规则的元素,它有两个重要的子接口,分别是java.util.List和java.util.Set。其中,List的特点是元素有序、元素可重复。Set的特点是元素无序,而且不可重复。List接口的主要实现类有java.util.ArrayList和java.util.LinkedList,Set接口的主要实现类有java.util.HashSet和java.util.TreeSet。
从上面的描述可以看出JDK中提供了丰富的集合类库,为了便于初学者进行系统地学习,接下来通过一张图来描述
整个集合类的继承体系。

其中,橙色框里填写的都是接口类型,而蓝色框里填写的都是具体的实现类。这几天将针对图中所列举的集合类进
行逐一地讲解。
集合本身是一个工具,它存放在java.util包中。在 Collection 接口定义着单列集合框架中最最共性的内容。
2.1.3 -Collection常用功能
Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可以操作所有的单列集合。
- public boolean add(E e) : 把给定的对象添加到当前集合中 。
- public void clear() :清空集合中所有的元素。
- public boolean remove(E e) : 把给定的对象在当前集合中删除。
- public boolean contains(E e) : 判断当前集合中是否包含给定的对象。
- public boolean isEmpty() : 判断当前集合是否为空。
- public int size() : 返回集合中元素的个数。
- public Object[] toArray() : 把集合中的元素,存储到数组中。
import java.util.ArrayList;
import java.util.Collection;
public class Demo{
public static void main(String[] args){
// 创建集合对象
// 使用多态形式
Collection coll = new ArrayList();
// 使用方法
// 添加功能 boolean add(String s)
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
System.out.println(coll);
// boolean contains(E e) 判断o是否在集合中存在
System.out.println("判断 扫地僧 是否在集合当中:" + coll.contains("扫地僧"));
// boolean remove(E e) 删除指定元素
System.out.println("删除石破天:" + coll.remove("石破天"));
System.out.println("操作之后集合中元素:" + coll);
// size() 集合中有几个元素
System.out.println("集合中有 " + coll.size() + " 个元素");
// Object[] toArray()转换成一个Object数组
Object[] objects = coll.toArray();
// 遍历数组
for(int i = 0; i < objects.length; i++){
System.out.print(objects[i]);
}
// void clear() 清空数组
coll.clear();
System.out.println("集合中内容为:" + coll);
// boolean isEmpty() 判断是否为空
System.out.println(coll.isEmpty());
}
} 2.2 - Iterator迭代器
2.2.1 - Iterator接口
在程序开发中,经常需要遍历集合中所有元素,针对这种需求,JDK专门提供了一个接口 java.util.Iterator。
Iterator接口也是java集合中的一员,但它于Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作。
- public Iterator iterator():获取集合对应的迭代器,用来遍历集合中的元素。
迭代:即Collection集合元素的通用获取方式。在取元素之前要先判断集合中有没有元素,如果有,就把这个元素取出来,继续再判断,如果还有就再取出来,一直把集合中的所有元素全部取出来。这种取出方式专业术语称为迭代。
- public E next():返回迭代的下一个元素。
- public boolean hasNext():如果仍有元素可以迭代,则返回true。
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Demo{
public static void main(String[] args){
// 使用多态方式 创建对象
Collection coll = new ArrayList();
// 添加元素到集合
coll.add("串串");
coll.add("火锅");
coll.add("烧烤");
// 遍历
// 使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator it = coll.iterator();
//泛型指的是 迭代出 元素的数据类型
while(it.hasNext()){
String s = it.next(); // 获取迭代出的元素
System.out.println(s);
}
}
} 2.2.2 - 迭代器的实现原理
我们在之前案例已经完成了Iterator遍历集合的整个过程。当遍历集合时,首先通过调用t集合的iterator()方法获得
迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取
出,否则说明已到达了集合末尾,停止遍历元素。
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素.
在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的
next方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next方法时,迭代器的
索引会指向第二个元素并将该元素返回,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对
元素的遍历。
2.2.3 - 增强for
增强for循环(也称for each循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。它的内部原
理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
for(元素的数据类型 变量:Collection集合or数组){
// 写操作代码
}它用于遍历Collection和数组,通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
public class Demo{
public static void main(String[] args){
int[] arr = {3,5,6,7};
// 使用增强for遍历数组
for(int a : arr){
System.out.println(a);
}
}
}public class Demo{
public static void main(String[] args){
Collection coll = new ArrayList();
coll.add("小河神");
coll.add("老河神");
coll.add("神婆");
for(String s : coll){
System.out.println(s);
}
}
} 2.3 - 泛型
2.3.1 - 泛型概述
Collection虽然可以存储各种对象,但实际上通常Collection只存储同一类型对象。例如都是存储字符串对象。因此
在JDK5之后,新增了泛型(Generic)语法,让你在设计API时可以指定类或方法支持泛型,这样我们使用API的时候
也变得更为简洁,并得到了编译时期的语法检查。
- 泛型:可以在类或方法中预支地使用未知地类型。
一般在创建对象时,将未知的类型确定具体的类型。当没有指定泛型时,默认类型为Object类型。
2.3.2 - 使用泛型的好处
- 将运行十七地ClassCastException,转移到了编译时期变成了编译失败。
- 避免了类型强转的麻烦。
public class GenericDemo2 {
public static void main(String[] args) {
Collection list = new ArrayList();
list.add("abc");
list.add("itcast");
// list.add(5);//当集合明确类型后,存放类型不一致就会编译报错
// 集合已经明确具体存放的元素类型,那么在使用迭代器的时候,迭代器也同样会知道具体遍历元素类型
Iterator it = list.iterator();
while(it.hasNext()){
String str = it.next();
//当使用Iterator控制元素类型后,就不需要强转了。获取到的元素直接就是String类型
System.out.println(str.length());
}
}
} 泛型是数据类型的一部分,我们将类名与泛型合并一起看作数据类型。
2.3.3 - 泛型的定义与使用
在集合中会大量使用泛型,泛型用来灵活地将数据类型应用到不同的类、方法、接口当中。将数据类型作为参数进行传递。
定义和使用含有泛型的类
修饰符 class 类名<代表泛型的变量>{ }
class ArrayList{
public boolean add(E e){}
public E get(int index){}
...
} 使用泛型时,在创建对象的时候确定泛型。
ArrayList list = new ArrayList(); 自定义泛型类
public class MyCGennerClass{
// 没有MVP类型,在这里代表 未知的一种数据类型 未来传递什么类型就是什么类型
private MVP mvp;
public void setMVP(MVP mvp){
this.mvp = mvp;
}
public MVP getMVP(){
return mvp;
}
} 使用
public class Demo{
public static void main(String[] args){
// 创建一个泛型为String的类
MyGenericClass my = new MyGenericClass();
// 调用setMVP
my.setMVP("大胡子");
// 调用getMVP
String mvp = my.getMVP();
System.out.println(mvp);
// 创建一个泛型为Integer的类
MyGenericClass my2 = new MyGenericClass();
my2.setMVP(123);
Integer mvp2 = my2.getMVP();
}
} 含有泛型的方法
修饰符 <代表泛型的变量> 返回值类型 方法名(参数){}
public class MyGenericMethod{
public void show(MVP mvp){
System.out.println(mvp.getClass());
}
public MVP show2(MVP mvp){
return mvp;
}
} 使用格式:调用方法时,确定泛型的类型
public class GenericMethodDemo {
public static void main(String[] args) {
// 创建对象
MyGenericMethod mm = new MyGenericMethod();
// 演示看方法提示
mm.show("aaa");
mm.show(123);
mm.show(12.45);
}
}含有泛型的接口
修饰符 interface 接口名<代表泛型的变量>{}
public interface MyGenericInterface{
public abstract void add(E e);
public abstract E getE();
} 使用格式:1.定义类时确定泛型的类型。
public class MyImp1 implements MyGenericInterface {
@Override
public void add(String e) {
// 省略...
}
@Override
public String getE() {
return null;
}
} 使用格式:2.始终不确定泛型的类型,直到创建对象时,确定泛型的类型。
public class MyImp2 implements MyGenericInterface {
@Override
public void add(E e) {
// 省略...
}
@Override
public E getE() {
return null;
}
}
/*
* 使用
*/
public class GenericInterface {
public static void main(String[] args) {
MyImp2 my = new MyImp2();
my.add("aa");
}
} 2.3.4 - 泛型通配符
当使用泛型类或者接口时,传递的数据中,泛型类型不确定,可以通过通配符表示。但是一旦使用泛型的通配
符后,只能使用Object类中的共性方法,集合中元素自身方法无法使用。
通配符基本使用
泛型的通配符:不知道使用什么类型来接受时,此时可以使用?,?表示未知通配符。
此时只能接受数据,不能往集合中存储数据。
public static void main(String[] args) {
Collection list1 = new ArrayList();
getElement(list1);
Collection list2 = new ArrayList();
getElement(list2);
}
public static void getElement(Collection coll){}
//?代表可以接收任意类型 通配符高级使用——受限泛型
之前设置泛型的时候,实际上是可以任意设置的,只要是类就能设置,但是在Java的泛型中可以指定一个泛型的上限和下限。
泛型的上限:
- 格式:类型名称 对象名称
- 意义:只能接受该类型及其子类
泛型的下限:
- 格式:类型名称 对象名称
- 意义:只能接受该类型及其父类型
比如:现已知Object类、String类、Number类、Integer类,其中Number类是Integer类的子类。
public static void main(String[] args) { Collectionlist1 = new ArrayList (); Collection list2 = new ArrayList (); Collection list3 = new ArrayList (); Collection
2.4 - 斗地主案例
2.4.1 - 案例介绍
按照斗地主的规则,完成洗牌发牌的动作。 具体规则:
使用54张牌打乱顺序,三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。
2.4.2 - 案例分析
- 准备牌:牌可以设计为一个ArrayList,每个字符串为一张牌。 每张牌由花色数字两部分组成,我们可以使用花色
集合与数字集合嵌套迭代完成每张牌的组装。 牌由Collections类的shuffle方法进行随机排序。 - 发牌:将每个人以及底牌设计为ArrayList将最后三张牌直接存放于底牌,剩余牌通过对3取模依次发牌。
- 看牌:直接打印每个集合
2.4.3 - 代码实现
public class Demo{
public static void main(String[] args){
/*
* 1. 准备操作
* */
// 1.1 创建牌盒 将来存储牌面的
ArrayList pokerBox = new ArrayList();
// 1.2 创建花色集合
ArrayList colors = new ArrayList();
// 1.3 创建数字集合
ArrayList numbers = new ArrayList();
// 1.4 分别给花色 以及 数字集合添加元素
colors.add("♥");
colors.add("♦");
colors.add("♠");
colors.add("♣");
for(int i = 2; i <= 10; i++){
numbers.add(i + "");
}
numbers.add("J");
numbers.add("Q");
numbers.add("K");
numbers.add("A");
// 1.5 创造牌 拼接牌操作
// 拿出一个花色 然后跟每一个数字进行结合 存储到盒中
for(String color : colors){
for(String number : numbers){
String card = color + number;
pokerBox.add(card);
}
}
// 1.6 大王小王
pokerBox.add("小☺");
pokerBox.add("大☠");
// System.out.println(pokerBox);
// 洗牌 就是将牌盒中的牌 索引打乱
// Collection类 工具类 静态方法 suffer方法
// static void shuffer(List list) 使用默认随机源对指定列表进行置换
// 2 洗牌
Collections.shuffle(pokerBox);
// 3 发牌
// 3.1 创建 三个 玩家集合 创建一个底牌集合
ArrayList player1 = new ArrayList();
ArrayList player2 = new ArrayList();
ArrayList player3 = new ArrayList();
ArrayList dipai = new ArrayList();
// 遍历 牌盒 必须知道索引
for(int i = 0; i < pokerBox.size(); i++){
// 获取牌面
String card = pokerBox.get(i);
// 留出三张底牌 存到 底牌集合中
if(i >= 51){
dipai.add(card);
}else{
// %3 == 0
if(i % 3 == 0){ // 玩家1
player1.add(card);
}else if(i % 3 == 1){ // 玩家2
player2.add(card);
}else{ // 玩家3
player3.add(card);
}
}
}
System.out.println("玩家1:" + player1);
System.out.println("玩家2:" + player2);
System.out.println("玩家3:" + player3);
System.out.println("底牌:" + dipai);
}
}
3 - List、Set、数据结构、Collections
3.1 - 数据结构
3.1.1 - 数据结构有什么用
现实世界的存储,我们使用的工具和建模。每种数据结构有自己的优点和缺点,想想如果Google的数据用的是数
组的存储,我们还能方便地查询到所需要的数据吗?而算法,在这么多的数据中如何做到最快的插入,查找,删
除,也是在追求更快。
我们java是面向对象的语言,就好似自动档轿车,C语言好似手动档吉普。数据结构呢?是变速箱的工作原理。你
完全可以不知道变速箱怎样工作,就把自动档的车子从 A点 开到 B点,而且未必就比懂得的人慢。写程序这件事,
和开车一样,经验可以起到很大作用,但如果你不知道底层是怎么工作的,就永远只能开车,既不会修车,也不能
造车。当然了,数据结构内容比较多,细细的学起来也是相对费功夫的,不可能达到一蹴而就。我们将常见的数据
结构:堆栈、队列、数组、链表和红黑树 这几种给大家介绍一下,作为数据结构的入门,了解一下它们的特点即
可。
3.1.2 - 栈
栈:stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一段进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
简单来说:采用该结构的结合,对元素的存取有如下的特点。
- 先进后出(即,存进去的元素,要在后它后面的元素一次取出后,才能取出该元素)。例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
- 栈的入口、出口都是栈的顶端位置。
-
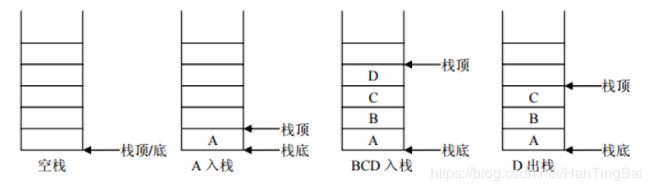
这两个名词需要注意:
-
压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
-
弹栈:就是取元素,即,把栈的顶端位置元素区出,栈中已有元素依次向栈顶方向移动一个位置。
3.1.3 - 队列
队列:queue,简称队。它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。
简单来说,采用该结构的结合,对元素的存取有如下的特点:
- 先进先出(即,存进去的元素,要在后它前面的元素一次区出,才能取出该元素)。例如,小火车过山洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
- 队列的入口、出口各占一侧。

3.1.4 - 数组
数组:Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素,就像是一排出租屋,有一百个房间,从001到100每个房间都有固定的编号,通过编号就可以快速找到租房子的人。
简单来说,采用该结构的结合,对元素的存取有如下特点。
- 查找元素快:通过索引,可以快速访问指定位置的元素。
- 增加元素慢,指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。
- 删除元素慢,指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引位置,把元素组中指定索引位置元素不复制到新数组中。
3.1.5 - 链表
链表:linkde list,由一系列节点node(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的链表由单向链表和双向链表,这里介绍的是单向链表。
简单来说,采用该结构的集合,对元素的存取有如下特点。
- 多个结点之间,通过地址进行来连接。例如,多个人手拉手,每个人使用自己的右手蜡烛下个人的左手,依此类推,这样多个人就连接到一起了。
- 查找元素慢:想要查找某个元素,需要通过连接的结点,依次向后查找指定元素。
- 增加元素快:只需要修改连接下个元素的地址即可。
- 删除元素快:只需要删除连接下个元素的地址即可。
3.1.6 - 红黑树
二叉树:binary tree,是每个节点都不超过2的有序树(tree)。
简单理解,就是一种类似于我们生活中树的结构,只不过每个节点上都最多只能有两个子节点。
二叉树是每个节点最多有两个子树的树结构。顶上的叫根节点,两边被称作”左子树“和”右子树“。
红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然是一颗二叉查找树,也就意味着,树的键值仍然是有序的。
红黑树的约束:
- 节点可以是红色的或者黑色的。
- 根节点是黑色的。
- 叶子节点(特指空节点)是黑色的。
- 每个红色节点的子节点都是黑色的。
- 任何一个节点到其每一个叶子节点的所有路径上的黑色节点数相同
红黑树的特点:
速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多于二倍。
3.2 - List集合
3.2.1 - List接口介绍
java.util.List 接口继承自 Collection接口,是单列集合的一个重要分支,习惯性地会将实现了List接口的对象称为List集合。在List集合中允许出现重复的元素,所有的元素是以一种线性方式存储的,在程序中可以通过索引来访问集合中的指定元素,另外,List集合中还有一个特点就是元素有序,即元素的存入顺序和取出顺序一致。
List接口的特点:
- 它是一个元素存取有序的集合。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素。
- 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
3.2.2 - List接口中的常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
- public void add(int index, E element):指定的元素,添加到该集合中的指定位置上。
- public E get(int index):返回集合中指定位置的元素。
- public E remove(int index):移除列表中指定的元素,返回的是移除的元素。
- public E set(int index):用指定元素替换集合中指定位置的元素,返回的是更新前的元素。
public class Demo{
public static void main(String[] args){
List list = new ArrayList();
list.add("火锅");
list.add("烧烤");
list.add("麻辣烫");
System.out.println(list);
list.add(1,"煎饼果子");
System.out.println(list);
System.out.println("删除索引位置为2的元素");
System.out.println(list.remove(2));
System.out.println(list);
list.set(0,"可乐");
System.out.println(list);
for(int i = 0; i < list.size(); i++){
System.out.println("第 " + i + " 个元素:" + list.get(i));
}
int i = 0;
for(String string : list){
System.out.println("第 " + i + " 个元素:" + string);
i++;
}
}
} 3.3 - List的子类
3.3.1 - ArrayList集合
java.util.ArrayList 集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中最多使用的功能就是查找数据、遍历数据,所以ArrayList是最常用的集合。
许多程序员开发时非常随意的使用ArrayList完成任何需求,并不严谨,这是不提倡的。
3.3.2 - LinkedList集合
java.util.LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。LinkedList是一个双向链表。
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。这些方法了解即可。
- public void addFirst(E e) :将指定元素插入此列表的开头。
- public void addLast(E e) :将指定元素添加到此列表的结尾。
- public E getFirst() :返回此列表的第一个元素。
- public E getLast() :返回此列表的最后一个元素。
- public E removeFirst() :移除并返回此列表的第一个元素。
- public E removeLast() :移除并返回此列表的最后一个元素。
- public E pop() :从此列表所表示的堆栈处弹出一个元素。
- public void push(E e) :将元素推入此列表所表示的堆栈。
- public boolean isEmpty() :如果列表不包含元素,则返回true。
LinkedList是List的子类,List中的方法LinkedList都是可以使用的,我们只需要了解LinkedList的特有方法即可。在开发时,LinkedList集合也可以作为堆栈,队列的结构使用。
public class Demo{
public static void main(String[] args){
LinkedList link = new LinkedList();
link.addFirst("abc1");
link.addFirst("abc2");
link.addFirst("abc3");
System.out.println(link);
System.out.println(link.getFirst());
System.out.println(link.getLast());
System.out.println(link.removeFirst());
System.out.println(link.removeLast());
while(link.isEmpty()){
System.out.println(link.pop());
}
System.out.println(link);
}
} 3.4 - Set接口
java.util.Set 接口和 java.util.List 接口一样,同样继承自Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格了。与List接口不同的是,Set接口中元素无需,并且都会以某种规则保证存入的元素不出现重复。
Set集合有多个子类,这里我们介绍其中的java.util.HashSet、java.util.LinkedHashSet这两个集合。
Set集合取出元素的方式可以采用:迭代器、增强for。
3.4.1 - HashSet结合介绍
java.util.HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。java.util.HashSet底层的实现其实是一个java.util.HashMap支持。
HashSet 是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法。
public class Demo{
public static void main(String[] args){
HashSet set = new HashSet();
set.add(new String("cba"));
set.add("abc");
set.add("bca");
set.add("cba");
for(String name : set){
System.out.println(name);
}
}
}
// 输出结果如下,说明集合中不能存储重复元素
// cba
// abc
// bac 3.4.2 - HashSet结合存储数据的结构(哈希表)
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。
但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈
希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找
时间
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,
其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,
就必须复写hashCode和equals方法建立属于当前对象的比较方式
3.4.3 - HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保
证HashSet集合中的对象唯一。
class Student{
private String name;
private int age;
public Student(){}
public Student(String name, int age){
this.name = name;
this.age = age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
public void setName(String name){
this.name = name;
}
public void setAge(int age){
this.age = age;
}
@Override
public boolean equals(Object o){
if(this == o)
return true;
if(o == null || (getClass() != o.getClass()))
return false;
Student student = (Student)o;
return age == student.age && Objects.equals(name,student.name);
}
@Override
public int hashCode(){
return Objects.hash(name, age);
}
@Override
public String toString(){
return "name = " + name + "," + "age = " + age;
}
}
public class Demo{
public static void main(String[] args){
// 创建集合对象 该集合中存储 Student类型对象
HashSet stuSet = new HashSet();
// 存储
Student stu = new Student("于谦", 43);
stuSet.add(stu);
stuSet.add(new Student("郭德纲",44));
stuSet.add(new Student("于谦",43));
stuSet.add(new Student("郭麒麟",23));
for(Student stu2 : stuSet){
System.out.println(stu2);
}
}
}
// 输出结果
// name = 郭德纲,age = 44
// name = 于谦,age = 43
// name = 郭麒麟,age = 23 3.4.5 - LinkedHashSet
HashSet是保证元素唯一,如果要保证有序呢?
在HashSet下面有一个子类java.util.LinkedHashSet,它是链表和哈希表组成的一个数据存储结构。
public class Demo{
public static void main(String[] args){
Set set = new LinkedHashSet();
set.add("bbb");
set.add("aaa");
set.add("abc");
set.add("bbc");
Interator it = set.iterator();
while(it.hashNext()){
System.out.println(it.next());
}
}
}
// 输出结果
// bbb
// aaa
// abc
// bbc 3.4.6 - 可变参数
在JDK1.5之后,如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们可以对其简化成如下格式:
修饰符 返回值类型 方法名(参数类型... 形象名){}其实这个书写完全等价于:
修饰符 返回值类型 方法名(参数类型[] 形象名){}只是后面这种定义,在调用时必须传递数组,而前者可以直接传递数据即可。
JDK1.5以后,出现了简化操作,...用在参数上,称之为可变参数。
同样是代表数组,但是在调用这个带有可变参数的方法时,不用创建数组(这就是简单之处),直接将数组中的元素
作为实际参数进行传递,其实编译成的class文件,将这些元素先封装到一个数组中,在进行传递。这些动作都在编
译.class文件时,自动完成了。
public class Demo{
public static void main(String[] args){
int[] arr = {1,4,62,432,2};
int sum = getSum(arr);
System.out.println(sum);
int sum2 = getSum(6,7,2,12,2121);
System.out.println(sum2);
}
public static int getSum(int... arr){
int sum = 0;
for(int a : arr){
sum += a;
}
return sum;
}
}
//如果在方法书写时,这个方法拥有多参数,参数中包含可变参数,可变参数一定要写在参数列表的末尾位置。3.5 - Collections
3.5.1 - 常用功能
java.utils.Collections 是集合工具类,用来对集合进行操作。部分方法如下:
- public static
boolean addAll(Collection 往集合中添加一些元素。c, T... elements) : - public static void shuffle(List list) :打乱顺序 :打乱集合顺序。
- public static
void sort(List 将集合中元素按照默认规则排序。list) : - public static
void sort(List 将集合中元素按照指定规则排list,Comparator ) :
序。
public class Demo{
public static void main(String[] args){
ArrayList list = new ArrayList();
Collections.addAll(list, 5,222,1,2);
System.out.println(list);
Collections.sort(list);
System.out.println(list);
}
}
// 结果
// [5,222,1,2]
// [1,2,5,222] 代码演示之后 ,发现我们的集合按照顺序进行了排列,可是这样的顺序是采用默认的顺序,如果想要指定顺序那该
怎么办呢?
