sparkCore
SparkCore
讲解
1、RDD基本概念
1.1、什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
Dataset:一个数据集合,用于存放数据的。
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
Resilient:RDD中的数据可以存储在内存中或者磁盘中。
1.2、为什么会产生RDD
RDD是Spark的基石,是实现Spark数据处理的核心抽象。那么RDD为什么会产生呢?
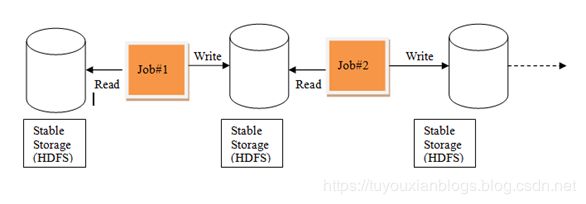
Hadoop的MapReduce是一种基于数据集的工作模式,面向数据,这种工作模式一般是从存储上加载数据集,然后操作数据集,最后写入物理存储设备。数据更多面临的是一次性处理。
MR的这种方式对数据领域两种常见的操作不是很高效。第一种是迭代式的算法。比如机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。
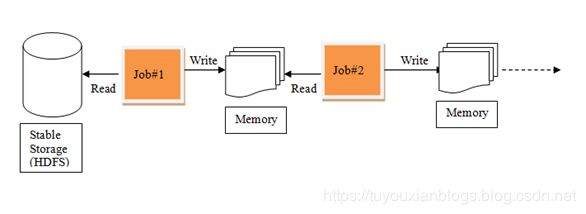
我们需要一个效率非常快,且能够支持迭代计算和有效数据共享的模型,Spark应运而生。RDD是基于工作集的工作模式,更多的是面向工作流。
但是无论是MR还是RDD都应该具有类似位置感知、容错和负载均衡等特性。
MR中的迭代:
spark的迭代:
1.3、RDD的属性
1)A list of partitions
RDD由很多partition构成,在spark中,计算式,有多少partition就对应有多少个task来执行。
2)A function for computing each split
对RDD做计算,相当于对RDD的每个split或partition做计算,其实就是每个算子都作用在每个分区上。
3)A list of dependencies on other RDDs
RDD之间有依赖关系,可溯源。
4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
可选项:如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区,比如可以按key的hash值分区
5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。
按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置,减少数据的IO和网络传输。
1.4、RDD的弹性
1) 自动进行内存和磁盘数据存储的切换
Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换
2) 基于血统的高效容错机制
在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据。
3) Task如果失败会自动进行特定次数的重试
RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是4次。
4) Stage如果失败会自动进行特定次数的重试
如果Job的某个Stage阶段计算失败,框架也会自动进行任务的重新计算,默认次数也是4次。
5) Checkpoint和Persist可主动或被动触发
RDD可以通过Persist持久化将RDD缓存到内存或者磁盘,当再次用到该RDD时直接读取就行。也可以将RDD进行检查点,检查点会将数据存储在HDFS中,该RDD的所有父RDD依赖都会被移除。
6) 数据分片[partition]的高度弹性
可以根据业务的特征,动态调整数据分片的个数,提升整体的应用执行效率。
1.5、RDD的特点
RDD表示只读的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必需的信息。RDDs之间存在依赖,RDD的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化RDD来切断血缘关系。
分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
只读
如下图所示,RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。

由一个RDD转换到另一个RDD,可以通过丰富的操作算子实现,不再像MapReduce那样只能写map和reduce了,如下图所示。

RDD的操作算子包括两类,一类叫做transformations,它是用来将RDD进行转化,构建RDD的血缘关系;另一类叫做actions,它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。
依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖。如下图所示,依赖包括两种,一种是窄依赖,RDDs之间分区是一一对应的,另一种是宽依赖,下游RDD的每个分区与上游RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。
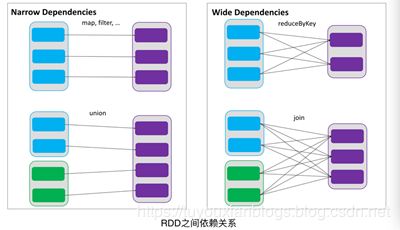
通过RDDs之间的这种依赖关系,一个任务流可以描述为DAG(有向无环图),如下图所示,在实际执行过程中宽依赖对应于Shuffle(图中的reduceByKey和join),窄依赖中的所有转换操作可以通过类似于管道的方式一气呵成执行(图中map和union可以一起执行)。

