假期充电 | 用经典图书评分数据集,练手推荐系统(附参考源码)
By 超神经
内容概要:五一假期过半,是不是光顾着玩啦?今天给大家推荐一个数据集,玩累了玩烦了,不如,学习一会儿?
关键词:系统推进 公开数据集 算法
共享阅读,囊括全球 150 万会员
「微信漂流瓶」想必大家都不陌生,其实早在 2001 年,就已经存在「图书漂流」了,这就是 Book-Crossing。
Book-Crossing 是一个共享阅读网站,由 Ron Hornbaker 在 2001 年 4 月 17 日创建,旨在将图书流通与互联网结合,让读完的书籍流通起来,被更多的人继续阅读。

Book-Crossing Logo 及意大利语 Slogan
意为自由放取书籍
读者可以在 Book-Crossing 网站注册,然后给自己的书本编码后,让书籍流通起来,而且可以追踪书籍后续传阅漂流的过程。
2015 年,Book-Crossing 已经拥有 150 万会员,有一千多万本书在 132 个国家间漂流。
20 万本书,百万条评分
Book–Crossing Dataset 是由 Book–Crossing 社区的 278858 名用户的评分组成,其包含约 271379 本书的 1149780 条评分数据。
该数据集包含 3 个分类:BX-用户、BX-书籍、BX-书本评级。
Book–Crossing Dataset
发布机构:弗莱堡大学 Cai-Nicolas Ziegler
包含数量:1,149,780 条评分数据
数据格式:CSV Dump / SQL Dump
数据大小:50.61 MB
采集时间:2004 年 8 月-9 月,为期四周
发布时间:2005 年
下载地址:https://hyper.ai/datasets/5524
BX-用户
包含用户信息,其中用户 ID 已被匿名化并映射到整数,除了包含人口统计数据的部分,其余字段均包含 NULL 值。
BX-书籍
包含书本的 ISBN 标识,除此之外,还提供了作者、出版年份、出版社等基于内容的信息,在拥有多位作者的情况下,仅提供第一作者;并且该数据集提供了链接到封面图像的 URL,相关链接直接指向 Amazon 网站。
BX-书本评级
包含图书评分信息,其中评级分为明确、从 1 – 10 表示和用 0 表示的隐含值。
该数据集由德国弗莱堡大学于 2005 年发布,相关论文有《Improving Recommendation Lists Through Topic Diversification》。
论文地址:http://dwz.date/axbz
数据集怎么用?
《基于模型的协同过滤应用---图书推荐》
https://github.com/XuefengHuang/RecommendationSystem
描述:基于 Spark, Python Flask 的在线图书推荐系统
作者参考项目:https://github.com/jadianes/spark-movie-lens
推荐算法参考思路:
在我们的在线图书推荐系统中,我们借用 Spark 的 ALS 算法的训练和预测函数,每次收到新的数据后,将其更新到训练数据集中,然后更新ALS训练得到的模型。
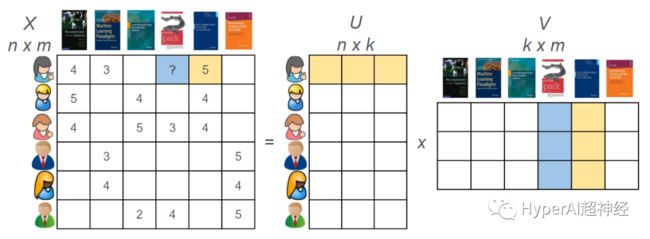
假设我们有一组用户,他们表现出了对一组图书的喜好。用户对一本图书的喜好程度越高,就会给其更高的评分,范围是从1到5。我们来通过一个矩阵来展示它,行代表用户,列代表图书。用户对图书的评分。
所有的评分范围从1到5,5代表喜欢程度最高。第一个用户(行1)对第一个图书(列1)的评分是4。空的单元格代表用户未给图书评价。

矩阵因子分解(如奇异值分解,奇异值分解+ +)将项和用户都转化成了相同的潜在空间,它所代表了用户和项之间的潜相互作用。矩阵分解背后的原理是潜在特征代表了用户如何给项进行评分。
给定用户和项的潜在描述,我们可以预测用户将会给还未评价的项多少评分。
—— 完 ——

扫描二维码,加入讨论群
获得更多优质数据集
了解人工智能落地应用
关注顶会&论文
回复「读者」了解更多
更多精彩内容(点击图片阅读)




直达数据集,点击 阅读原文 