我们发现还有个方法没有讲, public static
元素按照指定规则排序。接下来讲解一下指定规则的排列。
3.5.2 - Comparator比较器
public static
public class Demo{
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("cba");
list.add("aba");
list.add("sba");
list.add("nba");
//排序方法
Collections.sort(list);
System.out.println(list);
}
}
// 结果
// [aba,cba,nba,sba] 我们使用的是默认的规则完成字符串的排序,那么默认规则是如何定义出来的呢?
说到排序了,简单来说就是两个对象之间比大小,那么在Java中提供了两种比较的实现方式,一种是比较死板的采用 java.long.Comparable 接口去实现,一种是灵活的当我需要做排序的时候再去选择的 java.util.Comparator 接口完成。
那么我们采用的 public static
需要实现Comparable接口完成比较的功能,在String类型上如下:
public final class String implements java.io.Serializable, Comparable, CharSequence { String类实现了这个接口,并完成了比较规则的定义,但是这样就把这种规则写死了,那比如我想要字符串按照第
一个字符降序排列,那么这样就要修改String的源代码,这是不可能的了,那么这个时候我们可以使用
public static
Comparator这个接口,位于位于java.util包下,排序是comparator能实现的功能之一,该接口代表一个比较器,比
较器具有可比性!顾名思义就是做排序的,通俗地讲需要比较两个对象谁排在前谁排在后,那么比较的方法就是:
- public int compare(String o1, String o2) :比较其两个参数的顺序。
两个对象比较的结果有三种:大于,等于,小于。
如果要按照升序排序, 则o1 小于o2,返回(负数),相等返回0,01大于02返回(正数) 如果要按照
降序排序 则o1 小于o2,返回(正数),相等返回0,01大于02返回(负数)
public class Demo{
public static void main(String[] args){
ArrayList list = new ArrayList();
list.add("cba");
list.add("aba");
list.add("sba");
list.add("nba");
Collections.sort(list, new Comparator{
@Override
public int compare(String o1, String o2){
return o2.charAt(0) - o1.charAt(o);
}
});
System.out.println(list);
}
}
// 结果
// [sba,nba,cba,aba] 3.5.3 - 简述Comparable和Comparator两个接口的区别
Comparable:强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的compareTo方法
被称为它的自然比较方法。只能在类中实现compareTo()一次,不能经常修改类的代码实现自己想要的排序。实现
此接口的对象列表(和数组)可以通过Collections.sort(和Arrays.sort)进行自动排序,对象可以用作有序映射中
的键或有序集合中的元素,无需指定比较器。
Comparator:强行对某个对象进行整体排序。可以将Comparator 传递给sort方法(如Collections.sort或
Arrays.sort),从而允许在排序顺序上实现精确控制。还可以使用Comparator来控制某些数据结构(如有序set或
有序映射)的顺序,或者为那些没有自然顺序的对象collection提供排序。
3.5.4 - 练习
class Student implements Comparable{
private String name;
private int age;
public Student(){}
public Student(String name, int age){
this.name = name;
this.age = age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
public void setName(String name){
this.name = name;
}
public void setAge(int age){
this.age = age;
}
/*@Override
public boolean equals(Object o){
if(this == o)
return true;
if(o == null || (getClass() != o.getClass()))
return false;
Student student = (Student)o;
return age == student.age && Objects.equals(name,student.name);
}
@Override
public int hashCode(){
return Objects.hash(name, age);
}*/
@Override
public String toString(){
return "name = " + name + "," + "age = " + age;
}
@Override
public int compareTo(Student o) {
return this.age - o.age; // 升序
}
}
class HelloWorld{
public static void main(String[] args){
// 创建四个学生对象 存储到集合中
ArrayList list = new ArrayList();
list.add(new Student("rose",18));
list.add(new Student("jack",16));
list.add(new Student("abc",16));
list.add(new Student("ace",17));
list.add(new Student("mark",16));
/*
让学生 按照年龄排序 升序
*/
Collections.sort(list); //要求 该list中元素类型 必须实现比较器Comparable接口
for (Student student : list) {
System.out.println(student);
}
}
}
// name = jack,age = 16
// name = abc,age = 16
// name = mark,age = 16
// name = ace,age = 17
// name = rose,age = 18 3.5.5 - 扩展
如果在使用的时候,想要独立的定义规则,可以采用 Collections.sort(List list, Comparator) 方式,自己定义规则:
Collections.sort(list, new Comparator() {
@Override
public int compare(Student o1, Student o2) {
return o2.getAge()‐o1.getAge();//以学生的年龄降序
}
});
/*
Student{name='rose', age=18}
Student{name='ace', age=17}
Student{name='jack', age=16}
Student{name='abc', age=16}
Student{name='mark', age=16}
*/ Collections.sort(list, new Comparator() {
@Override
public int compare(Student o1, Student o2) {
// 年龄降序
int result = o2.getAge()‐o1.getAge();//年龄降序
if(result==0){ //第一个规则判断完了 下一个规则 姓名的首字母 升序
result = o1.getName().charAt(0)‐o2.getName().charAt(0);
}
return result;
}
});
/*
Student{name='rose', age=18}
Student{name='ace', age=17}
Student{name='abc', age=16}
Student{name='jack', age=16}
Student{name='mark', age=16}
*/
4 - Map
4.1 - Map集合
4.1.1 - 概述
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,
这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即 java.util.Map 接
口。
我们通过查看 Map 接口描述,发现 Map 接口下的集合与 Collection 接口下的集合,它们存储数据的形式不同。
- Collection中的集合,元素是孤立存在的,向集合中存储元素采用一个个元素的方式存储。
- Map中的集合,元素是成对存在的。每个元素由键与值两部分组成,通过键可以找所对应的值。
- Collection中的集合称为单列集合,Map中的集合称为双列集合。
- 需要注意的是,Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
4.1.2 - Map常用子类
通过查看Map接口描述,看到Map有多个子类,这里我们主要讲解常用的HashMap集合、LinkedHashMap集合。
-
HashMap:存储数据采用的哈希表结构,元素的存取顺序不能保证一致,由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals方法。
-
LinkedHashMap:HashMap下有个子类LinkedHashMap,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致;通过哈希表结构可以保证键的唯一、不重复,需要重写键的hashCode方法、equals方法。
Map接口中的集合都有两个泛型变量,在使用时,要为两个泛型变量赋予数据类型,两个泛型变量的数据类型可以相同,也可以不同。
4.1.3 - Map接口中的常用方法
Map接口定义了很多方法,常用的如下:
- public V put(K key, V value) : 把指定的键与指定的值添加到Map集合中。
- public V remove(Object key) : 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的
值。 - public V get(Object key) 根据指定的键,在Map集合中获取对应的值。
- public Set
keySet() : 获取Map集合中所有的键,存储到Set集合中。 - public Set
public class Demo{
public static void main(String[] args){
// 创建 map 对象
HashMap map = new HashMap();
// 添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊利");
map.put("邓超", "孙俪");
System.out.println(map);
// String remove(String key)
System.out.println(map.remove("邓超"));
System.out.println(map);
// 查看 黄晓明的媳妇 是谁
System.out.println(map.get("黄晓明"));
}
} 使用put方法时,若指定的键(key)在集合中没有,则没有这个键对应的值,返回null,并把指定的键值添加到
集合中;若指定的键(key)在集合中存在,则返回值为集合中键对应的值(该值为替换前的值),并把指定键所对应的
值,替换成指定的新值。
4.1.4 - Map集合遍历键找值方式
键找值方式:通过元素中的键,获取键所对应的值
分析步骤:
- 获取Map中所有的键,由于键是唯一的,所以返回一个Set集合存储所有的键。方法提示keyset()。
- 遍历键的Set集合,得到每一个键
- 根据键,获取键所对应的值。
class Demo{
public static void main(String[] args){
// 创建 map 对象
HashMap map = new HashMap();
// 添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊利");
map.put("邓超", "孙俪");
System.out.println(map);
//获取所有的键,获取键集
Set keys = map.keySet();
// 遍历键集 得到 每一个值
for(String key : keys){
String value = map.get(key);
System.out.println(key + "的cp是:" + value);
}
}
} 4.1.5 - Entry键值对对象
我们已经知道, Map 中存放的是两种对象,一种称为key(键),一种称为value(值),它们在在 Map 中是一一对应关
系,这一对对象又称做 Map 中的一个 Entry(项) 。 Entry 将键值对的对应关系封装成了对象。即键值对对象,这
样我们在遍历 Map 集合时,就可以从每一个键值对( Entry )对象中获取对应的键与对应的值。
既然Entry表示了一对键和值,那么也同样提供了获取对应键和对应值得方法。
- public K getKey() :获取Entry对象中的键。
- public V getValue() :获取Entry对象中的值。
在Map集合中也提供了获取所有Entry对象的方法:
- public Set
4.1.6 - Map集合遍历键值对方式
键值对方式:即通过集合中每个键值对(Entry)对象,获取键值对(Entry)对象中的键与值。
操作步骤:
- 获取Map集合中,所有的键值对对象,以Set集合形式返回。
- 遍历包含键值对对象的Set集合,得到每一个键值对对象。
- 通过键值对对象,获取Entry对象中的键与值。
class Demo{
public static void main(String[] args){
// 创建 map 对象
HashMap map = new HashMap();
// 添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊利");
map.put("邓超", "孙俪");
System.out.println(map);
//获取所有的键,获取键集
Set> entrySet = map.entrySet();
// 遍历得到每一个entry对象
for(Map.Entry entry : entrySet){
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "的cp是" + value);
}
}
} Map集合不能直接使用迭代器或者foreach进行遍历。但是转成Set之后就可以使用了。
4.1.7 - HashMap存储自定义类型键值
练习:每位学生(姓名,年龄)都有自己的家庭住址。那么,既然有对应关系,则将学生对象和家庭住址存储到
map集合中。学生作为键, 家庭住址作为值。
public class Student{
private String name;
private int age;
public Student() {}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
public class HashMapTest {
public static void main(String[] args) {
//1,创建Hashmap集合对象。
Mapmap = new HashMap();
//2,添加元素。
map.put(newStudent("lisi",28), "上海");
map.put(newStudent("wangwu",22), "北京");
map.put(newStudent("zhaoliu",24), "成都");
map.put(newStudent("zhouqi",25), "广州");
map.put(newStudent("wangwu",22), "南京");
//3,取出元素。键找值方式
SetkeySet = map.keySet();
for(Student key: keySet){
Stringvalue = map.get(key);
System.out.println(key.toString()+"....."+value);
}
}
} - 当给HashMap中存放自定义对象时,如果自定义对象作为key存在,这时要保证对象唯一,必须复写对象的
hashCode和equals方法(如果忘记,请回顾HashSet存放自定义对象)。 - 如果要保证map中存放的key和取出的顺序一致,可以使用 java.util.LinkedHashMap 集合来存放
4.1.8 - LinkedHashMap
我们知道HashMap保证成对元素唯一,并且查询速度很快,可是成对元素存放进去是没有顺序的,那么我们要保
证有序,还要速度快怎么办呢?
在HashMap下面有一个子类LinkedHashMap,它是链表和哈希表组合的一个数据存储结构。
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap map = new LinkedHashMap();
map.put("邓超", "孙俪");
map.put("李晨", "范冰冰");
map.put("刘德华", "朱丽倩");
Set> entrySet = map.entrySet();
for (Entry entry : entrySet) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
}
} 4.1.9 - Map练习
需求:
计算一个字符串中每个字符出现的次数
分析:
- 获取一个字符串对象。
- 创建一个Map集合,键代表字符,值代表次数。
- 遍历字符串得到每个字符。
- 判断Map中是否有该键。
- 如果没有,第一次出现,存储次数为1;如果有,则说明已经出现过,获取到对应的值进行++,再次存储。
- 打印最终结果
代码:
class Demo{
public static void main(String[] args){
System.out.println("请录入一个字符串:");
String line = new Scanner(System.in).nextLine();
// 定义 每个字符出现次数的方法
findChar(line);
}
private static void findChar(String line){
// 1 创建一个集合 存储字符 以及出现的次数
HashMap map = new HashMap();
// 2 遍历字符串
for(int i = 0; i < line.length(); i++){
char c = line.charAt(i);
// 判断 该字符 是否在键集中
if(!map.containsKey(c)){
map.put(c, 1);
} else {
Integer count = map.get(c);
map.put(c, ++count);
}
}
System.out.println(map);
}
} 4.2 - 补充知识点
4.2.1 - JDK9对集合添加的优化
通常,我们在代码中创建一个集合(例如,List 或 Set ),并直接用一些元素填充它。 实例化集合,几个 add方法
调用,使得代码重复。
public class Demo01 {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add("abc");
list.add("def");
list.add("ghi");
System.out.println(list);
}
} Java 9,添加了几种集合工厂方法,更方便创建少量元素的集合、map实例。新的List、Set、Map的静态工厂方法可
以更方便地创建集合的不可变实例。
public class HelloJDK9 {
public static void main(String[] args) {
Set str1=Set.of("a","b","c");
//str1.add("c");这里编译的时候不会错,但是执行的时候会报错,因为是不可变的集合
System.out.println(str1);
Map str2=Map.of("a",1,"b",2);
System.out.println(str2);
List str3=List.of("a","b");
System.out.println(str3);
}
} 需要注意以下两点:
1:of()方法只是Map,List,Set这三个接口的静态方法,其父类接口和子类实现并没有这类方法,比如
HashSet,ArrayList等待;2:返回的集合是不可变的;
4.3 - 模拟斗地主洗牌发牌
4.3.1 - 案例介绍
按照斗地主的规则,完成洗牌发牌的动作。
- 组装54张扑克牌将
- 54张牌顺序打乱
- 三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。
- 查看三人各自手中的牌(按照牌的大小排序)、底牌
4.3.2 - 案例需求分析
- 准备牌:完成数字与纸牌的映射关系:使用双列Map(HashMap)集合,完成一个数字与字符串纸牌的对应关系(相当于一个字典)。
- 洗牌:通过数字完成洗牌发牌
- 发牌:将每个人以及底牌设计为ArrayList,将最后3张牌直接存放于底牌,剩余牌通过对3取模依次发牌。存放的过程中要求数字大小与斗地主规则的大小对应。将代表不同纸牌的数字分配给不同的玩家与底牌。
- 看牌:通过Map集合找到对应字符展示。通过查询纸牌与数字的对应关系,由数字转成纸牌字符串再进行展示。
4.3.3 - 实现代码步骤
class HelloWorld{
public static void main(String[] args){
// 1 组装54张扑克牌
// 1.1 创建Map集合存储
HashMap pokerMap = new HashMap();
// 1.2 创建 花色集合 和 数字集合
ArrayList colors = new ArrayList();
ArrayList numbers = new ArrayList();
// 1.3 存储 花色 与 数字
Collections.addAll(colors, "♦", "♣", "♥", "♠");
Collections.addAll(numbers, "2", "A", "K", "Q", "J", "10", "9", "8", "7", "6", "5", "4", "3");
// 设置 存储编号变量
int count = 1;
pokerMap.put(count++, "大王");
pokerMap.put(count++, "小王");
// 1.4 创建牌 存储到map集合中
for(String number : numbers){
for(String color : colors){
String card = color + number;
pokerMap.put(count++, card);
}
}
// 2 将54张牌打乱
// 2.1 取出编号 集合
Set numberSet = pokerMap.keySet();
// 2.2 因为要将编号打乱顺序 所以 应该先进行转换到list集合中
ArrayList numberlist = new ArrayList();
numberlist.addAll(numberSet);
// 2.3 打乱顺序
Collections.shuffle(numberlist);
// 3 完成三个人的交替摸牌
// 3.1 发牌的编号 创建三个玩家集合 和一个 底牌集合
ArrayList noP1 = new ArrayList();
ArrayList noP2 = new ArrayList();
ArrayList noP3 = new ArrayList();
ArrayList dipaiNo = new ArrayList();
// 3.2 发牌
for(int i = 0; i = 51){
dipaiNo.add(no);
} else {
if(i % 3 == 0){
noP1.add(no);
} else if(i % 3 == 1){
noP2.add(no);
} else{
noP3.add(no);
}
}
}
// 4 查看三人手中各自的牌(按照牌的大小顺序)、底牌
// 4.1 对手中牌进行排序
Collections.sort(noP1);
Collections.sort(noP2);
Collections.sort(noP3);
Collections.sort(dipaiNo);
// 4.2 进行牌面的转换
// 创建三个玩家牌面集合 以及底牌牌面集合
ArrayList player1 = new ArrayList();
ArrayList player2 = new ArrayList();
ArrayList player3 = new ArrayList();
ArrayList dipai = new ArrayList();
// 4.3 转换
for(Integer i : noP1){
// 4.4 根据编号找到 牌面 pokerMap
String card = pokerMap.get(i);
player1.add(card);
}
for(Integer i : noP2){
// 4.4 根据编号找到 牌面 pokerMap
String card = pokerMap.get(i);
player2.add(card);
}
for(Integer i : noP3){
// 4.4 根据编号找到 牌面 pokerMap
String card = pokerMap.get(i);
player3.add(card);
}
for(Integer i : dipaiNo){
// 4.4 根据编号找到 牌面 pokerMap
String card = pokerMap.get(i);
dipai.add(card);
}
System.out.println("火锅:" + player1);
System.out.println("烧烤:" + player2);
System.out.println("串串:" + player3);
System.out.println("面条:" + dipai);
}
}
5 - 异常、线程
5.1 - 异常
5.1.1 - 异常概念
异常:指的是程序在执行过程中,出现的非正常情况,最终会导致JVM的非正常停止。
在Java等面向对象的编程语言中,异常本身是一个类,产生异常就是创建异常对象并抛出了一个异常对象。java处理异常的方式是中断处理。
异常指的并不是语法错误,语法错了,编译不会通过,不会产生字节码文件,根本不能运行。
5.1.2 - 异常体系
异常机制其实是帮助我们找到程序中的问题,异常的根类是 java.lang.Threowable,其中有两个子类:java.long.Error 与 java.lang.Exception ,平常所说的异常指 java.lang.Exception。
Throwable体系:
- Error:严重错误,无法通过处理的错误,只能事先避免,好比绝症
- Exception:表示异常,异常产生后程序员可以通过代码的方式纠正,使程序继续运行,是必须要处理的。好比感冒,阑尾炎。
Throwable中的常用方法:
- public void printStackTrace():打印异常的详细信息。包含了异常的类型,异常的原因,还包括异常出现的位置,在开发和调试阶段,都得使用printStackTrace。
- public String getMessage():获取发生异常的原因。提示给用户的时候,就是提示错误原因。
- public String toString():获取异常的类型和异常描述(不用)。
出现异常,不要紧张,把异常的简单类名,拷贝到API中去查。
5.1.3 - 异常分类
我们平常说的异常就是指Exception,因为这类异常一旦出现,我们就要对代码进行更正,修复程序。
异常(Exception)的分类:根据在编译时期还是运行时期去检查异常。
-
编译时期异常:checked异常。在编译时期,就会检查,如果没有处理异常,则编译失败。
-
运行时期异常:runtime异常。在运行时期,检查异常,在编译时期,运行异常不会被编译器检测(不报错)。
5.2 - 异常的处理
Java异常处理的五个关键字:try、catch、finally、throw、throws
5.2.1 - 抛出异常throw
在编写程序时,我们必须要考虑程序出现问题的情况。比如,在定义方法时,方法需要接受参数。那么,当调用方法使用接受到的参数时,首先需要对参数数据进行合法的判断,数据若不合法,就应该告诉调用者,传递合法的数据进来。这时需要使用抛出异常的方式来告诉调用者。
在java中,提供了一个throw关键字,它用来抛出一个指定的异常对象,那么,抛出一个异常具体如何操作呢?