缓存
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-1经过一系列的转换后得到RDD-n并保存到hdfs,RDD-1在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的RDD-1转换到RDD-m这一过程中,就不会计算其之前的RDD-0了。

checkpoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。
给定一个RDD我们至少可以知道如下几点信息:1、分区数以及分区方式;2、由父RDDs衍生而来的相关依赖信息;3、计算每个分区的数据,计算步骤为:1)如果被缓存,则从缓存中取的分区的数据;2)如果被checkpoint,则从checkpoint处恢复数据;3)根据血缘关系计算分区的数据。
1.6、通过wordcount来查看RDD属性
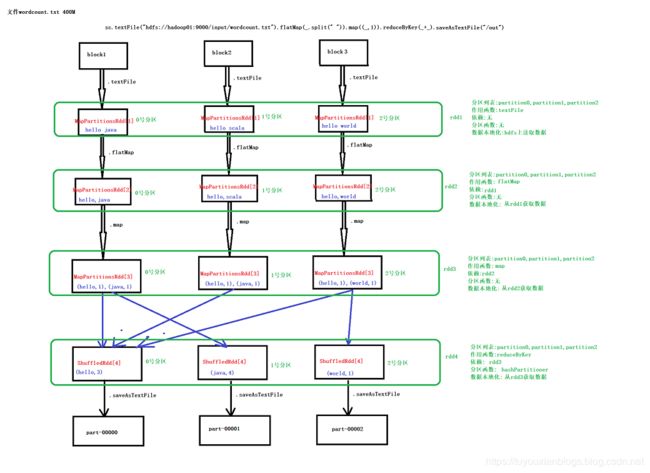
2、RDD的创建以及操作方式
2.1、RDD创建的三种方式
1、通过集合创建
val arr = Array(1,2,3,4,5)
val rdd1:RDD[Int] = sc.parallelize(arr)
2、读取文件创建
val rdd:RDD[String] = sc.textFile("/input/wordcount.txt")
3、rdd转换创建
val rdd1:RDD[String] = sc.textFile("/input/wordcount.txt")
val rdd2:RDD[String] = rdd1.flatMap(_.split(" "))
2.2、RDD的编程常用API
2.2.1、RDD算子分类
Transformation(转换):根据数据集创建一个新的数据集,计算后返回一个新RDD;
例如:一个rdd进行map操作后生了一个新的rdd。
Action(动作):对rdd结果计算后返回一个数值value给驱动程序;
例如:collect算子将数据集的所有元素收集完成返回给驱动程序。
2.2.2、Transformation算子
2.2.2.1、常用的Transformation算子介绍
官网所有transformation算子:
http://spark.apache.org/docs/2.2.0/rdd-programming-guide.html#transformations
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。 |
| repartition(numPartitions) | 重新给 RDD 分区 |
| repartitionAndSortWithinPartitions(partitioner) | 重新给 RDD 分区,并且每个分区内以记录的 key 排序 |
2.2.2.2、常用Transformation算子操作示例
1、map
map(func) : 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
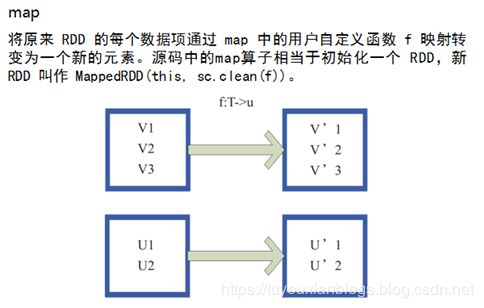
需求:创建一个装载Int数据的Rdd,并对Rdd中的元素*2
//创建一个RDD
val rdd1 = sc.parallelize(1 to 10)
//需求:对每个元素*2
//使用map算子针对rdd中每一条数据进行操作
rdd1.map(_*2).collect
//结果:Array(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
2、filter
filter(func): 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成

需求:创建一个装载Int数据的RDD,并获取其中为偶数的数据
//创建一个rdd
val rdd = sc.parallelize(1 to 10)
//筛选出偶数的数据
rdd.filter(_%2==0).collect
//结果:Array(2, 4, 6, 8, 10)
3、flatMap
flatMap(func) : 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)

需求:切割一组字符串获取一个个的单词
//待处理数据
val data = Array("hello java hello word","hello python hello world","how are you")
//创建rdd
val rdd = sc.parallelize(data)
//切割压平获取单词
rdd.flatMap(_.split(" ")).collect
//结果: Array(hello, java, hello, word, hello, python, hello, world, how, are, you)
//flatMap = map(_.split(" ")) + flatten
//val arr1 = data.map(_.split(" "))
//arr1结果:Array(Array(hello, java, hello, word), Array(hello, python, hello, world), Array(how, are, you))
//arr1.flatten
//结果:Array(hello, java, hello, word, hello, python, hello, world, how, are, you)
4、mapPartitions
mapPartitions针对的是分区上的所有数据,map针对的是分区上的每一条数据
mapPartitions(func) : 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]

