重复数据删除技术简介
0.绪论
一般情况下,数据中心每周需要将主存储设备的所有数据备份到辅存储设备上,并保存数月时间,我们称之为全备份。另外,数据中心可能每天还需做一次增量备份,只备份当天改变的数据。辅存储设备的容量达到主存储设备的10到20倍是很正常的。如果需要做容灾备份的话,容量还需翻一倍,假如容灾备份需要在广域网上进行,那么带宽消耗也是很可怕的。
1. 重复数据删除的分类
从重复数据删除发生的时间进行分类,可以分为在线和离线。在线是指数据到达存储设备之前进行重复数据删除;离线是指先暂时将所有数据存在缓冲区,等到服务器空闲再进行重复数据删除。在线的方式如果实现不当则会较大影响影响存储性能,而离线的方式则需要额外的存储空间。
从重复数据删除查找的范围进行分类,可以分为全局和局部。全局的重复数据删除可以删除多个存储结点的重复数据;局部的重复数据删除则只关注单个存储结点的重复数据。毫无疑问,全局的重复数据删除可以提供更高的压缩率,但是实现起来也更加复杂,开销也更大。
从重复数据删除发生的地点进行分类,可以分为源端和目标端。源端指的是数据的发送方,源端重复数据删除就是指在数据经过网络(比如WAN、LAN等)进行传输之前,就对数据进行重复数据删除处理;目标端指的是数据的接收方,目标端重复数据删除就是指在数据到达目标服务器后,再进行重复数据删除。容易看出,源端方式的优点是节省带宽,缺点是增加了源端机器的负担,而目标端方式则相反。
从重复数据删除实现的粒度进行分类,可以分为文件级和块级。文件级的重复数据删除通过删除相同的文件来减少数据存储量;块级的重复数据删除则是删除相同的数据块,实现方式是将文件或者数据流按一定方法进行分块。由于内容完全相同的文件是比较少见的,所以前者能达到的压缩率十分有限,后者由于其较高的压缩率而被广泛应用。
重复数据删除的实现方式非常依赖实际的工作环境,所以不同环境有着不同的最佳设计方案。
2.定长分块和变长分块
由于块级的重复数据删除技术较高的压缩率,所以在当今的备份系统中得到了广泛的应用。分块技术通常分为两种:定长的分块方式和变长的分块方式。
定长的分块方式实现起来比较简单,就是将文件或者数据流分成等长的数据块,长度通常设置在4KB到8Kb之间。这就类似于将硬盘磁道分成若干512B大小的扇区。考虑这种情况,在文件中间的某个位置插入一个字节,那么从这个位置开始往后,所有的数据块内容都被改变了(向前并入一个字节,向后丢弃一个字节)。这就导致两个相差仅1个字节的文件有大量的重复数据没有删除。
为了解决这个问题,出现了变长的分块方式。变长分块算法根据文件的内容进行分块,现在比较流行的是做法使用滑动窗口技术和Rabin指纹技术。

图1 滑动窗口技术
图一描述了滑动窗口分块算法,滑动窗口的大小的固定的,D和r也是固定参数。窗口在数据流上滑动(通常滑动的幅度可以是1字节),计算窗口内字节的Rabin指纹f。如果f mod D = r成立,那么当前滑动窗口的位置就是一条数据块的边界,否则继续移动滑动窗口。这个过程不断重复,直到整个文件都被分块。通过调整参数,可以控制数据块的平均长度,通常是8Kb。
3.如何判定重复
假设系统接收了一个数据块,并与先前存储的数据块进行比较,那么怎样才能确定两个数据块是相同的呢?