- 创建一个异常对象。封装一些提示信息(信息可以自己编写)。
- 需要将这个异常对象告知调用者,通过关键字throw就可以完成。 throw 异常对象。
throw用在方法内,用来抛出一个异常对象,将这个异常对象传递到调用者处,并结束当前方法的执行。
使用格式:
throw new 异常类名(参数);例如:
throw new NullPointerException("要访问的arr数组不存在");
throw new ArrayIndexOutOfBoundException("该索引在数组中不存在,已超出范围");class Demo{
public static void main(String[] args){
// 创建一个数组
int[] arr = {2,4,52,2};
// 根据索引找对应的元素
int index = 4;
int element = getElement(arr,index);
System.out.println(element);
System.out.println("over");
}
private static int getElement(int[] arr, int index) {
//判断 索引是否越界
if(index < 0 || index > arr.length - 1){
// 判断条件如果满足,当执行完throw抛出异常对象后,方法已经无法继续运算。
// 这时就会结束当前方法的执行,并将异常告知给调用者。这时就需要通过异常来解决。
throw new ArrayIndexOutOfBoundsException("角标越界");
}
int element = arr[index];
return element;
}
}注意:如果产生了问题,我们就会throw将问题描述类即异常进行抛出,也就是将问题返回给该方法的调用
者。那么对于调用者来说,该怎么处理呢?一种是进行捕获处理,另一种就是继续讲问题声明出去,使用throws
声明处理。
5.2.2 - Objects非空判断
我们学习过一个类Objects,曾提过它由一些静态的实用方法组成,这些方法时null-save(空指针安全的)或者null-tolerant(容忍空指针的),在它的源码中,对对象为null的值进行了抛出异常操作。
- public static
T requireNonNull(T obj): 查看指定引用对象不是null。
查看源码发现这里对为null的进行了抛出异常操作:
public static T requireNonNull(T obj) {
if (obj == null)
throw new NullPointerException();
return obj;
} 5.2.3 - 声明异常throws
声明异常:将问题标识出来,报告给调用者。如果方法内通过throw抛出了编译时异常,而没有捕获处理,那么必须通过throws进行声明,让调用者去处理。
关键字throws运用于方法声明上面,用于表示当前方法不处理异常,而是提醒该方法的调用者来处理异常。
// 声明异常格式
修饰符 返回值类型 方法名(参数) throws 异常类名1,异常类名2...{}
// 代码演示
public class ThrowsDemo{
public static void main(String[] args) throws FileNotFoundException{
read("a.txt");
}
// 如果定义功能时由问题发生需要报告给调用者,可以通过在方法上使用throws关键字进行声明
public static void read(String path) trhows FileNotFoundException{
if(!path.equals("a.txt")){
// 假设 如果不是 a.txt 就会认为 该文件不存在 是一个错误 也就是异常 throw
throw new FileNotFoundException("文件不存在");
}
}
}throws用于进行异常类的声明,若该方法可能有多种异常情况产生,那么在throws后面可以写多个异常类,用逗
号隔开。
class Demo{
public static void main(String[] args) throws IOException {
read("a.txt");
}
public static void read(String path)throws FileNotFoundException, IOException {
if (!path.equals("a.txt")) {
// 我假设 如果不是 a.txt 认为 该文件不存在 是一个错误 也就是异常 throw
throw new FileNotFoundException("文件不存在");
}
if (!path.equals("b.txt")) {
throw new IOException();
}
}
}5.2.4 - 捕获异常try...catch
如果异常出现的话,会立刻终止程序,所以我们得处理异常:
- 该方法不处理,而是声明抛出,由该方法的调用者来处理(throws)。
- 在方法中使用try-catch的语句块来处理异常。
try-catch的方式就是捕获异常。
- 捕获异常:java中对异常有针对性的语句进行捕获,可以对出现的异常进行指定方式的处理。
class Demo{
public static void main(String[] args){
// 当产生异常的时候,必须有处理方式,要么捕获,要么声明
try{
read("b.txt");
} catch(FileNotFoundException e) {
System.out.println(e);
}
System.out.println("over");
}
private static void read(String path) throws FileNotFoundException{
if(!path.equals("a.txt")){
throw new FileNotFoundException("文件不存在");
}
}
}如何获取异常信息:Throwable中定义了一些查看方法
- public String getMessage() :获取异常的描述信息,原因(提示给用户的时候,就提示错误原因。
- public String toString() :获取异常的类型和异常描述信息(不用)。
- public void printStackTrace() :打印异常的跟踪栈信息并输出到控制台。
包含了异常的类型、异常的原因,还包括异常出现的位置,在开发和调试阶段,都得使用print Stack Trace。
5.2.5 - finally代码块
finally:有一些特定的代码无论异常是否发生,都需要执行。另外,因为异常会引发程序跳转,导致有些语句执行不到,而finally就是解决这个问题的,在finally代码块中存放的代码都是一定会被执行的。
什么时候的代码必须最终执行?
当我们在try语句块中打开了一些物理资源(磁盘文件/网络连接/数据库连接等),我们都得在使用完后,最终关闭打开的资源。
// finally的语法:
try ... catch ... finally : 自身需要处理异常,最终还得关闭资源
// 代码参考
class Demo{
public static void main(String[] args){
try{
read("a.txt");
} catch(FileNotFoundException e) {
// 抓取到的时编译器异常,跑出去的时运行期
throw new RuntimeException(e);
} finally {
System.out.println("不管程序怎么样,这里都会被执行");
}
System.out.println("over");
}
private static void read(String path) throws FileNotFoundException{
if(!path.equals("a.txt")){
throw new FileNotFoundException("文件不存在");
}
}
}当只有在try或者catch中调用退出JVM的相关方法,此时finally才不会执行,否则finally永远会执行。
5.2.6 - 异常注意体系
多个异常使用捕获又该如何处理呢?
- 多个异常分别处理
- 多个异常一次捕获,多次处理。
- 多个异常一次捕获一次处理。
一般我们是使用一次捕获多次处理方式,格式如下:
try{
编写可能会出现异常的代码
} catch(异常类型A e){ 当try中出现A类型异常,就用catch来捕获
处理异常的代码
// 记录日志/打印异常信息/继续抛出异常
} catch(异常类型B e){ 当try中出现B类型异常,就用catch来捕获
处理异常的代码
// 记录日志/打印异常信息/继续抛出异常
}这种异常处理方式,要求多个catch中的异常不能相同,并且如果catch中的多个异常之间有父子类异常的关系,那么子类异常要求在上面的catch处理,父类异常在下面的catch处理。
- 运行时异常被抛出可以不处理,即不捕获也不声明抛出。
- 如果finally有return语句,永远返回finally中的结果,避免该情况。
- 如果父类抛出了多个异常,子类重写父类方法时,抛出和父类相同的异常或者是父类异常的子类或者不抛出异常。
- 父类方法没有抛出异常,子类重写父类该方法时也不可抛出异常。此时子类产生该异常,只能捕获处理,不能声明抛出。
5.3 - 自定义异常
5.3.1 - 概述
为什么需要自定义异常类:
我们说了java中不同的异常类,分别表示这某一种具体的异常情况,那么在开发过程中总有些异常情况时SUN没有定义的,此时我们根据自己业务的异常情况来定义异常类。
什么是自定义异常类:
在开发中根据自己业务的异常情况来定义异常类。
自定义一个业务逻辑异常:RegisterException,一个注册异常类。
异常类如何定义:
- 自定义一个编译器异常:自定义类,并继承于 java.lang.Exception。
- 自定义一个运行时期的异常类:自定义类 并继承于 java.lang.RuntimeException。
5.3.2 - 自定义异常的练习
要求:我们模拟注册,如果用户名已存在,则抛出异常并提示:该用户名已经被注册。
// 定义登陆异常类
// 业务逻辑异常
class RegisterException extends Exception{
public RegisterException(){}
// @param message 表示异常提示
public RegisterException(String message){
super(message);
}
}
class Demo{
// 模拟数据库中已经存在的账号
private static String[] names = {"bill", "hill", "jill"};
public static void main(String[] args){
try{
checkUsername("null");
System.out.println("注册成功"); // 如果没有发生异常就是注册成功
} catch(RegisterException | LoginException e){
// 处理异常
e.printStackTrace();
}
}
// 判断当前注册账号是否存在
// 因为是编译器异常,又想调用者去处理,所以声明该异常
public static boolean checkUsername(String uname) throws LoginException, RegisterException {
for(String name : names){
if(name.equals(uname)){
throw new RegisterException(name + " 用户名已经被注册。");
}
}
return true;
}
}5.4 - 多线程
5.4.1 - 并发与并行
- 并发:指两个或多个事件在同一时间段内发生。
- 并行:指两个或多个事件在同一时刻发生(同时发生)。
在操作系统中,安装了多个程序,并发指的是在一段时间内宏观上有多个程序同时运行,这在单 CPU 系统中,每
一时刻只能有一道程序执行,即微观上这些程序是分时的交替运行,只不过是给人的感觉是同时运行,那是因为分
时交替运行的时间是非常短的。
而在多个 CPU 系统中,则这些可以并发执行的程序便可以分配到多个处理器上(CPU),实现多任务并行执行,
即利用每个处理器来处理一个可以并发执行的程序,这样多个程序便可以同时执行。目前电脑市场上说的多核
CPU,便是多核处理器,核 越多,并行处理的程序越多,能大大的提高电脑运行的效率
注意:单核处理器的计算机肯定是不能并行的处理多个任务的,只能是多个任务在单个CPU上并发运行。同
理,线程也是一样的,从宏观角度上理解线程是并行运行的,但是从微观角度上分析却是串行运行的,即一个
线程一个线程的去运行,当系统只有一个CPU时,线程会以某种顺序执行多个线程,我们把这种情况称之为
线程调度。
5.4.2 - 线程与进程
- 进程:是指一个内存中运行的应用程序,每个进程都有一个独立的内存空间,一个应用程序可以同时运行多个进程;进程也是程序的一次执行过程,时系统运行程序的基本单位;系统运行一个程序即是一个进程从创建,运行到消亡的过程。
- 线程:线程是进程中的一个执行单元,负责当前进程中的程序执行,一个进程中至少有一个线程,一个进程中是可以有多个线程的,这个应用程序也可以被称为多线程程序。
简而言之:一个程序运行后至少有一个进程,一个进程里面可以包含多个线程。
5.4.3 - 创建线程类
java使用 java.lang.Thread 类代表线程,所有的线程对象都必须是Thread类或其子类的实例。每个线程的作用是完成一定的任务,实际上就是执行一段程序流即一段顺序执行的代码。Java使用线程执行体来代表这段程序流。
java通过继承Thread类来创建并启动多线程的步骤如下:
- 定义Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程需要完成的任务,因此把run()方法称为线程执行体。
- 创建Thread子类的实例,即创建了线程对象。
- 调用线程对象的start()方法来启动该线程。
public class Demo{
public static void main(String[] args){
// 创建自定义线程对象
MyThread mt = new MyThread("新的线程!");
// 开启新线程
mt.start();
// 在主方法中执行for循环
for(int i = 0; i < 10; i++){
System.out.println("main线程!" + i);
}
}
}自定义线程类:
public class MyThread extends Thread{
// 定义指定线程名称的构造方法
public MyThread(String name){
// 调用父类的String参数的构造方法,指定线程的名称
super(name);
}
// 重写run方法,完成该线程的执行逻辑
@Override
public void run(){
for(int i = 0; i < 10; i++){
System.out.println(getName() + " :正在执行!" + i);
}
}
}
6 - 线程、同步
6.1 - 线程
6.1.1 - 多线程原理
class MyThread extends Thread{
// 利用继承中的特点 将线程名称传递 进行设置
public MyThread(String name){
super(name);
}
// 重写run方法 定义线程要执行的代码
public void run(){
for(int i = 0; i < 20; i++){
System.out.println(getName() + i);
}
}
}
class Demo{
public static void main(String[] args){
System.out.println("这里是main线程");
MyThread mt = new MyThread("小强");
mt.start();
for(int i = 0; i < 20; i++){
System.out.println("旺财:" + i);
}
}
}程序启动运行main时候,java虚拟机启动一个进程,主线程main在main调用的时候被创建,随着调用mt的对象的start方法,另一个新的线程也启动了,这样,整个应用就在多线程下运行。
多线程执行时,在栈内存中,其实每一个执行线程都有一篇属于自己的栈内存空间。进行方法的压栈和弹栈。
当执行线程的任务结束了,线程自动在栈内存中释放了,但是当所有的执行线程都结束了,那么进程就结束了。
6.1.2 - Thread类
java.lang.Thread 类中定义了一些有关线程的方法。
构造方法:
- public Thread() :分配一个新的线程对象。
- public Thread(String name) :分配一个指定名字的新的线程对象。
- public Thread(Runnable target) :分配一个带有指定目标新的线程对象。
- public Thread(Runnable target,String name) :分配一个带有指定目标新的线程对象并指定名字。
常用方法:
- public String getName() :获取当前线程名称。
- public void start() :导致此线程开始执行; Java虚拟机调用此线程的run方法。
- public void run() :此线程要执行的任务在此处定义代码。
- public static void sleep(long millis) :使当前正在执行的线程以指定的毫秒数暂停(暂时停止执行)。
- public static Thread currentThread() :返回对当前正在执行的线程对象的引用。
翻阅API后得知创建线程的方式总共有两种,一种是继承Thread类方式,一种是实现Runnable接口方式,方式一我
们已经完成,接下来讲解方式二实现的方式。
6.1.3 - 创建线程方式二
采用 java.lang.Runnable 也是非常常见的一种,只需要重写run方法即可。
步骤如下:
- 定义Runnable接口的实现类,并重写该接口的run方法,该run方法的方法体同样是该线程的线程执行体。
- 创建Runnable实现类的实例,并以此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
- 调用线程对象的start方法来启动线程。
class MyRunnable implements Runnable{
@Override
public void run(){
for(int i = 0; i < 20; i++){
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
}
class Demo{
public static void main(String[] args){
System.out.println("这里是main线程");
MyRunnable mr = new MyRunnable();
Thread t = new Thread(mr,"小强");
t.start();
for(int i = 0; i < 20; i++){
System.out.println("旺财:" + i);
}
}
}通过实现Runnable接口,使得该类有了多线程类的特征。run()方法是多线程程序的一个执行目标。所有的多线程
代码都在run方法里面。Thread类实际上也是实现了Runnable接口的类。
在启动的多线程的时候,需要先通过Thread类的构造方法Thread(Runnable target) 构造出对象,然后调用Thread
对象的start()方法来运行多线程代码。
实际上所有的多线程代码都是通过运行Thread的start()方法来运行的。因此,不管是继承Thread类还是实现
Runnable接口来实现多线程,最终还是通过Thread的对象的API来控制线程的,熟悉Thread类的API是进行多线程
编程的基础。
Runnable对象仅仅作为Thread对象的target,Runnable实现类里包含的run()方法仅作为线程执行体。
而实际的线程对象依然是Thread实例,只是该Thread线程负责执行其target的run()方法。
6.1.4 - Thread和Runnable的区别
如果一个类继承Thread,则不适合资源共享,但是如果实现了Runable接口的话,则很容易就实现了资源共享。
总结:
实现Runnable接口比继承Thread类所具有优势:
- 适合多个相同的程序代码的线程去共享同一个资源。
- 可以避免java中的单继承的局限性。
- 增加程序的健壮性,实现解耦操作,代码可以被多个线程共享,代码和线程独立。
- 线程池只能放入实现Runable或者Callable类线程,不能直接放入继承Thread的类。
扩充:在java中,每次程序运行至少启动两个线程,一个是main线程,一个是垃圾收集线程,因为每当使用java命令执行一个类的时候,实际上都会启动一个JVM,每一个JVM其实就是在操作系统中启动了一个进程。
6.1.5 - 匿名内部类方式实现线程的创建
使用线程的匿名内部类方式,可以方便的实现每个线程执行不同的线程任务操作。
使用匿名内部类的方式实现Runnable接口,重新Runnable接口中的run方法:
class Demo{
public static void main(String[] args){
Runnable r = new Runnable(){
public void run(){
for(int i = 0; i < 20; i++){
System.out.println("火锅:" + i);
}
}
};
new Thread(r).start();;
for(int i = 0; i < 20; i++){
System.out.println("串串:" + i);
}
}
}6.2 - 线程安全
6.2.1 - 线程安全
如果有多个线程在同时运行,而这些线程可能会同时运行这段代码。程序在每次运行结果和单线程运行的结果是一样的,而且其他的变量也和预期的是一样的,就是线程安全的。
/*
我们通过一个案例,演示线程的安全问题
电影院要卖票,我们模拟电影院的卖票过程,假设要播放的电影是“爱情公寓”,本次电影的座位共100个。
我们来模拟电影院的售票窗口,实现多个窗口同时卖“爱情公寓”这场电影票。
需要窗口,采用线程对象来模拟,需要票,Runnable接口子类来模拟。
*/
// 模拟票
class Ticket implements Runnable{
private int ticket = 100;
@Override
public void run(){
// 每个窗口卖票的操作
// 窗口 永远开启
while(true){
if(ticket > 0){
// 出票操作
// 使用sleep模拟出票事件
try{
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取当前线程对象名字
String name = Thread.currentThread().getName();
System.out.println(name + " 正在卖:" + ticket--);
}
}
}
}
class Demo{
public static void main(String[] args){
// 创建线程任务对象
Ticket ticket = new Ticket();
// 创建三个窗口对象
Thread t1 = new Thread(ticket, "窗口1");
Thread t2 = new Thread(ticket, "窗口2");
Thread t3 = new Thread(ticket, "窗口3");
// 同时卖票
t1.start();
t2.start();
t3.start();
}
}线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,而无写
操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,
否则的话就可能影响线程安全。
6.2.2 - 线程同步
当我们使用多个线程访问同一个资源的时候,且多个线程中对资源有写的操作,就容易出现线程安全问题。
要解决上述多线程并发访问一个资源的安全性问题,也就是解决重复票与不存在票问题,java中提供了同步机制(synchronized)来解决。
为了保证每个线程都能正常执行原子操作,java中引入了线程同步机制。
有三种方式完成同步操作:
- 同步代码块。
- 同步方法。
- 锁机制。
6.2.3 - 同步代码块
同步代码块:synchronized 关键字可以用于方法中的某个区块中,表示支队这个区块的资源实行互斥访问。
// 格式
synchronized(同步锁){
需要同步操作的代码
}同步锁:
对象的同步锁只是一个概念,可以想象为在对象上标记了一个锁。
-
锁对象,可以是任意类型。
-
多个线程对象,要使用同一把锁。
注意:在任何时候,最多允许一个线程拥有同步锁,谁拿到锁就进入代码块,其他的线程只能在外面等着。
class Ticket implements Runnable{
private int ticket = 100;
Object lock = new Object();
@Override
public void run(){
//每个窗口卖票的操作
while(true){
synchronized (lock){
if(ticket > 0){
// 出票
try{
Thread.sleep(50);
} catch (InterruptedException e){
e.printStackTrace();
}
// 获取当前线程对象的名字
String name = Thread.currentThread().getName();
System.out.println(name + "正在卖:" + ticket--);
}
}
}
}
}6.2.4 - 同步方法
同步方法:使用synchronized修饰的方法,就叫做同步方法。保证A线程执行该方法的时候,其他线程只能在方法外面等着。
// 格式
public synchronized void method(){
可能会产生线程安全问题的代码
}同步锁是谁?