//创建一个rdd
val rdd = sc.parallelize(List(("kpop","female"),("zorro","male"),("mobin","male"),("lucy","female")))
//定义一个高阶函数
def partitionsFun(iter : Iterator[(String,String)]) : Iterator[String] = {
var woman = List[String]()
while (iter.hasNext){
val next = iter.next()
next match {
case (_,"female") => woman = next._1 :: woman
case _ =>
}
}
woman.iterator
}
val result = rdd.mapPartitions(partitionsFun)
result.collect()
//结果:Array[String] = Array(kpop, lucy)
5、mapPartitionsWithIndex
mapPartitionsWithIndex(func): 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U]

需求:查看每个分区有哪些数据
//创建RDD,设置分区数为3
val rdd = sc.parallelize(0 to 10,3)
//定义一个高阶函数,第一个参数为分区号,第二个参数为分区里面的数据
def queryPartition(index:Int,it:Iterator[Int])={
var result:List[(Int,List[Int])] = Nil
result = (index,it.toList) :: result
result.toIterator
}
rdd.mapPartitionsWithIndex(queryPartition).collect
//结果: Array((0,List(0, 1, 2)), (1,List(3, 4, 5, 6)), (2,List(7, 8, 9, 10)))
对于算子来说,各分区是并行执行的;即每个分区执行一次该算子
6、union
union(otherDataset): 对源RDD和参数RDD求并集后返回一个新的RDD;不去重

需求: 实现mysql union all功能
val rdd1 = sc.parallelize(1 to 5)
val rdd2 = sc.parallelize(6 to 10)
rdd1.union(rdd2).collect
//结果:Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
7、intersection
intersection(otherDataset): 对源RDD和参数RDD求交集后返回一个新的RDD,求交集,会去重

需求:取出两个rdd中都存在的数据
val rdd1 = sc.parallelize(1 to 5)
val rdd2 = sc.parallelize(3 to 10)
rdd1.intersection(rdd2).collect
//结果:Array(3,4,5)
8、distinct
distinct([numTasks])) : 对源RDD进行去重后返回一个新的RDD

需求:实现mysql distinct功能
val data = Array(1,2,3,1,3,5,6,2,7,9)
val rdd1 = sc.parallelize(data)
rdd1.distinct.collect
//结果:Array(6, 2, 1, 3, 7, 9, 5)
9、sample(withReplacement, fraction, seed)
sample(withReplacement, fraction, seed) : 以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子。例子从RDD中随机且有放回的抽出50%的数据,随机种子值为3(即可能以1 2 3的其中一个起始值)
用于检测数据是否出现数据倾斜,当然也可以统计key出现的次数预测是否数据倾斜,用sample更优
需求:对数据进行抽样,抽取的数据不放回,每个数据抽取的概率是50%
val rdd1 = sc.parallelize(1 to 10)
rdd1.sample(false,0.5).collect
//结果:Array(1, 5, 6, 7, 8, 10) [注意:此结果不固定,每次运行结果都会不太一样]
10、groupByKey
groupByKey([numTasks]): 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD

需求:按照用户性别进行分组
val arr = Array(("tom","man"),("hanmeimei","woman"),("lisi","man"),("zhangsan","man"),("wangwu","woman"))
val rdd1 = sc.parallelize(arr)
//将性别与名字调换位置
val rdd2 = rdd1.map(x=>(x._2,x._1))
//Array(("男","tom"),("女","hanmeimei"),("男","李四"),("男","张三"),("女","王五"))
rdd2.groupByKey().collect
//结果:Array((man,CompactBuffer(tom, lisi, zhangsan)), (woman,CompactBuffer(hanmeimei, wangwu)))
11、reduceByKey
reduceByKey与groupByKey区别:
reduceByKey会在partition上预先聚合,相当于mapreduce中预先进行combiner操作。
groupByKey不会预先聚合。
reduceByKey(func, [numTasks]): 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置

需求:单词统计
val data = Array("hello java hello world","hello scala","python is world good language")
sc.parallelize(data).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
//结果:Array((scala,1), (is,1), (python,1), (language,1), (hello,3), (java,1), (world,2), (good,1))