最直接的办法是按字节比较,但是这必须要先将原有数据从磁盘上读出来,这种做法的效率实在太低。现在流行的方法是对每个数据块计算它们的MD5或SHA-1散列值,形象地称其为指纹,并维护一个指纹索引表。每次系统接收一个数据块,如果其指纹已经在索引表中,那么就可以认为这是一个重复数据块,反之这就是一个新数据块。由于数据块的平均长度通常是8KB,而MD5和SHA-1散列值分别为16B和20B,所以是存在冲突风险的。但是据研究表明,不同数据块具有相同指纹的概率要比硬件错误低很多数量级,如果发生了错误,几乎可以肯定是由RAM、IO总线、网络传输、磁盘或者其他硬件、软件错误导致,而不是由于冲突。
4. 块级重复数据删除的基本流程
在一个块级重复数据删除系统的存储设备上至少需要维护三种重要的信息:数据区,文件逻辑视图,指纹索引表。数据区保存了经过重复数据删除处理后剩下的不重复的数据块;文件逻辑视图包括原文件的数据块引用,用于将来恢复数据文件原貌;指纹索引表包括一系列的数据块指纹和数据块元数据的键值对,数据块元数据包括数据块在硬盘的地址和大小等,指纹索引表中的指纹和数据区的数据块是一一对应的关系。
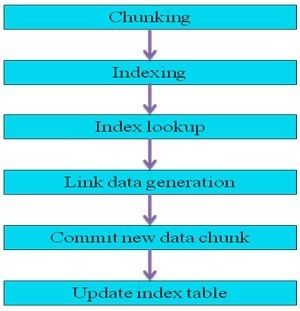
图2 块级重复数据删除的基本流程
图2块级重复数据删除的基本流程,一共可以分为六个步骤:
-
- 将进入系统的文件或数据流用1.2描述的分块算法进行分块。
- 计算每个数据块的指纹。最常用的方法是用SHA-1数字签名算法对每个数据块的内容计算其哈希值,称之为数据块指纹,指纹作为数据块的唯一标识来索引每个数据块。任何具有相同指纹的数据块被认为是相同的数据块,冲突的概率很低。
- 对每一个数据块的指纹查找指纹索引表,若在指纹索引表中发现相同指纹,则认为此数据块是重复的,若在指纹索引表中找不到相同指纹,则认为这是一个新数据块。
- 删除重复的数据块。系统不会存储重复的数据块,而仅仅是在文件逻辑视图中添加重复数据块的引用(数据块指针或者指纹)。即从逻辑上看,系统存在多个数据块副本,从物理上看,系统仅保存单一数据块副本。
- 存储新数据块。系统需要保存新数据块,这是实际储存在物理设备上的数据块。
- 更新指纹索引表。需要添加新数据块的指纹和元数据至指纹索引表,保持指纹索引表和储存数据块的一致性。
当需要恢复一个文件时,先读取文件元数据,根据元数据记录的数据块指针从数据区读出数据块(在另一种实现方式中,可以根据指纹查找指纹索引表获得数据块指针),将数据块重新组装成文件。
5.磁盘瓶颈
在备份系统中,辅存储设备有两个基本的要求。首先是低成本,存储备份数据的成本不能比主存储设备成本高很多。其次是高吞吐率,通常备份工作会选择在晚上和周末进行,如果不能按时完成将会影响日常工作。
在节约成本方面,重复数据删除技术有得天独厚的优势,20:1的压缩率就相当于减少了95%的存储和带宽成本。下面我们重点分析下重复数据删除系统的吞吐率问题。
第4小节给出了块级重复数据删除的基本流程,在第三步需要查找指纹索引表。如果我们有1TB的不同数据块,在平均块长是8KB的情况,那么指纹索引表光指纹就有2.5GB。因为使用RAM来保存指纹索引表成本实在太高了,所以一般指纹索引表保存在磁盘里。这样一来,每次新来一个数据块都需要查找磁盘中的指纹索引表。最坏的情况是这个数据块是第一次出现,指纹索引表根本就没有它的指纹。所以第三步成为了重复数据删除系统的性能瓶颈。
RAM的访问时间是1μm数量级的,而磁盘的访问时间是10ms数量级的,弥补这个缺口主要有两种基本的想法:
- 期望存储器件的更新换代,比如使用新型存储器件代替磁盘存储指纹索引表。
- 使用缓存技术,把RAM作为磁盘的缓存,储存一部分指纹索引表。
目前很多系统都已经采用了缓存的方法,但是效果却并不理想。比如Venti系统,使用了缓存技术后,吞吐率从5.6MB/s提升到了6.5MB/s,仅仅16%的提升归因于较低的缓存命中率。由于指纹是完全随机的,所以在索引中几乎没有空间局部性;另一方面,系统流式地接收数据,时间局部性也很有限。缺乏时空局部性导致了缓存的低命中率。
针对缓存命中率低的问题,Zhu等人[1]提出了一个解决方案,并且已经成功应用在了Data Domain的产品中。他们使用的技术改善了缓存命中率,减少了99%的磁盘访问,但是还有1%的未命中率,此时仍要磁盘中的索引表(多次读磁盘)。
Debnath等人设计的ChunkStash[2]改进了Zhu等人的设计,并使用flash存储指纹索引表,不仅完全避免了在磁盘上查找指纹索引表,而且每次缓存未命中都只需访问一次flash。
Bhagwat等人设计的Extreme Binning[3]则提出了新的思路,他们认为存在少量的重复数据块是可以容忍的,Extreme Binning的特点是查找指纹索引表以文件为单位,每个文件的数据块只需共用一次磁盘访问,而且具有优秀的可扩展性和并行性。
6.参考文献
[1] B. Zhu, K. Li, and H. Patterson. Avoiding the Disk Bottleneck in the Data Domain Deduplication File System. In FAST, 2008.
[2] B. Debnath, S. Sengupta, and J. Li. ChunkStash: Speeding up Inline Storage Deduplication using Flash Memory.
[3] D. Bhagwat, K. Eshghi, D. Long, and M. Lillibridge. Extreme Binning: Scalable, Parallel Deduplication for Chunk-based File Backup. In MASCOTS, 2009.