对于非static方法,同步锁就是this。
对于static方法,我们使用当前方法所在的类的字节码对象(类名.class)
class Ticket implements Runnable{
private int ticket = 100;
@Override
public void run(){
// 每个窗口卖票的操作
// 窗口 永远开启
while(true){
sellTicket();
}
}
// 锁对象 是 谁调用这个方法 就是谁
// 隐含 锁对象 就是 this
public synchronized void sellTicket(){
if(ticket > 0){
// 出票
try{
Thread.sleep(100);
} catch(InterruptedException e){
e.printStackTrace();
}
// 获取当前线程对象的名字
String name = Thread.currentThread().getName();
System.out.println(name + "正在卖:" + ticket--);
}
}
}6.2.5 - Lock锁
java.util.concurrent.locks.Lock 机制提供了比 synchronized 代码块和 synchronized 方法更广泛的锁定操作,同步代码块/同步方法具有的功能Lock都有,除此之外更加强大,更体现面向对象。
Lock锁也被称为同步锁,加锁与释放锁方法化了,如下:
-
public void lock():加同步锁。
-
public void unlock():释放同步锁
class Ticket implements Runnable{
private int ticket = 100;
Lock lock = new ReentrantLock();
@Override
public void run(){
while(true){
lock.lock();
if(ticket > 0){
try{
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
String name = Thread.currentThread().getName();
System.out.println(name + "正在卖:" + ticket--);
}
lock.unlock();
}
}
}6.3 - 线程状态
6.3.1 - 线程状态概述
当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。在线程的生命周期中,
有几种状态呢?在API中 java.lang.Thread.State 这个枚举中给出了六种线程状态:
| 线程状态 | 导致状态发生条件 |
|---|---|
| NEW(新建) | 线程刚被创建,但是并未启动,还没调用start方法 |
| Runnable(可运行) | 线程可以在java虚拟机中运行的状态,可能正在运行自己的代码,也可能没有,这取决于操作系统处理器。 |
| Blocked(锁阻塞) | 当一个线程试图获取一个对象锁,而该对象被其他的线程持有,则该线程进入Blocked状态;当该线程持有锁时,该线程将变成Runnable状态。 |
| Waiting(无限等待) | 一个线程在等待另一个线程执行一个(唤醒)动作时,该线程进入Waiting状态。进入这个状态后时不能自动唤醒的,必须等待另一个线程调用notify或者notifyAll方法才能唤醒。 |
| TimedWaiting(计时等待) | 同waiting状态,有几个方法有超时参数,调用它们将进入Timed Waiting状态。这一状态将一直保持到超时期满或者接受到唤醒通知。带有超时参数的常用方法有Thread.sleep、Object.wait。 |
| Teminated(被终止) | 因为run方法正常退出而死亡,或者因为没有捕获的异常终止了run方法而死亡。 |
我们不需要去研究这几种状态的实现原理,我们只需知道在做线程操作中存在这样的状态。那我们怎么去理解这几
个状态呢,新建与被终止还是很容易理解的,我们就研究一下线程从Runnable(可运行)状态与非运行状态之间
的转换问题。
6.3.2 - Timed Waiting(计时等待)
Timed Waiting在API中的描述为:一个正在限时等待另一个线程执行一个动作的线程处于这一状态。
在我们写卖票的实例中,为了减少线程执行太快、现象不明显等问题,我们在run方法中添加了sleep语句,这样就强制当前正在执行的线程休眠,以“减慢线程”。
其实当我们调用了sleep方法之后,当前执行的线程就进入到“休眠状态”,其实就是所谓的Timed Waiting,那么我们通过一个案例加深对该状态的一个理解。
class MyThread extends Thread{
public void run(){
for(int i = 0; i < 100; i++){
if(i % 10 == 0){
System.out.println("----- " + i);
}
System.out.println(i);
try{
Thread.sleep(1000);
System.out.println("线程睡眠一秒");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class HelloWorld{
public static void main(String[] args){
new MyThread().start();
}
}通过案例可以发现,sleep方法的使用还是很简单的。需要记住下面几点:
- 进入TIMED_WAITING 状态的一种常见情形时调用的 sleep方法,单独的线程
- 为了让其他线程有机会执行,可以将Thread.sleep的调用放线程run()之内。这样才能保证该线程执行过程中会睡眠。
- sleep与锁无关,线程睡眠到期自动苏醒,并返回到Runnable(可运行)状态。
sleep中指定的事件时线程不会运行的最短时间。因此,sleep方法不能保证该线程睡眠到期后就开始立刻执行。
6.3.3 - BLOCKED(锁阻塞)
Blocked状态在API中的介绍为:一个正在阻塞等待一个监视器锁(锁对象)的线程处于这一状态。
线程A与线程B代码中使用同一锁,如果线程A获取到锁,线程A进入到Runnable状态,那么线程B就进入到Blocked锁阻塞状态。
这是由Runnable状态进入Blocked状态。除此Waiting以及Time Waiting状态也会在某种情况下进入阻塞状态。
6.3.4 - Waiting(无限等待)
Wating状态在API中介绍为:一个正在无限期等待另一个线程执行一个特别的(唤醒)动作的线程处于这一状态。
class HelloWorld{
public static Object obj = new Object();
public static void main(String[] args){
new Thread(new Runnable() {
@Override
public void run(){
while(true){
synchronized (obj){
try{
System.out.println(Thread.currentThread().getName() + " === 获取锁对象,调用wait方法,进入waiting状态,释放锁对象");
obj.wait(); // 无限等待
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " === 从waiting状态醒来,获取到锁对象,继续执行了");
}
}
}
},"等待线程").start();
new Thread(new Runnable() {
@Override
public void run() {
try {
System.out.println(Thread.currentThread().getName() + "----- 等待三秒钟");
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (obj){
System.out.println(Thread.currentThread().getName() +"‐‐‐‐‐ 获取到锁对 象,调用notify方法,释放锁对象");
obj.notify();
}
}
},"唤醒线程").start();
}
}通过上述案例我们会发现,一个调用了某个对象的 Object.wait 方法的线程会等待另一个线程调用此对象的
Object.notify()方法 或 Object.notifyAll()方法。
其实waiting状态并不是一个线程的操作,它体现的是多个线程间的通信,可以理解为多个线程之间的协作关系,
多个线程会争取锁,同时相互之间又存在协作关系。就好比在公司里你和你的同事们,你们可能存在晋升时的竞
争,但更多时候你们更多是一起合作以完成某些任务。
当多个线程协作时,比如A,B线程,如果A线程在Runnable(可运行)状态中调用了wait()方法那么A线程就进入
了Waiting(无限等待)状态,同时失去了同步锁。假如这个时候B线程获取到了同步锁,在运行状态中调用了
notify()方法,那么就会将无限等待的A线程唤醒。注意是唤醒,如果获取到锁对象,那么A线程唤醒后就进入
Runnable(可运行)状态;如果没有获取锁对象,那么就进入到Blocked(锁阻塞状态)。
6.3.5 - 补充知识点
我们在翻阅API的时候会发现Timed Waiting(计时等待) 与 Waiting(无限等待) 状态联系还是很紧密的,
比如Waiting(无限等待) 状态中wait方法是空参的,而timed waiting(计时等待) 中wait方法是带参的。
这种带参的方法,其实是一种倒计时操作,相当于我们生活中的小闹钟,我们设定好时间,到时通知,可是
如果提前得到(唤醒)通知,那么设定好时间在通知也就显得多此一举了,那么这种设计方案其实是一举两
得。
如果没有得到(唤醒)通知,那么线程就处于Timed Waiting状态,直到倒计时完毕自动醒来;如果在倒
计时期间得到(唤醒)通知,那么线程从Timed Waiting状态立刻唤醒。
7 - 线程池、Lambda表达式
7.1 - 等待唤醒机制
7.1.1 - 线程间通信
概念:多个线程在处理同一个资源,但是处理的动作却不相同。
比如:线程A是用来生成包子的,线程B是用来吃包子的,包子可以理解为同一资源,线程A与线程B处理的动作,一个是生产,一个是消费,那么线程A与线程B之间就存在线程通信的问题。
为什么要处理线程间通信:
多个线程并发执行时,在默认情况下CPU时随机切换线程的,当我们需要多个线程来共同完成同一个任务,并且我们希望它们有规律的执行,那么多线程之间需要一些协调通信,以此来帮我们达到多线程共同操作同一份数据。
如何保证线程间通信有效利用资源:
多个线程在处理同一个资源,并且任务不同时,需要线程通信来帮助解决线程之间对同一个变量的使用或者操作。就是多个线程在操作同一份数据时,避免对同一共享变量的争夺。也就是我们需要通过一定的手段使各个线程能够有效的利用资源。而这种手段即——等待唤醒机制。
7.1.2 - 等待唤醒机制
什么是等待唤醒机制
这是多个线程之间的一种协作机制。谈到线程我们经常想到的是线程之间的竞争(race),比如去争夺锁,但这并不是故事的全部,线程之间也会有协作机制。就好比在公司的同时,之间可能存在晋升的竞争关系,但是更多时间是在一起合作完成某些任务。
就是在一个线程进行了规定操作之后,就进入了等待状态;在有多个线程进行等待时,如果需要,可以使用notifyAll()来唤醒所有的等待线程。
wait / notify 就是线程间的一种协作机制。
等待唤醒中的方法
等待唤醒机制就是用于解决线程间通信的问题的,使用到的3个方法的含义如下:
- wait:线程不再活动,不再参与调用,进入 wait set 中,因此不会浪费CPU资源,也不会去竞争锁了,这时的线程状态即是WAITING。它还要等着别的线程执行一个特别的操作,也就是“通知(notify)”在这个对象上等待的线程从 wait set 中释放出来,重新进入调度队列(ready quece)中。
- notify:选取所通知对象的 wait set 中的一个线程释放;例如,餐馆有位置后,等候就餐最久的顾客最先入座。
- notifyAll:释放所通知对象上的 wait set 上的全部线程。
注意:
哪怕只通知了一个等待的线程,被通知线程也不能立即恢复执行,因为它当初中断的地方在同步块内,而此刻它已经不持有锁,所以它需要再次去尝试获取锁,成功后才能够在当初调用 wait 方法之后的地方恢复执行。
- 如果能够获取锁,线程就从 WAITING 状态 变成 RUNNABLE 状态。
- 否则,从 wait set 出来,又进入 entry set,线程就从 WAITING 状态又变成 BLOCKED 状态。
调用wait和notify方法需要注意的细节
- wait方法和notify方法必须要由一个锁对象调用。因为:对应的锁对象可以通过notify唤醒使用同一个锁对象调用的wait方法后的线程。
- wait方法与notify方法属于Object类的方法。因为:锁对象可以是任意对象,而任意对象的所属类都是继承了Ojbect类的。
- wait方法与notify方法必须要在同步代码块或者是同步函数中使用。因为:必须要通过锁对象调用这两个方法。
7.1.3 - 生产者与消费者问题
等待唤醒机制其实就是经典的“生产者”和“消费者”的问题。
就拿生产包子和消费包子来说等待唤醒机制如何有效的利用资源:
包子铺线程生产包子,吃货线程消费包子,当包子没有时,吃货线程等待,包子铺线程生产包子,并通知吃货线程,因为已经有包子了,那么包子铺线程进入等待状态。
接下来,吃货线程能否进一步执行取决于锁的获取情况,如果吃货获取到锁,就执行吃包子的动作,包子吃完,并通知包子铺线程,吃货线程进入等待。
包子铺线程能否进一步执行则取决于锁的获取情况。
// 包子资源
class BaoZi{
String pier;
String xianer;
boolean flag = false; // 包子资源状态 包子资源 是否存在
}
// 吃货线程类
class ChiHuo extends Thread{
private BaoZi bz;
public ChiHuo(String name, BaoZi bz){
super(name);
this.bz = bz;
}
@Override
public void run(){
while(true){
synchronized (bz){
if(bz.flag == false){
try{
bz.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("吃货正在吃 " + bz.pier + bz.xianer + "包子");
bz.flag = false;
bz.notify();
}
}
}
}
// 包子铺线程类
class BaoZiPu extends Thread{
private BaoZi bz;
public BaoZiPu(String name, BaoZi bz){
super(name);
this.bz = bz;
}
@Override
public void run(){
int count = 0;
// 造包子
while(true){
// 同步
synchronized (bz){
if(bz.flag == true) // 包子存在
try{
bz.wait();
} catch(InterruptedException e){
e.printStackTrace();
}
// 没有包子 造包子
System.out.println("包子铺开始做包子");
if(count % 2 == 0){
// 冰皮 五仁
bz.pier = "冰皮";
bz.xianer = "五仁";
} else {
bz.pier = "薄皮";
bz.xianer = "牛肉大葱";
}
count++;
bz.flag = true;
System.out.println("包子已经做好了:" + bz.pier + bz.xianer);
System.out.println("吃货可以吃了'");
// 唤醒等待线程
bz.notify();
}
}
}
}
class HelloWorld{
public static void main(String[] args){
// 等待唤醒案例
BaoZi bz = new BaoZi();
ChiHuo ch = new ChiHuo("吃货", bz);
BaoZiPu bzp = new BaoZiPu("包子铺", bz);
ch.start();
bzp.start();
}
}7.2 - 线程池
7.2.1 - 线程池思想概述
我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题:
如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低
系统的效率,因为频繁创建线程和销毁线程需要时间。
那么有没有一种办法使得线程可以复用,就是执行完一个任务,并不被销毁,而是可以继续执行其他的任务?
在Java中可以通过线程池来达到这样的效果。
7.2.2 - 线程池的概念。
线程池:其实就是一个容纳多个线程的容器,其中的线程可以反复使用,省去了频繁创建线程对象的操作。无需反复创建线程而消耗过多资源。
合理使用线程池能够带来三个好处:
- 降低资源消耗。减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。可以根据系统的承受能力,调整线程池中工作线程数量,防止因为消耗过多的内存,而把服务器累趴下。
7.2.3 - 线程池的使用
java里面线程池的顶级接口是 java.util.concurrent.Executor,但是严格意义上讲 Executor 并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是 java.util.concurrent.ExecutorService。
要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,很有可能配置的线程池不是较优的,因此在 java.util.concurrent.Executors 线程工厂里面提供了一些静态工厂,生成一些常用的线程池。官方建议使用 Executors 工程类来创建线程池对象。
Executor 类中有个创建线程池的方法:
-
public static ExecutorService newFixedThreadPool(int nThreads):返回线程池对象。(创建的是有界线程池,也就是池中的线程个数可以指定最大数量)
获取到了一个线程池ExecutorService对象,那么怎么使用呢?在这里定义了一个使用线程池对象的方法:
- public Future submit(Runnable task):获取线程池中的某一个线程对象,并执行。
Future接口:用来记录线程任务执行完毕后产生的结果。线程池创建与使用。
使用线程池中线程对象的步骤:
- 创建线程对象。
- 创建Runnable接口子类对象。(task)
- 提交Runnable接口子类对象。(take task)
- 关闭线程池。(一般不做)
class MyRunnable implements Runnable{
@Override
public void run(){
System.out.println("要一个教练");
try{
Thread.sleep(2000);
} catch(InterruptedException e){
e.printStackTrace();
}
System.out.println("教练来了:" + Thread.currentThread().getName());
System.out.println("教完游泳,教练回到了泳池");
}
}
class HelloWorld{
public static void main(String[] args){
// 创建线程池对象
ExecutorService service = Executors.newFixedThreadPool(2);
// 创建Runnable实例对象
MyRunnable r = new MyRunnable();
// 从线程池中获取线程对象,然后调用MyRunnable中的run
service.submit(r);
// 再获取一个线程对象,调用MyRunnable中的run
service.submit(r);
service.submit(r);
// 注意:submit方法调用结束后,程序并不终止,是因为线程池控制了线程的关闭。
// 将使用完的线程又归还到了线程池中
// 关闭线程池
//service.shutdown();
}
}7.3 - Lambda表达式
7.3.1 - 函数式编程思想概述
在数学中,函数就是有输入量、输出量的一套计算方案,也就是“拿什么东西做什么事情”。相对而言,面向对象过分强调“必须通过对象的形式来做事情”,而函数式思想则尽量忽略面向对象的复杂语法——强调做什么,而不是以什么形式做。
面向对象的思想:
做一件事情,找一个能解决这个事情的对象,调用对象的方法,完成事情。
函数式编程思想:
只要能获取到结果,谁去做的,怎么做的不重要,重视的是结果,不重视过程。
7.3.2 - 冗余的Runnable代码
传统写法:
当需要启动一个线程去完成任务时,通常会通过 java.lang.Runnable 接口来定义任务内容,并使用 java.lang.Thread 类来启动线程。代码如下:
public class Demo01Runnable {
public static void main(String[] args) {
// 匿名内部类
Runnable task = new Runnable() {
@Override
public void run() { // 覆盖重写抽象方法
System.out.println("多线程任务执行!");
}
};
new Thread(task).start(); // 启动线程
}
}本着“一切皆对象”的思想,这种做法是无可厚非的:首先创建一个Runnable接口的匿名内部类对象来指定任务内容,再将其交给一个线程来启动。
代码分析:
对于Runnable的匿名内部类用法,可以分析出几点内容:
- Thread 类需要 Runnable 接口作为参数,其中的抽象 run 方法是用来指定线程任务内容的核心。
- 为了指定 run 的方法体,不得不需要Runnable接口的实现类。
- 为了省去一个 RunnableImpl 实现类的麻烦,不得不使用匿名内部类。
- 为了覆盖重写抽象 run 方法,所以方法名称、方法参数、方法返回值不得不再写一遍,且不能写错。
- 而实际上,似乎只有方法体才是关键所在。
7.3.3 - 编程思想转换
做什么,而不是怎么做
我们真的希望创建一个匿名内部类对象吗?不。我们只是为了做这件事情而不得不创建一个对象。我们真正希望做
的事情是:将 run 方法体内的代码传递给 Thread 类知晓。
传递一段代码——这才是我们真正的目的。而创建对象只是受限于面向对象语法而不得不采取的一种手段方式。
那,有没有更加简单的办法?如果我们将关注点从“怎么做”回归到“做什么”的本质上,就会发现只要能够更好地达
到目的,过程与形式其实并不重要。
2014年3月Oracle所发布的Java 8(JDK 1.8)中,加入了Lambda表达式的重量级新特性,为我们打开了新世界的大门。
7.3.4 - 体验Lambda更优化写法
借助Java 8的全新语法,上述 Runnable 接口的匿名内部类写法可以通过更简单的Lambda表达式达到等效:
public class Demo02LambdaRunnable {
public static void main(String[] args) {
new Thread(() ‐> System.out.println("多线程任务执行!")).start(); // 启动线程
}
}这段代码和刚才的执行效果是完全一样的,可以在1.8或更高的编译级别下通过。从代码的语义中可以看出:我们
启动了一个线程,而线程任务的内容以一种更加简洁的形式被指定。
不再有“不得不创建接口对象”的束缚,不再有“抽象方法覆盖重写”的负担,就是这么简单!
7.3.5 - 回顾匿名内部类
Lambda是怎样击败面向对象的?在上例中,核心代码其实只是如下所示的内容:
() -> System.out.println("多线程任务执行!")使用实现类
要启动一个线程,需要创建一个 Thread 类的对象并调用 start 方法。而为了指定线程执行的内容,需要调用
Thread 类的构造方法:
- public Thread(Runnable target)
为了获取 Runnable 接口的实现对象,可以为该接口定义一个实现类 RunnableImpl :
public class RunnableImpl implements Runnable {
@Override
public void run() {
System.out.println("多线程任务执行!");
}
}然后创建该实现类的对象Thread类的构造参数:
public class Demo03ThreadInitParam {
public static void main(String[] args) {
Runnable task = new RunnableImpl();
new Thread(task).start();
}
}使用匿名内部类
这个RunableImpl类只是为了实现Runnable接口而存在的,而且仅被使用了唯一一次,所以使用匿名内部类的语法即可省去该类的单独定义,即匿名内部类:
public class Demo04ThreadNameless {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("多线程任务执行!");
}
}).start();
}
}匿名内部类的好处与弊端
一方面,匿名内部类可以帮我们省去实现类的定义;另一方面,匿名内部类的语法——确实太复杂了。
语义分析
仔细分析该代码中的语义,Runnable接口只有一个run方法的定义:
- public abstract void run();
即制定了一种做事情的方案(其实就是一个函数):
- 无参数:不需要任何条件即可执行该方案。
- 无返回值:该饭干不产生任何结果。
- 代码块:该方案的具体执行步骤。
同样的语义体现在 Lambda语法中,要更加简单:
() -> System.out.println("多线程任务执行!")- 前面一堆小括号即run方法的参数,代表不需要任何条件。
- 中间的一个箭头代表将前面的参数传递给后面的代码。
- 后面的输出语句即业务逻辑代码。
7.3.6 - Lambda标准格式
Lambda升渠面向对象的条条框框,格式由3个部分组成:
- 一些参数
- 一个箭头
- 一段代码
Lambda表达式的标准格式为:
(参数类型 参数名称) -> {代码语句}格式说明:
- 小括号内的语法与传统方法参数列表一致:无参数则留空;多个参数则用逗号分隔。
- -> 是新引入的语法格式,代表指向动作。
- 大括号内的语法与传统方法体要求基本一致。
7.3.7 - 练习
题目
给一个厨子 Cook 接口,内含唯一的抽象方法 makeFood,且无参数,无返回值。如下:
public interface Cook{
void makeFood();
}在下面的代码中,请使用Lambda标准格式调用 invokeCook 方法,打印输出”吃饭“字样。
public class Demo05InvokeCook {
public static void main(String[] args) {
// TODO 请在此使用Lambda【标准格式】调用invokeCook方法
}
private static void invokeCook(Cook cook) {
cook.makeFood();
}
}解答
public static void main(String[] args) {
invokeCook(() ‐> {
System.out.println("吃饭啦!");
});
}7.3.8 - Lambda的参数和返回值
需求:
使用数组存储多个Person对香港
对数组中的Person对象使用Arrays的sort方法通过年龄进行排序
下面举例演示 java.util.Comparator
-
public abstract int compare(T o1, T o2);
当需要一个对象数组进行排序时,Arrays.sort 方法需要一个 Comparator 接口实例来指定排序的规则。假设有一个Person类,含有String name 和 int age 两个成员变量:
public class Person{
private String name;
private int age;
// 省略构造器、toString方法和Getter、Setter
}传统写法
如果使用传统的代码对Person[]数组进行排序,写法如下:
import java.util.Arrays;
import java.util.Comparator;
public class Demo{
public static void main(String[] args){
Person[] array = {
new Person("古力娜扎", 19),
new Person("迪丽热巴", 18),
new Person("马儿扎哈", 20)
};
// 匿名内部类
Comparator comp = new Comparator(){
@Override
public int compare(Person o1, Person o2){
return o1.getAge() - o2.getAge();
}
}
Arrays.sort(array, comp); // 第二个参数为排序规则,即Comparator接口实例
for(Person person : array){
System.out.println(person);
}
}
} 这种做法在面对对象的思想中,似乎是理所当然的。其中 Comparator 接口实例代表了,按照年龄从小到大的规则排序。
代码分析:
下面,我们来搞清楚上述代码真正要做什么事情。
- 为了排序, Arrays.sort 方法需要排序规则,即 Comparator 接口的实例,抽象方法 compare 是关键;
- 为了指定 compare 的方法体,不得不需要 Comparator 接口的实现类;
- 为了省去定义一个 ComparatorImpl 实现类的麻烦,不得不使用匿名内部类;
- 必须覆盖重写抽象 compare 方法,所以方法名称、方法参数、方法返回值不得不再写一遍,且不能写错;
Lambda写法
import java.utli.Arrays;
public class Demo{
public static void main(String[] args){
Person[] array = {
new Person("古力娜扎", 19),
new Person("迪丽热巴", 18),
new Person("马儿扎哈", 20)
};
Arrays.sort(array, (Person a, Person b)->{
return a.getAge() - b.getAge();
});
for(Person person : array){
System.out.println(person);
}
}
}7.3.9 - 练习
题目
给定一个计算器Calcutor接口,内含抽象方法 calc 可以将两个int 数字相加得到和值:
public interface Calculator{
int calc(int a, intb);
}在下面的代码中,请使用Lambda的标准格式调用invokeCalc方法,完成120和130的相加计算。
public class Demo{
public static void main(String[] args){
}
private static void invokeCalc(int a, int b, Calculator calculator){
int result = calcuator.calc(a,b);
System.out.println("结果是:" + result);
}
}解答
public class Demo{
public static void main(String[] args){
invokeCalc(120, 130, (int a, int b) ->{
return a + b;
});
}
}7.3.10 - Lambda省略格式
可推导即可省略
Lambda强调的是 做什么 而不是 怎么做,所以凡是可以根据上下文推到得知的信息,都可以省略。例如上例还可以使用Lambda的省略写法。
public static void main(String[] args){
invokeCalc(120, 130, (int a, int b) -> a + b);
}省略规则
在Lambda标准格式的基础上,使用省略写法的规则为:
- 小括号内参数的类型可以省略
- 如果小括号内有且仅有一个参数,则小括号可以省略。
- 如果大括号内由且仅有一个语句,则无论是否有返回值,都可以省略大括号、return关键字以及语句分号,
7.3.11 - Lambda的使用前提
Lambda的语法非常简洁,完全没有面向对象的束缚,但是使用时有几个问题需要特别注意:
- 使用Lambda必须有接口,且要求接口中有且仅有一个抽象方法。无论是JDD内置的Runnable、Comparator接口还是自定义的接口,只有当接口中的抽象方法存在且唯一时,才可以使用Lambda。
- 使用Lambda必须具有上下推断。也就是方法的参数或局部变量必须为Lambda对应的接口类型,才能使用Lambda作为该接口的实例。
有且仅有一个抽象方法的接口,被称为“函数式接口”
8 - File类、递归
8.1 - File类
8.1.1 - 概述
java.io.File 类是文件和目录路径名的抽象表示,主要用于文件和目录的创建、查找和删除等操作。
8.1.2 - 构造方法
- public File(String pathname) :通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例。
- public File(String parent, String child) :从父路径名字符串和子路径名字符串创建新的 File实例。
- public File(File parent, String child) :从父抽象路径名和子路径名字符串创建新的 File实例。
// 文件路径名
String pathname = "D:\\aaa.txt";
File file1 = new File(pathname);
// 文件路径名
String pathname2 = "D:\\aaa\\bbb.txt";
File file2 = new File(pathname2);
// 通过父路径和子路径字符串
Stinrg parent = "d:\\aaa"
String child = "bbb.txt";
File file3 = new File(parent, child);
// 通过父级File对象和子路径字符串
File parentDir = new File("d:\\aaa");
String child = "bbb.txt";
File file4 = new File(patentDir, child);
- 一个File对象代表硬盘中实际存在的一个文件或目录
- 无论该路径下是否存在文件或者目录,都不影响File对象的创建
8.1.3 - 常用方法
获取功能的方法:
- public String getAbsolutePath() :返回此File的绝对路径名字符串。
- public String getPath() :将此File转换为路径名字符串。
- public String getName() :返回由此File表示的文件或目录的名称。
- public long length() :返回由此File表示的文件的长度。
public class FileGet{
public static void main(String[] args) {
File f = new File("d:/aaa/bbb.java");
System.out.println("文件绝对路径:"+f.getAbsolutePath());
System.out.println("文件构造路径:"+f.getPath());
System.out.println("文件名称:"+f.getName());
System.out.println("文件长度:"+f.length()+"字节");
File f2 = new File("d:/aaa");
System.out.println("目录绝对路径:"+f2.getAbsolutePath());
System.out.println("目录构造路径:"+f2.getPath());
System.out.println("目录名称:"+f2.getName());
System.out.println("目录长度:"+f2.length());
}
}
// length(),表示文件的长度。但是File对象表示目录,则返回值未指定.绝对路径和相对路径
- 绝对路径:从盘符开始的路径,这是一个完整的路径。
- 相对路径:相对于项目目录的路径,这是一个便捷的路径,开发中经常使用。
public class FilePath {
public static void main(String[] args) {
// D盘下的bbb.java文件
File f = new File("D:\\bbb.java");
System.out.println(f.getAbsolutePath());
// 项目下的bbb.java文件
File f2 = new File("bbb.java");
System.out.println(f2.getAbsolutePath());
}
}判断功能的方法
- public boolean exists() :此File表示的文件或目录是否实际存在。
- public boolean isDirectory() :此File表示的是否为目录。
- public boolean isFile() :此File表示的是否为文件。
public class FileIs {
public static void main(String[] args) {
File f = new File("d:\\aaa\\bbb.java");
File f2 = new File("d:\\aaa");
// 判断是否存在
System.out.println("d:\\aaa\\bbb.java 是否存在:"+f.exists());
System.out.println("d:\\aaa 是否存在:"+f2.exists());
// 判断是文件还是目录
System.out.println("d:\\aaa 文件?:"+f2.isFile());
System.out.println("d:\\aaa 目录?:"+f2.isDirectory());
}
}创建删除功能的方法
- public boolean createNewFile() :当且仅当具有该名称的文件尚不存在时,创建一个新的空文件。
- public boolean delete() :删除由此File表示的文件或目录。
- public boolean mkdir() :创建由此File表示的目录。
- public boolean mkdirs() :创建由此File表示的目录,包括任何必需但不存在的父目录。
public class FileCreateDelete {
public static void main(String[] args) throws IOException {
// 文件的创建
File f = new File("aaa.txt");
System.out.println("是否存在:"+f.exists()); // false
System.out.println("是否创建:"+f.createNewFile()); // true
System.out.println("是否存在:"+f.exists()); // true
// 目录的创建
File f2= new File("newDir");
System.out.println("是否存在:"+f2.exists());// false
System.out.println("是否创建:"+f2.mkdir()); // true
System.out.println("是否存在:"+f2.exists());// true
// 创建多级目录
File f3= new File("newDira\\newDirb");
System.out.println(f3.mkdir()); // false
File f4= new File("newDira\\newDirb");
System.out.println(f4.mkdirs()); // true
// 文件的删除
System.out.println(f.delete()); // true
// 目录的删除
System.out.println(f2.delete()); // true
System.out.println(f4.delete()); // false
}
}8.1.4 - 目录的遍历
- public String[] list() :返回一个String数组,表示该File目录中的所有子文件或目录。
- public File[] listFiles() :返回一个File数组,表示该File目录中的所有的子文件或目录。
public class FileFor {
public static void main(String[] args) {
File dir = new File("d:\\java_code");
//获取当前目录下的文件以及文件夹的名称。
String[] names = dir.list();
for(String name : names){
System.out.println(name);
}
//获取当前目录下的文件以及文件夹对象,只要拿到了文件对象,那么就可以获取更多信息
File[] files = dir.listFiles();
for (File file : files) {
System.out.println(file);
}
}
}
// 调用listFiles方法的File对象,表示的必须是实际存在的目录,否则返回null,无法进行遍历。8.2 - 递归
8.2.1 - 概述
递归:指在当前方法内调用自己的这种现象。
递归的分类:
- 递归分两种,直接递归和间接递归。
- 直接递归称为方法自己调用字节。
- 简介递归可以A方法调用B方法,B方法调用C方法,C方法调用A方法。
注意事项:
- 递归一定要有条件限定,保证递归能够停止下来,否则会发生栈内存溢出。
- 在递归中虽然有限定条件,但是递归次数不能太多,否则也会发生栈内存溢出。
- 构造方法,禁止递归。
public class Demo01DiGui {
public static void main(String[] args) {
// a();
b(1);
}
/* *
* 3.构造方法,禁止递归
* 编译报错:构造方法是创建对象使用的,不能让对象一直创建下去
*/
public Demo01DiGui() {
//Demo01DiGui();
}
/* *
* 2.在递归中虽然有限定条件,但是递归次数不能太多。否则也会发生栈内存溢出。
* 4993
* Exception in thread "main" java.lang.StackOverflowError
*/
private static void b(int i) {
System.out.println(i);
//添加一个递归结束的条件,i==5000的时候结束
if(i==5000){
return;//结束方法
}
b(++i);
}
/* *
* 1.递归一定要有条件限定,保证递归能够停止下来,否则会发生栈内存溢出。
* Exception in thread "main"
* java.lang.StackOverflowError
*/
private static void a() {
System.out.println("a方法");
a();
}
}8.2.2 - 递归累加求和。
计算1~n的和
分析:num的累和 = num + (num - 1)的累和,所以可以把累和的操作定义成一个方法,递归调用。
public class DiGuiDemo {
public static void main(String[] args) {
//计算1~num的和,使用递归完成
int num = 5;
// 调用求和的方法
int sum = getSum(num);
// 输出结果
System.out.println(sum);
}
/*
通过递归算法实现.