12、combineByKey
combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C) :
对相同K,把V合并成一个集合.
createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey() 会使用一个叫作 createCombiner() 的函数来创建
那个键对应的累加器的初始值
mergeValue: 如果这是一个在处理当前分区之前已经遇到的键, 它会使用 mergeValue() 方法将该键的累加器对应的当前值与这个新的值进行合并
mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
需求:实现单词计数
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//单词计数
//参数说明:
//第一个参数:在每个分区中如果是第一次遇到该key,则对key的value进行一个初始化
//第二个参数: 在每个分区上相同key按照执行function的逻辑进行计算
//第三个参数: 将每个分区的计算结果那过来之后在按照指定function逻辑进行计算
rdd1.combineByKey(x=>x,(x:Int,y:Int)=>x+y,(x:Int,y:Int)=>x+y).collect
//结果:Array((scala,1), (is,1), (python,1), (language,1), (hello,3), (java,1), (world,2), (good,1))
13、aggregateByKey
aggregateByKey(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
在kv对的RDD中,按key将value进行分组合并,合并时,将每个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出。
seqOp函数用于在每一个分区中用初始值逐步迭代value,combOp函数用于合并每个分区中的结果
需求:单词计数
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
/**
*参数说明:
*第一个参数: 初始值,第二个参数在调用时第一个x就为该初始值
*第二个参数: 每个分区上进行相同key按照指定function逻辑计算,每个key在第一次调用时x的值为第一个参数设置的值
*第三个参数: 将每个分区的计算结果合并后按照指定function逻辑计算
*/
rdd1.aggregateByKey(0)((x:Int,y)=>x+y,(x:Int,y:Int)=>x+y).collect
//结果: Array((scala,1), (is,1), (python,1), (language,1), (hello,3), (java,1), (world,2), (good,1))
//初始值为1:rdd1.aggregateByKey(1)((x:Int,y)=>x+y,(x:Int,y:Int)=>x+y).collect
//结果: Array((scala,2), (is,2), (python,2), (language,2), (hello,5), (java,2), (world,4), (good,2))
14、foldByKey
foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
aggregateByKey的简化操作,seqop和combop相同
需求:单词计数
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//foldByKey是简化版的aggregateByKey
rdd1.foldByKey(0)(_+_).collect
//结果:Array((scala,1), (is,1), (python,1), (language,1), (hello,3), (java,1), (world,2), (good,1))
15、sortByKey
sortByKey([ascending], [numTasks]): 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
需求: 按照key进行排序
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
rdd.sortByKey(true).collect()
//Array((1,dd), (2,bb), (3,aa), (6,cc))
16、sortBy
sortBy(func,[ascending], [numTasks])
与sortByKey类似,但是更灵活
需求:按照单词的次数进行排序
val data = Array(("world",5),("hello",10),("java",3),("scala",6))
val rdd1 = sc.parallelize(data)
//指定单词的次数排序
rdd1.sortBy(_._2).collect
//结果:Array((java,3), (world,5), (scala,6), (hello,10))
17、join
join(otherDataset, [numTasks])
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD

需求:实现mysql inner join功能
val rdd1 = sc.parallelize(Array(("aa",1),("bb",2),("cc",3)))
val rdd2 = sc.parallelize(Array(("aa",1),("ff",2),("dd",3)))
rdd1.join(rdd2).collect
//结果:Array((aa,(1,1)))
18、cogroup
cogroup(otherDataset, [numTasks])
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
val rdd1 = sc.parallelize(Array(("aa",1),("bb",2),("cc",3)))
val rdd2 = sc.parallelize(Array(("aa",1),("ff",2),("dd",3)))
rdd1.cogroup(rdd2).collect
//结果:Array((aa,(CompactBuffer(1),CompactBuffer(1))), (dd,(CompactBuffer(),CompactBuffer(3))), (ff,(CompactBuffer(),CompactBuffer(2))), (bb,(CompactBuffer(2),CompactBuffer())), (cc,(CompactBuffer(3),CompactBuffer())))
19、coalesce
coalesce(numPartitions)
减少 RDD 的分区数到指定值。
//创建RDD,设置分区数为10
val rdd1 = sc.parallelize(Array(("aa",1),("bb",2),("cc",3)),10)
//减少分区数
rdd1.coalesce(1).partitions.length
//结果:1
20、repartition
repartition(numPartitions)
重新给 RDD 分区
//创建RDD,设置分区数为10
val rdd1 = sc.parallelize(Array(("aa",1),("bb",2),("cc",3)),10)
//重新分成3个区
rdd1.repartition(3).partitions.length
//结果:3
21、repartitionAndSortWithinPartitions
repartitionAndSortWithinPartitions(partitioner)
epartitionAndSortWithinPartitions函数是repartition函数的变种,与repartition函数不同的是,repartitionAndSortWithinPartitions在给定的partitioner内部进行排序,性能比repartition要高。
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//单词聚合
val rdd2 = rdd1.reduceByKey(_+_)
//按指定规则重新进行分区并在partition内部排序
rdd2.repartitionAndSortWithinPartitions(new HashPartitioner(3)).collect
22、mapValues
mapValues
针对于(K,V)形式的类型只对V进行操作
需求:单词统计
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
rdd1.groupByKey.mapValues(_.sum).collect
//结果:Array((scala,1), (is,1), (python,1), (language,1), (hello,3), (java,1), (world,2), (good,1))
23、subtract
def subtract(other: RDD[T]): RDD[T]
返回在RDD中出现,并且不在otherRDD中出现的元素,不去重。求差集