参数列表:int
返回值类型: int
*/
public static int getSum(int num) {
/*
num为1时,方法返回1,
相当于是方法的出口,num总有是1的情况
*/
if(num == 1){
return 1;
}
/*
num不为1时,方法返回 num +(num‐1)的累和
递归调用getSum方法
*/
return num + getSum(num‐1);
}
}8.2.3 - 递归求阶乘
阶乘:所有小于等于该数的正整数的积。
n的阶乘:n! = n * (n - 1) * ... * 3 * 2 * 1分析:这与累和类似,只不过换成了乘法运算。
推理得出:n! = n * (n - 1)!public class DiGuiDemo {
//计算n的阶乘,使用递归完成
public static void main(String[] args) {
int n = 3;
// 调用求阶乘的方法
int value = getValue(n);
// 输出结果
System.out.println("阶乘为:"+ value);
}
/*
通过递归算法实现.
参数列表:int
返回值类型: int
*/
public static int getValue(int n) {
// 1的阶乘为1
if (n == 1) {
return 1;
}
/*
n不为1时,方法返回 n! = n*(n‐1)!
递归调用getValue方法
*/
return n * getValue(n ‐ 1);
}
}
8.2.4 - 递归打印多级目录
分析:多级目录的打印,就是当目录的嵌套。遍历之前,无从知道到底有多少级目录,所以我们还是要使用递归实现。
public class DiGuiDemo2 {
public static void main(String[] args) {
// 创建File对象
File dir = new File("D:\\aaa");
// 调用打印目录方法
printDir(dir);
}
public static void printDir(File dir) {
// 获取子文件和目录
File[] files = dir.listFiles();
// 循环打印
/*
判断:
当是文件时,打印绝对路径.
当是目录时,继续调用打印目录的方法,形成递归调用.
*/
for (File file : files) {
// 判断
if (file.isFile()) {
// 是文件,输出文件绝对路径
System.out.println("文件名:"+ file.getAbsolutePath());
} else {
// 是目录,输出目录绝对路径
System.out.println("目录:"+file.getAbsolutePath());
// 继续遍历,调用printDir,形成递归
printDir(file);
}
}
}
8.3 - 综合案例
8.3.1 - 文件搜索
搜索 D:\aaa 目录中的 .java 文件。
分析:
- 目录搜索,无法判断有多少级目录,所以使用递归,遍历所有目录。
- 遍历目录是,获取的子文件,通过文件名称,判断是否符合条件。
public class Demo{
public static void main(String[] args){
// 创建file对象
File dir = new File("D:\\aaa");
// 调用打印目录方法
printDir(dir);
}
public staic void printDir(File dir){
// 获取子文件和目录
File[] files = dir.listFiles();
// 循环打印
for(File file : files){
if(file.isFile()){
// 是文件,判断文件名并输出文件绝对路径
if(file.getName().endWith(".java")){
System.out.println("文件名:" + file.getAbsoultPath());
}
else {
// 是目录,继续遍历,形成递归
printDir(file);
}
}
}
}8.3.2 - 文件过滤器优化
java.io.FileFilter 是一个接口,是File的过滤器。该接口的对象可以传递给File类的 listFiles(FileFileter)作为参数,接口中只有一个方法。
boolean accept(File pathname):测试pathname是否应该包含在当前File目录中,符合则返回true。
分析:
- 接口作为参数,需要传递子类对象,重写其中方法。我们选择匿名内部类方式,比较简单。
- accept方法,参数为File,表示当前File下所有的子文件和子目录。保留住则返回true,过滤掉则返回false。保留规则:1、要么是java文件;2、要么是目录,用于继续遍历。
- 通过过滤器的作用,listFiles(FileFilter)返回的数组元素中,子文件对象都是符合条件的,可以直接打印。
public class Demo{
public static void main(String[] args){
File dir = new File("D:\\aaa");
printDir2(dir);
}
public static void printDir2(File dir){
// 匿名内部类方式,创建过滤器子类对象
File[] files = dir.listFiles(new FileFilter(){
@Override
public boolean accept(File pathname){
return pathname.getName().endsWith(".java") || pathname.isDirectory();
}
});
// 循环打印
for(File file : files){
if(file.isFile()){
System.out.println("文件名:" + file.getAbsolutePath());
} else {
printDir2(file);
}
}
}
}8.3.3 - Lambda优化
分析:FileFilter 是只有一个方法的接口,因此可以使用lambda表达式简写。
public static void printDir3(File dir){
// lambda的改写
File[] files = dir.listFiles(f -> return f.getName().endsWith(".java") || f.isDirectory());
// 循环打印
for(File file : files){
if(file.isFile()){
System.out.println("文件名:" + file.getAbsoultePath());
} else {
printDir(file);
}
}
}
9 - 字节流、字符流
9.1 - IO概述
9.1.1 - 什么是IO
生活中,你肯定经历过这样的场景。当你编辑一个文本文件,忘记了 ctrl+s ,可能文件就白白编辑了。当你电脑
上插入一个U盘,可以把一个视频,拷贝到你的电脑硬盘里。那么数据都是在哪些设备上的呢?键盘、内存、硬
盘、外接设备等等。
我们把这种数据的传输,可以看做是一种数据的流动,按照流动的方向,以内存为基准,分为 输入input 和 输出
output ,即流向内存是输入流,流出内存的输出流。
Java中I/O操作主要是指使用 java.io 包下的内容,进行输入、输出操作。输入也叫做读取数据,输出也叫做作写
出数据。
9.1.2 - IO的分类
根据数据的流向分为:输入流和输出流。
- 输入流:把数据从其他设备上读取到内存中的流。
- 输出流:把数据从内存中写出到其他设备上的流。
格局数据的类型分为:字节流和字符流。
- 字节流:以字节为单位,读写数据的流。
- 字符流:以字符为单位,读写数据的流。
9.1.3 - 顶级父类们
| 输入流 | 输出流 | |
| 字节流 | 字节输入流 InputStream |
字节输出流 OutputStream |
| 字符流 | 字符输入流 Reader |
字符输出流 Writer |
9.2 - 字节流
9.2.1 - 一切皆为字节
一切文件数据在存储时,都是以二进制数字的形式保存,都是一个个的字节,那么传输时一样如此。所以,字节流可以传输任意文件数据。在操作流的时候,我们要时刻明确,无论使用什么样的流对象,底层传输始终为二进制数据。
9.2.2 - 字节输出流【OutputStream】
java.io.OutputStream 抽象类时表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
- public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
- public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
- public void write(byte[] b) :将 b.length字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len) :从指定的字节数组写入 len字节,从偏移量 off 开始输出到此输出流。
- public abstract void write(int b) :将指定的字节输出流。
close方法,当完成流的操作时,必须调用此方法,释放系统资源。
9.2.3 - FileOutputStream类
OutputStream 有很多子类,我们从最简单的一个子类开始。
java.io.FileOutputStream类 是文件输出流,用于将数据写出到文件。
构造方法
- public FileOutputStream(File file):创建文件输出流以写入由指定的File对象表示的文件。
- public FileOutputStream(String name):创建文件输出流以指定的名称写入文件。
当创建一个流对象时,必须传入一个文件路径。该路径下,如果没有这个文件,会创建该文件。如果有这个文件,会清空这个文件的数据。
public class Demo throws IOExecpetion{
public static void main(String[] args){
// 使用File对象创建流对象
File file = new File("a.txt");
FileOutputStream for = new FileOutputStream(file);
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("b.txt");
}
}写出字节数据:写出字节
write(int b) 方法,每次可以写出一个字节数据。
public class Demo{
public static void main(String[] args){
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 写出数据
fos.write(97); // 写出第一个字节
fos.write(98); // 写出第二个字节
fos.write(99); // 写出第三个字节
// 关闭资源
fos.close();
}
}
- 虽然参数为int类型四个字节,但是只会保留一个字节的信息写出。
- 流操作完毕后,必须释放系统资源,调用close方法,千万记得。
写出字节数据:写出字节数组
write(byte[] b),每次可以写出数组中的数据。
public class Demo{
public static void main(String[] args){
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 字符串转换为字节数组
byte[] b = "奶思".getBytes();
// 写出字节数组数据
fos.write(b);
// 关闭资源
fos.close();
}
}写出字节数据:写出指定长度字节数组
write(byte[] b, int off, int len),每次写出从off索引开始,len个字节。
public class Demo{
public static void main(String[] args){
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 写出从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b,2,2);
// 关闭资源
fos.close();
}
}数据追加续写
经过以上的演示,每次程序运行,创建输出流对象,都会清空目标文件中的数据。如何保留目标文件中数据,还能
继续添加新数据呢?
- public FileOutputStream(File file, boolean append):创建文件输出流以写入指定的File对象表示的文件。
- public FileOutputStream(String name, boolean append):创建文件输出流写入以指定的名称写入文件。
这两个构造方法,参数中都需要传入一个boolean类型的值, true 表示追加数据, false 表示清空原有数据。
这样创建的输出流对象,就可以指定是否追加续写了。
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt",true);
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 写出从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b);
// 关闭资源
fos.close();
}
}写出换行
Windows系统里,换行符号是\r\n。
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 定义字节数组
byte[] words = {97,98,99,100,101};
// 遍历数组
for (int i = 0; i < words.length; i++) {
// 写出一个字节
fos.write(words[i]);
// 写出一个换行, 换行符号转成数组写出
fos.write("\r\n".getBytes());
}
// 关闭资源
fos.close();
}
}9.2.4 - 字节输入流【InputStream】
java.io.InputStream 抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
- public void close():关闭此输入流并释放与此流相关联的任何系统资源。
- public abstract int read():从输入流读取数据的下一个字节。
- public int read(byte[] b):从输入流中读取一些字节数,并将它们存储到字节数组 b 中。
9.2.5 - FileInputStream类
java.io.FileInputStream类 是文件输入流,从文件中读取字节。
构造方法
- FileInputStream(File file):通过打开与实际文件的连接来创建一个FileInputStream,该文件由文件系统中的File对象file命名。
- FileInputStream(String name):通过打开与实际文件的连接来创建一个FileInputStream,该文件由文件系统中的路径名name命名。
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有该文件,会抛出FileNotFoundException。
public class FileInputStreamConstructor throws IOException{
public static void main(String[] args) {
// 使用File对象创建流对象
File file = new File("a.txt");
FileInputStream fos = new FileInputStream(file);
// 使用文件名称创建流对象
FileInputStream fos = new FileInputStream("b.txt");
}
}读取字节数据:读取字节
read方法,每次可以读取一个字节的数据,提升为int类型,读取到文件末尾,返回-1。
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("read.txt");
// 读取数据,返回一个字节
int read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
// 读取到末尾,返回‐1
read = fis.read();
System.out.println( read);
// 关闭资源
fis.close();
}
}循环改进读取方式:
public class Demo{
public static void mian(String[] args) throws IOException{
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("read.txt");
// 定义变量,保存数据
int b;
// 循环读取
while(b = fis.read() != -1){
System.out.println((char)b);
}
// 关闭资源
fis.close();
}
}读取字节数据:使用字节数组读取
read(byte[] b),每次读取b的长度个字节到数组中,返回读取到的有效字节个数,读取到末尾时,返回-1。
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象.
FileInputStream fis = new FileInputStream("read.txt"); // 文件中为abcde
// 定义变量,作为有效个数
int len ;
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 循环读取
while (( len= fis.read(b))!=‐1) {
// 每次读取后,把数组变成字符串打印
System.out.println(new String(b));
}
// 关闭资源
fis.close();
}
}错误数据 d ,是由于最后一次读取时,只读取一个字节 e ,数组中,上次读取的数据没有被完全替换,所以要通过 len ,获取有效的字节。
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象.
FileInputStream fis = new FileInputStream("read.txt"); // 文件中为abcde
// 定义变量,作为有效个数
int len ;
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 循环读取
while (( len= fis.read(b))!=‐1) {
// 每次读取后,把数组的有效字节部分,变成字符串打印
System.out.println(new String(b,0,len));// len 每次读取的有效字节个数
}
// 关闭资源
fis.close();
}
}使用数组读取,每次读取多个字节,减少了系统间的IO操作次数,从而提高了读写的效率,建议开发中使
用。
9.2.6 - 字节流练习:图片复制
复制原理:
从已有文件中读取字节,将该字节写出到另一个文件中。
案例实现:
public class Copy {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 指定数据源
FileInputStream fis = new FileInputStream("D:\\test.jpg");
// 1.2 指定目的地
FileOutputStream fos = new FileOutputStream("test_copy.jpg");
// 2.读写数据
// 2.1 定义数组
byte[] b = new byte[1024];
// 2.2 定义长度
int len;
// 2.3 循环读取
while ((len = fis.read(b))!=‐1) {
// 2.4 写出数据
fos.write(b, 0 , len);
}
// 3.关闭资源
fos.close();
fis.close();
}
}9.3 - 字符流
当使用字节流读取文本文件时,可能会有一个小问题。就是遇到中文字符时,可能不会显示完整的字符,那是因为
一个中文字符可能占用多个字节存储。所以Java提供一些字符流类,以字符为单位读写数据,专门用于处理文本文
件。
9.3.1 - 字符输入流【Reader】
java.io.Reader 抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
- public void close():关闭此流释放与此流相关联的任何系统资源。
- public int read():从输入流读取一个字符
- public int read(char[] cbuf):从输入流读取一些字符,并将它们存储到字符数组cbuf中。
9.3.2 - FileReader类
java.io.Reader类是读取字符文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
字符编码:字节与字符的对应规则。Windows系统的中文编码默认时GBK编码表。
字节缓冲区:一个字节数组,用来临时存储字节数据。
构造方法
- FileReader(File file):创建一个新的FileReader,给定要读取的File对象。
- FileReader(String fileName):创建一个新的FileReader,给定要读取的文件的名称
当你创建一个流对象时,必须传入一个文件路径,类似于FileInputStream。
public class FileReaderConstructor throws IOException{
public static void main(String[] args) {
// 使用File对象创建流对象
File file = new File("a.txt");
FileReader fr = new FileReader(file);
// 使用文件名称创建流对象
FileReader fr = new FileReader("b.txt");
}
}读取字符数据:读取字符
read 方法,每次可以读取一个字符的数据,提升为int类型,读取到文件末尾,返回-1,循环读取。
public class FRRead {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileReader fr = new FileReader("read.txt");
// 定义变量,保存数据
int b ;
// 循环读取
while ((b = fr.read())!=‐1) {
System.out.println((char)b);
}
// 关闭资源
fr.close();
}
}读取字符数据:使用字符数组读取
read(char[] cbuf),每次读取b长度个字符到数组中,返回读取到的有效字符个数,读取到末尾时,返回-1。
public class Demo{
public static void main(String[] args){
// 使用文件名称创建对象
FileReader fr = new FileReader("read.txt");
// 定义变量,保存有效字符个数
int len;
// 给定字符数组,作为装字符数据的容器
char[] cbuf = new char[2];
// 循环读取
while(len = (fr.read(buf) != -1)){
System.out.println(new String(cbuf));
}
// 关闭资源
fr.close();
}
}
// 改进
public class Demo{
public static void main(String[] args){
// 使用文件名称创建对象
FileReader fr = new FileReader("read.txt");
// 定义变量,保存有效字符个数
int len;
// 给定字符数组,作为装字符数据的容器
char[] cbuf = new char[2];
// 循环读取
while(len = (fr.read(buf) != -1)){
System.out.println(new String(cbuf, 0, len));
}
// 关闭资源
fr.close();
}
}9.3.3 - 字符输出流【Writer】
java.io.writer 抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地,它定义了字节输出流的基本共性功能方法。
- void writer(int c):写入单个字符。
- void writer(char[] cbuf):写入字符数组。
- abstract void write(char[] cbuf, int off, int len):写入字符数组的某一部分,off数组的开始索引,len写的字符个数。
- void writer(String str):写入字符串。
- void writer(String str, int off, int len):写入字符串中的某一部分,off字符串的开始索引,len写的字符个数。
- void flush():刷新该流的缓冲。
- void close():关闭此流,但要先刷新它。
9.3.4 - FileWriter类
java.io.FileWriter类是写出字符到文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
构造方法
- FileWriter(File file):创建一个新的FileWriter,给定要读取的File对象。
- FileWriter(String fileName):创建一个新的FileWriter,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径,类似于FileOutputStream。
基本写出类型:写出字符:
write(int b)方法,每次可以写出一个字符数据。
public class Demo{
public static void main(String[] args){
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据
fw.write(97); // 写出第一个字符
fw.write('b'); // 写出第二个字符
fw.write('C'); // 写出第三个字符
fw.write(30000); // 写出第四个字符
}
}
- 虽然参数为int类型四个字节,但是只会保留一个字符的信息写出。
- 未调用close方法,数据只是保存到了缓冲区,并未写到文件中。
基本写出类型:关闭和刷新
因为内置缓冲区的原因,如果不关闭输出流,无法写字符到文件中,但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要flush方法了。
- flush:刷新缓冲区,流对象可以继续使用。
- close:先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了。
写出其他数据:写出字符数组
write(char[] cbuf) 和 write(char[] cbuf, int off, int len) ,每次可以写出字符数组中的数据,用法类似FileOutputStream。
public class Demo{
public static void main(String[] args){
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 字符串转换为字节数组
char[] chars = "程序员".toCharArray();
// 写出字符数组
fw.write(chars);
// 写出从索引2开始,2个字节。索引2是'程',两个字节,也就是'程序'。
fw.write(b,0,2); // 程序
// 关闭资源
fos.close();
}
}写出其他数据:写出字符串
write(String str) 和 write(String str, int off, int len) ,每次可以写出字符串中的数据,更为方便.
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 字符串
String msg = "程序员";
// 写出字符数组
fw.write(msg);
fw.write(msg,0,2); // 程序
// 关闭资源
fos.close();
}
}写出其他数据:续写和换行
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象,可以续写数据
FileWriter fw = new FileWriter("fw.txt",true);
// 写出字符串
fw.write("程序");
// 写出换行
fw.write("\r\n");
// 写出字符串
fw.write("员");
// 关闭资源
fw.close();
}
}字符流,只能操作文本文件,不能操作图片、视频等非文本文件。
当我们单纯的读或者写文本文件时,使用字符流,其他情况使用字节流。
9.4 - IO异常的处理
9.4.1 - JDK7 前处理
之前的入门练习,我们一直把异常抛出,而实际开发中并不能这样处理,建议使用 try...catch...finally 代码
块,处理异常部分。
public class HandleException1 {
public static void main(String[] args) {
// 声明变量
FileWriter fw = null;
try {
//创建流对象
fw = new FileWriter("fw.txt");
// 写出
fw.write("程序员");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fw != null) {
fw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}9.4.2 - JDK7 处理
还可以使用JDK7优化后的 try-with-resource 语句,该语句确保了每个资源在语句结束时关闭。所谓的资源
(resource)是指在程序完成后,必须关闭的对象。
// 格式
try(创建流语句对象,如果多一个,使用";"隔开){
// 读写数据
} catch(IOException e){
e.printStackTrace();
}
public class HandleException2 {
public static void main(String[] args) {
// 创建流对象
try ( FileWriter fw = new FileWriter("fw.txt"); ) {
// 写出数据
fw.write("程序员");
} catch (IOException e) {
e.printStackTrace();
}
}
}9.4.3 - JDK9 改进
JDK9中 try-with-resource 的改进,对于引入对象的方式,支持的更加简洁。被引入的对象,同样可以自动关闭,
无需手动close.
// 格式
// 被final修饰的对象
final Resource resource1 = new Resource("resource1");
// 普通对象
Resource resource2 = new Resource("resource2");
// 引入方式:直接引入
try (resource1; resource2) {
// 使用对象
}
public class Demo{
public static void mian(String[] args){
// 创建流对象
final FileReader fr = nw FileReader("in.txt");
FileWriter fw = new FileWriter("out.txt");
// 引入到try中
try(fr; fw){
// 定义变量
int b;
// 读取数据
while((b = fr.read()) != -1){
fw.write(b);
}
} catch (IOExecption e){
e.printStackTrace();
}
}
}9.5 - 属性集
9.5.1 - 概述
java.util.Properties 继承于 Hashtable ,来表示一个持久的属性集。它使用键值结构存储数据,每个键及其对应值都是一个字符串。该类也被许多java类使用,比如获取系统属性时,System.getProperties方法就是返回一个Properties对象。
9.5.2 - Properties类
构造方法
- public Properties():创建一个空的属性集。
基本的存储方法
- public Object setProperty(String key, String value):保存一对属性。
- public String getProperty(String key):使用此属性类表中指定的键搜索属性值。
- public Set
stringPropertyNames(): 所有键的名称的集合。
public class Demo{
public static void main(String[] args){
// 创建属性集对象
Properties properties = new Properties();
// 添加键值对元素
properties.setProperty("filename", "a.txt");
properties.setProperty("length", "209385038");
properties.setProperty("location","D:\\a.txt");
// 打印属性集对象
System.out.println(properties);
// 通过键,获取属性值
System.out.println(properties.getProperty("filename"));
System.out.println(properties.getProperty("length"));
System.out.println(properties.getProperty("location"));
// 遍历属性集,获取所有键的集合
Set strings = properties.stringPropertyNames();
// 打印键值对
for(String key : strings){
System.out.println(key+" ‐‐ "+properties.getProperty(key));
}
}
} 与流相关的方法
- public void load(InputStream inSteram):从字节输入流中读取键值对。
参数中使用了字节输入流,通过流对象,可以关联到某文件上,这样就能够加载文本中的数据了。
//文本内容
filename=a.txt
length=209385038
location=D:\a.txt
public class ProDemo2 {
public static void main(String[] args) throws FileNotFoundException {
// 创建属性集对象
Properties pro = new Properties();
// 加载文本中信息到属性集
pro.load(new FileInputStream("read.txt"));
// 遍历集合并打印
Set strings = pro.stringPropertyNames();
for (String key : strings ) {
System.out.println(key+" ‐‐ "+pro.getProperty(key));
}
}
}
// 文本中的数据,必须是键值对形式,可以使用空格、等号、冒号等符号分隔。
10 - 缓冲流、转换流、序列化流
10.1 - 缓冲流
10.1.1 - 概述
缓冲流,也叫做高效流,是对四个基本的FileXxx流的增强,所以也是4个流,按照数据类型分类:
- 字节缓冲流:BufferedInputStream,BufferedOutStream
- 字符缓冲流:BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
10.1.2 - 字节缓冲流
构造方法
- public BufferedInputStream(InputStream in):创建一个新的缓冲输入流。
- public BufferedOutputStream(OutputStream out):创建一个新的缓冲输出流
// 创建字节缓冲输入流
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("bis.txt"));
// 创建字节缓冲输出流
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("bos.txt"));效率测试
查询API,缓冲流读写方法与基本的流是一致的,我们通过复制大文件(375MB),测试它的效率。
// 基本流
public class Demo{
public static void main(String[] args){
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try(
FileInputStream fis = new FileInputStream("jdk9.exe");
FileOutputStream fos = new FileOutputStream("copy.exe");
){
// 读写数据
int b;
while((b = fis.read()) != -1){
fos.write(b);
}
} catch (IOExecption e){
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("普通流复制时间:" + (end - start) + "毫秒");
}
}// 缓冲流
public class Demo2{
public static void main(String[] args){
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try(
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jkd9.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe"));
){
// 读写数据
int b;
while((b = bis.read()) != -1){
bos.write(b);
}
} catch (IOException){
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流复制时间:" + (end - start) + "毫秒");
}
}// 缓冲流优化:使用数组
public class Demo2{
public static void main(String[] args){
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try(
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jkd9.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe"));
){
// 读写数据
int len;
byte[] bytes = new byte[8*1024];
while((len = bis.read(bytes)) != -1){
bos.write(bytes, 0, len);
}
} catch (IOException){
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流复制时间:" + (end - start) + "毫秒");
}
}10.1.3 - 字符缓冲流
构造方法
- public BufferedReader(Reader in):创建一个新的缓冲输入流
- public BufferedWriter(Writer out):创建一个新的缓冲输出流
// 创建字符缓冲输入流
BufferedReader br = new BufferedReader(new FileReader("br.txt"));
// 创建字符缓冲输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("bw.txt"));特有方法
字符缓冲流的基本方法与普通字符流调用方式一致。
- BufferedReader:public String readLine():读取一行文字
- BufferedWriter:public void newLine():写一行行分隔符,由系统属性定义符号。
public class readLineDemo{
public static void main(String[] args){
// 创建流对象
BufferedReader br = new BufferedReader(new FileReader("in.txt"));
// 定义字符串,保存读取的一行文字
String line = null;
// 循环读取,读到最后返回null
while((line = br.readLine()) != null){
System.out.print(line);
System.out.println("-----");
}
// 释放资源
br.close();
}
}public class newLineDemo{
public static void main(String[] args){
// 创建流对象
BufferedWriter bw = new BufferedWriter(new FileWriter("out.txt"));
// 写出数据
bw.write("程序");
// 写出换行
bw.newLine();
bw.write("员");
bw.newLine();
// 释放资源
bw.close();
}
}10.1.4 - 练习:文本排序
将文本信息恢复顺序。
3.侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉
以咨之,然后施行,必得裨补阙漏,有所广益。
8.愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其
咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。
4.将军向宠,性行淑均,晓畅军事,试用之于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,
必能使行阵和睦,优劣得所。
2.宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不
宜偏私,使内外异法也。
1.先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外
者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以
塞忠谏之路也。
9.今当远离,临表涕零,不知所言。
6.臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣
以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
7.先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐付托不效,以伤先帝之明,故五月渡泸,深入不毛。
今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛
下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
5.亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息
痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。public class BufferedTest{
public static void main(String[] args) throws IOException{
// 创建map集合,保存文本数据,键为序号,值为文字
HashMap lineMap = new HashMap<>();
// 创建流对象
BufferedReader br = new BufferedReader(new FileReader("in.txt"));
BufferedWriter bw = new BufferedWriter(new FileWriter("out.txt"));
// 读取数据
String line = null;
while((line = br,readLine()) != null){
// 解析文本
String[] split = line.split("\\.");
// 保存到集合
lineMap.put(split[0], split[1]);
}
// 释放资源
br.close();
// 遍历map集合
for(int i = 1; i <= lineMap.size){
String key = String.valueOf(i);
// 获取map中文本
String value = lineMap.get(key);
// 写出拼接文本
bw.write(key + "." + value);
// 写出换行
bw.newLine();
}
bw.close();
}
} 10.2 - 转换流
10.2.1 - 字符编码和字符集
字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制
数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。
将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。
比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
-
字符编码 Character Encoding : 就是一套自然语言的字符与二进制数之间的对应规则。
字符集
- 字符集 Charset :也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符
号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符
集有ASCII字符集、GBK字符集、Unicode字符集等。
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
- ASCII字符集 :
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁
字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显
示字符(英文大小写字符、阿拉伯数字和西文符号)。
基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)
表示一个字符,共256字符,方便支持欧洲常用字符。
- ISO-8859-1字符集:
拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
ISO-5559-1使用单字节编码,兼容ASCII编码。
- GBxxx字符集:
GB就是国标的意思,是为了显示中文而设计的一套字符集。
GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,
就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文
的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这
就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了
21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节
组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
- Unicode字符集 :
Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国
码。
它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-
32。最为常用的UTF-8编码。
UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用
中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,
我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
10.2.2 - 编码引出的问题
在IDEA中,使用 FileReader 读取项目中的文本文件。由于IDEA的设置,都是默认的 UTF-8 编码,所以没有任何
问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。
public class ReaderDemo {
public static void main(String[] args) throws IOException {
FileReader fileReader = new FileReader("E:\\File_GBK.txt");
int read;
while ((read = fileReader.read()) != ‐1) {
System.out.print((char)read);
}
fileReader.close();
}
}10.2.3 - InputStreamReader类
转换流 java.io.InputStreamReader ,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定
的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
- InputStreamReader(InputStream in):创建一个使用默认字符集的字符流。
- InputStreamWriter(InputStream, String charsetName):创建一个指定字符集的字符流。
InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");指定编码读取
public class Demo{
public static void main(String[] args){
// 定义文件路径,文件为gbk编码
String Filename = "E:\\file_gbk.txt";
// 创建流对象,默认UTF8编码
InputStreamReader isr = new InputStreamReader(new FileInputStream(FileName));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream(FileName), "GBK");
// 定义变量,保存字符
int read;
// 使用默认编码字符读取,乱码
while((read = isr.read()) != -1){
System.out.print((char)read);
}
isr.close();
while((read = isr2.read()) != -1){
System.out.print((char)read);
}
isr2.close();
}
}10.2.4 - OutputStreamWriter类
转换流java.io.OutputStreamWriter,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
- OutputStreamWriter(OutputStream in) : 创建一个使用默认字符集的字符流。
- OutputStreamWriter(OutputStream in, String charsetName) : 创建一个指定字符集的字符流。
OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("out.txt"));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("out.txt") , "GBK");指定编码写出
public class OutputDemo {
public static void main(String[] args) throws IOException {
// 定义文件路径
String FileName = "E:\\out.txt";
// 创建流对象,默认UTF8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(FileName));
// 写出数据
osw.write("你好"); // 保存为6个字节
osw.close();
// 定义文件路径
String FileName2 = "E:\\out2.txt";
// 创建流对象,指定GBK编码
OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream(FileName2),"GBK");
// 写出数据
osw2.write("你好");// 保存为4个字节
osw2.close();
}
}10.2.5 - 练习:转换文件编码
将GBK编码的文本文件,转换为UTF-8编码的文本文件。
public class Demo{
public static void main(Stringp[] args){
// 定义文件路径
String srcFile = “file_gbk.txt”;
String destFile = "file_utf8.txt";
// 创建流对象
InputStreamReader isr = new InputStreamRreader(new FileInputStream(srcFile), "GBK");
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(destFile));
// 读写数据
char[] cbuf = new char[1024];
int len;
while((len = isr.read()) != -1){
osw.write(cbuf, 0, len);
}
osw.close();
isr.close();
}
}10.3 - 序列化
10.3.1 - 概述
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该 对象的数据 、 对象的
类型 和 对象中存储的属性 等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。 对象的数据 、 对象的类型 和 对象中
存储的数据 信息,都可以用来在内存中创建对象。
10.3.2 - ObjectOutputStream类
java.io.ObjectOutputStream类,将java对象的原始数据类型写出到文件,实现对象的持久存储。
构造方法
- public ObjectOutputStream(OutputStream out):创建一个指定的OutputStream的ObjectOutputStream。
FileOutputStream fileOut = new FileOutputStream("employee.txt");
ObjectOutputStream out = new ObjectOutputStream(fileOut);序列化操作
1. 一个对象想要序列化,必须满足两个条件。
- 该类必须实现 java.io.Serializable 接口, Serializable 是一个标记接口,不实现此接口的类将不会使任
何状态序列化或反序列化,会抛出 NotSerializableException 。 - 该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用
transient 关键字修饰。
public class Employee implements java.io.Serializable {
public String name;
public String address;
public transient int age; // transient瞬态修饰成员,不会被序列化
public void addressCheck() {
System.out.println("Address check : " + name + " ‐‐ " + address);
}
}2. 写出对象方法
-
public final void writeObject(Object obj):将指定的对象写出。
public class SerializeDemo{
public static void main(String [] args) {
Employee e = new Employee();
e.name = "zhangsan";
e.address = "beiqinglu";
e.age = 20;
try {
// 创建序列化流对象
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("employee.txt"));
// 写出对象
out.writeObject(e);
// 释放资源
out.close();
fileOut.close();
System.out.println("Serialized data is saved"); // 姓名,地址被序列化,年龄没有被序列化。
} catch(IOException i) {
i.printStackTrace();
}
}
}10.3.3 - ObjectInputStream类
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
构造方法
- public ObjectInputStream(InputStream in):创建一个指定的InputStream的ObjectInputStream。
反序列化操作1
如果能找到一个对象的class文件,我们可以进行反序列化操作,调用 ObjectInputStream 读取对象的方法。
- public final Object readObject():读取一个对象。
public class Demo{
public static void main(String[] args){
Employee e = null;
try{
// 创建反序列化流
FileInputStream fileIn = new FileInputStream("employee.txt");
ObjectInputStream in = new ObjectInputStream(fileIn);
// 读取一个对象
e = (Employee)in.readObject();
// 释放资源
in.close();
fileIn().close();
} catch (IOException i){
// 捕获其他异常
i.printStackTrace();
return;
} catch (ClassNotFoundException c){
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
// 无异常,直接打印输出
System.out.println("Name: " + e.name); // zhangsan
System.out.println("Address: " + e.address); // beiqinglu
System.out.println("age: " + e.age); // 0
}
}对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个ClassNotFoundException异常。
反序列化操作2
另外,当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了更改,那么反序列化的操作也会失败,抛出一个InvalidClassException异常。发生这个异常的原因如下:
- 该类的序列版本号从流中读取的类描述符的版本号不匹配。
- 该类包含未知数据类型。
- 该类没有可访问的无参构造参数。
Serializable 接口给需要序列化的类,提供了一个序列版本号。 serialVersionUID 该版本号的目的在于验证序
列化的对象和对应类是否版本匹配。
public class Employee implements java.io.Serializable {
// 加入序列版本号
private static final long serialVersionUID = 1L;
public String name;
public String address;
// 添加新的属性 ,重新编译, 可以反序列化,该属性赋为默认值.
public int eid;
public void addressCheck() {
System.out.println("Address check : " + name + " ‐‐ " + address);
}
}10.3.4 - 练习:序列化集合
-
将有多个自定义对象的集合序列化操作,保存到 list.txt 文件中。
-
反序列化 list.txt ,并遍历集合,打印对象信息。
public class SerTest {
public static void main(String[] args) throws Exception {
// 创建 学生对象
Student student = new Student("老王", "laow");
Student student2 = new Student("老张", "laoz");
Student student3 = new Student("老李", "laol");
ArrayList arrayList = new ArrayList<>();
arrayList.add(student);
arrayList.add(student2);
arrayList.add(student3);
// 序列化操作
serializ(arrayList);
// 反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("list.txt"));
// 读取对象,强转为ArrayList类型
ArrayList list = (ArrayList)ois.readObject();
for (int i = 0; i < list.size(); i++ ){
Student s = list.get(i);
System.out.println(s.getName()+"‐‐"+ s.getPwd());
}
}
private static void serializ(ArrayList arrayList) throws Exception {
// 创建 序列化流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("list.txt"));
// 写出对象
oos.writeObject(arrayList);
// 释放资源
oos.close();
}
} 10.4 - 打印流
10.4.1 - 概述
平时我们在控制台打印输出,是调用 print 方法和 println 方法完成的,这两个方法都来自于
java.io.PrintStream 类,该类能够方便地打印各种数据类型的值,是一种便捷的输出方式。
10.4.2 - PrintStream类
构造方法
- public PrintStream(String fileName):使用指定的文件名创建一个新的打印流。
PrintStraem ps = new PrintStream("ps.txt");改变打印流向
System.out 就是 PrintStream 类型的,只不过它的流向是系统规定的,打印在控制台上。不过,既然是流对象,
我们就可以玩一个"小把戏",改变它的流向。
public class PrintDemo {
public static void main(String[] args) throws IOException {
// 调用系统的打印流,控制台直接输出97
System.out.println(97);
// 创建打印流,指定文件的名称
PrintStream ps = new PrintStream("ps.txt");
// 设置系统的打印流流向,输出到ps.txt
System.setOut(ps);
// 调用系统的打印流,ps.txt中输出97
System.out.println(97);
}
}
11 - 网络编程
11.1 - 网络编程入门
11.1.1 - 软件结构
- C/S结构 :全称为Client/Server结构,是指客户端和服务器结构。常见程序有QQ、迅雷等软件。
- B/S结构 :全称为Browser/Server结构,是指浏览器和服务器结构。常见浏览器有谷歌、火狐等。
两种架构各有优势,但是无论哪种架构,都离不开网络的支持。网络编程,就是在一定的协议下,实现两台计算机
的通信的程序。
11.1.2 - 网络通信协议
- 网络通信协议:通信协议是对计算机必须遵守的规则,只有遵守这些规则,计算机之间才能进行通信。这就
好比在道路中行驶的汽车一定要遵守交通规则一样,协议中对数据的传输格式、传输速率、传输步骤等做了
统一规定,通信双方必须同时遵守,最终完成数据交换。 - TCP/IP协议: 传输控制协议/因特网互联协议( Transmission Control Protocol/Internet Protocol),是
Internet最基本、最广泛的协议。它定义了计算机如何连入因特网,以及数据如何在它们之间传输的标准。它
的内部包含一系列的用于处理数据通信的协议,并采用了4层的分层模型,每一层都呼叫它的下一层所提供的
协议来完成自己的需求。
11.1.3 - 协议分类
通信的协议还是比较复杂的, java.net 包中包含的类和接口,它们提供低层次的通信细节。我们可以直接使用这
些类和接口,来专注于网络程序开发,而不用考虑通信的细节。
java.net 包中提供了两种常见的网络协议的支持:
- TCP:传输控制协议 (Transmission Control Protocol)。TCP协议是面向连接的通信协议,即传输数据之前,
在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。
三次握手:TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可
靠。
第一次握手,客户端向服务器端发出连接请求,等待服务器确认。
第二次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求。
第三次握手,客户端再次向服务器端发送确认信息,确认连接。
完成三次握手,连接建立后,客户端和服务器就可以开始进行数据传输了。由于这种面向连接的特性,TCP协议可
以保证传输数据的安全,所以应用十分广泛,例如下载文件、浏览网页等。
-
UDP:用户数据报协议(User Datagram Protocol)。UDP协议是一个面向无连接的协议。传输数据时,不需
要建立连接,不管对方端服务是否启动,直接将数据、数据源和目的地都封装在数据包中,直接发送。每个
数据包的大小限制在64k以内。它是不可靠协议,因为无连接,所以传输速度快,但是容易丢失数据。日常应
用中,例如视频会议、QQ聊天等。
11.1.4 - 网络编程三要素
协议
- 协议:计算机网络通信必须遵守的规则。
IP地址
- IP地址:指互联网协议地址(Internet Protocol Address),俗称IP。IP地址用来给一个网络中的计算机设
备做唯一的编号。假如我们把“个人电脑”比作“一台电话”的话,那么“IP地址”就相当于“电话号码”。
IP地址分类
- Pv4:是一个32位的二进制数,通常被分为4个字节,表示成 a.b.c.d 的形式,例如 192.168.65.100 。其
中a、b、c、d都是0~255之间的十进制整数,那么最多可以表示42亿个。 - IPv6:由于互联网的蓬勃发展,IP地址的需求量愈来愈大,但是网络地址资源有限,使得IP的分配越发紧张。
有资料显示,全球IPv4地址在2011年2月分配完毕
为了扩大地址空间,拟通过IPv6重新定义地址空间,采用128位地址长度,每16个字节一组,分成8组十六进
制数,表示成 ABCD:EF01:2345:6789:ABCD:EF01:2345:6789 ,号称可以为全世界的每一粒沙子编上一个网
址,这样就解决了网络地址资源数量不够的问题
常用命令
// 查看本机地址,在控制台输入
ipconfig
// 检测网络是否连通,在控制台输入
ping 空格 IP地址
ping 220.181.57.216特殊的IP地址
- 本机IP地址: 127.0.0.1 、 localhost 。
端口号
网络的通信,本质上是两个进程(应用程序)的通信。每台计算机都有很多的进程,那么在网络通信时,如何区分
这些进程呢?