val rdd1 = sc.parallelize(1 to 7)
val rdd2 = sc.parallelize(3 to 9)
rdd1.subtract(rdd2).collect
//结果:Array(1, 2)
2.2.3、Action算子
2.2.3.1、常用Action算子介绍
官网所有action算子:http://spark.apache.org/docs/2.2.0/rdd-programming-guide.html#actions
Action算子真正触发任务计算
常用action算子:
| 动作 | 含义 |
|---|---|
| reduce(func) | reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数func |
2.2.3.2、常用action算子操作示例
1、reduce
reduce(func)
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
val data1 = Array(1,2,3,4,5)
val rdd1 = sc.parallelize(data1)
rdd1.reduce(_+_)
//结果:15
val data2 = Array("a","b","c","d")
val rdd2 = sc.parallelize(data2)
val rdd3 = rdd2.map((_,1))
rdd3.reduce((x,y)=>(x._1+y._1,x._2+y._2))
//结果:(abcd,4)
2、collect
collect
在驱动程序中,以数组的形式返回数据集的所有元素
val data1 = Array(1,2,3,4,5)
val rdd1 = sc.parallelize(data1)
rdd1.collect
//结果:Array(1,2,3,4,5)
3、count
count
返回RDD的元素个数
val data1 = Array(1,2,3,4,5)
val rdd1 = sc.parallelize(data1)
rdd1.count
//结果:5
4、first
first
返回RDD的第一个元素(类似于take(1))
val data1 = Array(1,2,3,4,5)
val rdd1 = sc.parallelize(data1)
rdd1.first
//结果:1
5、take
take
返回一个RDD的前n个元素组成的数组
val data1 = Array(1,2,3,4,5)
val rdd1 = sc.parallelize(data1)
rdd1.take(3)
//结果:Array(1,2,3)
6、saveAsTextFile
saveAsTextFile
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//单词聚合
val rdd2 = rdd1.reduceByKey(_+_)
//保存单词统计结果到hdfs
rdd2.saveAsTextFile("hdfs://hadoop01:9000/out")
7、saveAsSequenceFile
saveAsSequenceFile
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//单词聚合
val rdd2 = rdd1.reduceByKey(_+_)
//保存单词统计结果到hdfs
rdd2.saveAsSequenceFile("hdfs://hadoop01:9000/out")
8、saveAsObjectFile
saveAsObjectFile
将数据集的元素,以 Java 序列化的方式保存到指定的目录下
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//单词聚合
val rdd2 = rdd1.reduceByKey(_+_)
//保存单词统计结果到hdfs
rdd2.saveAsObjectFile("hdfs://hadoop01:9000/out")
9、countByKey
countByKey()
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//单词聚合
val rdd2 = rdd1.countByKey()
//结果: Map(is -> 1, good -> 1, world -> 2, java -> 1, language -> 1, scala -> 1, python -> 1, hello -> 3)
10、foreach
foreach
在数据集的每一个元素上,运行函数func
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//打印rdd1的元素
rdd1.foreach(println)