如果说IP地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的进程(应用程序)了。
- 端口号:用两个字节表示的整数,它的取值范围是0~65535。其中,0~1023之间的端口号用于一些知名的网
络服务和应用,普通的应用程序需要使用1024以上的端口号。如果端口号被另外一个服务或应用所占用,会
导致当前程序启动失败。
利用 协议 + IP地址 + 端口号 三元组合,就可以标识网络中的进程了,那么进程间的通信就可以利用这个标识与其
它进程进行交互。
11.2 - TCP通信程序
11.2.1 - 概述
TCP通信能实现两台计算机之间的数据交互,通信的两端,要严格区分为客户端(Client)与服务端(Server)。
两端通信时步骤:
- 服务端程序,需要实现启动,等待客户端的连接。
- 客户端主动连接服务器端,连接成功才能通信。服务端不可以主动连接客户端。
在java中,提供了两个类用于实现TCP通信程序
- 客户端: java.net.Socket 类表示。创建 Socket 对象,向服务端发出连接请求,服务端响应请求,两者建
立连接开始通信。 - 服务端: java.net.ServerSocket 类表示。创建 ServerSocket 对象,相当于开启一个服务,并等待客户端
的连接。
11.2.2 - Socket类
Socket 类:该类实现客户端套接字,套接字指的是两台设备之间通讯的端点。
构造方法
- public Socket(String host, int port) :创建套接字对象并将其连接到指定主机上的指定端口号。如果指
定的host是null ,则相当于指定地址为回送地址
回送地址(127.x.x.x) 是本机回送地址(Loopback Address),主要用于网络软件测试以及本地机进程间通信,无论什么程序,一旦使用回送地址发送数据,立即返回,不进行任何网络传输。
Socket client = new Socket("127.0.0.1", 6666);成员方法
- public InputStream getInputStream() : 返回此套接字的输入流。
如果此Scoket具有相关联的通道,则生成的InputStream 的所有操作也关联该通道。
关闭生成的InputStream也将关闭相关的Socket。
- public OutputStream getOutputStream() : 返回此套接字的输出流。
如果此Scoket具有相关联的通道,则生成的OutputStream 的所有操作也关联该通道。
关闭生成的OutputStream也将关闭相关的Socket。
- public void close() :关闭此套接字。
一旦一个socket被关闭,它不可再使用。
关闭此socket也将关闭相关的InputStream和OutputStream 。
- public void shutdownOutput() : 禁用此套接字的输出流。
任何先前写出的数据将被发送,随后终止输出流
11.2.3 - ServerSocket类
ServerSocket 类:这个类实现了服务器套接字,该对象等待通过网络的请求。
构造方法
- public ServerSocket(int port) :使用该构造方法在创建ServerSocket对象时,就可以将其绑定到一个指
定的端口号上,参数port就是端口号。
ServerSocket server = new ServerSocket(6666);成员方法
- public Socket accept() :侦听并接受连接,返回一个新的Socket对象,用于和客户端实现通信。该方法
会一直阻塞直到建立连接。
11.2.4 - 简单的TCP网络程序
- 【服务端】启动,创建ServerSocket对象,等待连接。
- 【客户端】启动,创建Socket对象,请求连接。
- 【服务端】接收连接,调用accept方法,并返回一个Socket对象。
- 【客户端】Socket对象,获取OutputStream,向服务端写出数据。
- 【服务端】Scoket对象,获取InputStream,读取客户端发送的数据。
- 【服务端】Socket对象,获取OutputStream,向客户端回写数据。
- 【客户端】Scoket对象,获取InputStream,解析回写数据。
- 【客户端】释放资源,断开连接。
客户端向服务器发送数据
// 服务端实现
public class ServerTcp{
public static void main(String[] args) throws IOException{
System.out.println("服务端启动,等待连接...");
// 1 创建ServerSocket对象,绑定端口,开始等待连接
ServerSocket ss = new ServerSocket(6666);
// 2 接受连接 accept 方法,返回 socket 对象
Socket server = server.getInputStream();
// 3 通过 socket 获取输入流
InputStream is = server.getInputStream();
// 4 一次性读取数据
// 4.1 创建字节数组
byte[] b = new byte[1024];
// 4.2 数据读取到字节数组中
int len = is.read(b);
// 4.3 解析数组,打印字符串信息
String msg = new String(b, 0, len);
// 5 关闭资源
is.close();
server.close();
}
}
// 客户端实现
public class ClientTcp{
public static void main(String[] args) throws Execption{
System.out.println("客户端,发送数据");
// 1 创建 Socket(ip, port)
Socket client = new Socket("localhose", 6666);
// 2 获取流对象,输出流
OutputStream os = client.getOutputStream();
// 3 写出数据
os.write("tcp".getBytes());
// 4 关闭资源
os.close();
client.close();
}
}服务端向客户端发送数据
// 服务端
public class ServerTcp{
public static void main(String[] args) throws IOException{
// 1 创建 ServerSocket 对象,绑定端口,开始等待连接
ServerSocket ss = new ServerSocket(6666);
// 2 接受连接 accept 方法,返回socket对象
Socket server = ss.accept();
// 3 通过socket,获取输入流
InputStream is = server.getInputStream();
// 4 一次性读取数据
// 4.1 创建字节数组
byte[] b = new byte[1024];
// 4.2 数据读取到字节数组中
int len = is.read(b);
// 4.3 解析数组,打印字符串信息
String msg = new String(b, 0, len);
System.out.println(msg);
// ==== 回写数据 ====
// 5 通过socket 获取输出流
OutputStream out = server.getOutputStream();
// 6 回写数据
out.write("我很好,谢谢".getBytes());
// 7 关闭资源
out.close();
is.close();
server.close();
}
}
// 客户端
public class ClinetTcp{
public static void main(String[] args) throws Exception{
// 1 创建 Socket(ip, port),确定连接到哪里
Socket client = new Socket("localhost", 6666);
// 2 通过Socket,获取输出流对象
OutputStream os = client.getOutputStream();
// 3 写出数据
os.write("tcp".getBytes());
// === 解析回写 ===
// 4 通过 Socket获取,输入流对象
InputStream in = client.getInputStream();
// 5 读取数据
byte[] b = new byte[100];
int len = in.read(b);
System.out.println(new String(b, 0, len));
// 6 关闭资源
in.close();
os.close();
client.close();
}
}
11.3 - 综合案例
11.3.1 - 文件上传案例
- 【客户端】输入流,从硬盘读取文件数据到程序中。
- 【客户端】输出流,写出文件数据到服务端。
- 【服务端】输入流,读取文件数据到服务端程序。
- 【服务端】输出流,写出文件数据到服务器硬盘中。
会产生的问题:
- 文件名称写死的问题:服务端,保存文件地名称如果写死,那么最终导致服务器硬盘,只会保留一个文件,建议使用系统时间优化,保证文件名唯一。
- 循环接受的问题:服务端,只保存一个文件就关闭了,之后的用户无法再上传,这是不符合实际的,使用循环改进,可以不断地接受不同用户地文件。
- 效率问题:在接收大文件时,可能耗费几秒钟的时间,此时不能接收其他用户上传,所以,使用多线程优化。
public class FileUpload_Server{
public static void mian(String[] args){
System.out.println("服务器 启动....");
// 1 创建服务端ServerSocket
ServerSocket serverSocket = new ServerSocket(6666);
// 2 循环接受,建立连接
while(true){
Socket accept = serverSocket.accpet();
// 3 socket对象交给子线程处理,进行读写操作
// Runnable接口中,只有一个run方法,使用lambda表达式简化格式
new Thread(()->{
try(
// 3.1 获取输入流对象
BufferedInputStream bis = new BufferedInputSteram(accept.getInputSteam());
// 3.2 创建输出流对象,保存到本地
FileOutputStream fis = new FileOutputStream(System.currentTimeMillis() + ".jpg");
BufferedOutputStream bos = new BufferedOutputStream(fis);
){
// 3.3 读写数据
byte[] b = new byte[1024 * 8];
int len;
while((len = bis.read(b)) != -1){
bos.write(b, 0, len);
}
// 4 关闭资源
bos.close();
bis.close();
accept.close();
System.out.println("文件已经上传保存");
} catch(IOException e){
e.printStackTrace();
}
}).start();
}
}
}
// 客户端
public class FileUPload_Client {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 创建输入流,读取本地文件
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("test.jpg"));
// 1.2 创建输出流,写到服务端
Socket socket = new Socket("localhost", 6666);
BufferedOutputStream bos = new BufferedOutputStream(socket.getOutputStream());
//2.写出数据.
byte[] b = new byte[1024 * 8 ];
int len ;
while (( len = bis.read(b))!=‐1) {
bos.write(b, 0, len);
bos.flush();
}
System.out.println("文件发送完毕");
// 3.释放资源
bos.close();
socket.close();
bis.close();
System.out.println("文件上传完毕 ");
}
}
信息回写
- 【服务端】获取输出流,回写数据。
- 【客户端】获取输入流,解析回写数据。
// 服务端
public class FileUpload_Server {
public static void main(String[] args) throws IOException {
System.out.println("服务器 启动..... ");
// 1. 创建服务端ServerSocket
ServerSocket serverSocket = new ServerSocket(6666);
// 2. 循环接收,建立连接
while (true) {
Socket accept = serverSocket.accept();
/*
3. socket对象交给子线程处理,进行读写操作
Runnable接口中,只有一个run方法,使用lambda表达式简化格式
*/
new Thread(() ‐> {
try (
//3.1 获取输入流对象
BufferedInputStream bis = new BufferedInputStream(accept.getInputStream());
//3.2 创建输出流对象, 保存到本地 .
FileOutputStream fis = new FileOutputStream(System.currentTimeMillis() +
".jpg");
BufferedOutputStream bos = new BufferedOutputStream(fis);
) {
// 3.3 读写数据
byte[] b = new byte[1024 * 8];
int len;
while ((len = bis.read(b)) != ‐1) {
bos.write(b, 0, len);
}
// 4.=======信息回写===========================
System.out.println("back ........");
OutputStream out = accept.getOutputStream();
out.write("上传成功".getBytes());
out.close();
//================================
//5. 关闭 资源
bos.close();
bis.close();
accept.close();
System.out.println("文件上传已保存");
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
}
// 客户端
public class FileUpload_Client {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 创建输入流,读取本地文件
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("test.jpg"));
// 1.2 创建输出流,写到服务端
Socket socket = new Socket("localhost", 6666);
BufferedOutputStream bos = new BufferedOutputStream(socket.getOutputStream());
//2.写出数据.
byte[] b = new byte[1024 * 8 ];
int len ;
while (( len = bis.read(b))!=‐1) {
bos.write(b, 0, len);
}
// 关闭输出流,通知服务端,写出数据完毕
socket.shutdownOutput();
System.out.println("文件发送完毕");
// 3. =====解析回写============
InputStream in = socket.getInputStream();
byte[] back = new byte[20];
in.read(back);
System.out.println(new String(back));
in.close();
// ============================
// 4.释放资源
socket.close();
bis.close();
}
}
12 - 函数式接口
12.1 - 函数式接口
12.1.1 - 概念
函数式接口在Java中是指:有且仅有一个抽象方法的接口。
函数式接口,即适用于函数式编程场景的接口。而Java中的函数式编程体现就是Lambda,所以函数式接口就是可
以适用于Lambda使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的Lambda才能顺利地进行推导。
"语法糖”是指使用更加方便,但是原理不变的代码语法。例如在遍历集合时使用的for-each语法,其实
底层的实现原理仍然是迭代器,这便是“语法糖”。从应用层面来讲,Java中的Lambda可以被当做是匿名内部
类的“语法糖”,但是二者在原理上是不同的。
12.1.2 - 格式
只要确保接口中有且仅有一个抽象方法即可:
修饰符 interface 接口名称 {
public abstract 返回值类型 方法名称(可选参数信息);
// 其他非抽象方法内容
}由于接口当中抽象方法的 public abstract 是可以省略的,所以定义一个函数式接口非常简单。
public interface MyFunctionalInterface {
void myMethod();
}12.1.3 - @FunctionalInterface注解
与 @Override 注解的作用类似,Java 8中专门为函数式接口引入了一个新的注解: @FunctionalInterface 。该注
解可用于一个接口的定义上:
@FunctionalInterface
public interface MyFunctionalInterface {
void myMethod();
}一旦使用该注解来定义接口,编译器将会强制检查该接口是否确实有且仅有一个抽象方法,否则将会报错。需要注
意的是,即使不使用该注解,只要满足函数式接口的定义,这仍然是一个函数式接口,使用起来都一样。
12.1.4 - 自定义函数式接口
对于刚刚定义好的 MyFunctionalInterface 函数式接口,典型使用场景就是作为方法的参数:
@FunctionalInterface
interface MyFunctionalInterface {
void myMethod();
}
class HelloWorld{
// 使用自定义的函数式接口作为方法参数
private static void doSomething(MyFunctionalInterface inter) {
inter.myMethod(); // 调用自定义的函数式接口方法
}
public static void main(String[] args) {
// 调用使用函数式接口的方法
doSomething(()->{System.out.println("Lambda执行啦!");});
}
}12.2 - 函数式编程
12.2.1 - Lambda的延迟执行
有些场景的代码执行后,结果不一定会被使用,从而造成性能浪费。而Lambda表达式是延迟执行的,这正好可以
作为解决方案,提升性能
性能浪费的日志案例
注:日志可以帮助我们快速的定位问题,记录程序运行过程中的情况,以便项目的监控和优化。
一种典型的场景就是对参数进行有条件使用,例如对日志消息进行拼接后,在满足条件的情况下进行打印输出:
public class Demo01Logger {
private static void log(int level, String msg) {
if (level == 1) {
System.out.println(msg);
}
}
public static void main(String[] args) {
String msgA = "Hello";
String msgB = "World";
String msgC = "Java";
log(1, msgA + msgB + msgC);
}
}这段代码存在问题:无论级别是否满足要求,作为 log 方法的第二个参数,三个字符串一定会首先被拼接并传入方
法内,然后才会进行级别判断。如果级别不符合要求,那么字符串的拼接操作就白做了,存在性能浪费。
备注:SLF4J是应用非常广泛的日志框架,它在记录日志时为了解决这种性能浪费的问题,并不推荐首先进行
字符串的拼接,而是将字符串的若干部分作为可变参数传入方法中,仅在日志级别满足要求的情况下才会进
行字符串拼接。例如: LOGGER.debug("变量{}的取值为{}。", "os", "macOS") ,其中的大括号 {} 为占位
符。如果满足日志级别要求,则会将“os”和“macOS”两个字符串依次拼接到大括号的位置;否则不会进行字
符串拼接。这也是一种可行解决方案,但Lambda可以做到更好。
体验Lambda的更优写法
使用Lambda必然需要一个函数式接口:
@FunctionalInterface
public interface MessageBulider{
String bulidMessage();
}然后对log方法进行改造:
public class Demo{
private static void log(int level, MessageBulider bulider){
if (level == 1) {
System.out.println(builder.buildMessage());
}
public static void main(String[] args){
String msgA = "Hello";
String msgB = "World";
String msgC = "Java";
log(1, ()->msgA + msgB + msgC);
}
}这样一来,只有当级别满足要求的时候,才会进行三个字符串的拼接;否则三个字符串将不会进行拼接。
证明Lambda的延迟
public class Demo{
private static void log(int level, MessageBuilder builder) {
if (level == 1) {
System.out.println(builder.buildMessage());
}
}
public static void main(String[] args) {
String msgA = "Hello";
String msgB = "World";
String msgC = "Java";
log(2, () ‐> {
System.out.println("Lambda执行!");
return msgA + msgB + msgC;
});
}
}从结果中可以看出,再不符合急别要求的情况下,Lambda将不会执行。从而达到节省性能的结果。
扩展:实际上使用内部类也可以达到同样的效果,只是将代码操作延迟到了另一个对象当中通过调用方法来完成。而是否调用其所在方法是再条件判断之后才执行。
12.2.2 - 使用Lambda作为参数和返回值
如果抛开实现原理不说,Java中的Lambda表达式可以被当作是匿名内部类的替代品。如果方法的参数是一个函数
式接口类型,那么就可以使用Lambda表达式进行替代。使用Lambda表达式作为方法参数,其实就是使用函数式
接口作为方法参数。
例如 java.lang.Runnable 接口就是一个函数式接口,假设有一个 startThread 方法使用该接口作为参数,那么就
可以使用Lambda进行传参。这种情况其实和 Thread 类的构造方法参数为 Runnable 没有本质区别。
public class Demo04Runnable {
private static void startThread(Runnable task) {
new Thread(task).start();
}
public static void main(String[] args) {
startThread(() ‐> System.out.println("线程任务执行!"));
}
}类似地,如果一个方法的返回值类型是一个函数式接口,那么就可以直接返回一个Lambda表达式。当需要通过一
个方法来获取一个 java.util.Comparator 接口类型的对象作为排序器时,就可以调该方法获取。
import java.util.Arrays;
import java.util.Comparator;
public class Demo06Comparator {
private static Comparator newComparator() {
return (a, b) ‐> b.length() ‐ a.length();
}
public static void main(String[] args) {
String[] array = { "abc", "ab", "abcd" };
System.out.println(Arrays.toString(array));
Arrays.sort(array, newComparator());
System.out.println(Arrays.toString(array));
}
} 其中直接return一个Lambda表达式即可。
12.3 - 常用的函数式接口
JDK提供了大量常用的函数式接口以丰富Lambda的典型使用场景,它们主要在 java.util.function 包中被提供。
下面是最简单的几个接口及使用示例。
12.3.1 - Supplier接口
java.util.function.Supplier
象数据。由于这是一个函数式接口,这也就意味着对应的Lambda表达式需要“对外提供”一个符合泛型类型的对象
数据。
import java.util.fuction.Supplier;
public class Demo{
private static String getString(Supplier function){
return function.get();
}
public static void main(String[] args){
String msgA = "Hello";
String msgB = "World";
System.out.println(getString(() ‐> msgA + msgB));
}
} 12.3.2 - 练习:求数组元素最大值
使用 Supplier 接口作为方法参数类型,通过Lambda表达式求出int数组中的最大值。提示:接口的泛型请使用
java.lang.Integer 类。
public class Demo02Test {
//定一个方法,方法的参数传递Supplier,泛型使用Integer
public static int getMax(Supplier sup){
return sup.get();
}
public static void main(String[] args) {
int arr[] = {2,3,4,52,333,23};
//调用getMax方法,参数传递Lambda
int maxNum = getMax(()‐>{
//计算数组的最大值
int max = arr[0];
for(int i : arr){
if(i>max){
max = i;
}
}
return max;
});
System.out.println(maxNum);
}
} 12.3.3 - Consumer接口
java.util.function.Consumer
其数据类型由泛型决定。
抽象方法:accept
Consumer 接口中包含抽象方法 void accept(T t) ,意为消费一个指定泛型的数据。基本使用如:
import java.util.function.Consumer;
public class Demo {
private static void consumeString(Consumer function) {
function.accept("Hello");
}
public static void main(String[] args) {
consumeString(s ‐> System.out.println(s));
}
} 当然,更好的写法是使用方法引用。
默认方法:andThen
如果一个方法的参数和返回值全都是 Consumer 类型,那么就可以实现效果:消费数据的时候,首先做一个操作,
然后再做一个操作,实现组合。而这个方法就是 Consumer 接口中的default方法 andThen 。下面是JDK的源代码:
default Consumer andThen(Consumer after) {
Objects.requireNonNull(after);
return (T t) ‐> { accept(t); after.accept(t); };
} java.util.Objects 的 requireNonNull 静态方法将会在参数为null时主动抛出
NullPointerException 异常。这省去了重复编写if语句和抛出空指针异常的麻烦。
要想实现组合,需要两个或多个Lambda表达式即可,而 andThen 的语义正是“一步接一步”操作。例如两个步骤组
合的情况:
import java.util.function.Consumer;
public class Demo{
private static void consumeString(Consumer one, Consumer two) {
one.andThen(two).accept("Hello");
}
public static void main(String[] args) {
consumeString(
s ‐> System.out.println(s.toUpperCase()),
s ‐> System.out.println(s.toLowerCase()));
}
} 运行结果将会首先打印完全大写的HELLO,然后打印完全小写的hello。当然,通过链式写法可以实现更多步骤的
组合。
12.3.4 - 练习:格式化打印信息
下面的字符串数组当中存有多条信息,请按照格式“ 姓名:XX。性别:XX。 ”的格式将信息打印出来。要求将打印姓
名的动作作为第一个 Consumer 接口的Lambda实例,将打印性别的动作作为第二个 Consumer 接口的Lambda实
例,将两个 Consumer 接口按照顺序“拼接”到一起。
public static void main(String[] args) {
String[] array = { "迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男" };
}import java.util.function.Consumer;
public class Demo{
public static void main(String[] args) {
String[] array = { "迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男" };
printInfo(
s ‐> System.out.print("姓名:" + s.split(",")[0]),
s ‐> System.out.println("。性别:" + s.split(",")[1] + "。"),array);
}
private static void printInfo(Consumer one, Consumer two, String[] array) {
for (String info : array) {
one.andThen(two).accept(info); // 姓名:迪丽热巴。性别:女。
}
}
} 12.3.5 - Predicate接口
有时候我们需要对某种类型的数据进行判断,从而得到一个boolean值结果。这时可以使用
java.util.function.Predicate
抽象方法:test
Predicate 接口中包含一个抽象方法: boolean test(T t) 。用于条件判断的场景:
import java.util.function.Predicate;
public class Demo {
private static void method(Predicate predicate) {
boolean veryLong = predicate.test("HelloWorld");
System.out.println("字符串很长吗:" + veryLong);
}
public static void main(String[] args) {
method(s ‐> s.length() > 5);
}
} 条件判断的标准是传入的Lambda表达式逻辑,只要字符串长度大于5则认为很长。
默认方法:and
既然是条件判断,就会存在与、或、非三种常见的逻辑关系。其中将两个 Predicate 条件使用“与”逻辑连接起来实
现“并且”的效果时,可以使用default方法 and 。其JDK源码为:
default Predicate and(Predicate other) {
Objects.requireNonNull(other);
return (t) ‐> test(t) && other.test(t);
} 如果要判断一个字符串既要包含大写“H”,又要包含大写“W”,那么:
import java.util.function.Predicate;
public class Demo{
private static void method(Predicate one, Predicate two) {
boolean isValid = one.and(two).test("Helloworld");
System.out.println("字符串符合要求吗:" + isValid);
}
public static void main(String[] args) {
method(s ‐> s.contains("H"), s ‐> s.contains("W"));
}
} 默认方法:or
与 and 的“与”类似,默认方法 or 实现逻辑关系中的“或”。JDK源码为:
default Predicate or(Predicate other) {
Objects.requireNonNull(other);
return (t) ‐> test(t) || other.test(t);
} 如果希望实现逻辑“字符串包含大写H或者包含大写W”,那么代码只需要将“and”修改为“or”名称即可,其他都不
变:
import java.util.function.Predicate;
public class Demo {
private static void method(Predicate one, Predicate two) {
boolean isValid = one.or(two).test("Helloworld");
System.out.println("字符串符合要求吗:" + isValid);
}
public static void main(String[] args) {
method(s ‐> s.contains("H"), s ‐> s.contains("W"));
}
} 默认方法:negate
“与”、“或”已经了解了,剩下的“非”(取反)也会简单。默认方法 negate 的JDK源代码为:
default Predicate negate() {
return (t) ‐> !test(t);
} 从实现中很容易看出,它是执行了test方法之后,对结果boolean值进行“!”取反而已。一定要在 test 方法调用之前
调用 negate 方法,正如 and 和 or 方法一样:
import java.util.function.Predicate;
public class Demo{
private static void method(Predicate predicate) {
boolean veryLong = predicate.negate().test("HelloWorld");
System.out.println("字符串很长吗:" + veryLong);
}
public static void main(String[] args) {
method(s ‐> s.length() < 5);
}
} 12.3.6 - 练习:集合信息筛选
数组当中有多条“姓名+性别”的信息如下,请通过 Predicate 接口的拼装将符合要求的字符串筛选到集合
ArrayList 中,需要同时满足两个条件:
-
必须为女生;
-
姓名为4个字。
public class DemoPredicate {
public static void main(String[] args) {
String[] array = { "迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男", "赵丽颖,女" };
}
}import java.util.ArrayList;
import java.util.List;
import java.util.function.Predicate;
public class Demo{
public static void main(String[] args) {
String[] array = { "迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男", "赵丽颖,女" };
List list = filter(array,
s ‐> "女".equals(s.split(",")[1]),
s ‐> s.split(",")[0].length() == 4);
System.out.println(list);
}
private static List filter(String[] array, Predicate one,
Predicate two) {
List list = new ArrayList<>();
for (String info : array) {
if (one.and(two).test(info)) {
list.add(info);
}
}
return list;
}
} 12.3.7 - Function接口
java.util.function.Function
后者称为后置条件。
抽象方法:apply
Function 接口中最主要的抽象方法为: R apply(T t) ,根据类型T的参数获取类型R的结果。
使用的场景例如:将 String 类型转换为 Integer 类型。
import java.util.function.Function;
public class Demo11FunctionApply {
private static void method(Function function) {
int num = function.apply("10");
System.out.println(num + 20);
}
public static void main(String[] args) {
method(s ‐> Integer.parseInt(s));
}
} 当然,最好是通过方法引用的写法。
默认方法:andThen
Function 接口中有一个默认的andThen方法,用来进行组合操作。JDK源代码如下:
default Function andThen(Function after) {
Objects.requireNonNull(after);
return (T t) ‐> after.apply(apply(t));
} 该方法同样用于“先做什么,再做什么”的场景,和 Consumer 中的 andThen 差不多:
import java.util.function.Function;
public class Demo12FunctionAndThen {
private static void method(Function one, Function two) {
int num = one.andThen(two).apply("10");
System.out.println(num + 20);
}
public static void main(String[] args) {
method(str‐>Integer.parseInt(str)+10, i ‐> i *= 10);
}
} 第一个操作是将字符串解析成为int数字,第二个操作是乘以10。两个操作通过 andThen 按照前后顺序组合到了一
起。
请注意,Function的前置条件泛型和后置条件泛型可以相同。
12.3.8 - 练习:自定义函数模型拼接
请使用 Function 进行函数模型的拼接。
import java.util.function.Function;
public class DemoFunction {
public static void main(String[] args) {
String str = "赵丽颖,20";
int age = getAgeNum(str, s ‐> s.split(",")[1],
s ‐>Integer.parseInt(s),
n ‐> n += 100);
System.out.println(age);
}
private static int getAgeNum(String str, Function one,
Function two,
Function three) {
return one.andThen(two).andThen(three).apply(str);
}
}
13 - Stream流、方法引用
13.1 - Stream流
13.1.1 - 传统集合的多步遍历代码
几乎所有的集合(如 Collection 接口或 Map 接口等)都支持直接或间接的遍历操作。而当我们需要对集合中的元
素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。
import java.util.ArrayList;
import java.util.List;
public class Demo{
public stataic void main(String[] args){
List list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
for (String name : list) {
System.out.println(name);
}
}
} 这是一段非常简单的集合遍历操作:对集合中的每一个字符串都进行打印输出操作。
13.1.2 - 循环遍历的弊端
Java 8的Lambda让我们可以更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行
了对比说明。现在,我们仔细体会一下上例代码,可以发现:
- for循环的语法就是“怎么做”
- for循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从
第一个到最后一个顺次处理的循环。前者是目的,后者是方式
试想一下,如果希望对集合中的元素进行筛选过滤:
- 将集合A根据条件一过滤为子集B;
- 然后再根据条件二过滤为子集C。
那怎么办?在Java 8之前的做法可能为:
import java.util.ArrayList;
import java.util.List;
public class Demo02NormalFilter {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
List zhangList = new ArrayList<>();
for (String name : list) {
if (name.startsWith("张")) {
zhangList.add(name);
}
}
List shortList = new ArrayList<>();
for (String name : zhangList) {
if (name.length() == 3) {
shortList.add(name);
}
}
for (String name : shortList) {
System.out.println(name);
}
}
} 这段代码中含有三个循环,每一个作用不同:
- 首先筛选所有姓张的人;
- 然后筛选名字有三个字的人;
- 最后进行对结果进行打印输出。
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。这是理所当然的么?不是。循
环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使
用另一个循环从头开始
13.1.3 - Stream的更优写法
下面来看一下借助Java 8的Stream API,什么才叫优雅:
import java.util.ArrayList;
import java.util.List;
public class Demo03StreamFilter {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
list.stream()
.filter(s ‐> s.startsWith("张"))
.filter(s ‐> s.length() == 3)
.forEach(System.out::println);
}
} 直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印。代码
中并没有体现使用线性循环或是其他任何算法进行遍历,我们真正要做的事情内容被更好地体现在代码中。
13.1.4 - 流式思想概述
整体来看,流式思想类似于工厂车间的“生产流水线”。
Stream(流)是一个来自数据源的元素队列
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组 等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent
style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。 - 内部迭代: 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭
代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法
当使用一个流的时候,通常包括三个基本步骤:获取一个数据源(source)→ 数据转换→执行操作获取想要的结
果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以
像链条一样排列,变成一个管道。
13.1.5 - 根据Collection获取流
java.util.stream.Stream
获取一个流非常简单,有以下几种常用的方式:
- 所有的 Collection 集合都可以通过 stream 默认方法获取流;
- Stream 接口的静态方法 of 可以获取数组对应的流
首先, java.util.Collection 接口中加入了default方法 stream 用来获取流,所以其所有实现类均可获取流。
import java.util.*;
import java.util.stream.Stream;
public class Demo04GetStream {
public static void main(String[] args) {
List list = new ArrayList<>();
// ...
Stream stream1 = list.stream();
Set set = new HashSet<>();
// ...
Stream stream2 = set.stream();
Vector vector = new Vector<>();
// ...
Stream stream3 = vector.stream();
}
} 13.1.6 - 根据Map获取流
java.util.Map 接口不是 Collection 的子接口,且其K-V数据结构不符合流元素的单一特征,所以获取对应的流
需要分key、value或entry等情况:
import java.util.HashMap;
import java.util.Map;
import java.util.stream.Stream;
public class Demo05GetStream {
public static void main(String[] args) {
Map map = new HashMap<>();
// ...
Stream keyStream = map.keySet().stream();
Stream valueStream = map.values().stream();
Stream> entryStream = map.entrySet().stream();
}
} 13.1.7 - 根据数组获取流
如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以 Stream 接口中提供了静态方法
of ,使用很简单:
import java.util.stream.Stream;
public class Demo06GetStream {
public static void main(String[] args) {
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream stream = Stream.of(array);
}
}
// of 方法的参数其实是一个可变参数,所以支持数组 13.1.8 - 逐一处理:forEach
流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
- 延迟方法:返回值类型仍然是 Stream 接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方
法均为延迟方法。) - 终结方法:返回值类型不再是 Stream 接口自身类型的方法,因此不再支持类似 StringBuilder 那样的链式调
用。本小节中,终结方法包括 count 和 forEach 方法。
虽然方法名字叫 forEach ,但是与for循环中的“for-each”昵称不同。
void forEach(Consumer action);该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理。
import java.util.stream.Stream;
public class Demo12StreamForEach {
public static void main(String[] args) {
Stream stream = Stream.of("张无忌", "张三丰", "周芷若");
stream.forEach(name‐> System.out.println(name));
}
} 13.1.9 - 过滤:filter
可以通过 filter 方法将一个流转换成另一个子集流。方法签名:
Stream filter(Predicate predicate); 该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
import java.util.stream.Stream;
class HelloWorld {
public static void main(String[] args) {
Stream original = Stream.of("张无忌", "张三丰", "周芷若","王八蛋","张大傻子");
Stream result = original.filter(s->s.startsWith("张"));
result.forEach(s->System.out.println(s));
}
} 13.1.10 - 映射:map
如果需要将流中的元素映射到另一个流中,可以使用 map 方法。方法签名:
Stream map(Function mapper); 该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
import java.util.stream.Stream;
public class Demo08StreamMap {
public static void main(String[] args) {
Stream original = Stream.of("10", "12", "18");
Stream result = original.map(str‐>Integer.parseInt(str));
}
} 这段代码中, map 方法的参数通过方法引用,将字符串类型转换成为了int类型(并自动装箱为 Integer 类对
象)。
13.1.11 - 统计个数:count
正如旧集合 Collection 当中的 size 方法一样,流提供 count 方法来数一数其中的元素个数:
long count();该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。基本使用:
import java.util.stream.Stream;
public class Demo09StreamCount {
public static void main(String[] args) {
Stream original = Stream.of("张无忌", "张三丰", "周芷若");
Stream result = original.filter(s ‐> s.startsWith("张"));
System.out.println(result.count()); // 2
}
} 13.1.12 - 取用前几个:limit
limit 方法可以对流进行截取,只取用前n个。方法签名:
Stream limit(long maxSize); 参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。基本使用:
import java.util.stream.Stream;
public class Demo10StreamLimit {
public static void main(String[] args) {
Stream original = Stream.of("张无忌", "张三丰", "周芷若");
Stream result = original.limit(2);
System.out.println(result.count()); // 2
}
} 13.1.13 - 跳过前几个:skip
如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:
Stream skip(long n); 如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
import java.util.stream.Stream;
public class Demo11StreamSkip {
public static void main(String[] args) {
Stream original = Stream.of("张无忌", "张三丰", "周芷若");
Stream result = original.skip(2);
System.out.println(result.count()); // 1
}
} 13.1.14 - 组合:concat
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :
static Stream concat(Stream a, Stream b) 这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的
import java.util.stream.Stream;
public class Demo12StreamConcat {
public static void main(String[] args) {
Stream streamA = Stream.of("张无忌");
Stream streamB = Stream.of("张翠山");
Stream result = Stream.concat(streamA, streamB);
}
} 13.1.15 - 练习:集合元素处理(传统方式)
现在有两个 ArrayList 集合存储队伍当中的多个成员姓名,要求使用传统的for循环(或增强for循环)依次进行以
下若干操作步骤:
- 第一个队伍只要名字为3个字的成员姓名;存储到一个新集合中。
- 第一个队伍筛选之后只要前3个人;存储到一个新集合中。
- 第二个队伍只要姓张的成员姓名;存储到一个新集合中。
- 第二个队伍筛选之后不要前2个人;存储到一个新集合中。
- 将两个队伍合并为一个队伍;存储到一个新集合中。
- 根据姓名创建 Person 对象;存储到一个新集合中。
- 打印整个队伍的Person对象信息。
import java.util.ArrayList;
import java.util.List;
public class DemoArrayListNames {
public static void main(String[] args) {
//第一支队伍
ArrayList one = new ArrayList<>();
one.add("迪丽热巴");
one.add("宋远桥");
one.add("苏星河");
one.add("石破天");
one.add("石中玉");
one.add("老子");
one.add("庄子");
one.add("洪七公");
//第二支队伍
ArrayList two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("赵丽颖");
two.add("张三丰");
two.add("尼古拉斯赵四");
two.add("张天爱");
two.add("张二狗");
// ....
}
} public class Person {
private String name;
public Person() {}
public Person(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{name='" + name + "'}";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class Person {
private String name;
public Person() {}
public Person(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{name='" + name + "'}";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class HelloWorld {
public static void main(String[] args) {
List one = new ArrayList<>();
one.add("迪丽热巴");
one.add("宋远桥");
one.add("苏星河");
one.add("石破天");
one.add("石中玉");
one.add("老子");
one.add("庄子");
one.add("洪七公");
List two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("赵丽颖");
two.add("张三丰");
two.add("尼古拉斯赵四");
two.add("张天爱");
two.add("张二狗");
// 第一个队伍只要名字为3个字的成员姓名;
List oneA = new ArrayList<>();
for (String name : one) {
if (name.length() == 3) {
oneA.add(name);
}
}
// 第一个队伍筛选之后只要前3个人;
List oneB = new ArrayList<>();
for (int i = 0; i < 3; i++) {
oneB.add(oneA.get(i));
}
// 第二个队伍只要姓张的成员姓名;
List twoA = new ArrayList<>();
for (String name : two) {
if (name.startsWith("张")) {
twoA.add(name);
}
}
// 第二个队伍筛选之后不要前2个人;
List twoB = new ArrayList<>();
for (int i = 2; i < twoA.size(); i++) {
twoB.add(twoA.get(i));
}
// 将两个队伍合并为一个队伍;
List totalNames = new ArrayList<>();
totalNames.addAll(oneB);
totalNames.addAll(twoB);
// 根据姓名创建Person对象;
List totalPersonList = new ArrayList<>();
for (String name : totalNames) {
totalPersonList.add(new Person(name));
}
// 打印整个队伍的Person对象信息。
for (Person person : totalPersonList) {
System.out.println(person);
}
}
} 13.1.16 - 练习:集合元素处理(Stream方式)
class HelloWorld {
public static void main(String[] args) {
List one = new ArrayList<>();
one.add("迪丽热巴");
one.add("宋远桥");
one.add("苏星河");
one.add("石破天");
one.add("石中玉");
one.add("老子");
one.add("庄子");
one.add("洪七公");
List two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("赵丽颖");
two.add("张三丰");
two.add("尼古拉斯赵四");
two.add("张天爱");
two.add("张二狗");
// 第一个队伍只要名字为3个字的成员姓名;
// 第一个队伍筛选之后只要前3个人;
Stream streamOne = one.stream().filter(s->s.length() == 3).limit(3);
// 第二个队伍只要姓张的成员姓名;
// 第二个队伍筛选之后不要前2个人;
Stream streamTwo = two.stream().filter(s->s.startsWith("张")).skip(2);
// 将两个队伍合并为一个队伍;
// 根据姓名创建Person对象;
// 打印整个队伍的Person对象信息。
Stream.concat(streamOne, streamTwo).map(Person::new).forEach(System.out::println);
}
} 13.2 - 方法引用
在使用Lambda表达式的时候,我们实际上传递进去的代码就是一种解决方案:拿什么参数做什么操作。那么考虑
一种情况:如果我们在Lambda中所指定的操作方案,已经有地方存在相同方案,那是否还有必要再写重复逻辑?
13.2.1 - 冗余的Lambda场景
来看一个简单的函数式接口以应用Lambda表达式:
@FunctionalInterface
public interface Printable {
void print(String str);
}在 Printable 接口当中唯一的抽象方法 print 接收一个字符串参数,目的就是为了打印显示它。那么通过Lambda
来使用它的代码很简单:
public class Demo01PrintSimple {
private static void printString(Printable data) {
data.print("Hello, World!");
}
public static void main(String[] args) {
printString(s ‐> System.out.println(s));
}
}其中 printString 方法只管调用 Printable 接口的 print 方法,而并不管 print 方法的具体实现逻辑会将字符串
打印到什么地方去。而 main 方法通过Lambda表达式指定了函数式接口 Printable 的具体操作方案为:拿到String(类型可推导,所以可省略)数据后,在控制台中输出它。
13.2.2 - 问题分析
这段代码的问题在于,对字符串进行控制台打印输出的操作方案,明明已经有了现成的实现,那就是 System.out
对象中的 println(String) 方法。既然Lambda希望做的事情就是调用 println(String) 方法,那何必自己手动调
用呢?
13.2.3 - 用方法改进代码
能否省去Lambda的语法格式(尽管它已经相当简洁)呢?只要“引用”过去就好了:
public class Demo02PrintRef {
private static void printString(Printable data) {
data.print("Hello, World!");
}
public static void main(String[] args) {
printString(System.out::println);
}
}
// 请注意其中的双冒号 :: 写法,这被称为“方法引用”,而双冒号是一种新的语法。13.2.4 - 方法引用符
双冒号 :: 为引用运算符,而它所在的表达式被称为方法引用。如果Lambda要表达的函数方案已经存在于某个方
法的实现中,那么则可以通过双冒号来引用该方法作为Lambda的替代者。
语义分析
例如上例中, System.out 对象中有一个重载的 println(String) 方法恰好就是我们所需要的。那么对于
printString 方法的函数式接口参数,对比下面两种写法,完全等效:
- Lambda表达式写法: s -> System.out.println(s);
- 方法引用写法: System.out::println
第一种语义是指:拿到参数之后经Lambda之手,继而传递给 System.out.println 方法去处理。
第二种等效写法的语义是指:直接让 System.out 中的 println 方法来取代Lambda。两种写法的执行效果完全一
样,而第二种方法引用的写法复用了已有方案,更加简洁。
注:Lambda 中 传递的参数 一定是方法引用中 的那个方法可以接收的类型,否则会抛出异常
推导与省略
如果使用Lambda,那么根据“可推导就是可省略”的原则,无需指定参数类型,也无需指定的重载形式——它们都
将被自动推导。而如果使用方法引用,也是同样可以根据上下文进行推导
函数式接口是Lambda的基础,而方法引用是Lambda的孪生兄弟。
下面这段代码将会调用 println 方法的不同重载形式,将函数式接口改为int类型的参数:
@FunctionalInterface
public interface PrintableInteger {
void print(int str);
}由于上下文变了之后可以自动推导出唯一对应的匹配重载,所以方法引用没有任何变化:
public class Demo03PrintOverload {
private static void printInteger(PrintableInteger data) {
data.print(1024);
}
public static void main(String[] args) {
printInteger(System.out::println);
}
}这次方法引用将会自动匹配到 println(int) 的重载形式。
13.2.5 - 通过对象名引用成员方法
这是最常见的一种用法,与上例相同。如果一个类中已经存在了一个成员方法:
public class MethodRefObject {
public void printUpperCase(String str) {
System.out.println(str.toUpperCase());
}
}函数式接口仍然定义为:
@FunctionalInterface
public interface Printable {
void print(String str);
}那么当需要使用这个 printUpperCase 成员方法来替代 Printable 接口的Lambda的时候,已经具有了
MethodRefObject 类的对象实例,则可以通过对象名引用成员方法,代码为:
public class Demo04MethodRef {
private static void printString(Printable lambda) {
lambda.print("Hello");
}
public static void main(String[] args) {
MethodRefObject obj = new MethodRefObject();
printString(obj::printUpperCase);
}
}13.2.6 - 通过类名引用静态方法
由于在 java.lang.Math 类中已经存在了静态方法 abs ,所以当我们需要通过Lambda来调用该方法时,有两种写
法。首先是函数式接口:
@FunctionalInterface
public interface Calcable {
int calc(int num);
}第一种写法是使用Lambda表达式:
public class Demo05Lambda {
private static void method(int num, Calcable lambda) {
System.out.println(lambda.calc(num));
}
public static void main(String[] args) {
method(‐10, n ‐> Math.abs(n));
}
}但是使用方法引用的更好写法是:
public class Demo06MethodRef {
private static void method(int num, Calcable lambda) {
System.out.println(lambda.calc(num));
}
public static void main(String[] args) {
method(‐10, Math::abs);
}
}在这个例子中,下面两种写法是等效的:
-
Lambda表达式: n -> Math.abs(n)
-
方法引用: Math::abs
13.2.7 - 通过super引用成员方法
如果存在继承关系,当Lambda中需要出现super调用时,也可以使用方法引用进行替代。首先是函数式接口:
@FunctionalInterface
public interface Greetable {
void greet();
}然后是父类 Human 的内容:
public class Human {
public void sayHello() {
System.out.println("Hello!");
}
}最后是子类 Man 的内容,其中使用了Lambda的写法:
public class Man extends Human {
@Override
public void sayHello() {
System.out.println("大家好,我是Man!");
}
//定义方法method,参数传递Greetable接口
public void method(Greetable g){
g.greet();
}
public void show(){
//调用method方法,使用Lambda表达式
method(()‐>{
//创建Human对象,调用sayHello方法
new Human().sayHello();
});
//简化Lambda
method(()‐>new Human().sayHello());
//使用super关键字代替父类对象
method(()‐>super.sayHello());
}
}但是如果使用方法引用来调用父类中的 sayHello 方法会更好,例如另一个子类 Woman :
public class Man extends Human {
@Override
public void sayHello() {
System.out.println("大家好,我是Man!");
}
//定义方法method,参数传递Greetable接口
public void method(Greetable g){
g.greet();
}
public void show(){
method(super::sayHello);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: () -> super.sayHello()
- 方法引用: super::sayHello
13.2.8 - 通过this引用成员方法
this代表当前对象,如果需要引用的方法就是当前类中的成员方法,那么可以使用“this::成员方法”的格式来使用方
法引用。首先是简单的函数式接口:
@FunctionalInterface
public interface Richable {
void buy();
}下面是一个丈夫 Husband 类:
public class Husband {
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(() ‐> System.out.println("买套房子"));
}
}开心方法 beHappy 调用了结婚方法 marry ,后者的参数为函数式接口 Richable ,所以需要一个Lambda表达式。
但是如果这个Lambda表达式的内容已经在本类当中存在了,则可以对 Husband 丈夫类进行修改:
public class Husband {
private void buyHouse() {
System.out.println("买套房子");
}
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(() ‐> this.buyHouse());
}
}如果希望取消掉Lambda表达式,用方法引用进行替换,则更好的写法为
public class Husband {
private void buyHouse() {
System.out.println("买套房子");
}
private void marry(Richable lambda) {
lambda.buy();
}
public void beHappy() {
marry(this::buyHouse);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: () -> this.buyHouse()
- 方法引用: this::buyHouse
13.2.9 - 类的构造器引用
由于构造器的名称与类名完全一样,并不固定。所以构造器引用使用 类名称::new 的格式表示。首先是一个简单
的 Person 类:
public class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}然后是用来创建 Person 对象的函数式接口:
public interface PersonBuilder {
Person buildPerson(String name);
}要使用这个函数式接口,可以通过Lambda表达式:
public class Demo09Lambda {
public static void printName(String name, PersonBuilder builder) {
System.out.println(builder.buildPerson(name).getName());
}
public static void main(String[] args) {
printName("赵丽颖", name ‐> new Person(name));
}
}但是通过构造器引用,有更好的写法:
public class Demo10ConstructorRef {
public static void printName(String name, PersonBuilder builder) {
System.out.println(builder.buildPerson(name).getName());
}
public static void main(String[] args) {
printName("赵丽颖", Person::new);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: name -> new Person(name)
- 方法引用: Person::new
13.2.10 - 数组的构造器引用
数组也是 Object 的子类对象,所以同样具有构造器,只是语法稍有不同。如果对应到Lambda的使用场景中时,
需要一个函数式接口:
@FunctionalInterface
public interface ArrayBuilder {
int[] buildArray(int length);
}在应用该接口的时候,可以通过Lambda表达式:
public class Demo11ArrayInitRef {
private static int[] initArray(int length, ArrayBuilder builder) {
return builder.buildArray(length);
}
public static void main(String[] args) {
int[] array = initArray(10, length ‐> new int[length]);
}
}但是更好的写法是使用数组的构造器引用:
public class Demo12ArrayInitRef {
private static int[] initArray(int length, ArrayBuilder builder) {
return builder.buildArray(length);
}
public static void main(String[] args) {
int[] array = initArray(10, int[]::new);
}
}在这个例子中,下面两种写法是等效的:
- Lambda表达式: length -> new int[length]
- 方法引用: int[]::new