11、foreachPartition
foreachPartition
在数据集的每一个分区上,运行函数func
val data = Array("hello java hello world","hello scala","python is world good language")
//进行单词切割、压平、出现一个单词记做1
val rdd1 = sc.parallelize(data).flatMap(_.split(" ")).map((_,1))
//打印rdd1的元素
rdd1.foreachPartition(x=>println(x.toBuffer))
![]()
2.2.4、数值RDD的统计操作
Spark 对包含数值数据的 RDD 提供了一些描述性的统计操作。 Spark 的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建出模型。这些 统计数据都会在调用 stats() 时通过一次遍历数据计算出来,并以 StatsCounter 对象返回。
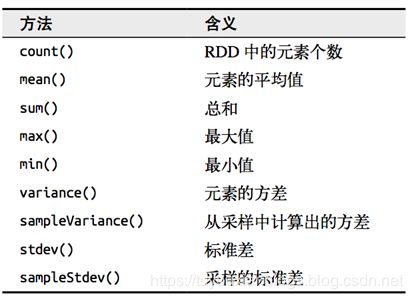
val rdd1 = sc.parallelize(1 to 100)
rdd1.sum
rdd1.max
rdd1.min
3、通过spark实现点击流日志分析
3.1、创建maven工程,导入依赖
<properties>
<scala.version>2.11.12scala.version>
<spark.version>2.2.0spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>3.1.1version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>mainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
3.2、统计访问的PV
PV:page view 页面浏览量
import org.apache.spark.{SparkConf, SparkContext}
object PVCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("pv")
//1、创建sparkContext
val sc = new SparkContext(conf)
//2、读取文件
val rdd1 = sc.textFile("F:\\access.log")
//3、统计次数
val pvcount = rdd1.count()
println(pvcount)
}
}
3.3、统计访问的UV
UV:unique pageview 今天一共有多少人来访问了
import org.apache.spark.{SparkConf, SparkContext}
/**
* 统计用户访问量
*/
object UVCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("uv")
//1、创建sparkContext
val sc = new SparkContext(conf)
//2、读取文件
val rdd1 = sc.textFile("F:\\access.log")
//3、取出ip
val ips = rdd1.map(_.split(" ")(0))
//4、去重
val rdd5 = ips.distinct()
//5、统计数量
val uvcount = rdd5.count()
println(uvcount)
}
}
3.4、统计url refrence topN
url refrence topN:上一级的url从哪里来的,httpRefer的统计
import org.apache.spark.{SparkConf, SparkContext}
/**
* 统计refrence url个数,取出最多的五个
*/
object TopN {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("pv")
//1、创建sparkContext
val sc = new SparkContext(conf)
//2、读取文件
val rdd1 = sc.textFile("F:\\access.log")
//3、取出refrence url
//先按照空格切割
val rdd2 = rdd1.map(_.split(" "))
//过滤出不符合规则的数据,refrence url位于第10位,所有需要将长度小于11的数据过滤掉,并且将refrence url为-的数据也过滤掉
val rdd3 = rdd2.filter(x=>x.length>10 && x(10)!="\"-\"")
//取出refrence url
val rdd4 = rdd3.map(x=>(x(10),1))
//统计refrence url出现的次数并排序
val rdd5 = rdd4.reduceByKey(_+_).sortBy(_._2,false)
//取出前五的refrene url
println(rdd5.take(5).toBuffer)
}
}
4、通过Spark实现ip地址查询
在互联网中,我们经常会见到城市热点图这样的报表数据,例如在百度统计中,会统计今年的热门旅游城市、热门报考学校等,会将这样的信息显示在热点图中。
因此,我们需要通过日志信息(运行商或者网站自己生成)和城市ip段信息来判断用户的ip段,统计热点经纬度。
代码实现:
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 通过spark定位ip经纬度
*/
object IpLocation {
/**
* 将ip转换为long
* @param ip
* @return
*/
def ipToLong(ip:String):Long = {
val ipNum = ip.split("\\.")
var resultNum:Long = 0
ipNum.foreach(num=>{
resultNum = num.toLong | resultNum <<8L
})
resultNum
}
/**
* 通过二分查找法查找ip所属基站
* @param iplong
* @param ipValues
* @return
*/
def binaryFindIp(iplong: Long, ipValues: Array[(Long, Long, String, String)]): Int = {
//开始位坐标
var startIndex = 0
//结束为坐标
var endIndex = ipValues.length
while (startIndex<=endIndex){
//获取中间坐标
val tmpIndex = (endIndex + startIndex) / 2
//判断是否在起始值与结束值之间
if(iplong>=ipValues(tmpIndex)._1 && iplong<= ipValues(tmpIndex)._2){
return tmpIndex
//如果小于起始值,那么需要将当前index作为endIndex
}else if(iplong {
val arr = x.split("\\|")
(arr(2).toLong, arr(3).toLong, arr(arr.length - 2), arr(arr.length - 1))
})
//将字段文件广播出去
val bcIp = context.broadcast(dictIp.collect())
//2、读取日志数据,获取ip地址
val logFile = context.textFile("F:\\20090121000132.394251.http.format")
val ips = logFile.map(_.split("\\|")(1))
//3、将ip地址转换为long类型后与字典数据进行比较,找到ip所属基站
val longLatRdd = ips.mapPartitions(it=>{
//取出广播数据
val ipValues = bcIp.value
it.map(ip=>{
//将ip转换为Long
val iplong = ipToLong(ip)
//查找ip所处基站坐标
val index:Int = binaryFindIp(iplong,ipValues)
//经度
val longitude = ipValues(index)._3
//纬度
val latitude = ipValues(index)._4
((longitude,latitude),1)
})
})
//4、统计基站连接人数
val result: RDD[((String, String), Int)] = longLatRdd.reduceByKey(_+_)
//5、将结果数据写入mysql
result.foreachPartition(it=>{
it.foreach(element =>{
val longitude = element._1._1
val latitude =element._1._2
var connection:Connection = null
var statement:PreparedStatement = null
try{
//获取数据库链接
connection = DriverManager.getConnection("jdbc:mysql://hadoop01:3306/spark")
statement = connection.prepareStatement("insert into iplocaltion values(?,?,?)")
//参数设置
statement.setString(1,longitude)
statement.setString(2,latitude)
statement.setInt(3,element._2)
statement.execute()
}catch {
case e:Exception=> None
}finally {
if(statement!=null)
statement.close()
if(connection!=null)
connection.close()
}
})
})
}
}
5、RDD的依赖关系
RDD的依赖
RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide
dependency)。
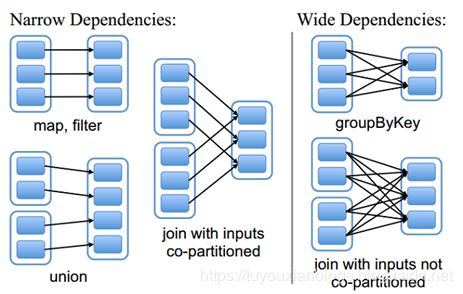
窄依赖:
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女
宽依赖:
宽依赖指的是多个子RDD的partition会依赖同一个父RDD的partition
总结:宽依赖我们形象的比喻为超生
血统[Lineage]:
RDD只支持粗粒度转换,即只记录单个块上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
6、RDD的缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或者缓存数据集。当持久化某个RDD后,每一个节点都将把计算分区结果保存在内存中,对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
6.1、RDD的缓存方式
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在objectStorageLevel中定义的。

缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
7、DAG的生成
7.1、 什么是DAG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段)。对于窄依赖,partition的转换处理在一个Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。

8、spark任务调度
8.1、任务调度流程图
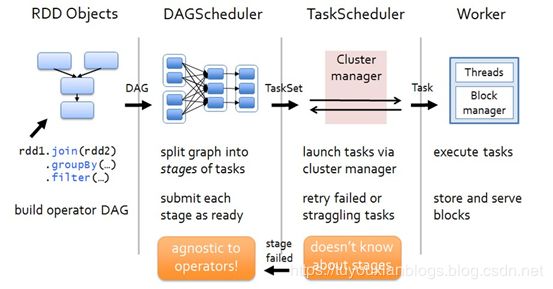
各个RDD之间存在着依赖关系,这些依赖关系就形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分。DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,最后在Worker节点上启动task。
8.2、DAGScheduler
(1)DAGScheduler对DAG有向无环图进行Stage划分。
(2)记录哪个RDD或者 Stage 输出被物化(缓存),通常在一个复杂的shuffle之后,通常物化一下(cache、persist),方便之后的计算。
(3)重新提交shuffle输出丢失的stage(stage内部计算出错)给TaskScheduler
(4)将 Taskset 传给底层调度器
a)– spark-cluster TaskScheduler
b)– yarn-cluster YarnClusterScheduler
c)– yarn-client YarnClientClusterScheduler
8.3、TaskScheduler
(1)为每一个TaskSet构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
(2)数据本地性决定每个Task最佳位置
(3)提交 taskset( 一组task) 到集群运行并监控
(4)推测执行,碰到计算缓慢任务需要放到别的节点上重试
(5)重新提交Shuffle输出丢失的Stage给DAGScheduler
9、RDD容错机制之checkpoint
9.1、为什么需要checkpoint
(1)、Spark 在生产环境下经常会面临transformation的RDD非常多(例如一个Job中包含1万个RDD)或者具体transformation的RDD本身计算特别复杂或者耗时(例如计算时长超过1个小时),这个时候就要考虑对计算结果数据持久化保存;
(2)、Spark是擅长多步骤迭代的,同时擅长基于Job的复用,这个时候如果能够对曾经计算的过程产生的数据进行复用,就可以极大的提升效率;
(3)、如果采用persist把数据放在内存中,虽然是快速的,但是也是最不可靠的;如果把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏,系统管理员可能清空磁盘。
(4)、Checkpoint的产生就是为了相对而言更加可靠的持久化数据,在Checkpoint的时候可以指定把数据放在本地,并且是多副本的方式,但是在生产环境下是放在HDFS上,这就天然的借助了HDFS高容错、高可靠的特征来完成了最大化的可靠的持久化数据的方式;
假如进行一个1万个算子操作,在9000个算子的时候persist,数据还是有可能丢失的,但是如果checkpoint,数据丢失的概率几乎为0。
9.2、checkpoint的原理
当RDD使用cache机制从内存中读取数据,如果数据没有读到,会使用checkpoint机制读取数据。此时如果没有checkpoint机制,那么就需要找到父RDD重新计算数据了,因此checkpoint是个很重要的容错机制。
checkpoint就是对于一个RDD chain(链)如果后面需要反复使用某些中间结果RDD,可能因为一些故障导致该中间数据丢失,那么就可以针对该RDD启动checkpoint机制,使用checkpoint首先需要调用sparkContext的setCheckpointDir方法,设置一个容错文件系统目录,比如hdfs,然后对RDD调用checkpoint方法。之后在RDD所处的job运行结束后,会启动一个单独的job来将checkpoint过的数据写入之前设置的文件系统持久化,进行高可用。所以后面的计算在使用该RDD时,如果数据丢失了,但是还是可以从它的checkpoint中读取数据,不需要重新计算。
9.3、checkpoint与persist和cache的区别
persist或者cache与checkpoint的区别在于,前者持久化只是将数据保存在BlockManager中但是其lineage是不变的,但是后者checkpoint执行完后,rdd已经没有依赖RDD,只有一个checkpointRDD,checkpoint之后,RDD的lineage就改变了。persist或者cache持久化的数据丢失的可能性更大,因为可能磁盘或内存被清理,但是checkpoint的数据通常保存到hdfs上,放在了高容错文件系统。
10、spark运行架构
10.1、spark运行基本流程
Spark运行基本流程参见下面示意图:

(1)、构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
(2)、资源管理器分配Executor资源并启动Executor,Executor运行情况将随着心跳发送到资源管理器上;
(3)、Executor向SparkContext申请Task,
(4)、SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。
(5)、Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
(6)、Task在Executor上运行,运行完毕释放所有资源。
10.2、spark运行架构的特点
Spark运行架构特点:
1、每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。
2、Spark任务与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
3、提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark程序运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
4、Task采用了数据本地性和推测执行的优化机制。
11、数据读取与保存的主要方式
11.1、文本文件的输入输出
当我们将一个文本文件读取为 RDD 时,输入的每一行 都会成为RDD的一个元素。也可以将多个完整的文本文件一次性读取为一个pair RDD, 其中键是文件名,值是文件内容。
val input = sc.textFile("./README.md")
如果传递目录,则将目录下的所有文件读取作为RDD。文件路径支持通配符。
通过wholeTextFiles()对于大量的小文件读取效率比较高,大文件效果没有那么高。
Spark通过saveAsTextFile() 进行文本文件的输出,该方法接收一个路径,并将 RDD 中的内容都输入到路径对应的文件中。Spark 将传入的路径作为目录对待,会在那个 目录下输出多个文件。这样,Spark 就可以从多个节点上并行输出了。
val readme = sc.textFile("./README.md")
readme.collect()
//Array[String] = Array(# Apache Spark, "", Spark is a fast and general cluster...
readme.saveAsTextFile("hdfs://hadoop01:9000/test")
11.2、json文件的输入输出
如果JSON文件中每一行就是一个JSON记录,那么可以通过将JSON文件当做文本文件来读取,然后利用相关的JSON库对每一条数据进行JSON解析。
import org.json4s._
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization
var result = sc.textFile("examples/src/main/resources/people.json")
implicit val formats = Serialization.formats(ShortTypeHints(List()))
result.collect()
//Array({"name":"Michael"}, {"name":"Andy", "age":30}, {"name":"Justin", "age":19})
如果JSON数据是跨行的,那么只能读入整个文件,然后对每个文件进行解析。
JSON数据的输出主要是通过在输出之前将由结构 化数据组成的 RDD 转为字符串 RDD,然后使用 Spark 的文本文件 API 写出去。 说白了还是以文本文件的形式存,只是文本的格式已经在程序中转换为JSON。
11.3、CSV文件输入输出
读取 CSV/TSV 数据和读取 JSON 数据相似,都需要先把文件当作普通文本文件来读取数据,然后通过将每一行进行解析实现对CSV的读取。
CSV/TSV数据的输出也是需要将结构化RDD通过相关的库转换成字符串RDD,然后使用 Spark 的文本文件 API 写出去。
11.4、SequenceFile文件输入输出
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。
Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext 中,可以调用 sequenceFile [keyClass, valueClass](path)。

val data=sc.parallelize(List((2,"aa"),(3,"bb"),(4,"cc"),(5,"dd"),(6,"ee")))
data.saveAsSequenceFile("hdfs://node01:8020/sequdata")
val sdata = sc.sequenceFile[Int,String]("hdfs://node01:8020/sdata/p*")
sdata.collect()
//Array[(Int, String)] = Array((2,aa), (3,bb), (4,cc), (5,dd), (6,ee))
可以直接调用 saveAsSequenceFile(path) 保存你的PairRDD,它会帮你写出数据。需要键和值能够自动转为Writable类型。
11.5、对象文件输入输出
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。
可以通过objectFile[k,v](path) 函数接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile() 实现对对象文件的输出。因为是序列化所以要指定类型。
val data=sc.parallelize(List((2,"aa"),(3,"bb"),(4,"cc"),(5,"dd"),(6,"ee")))
data.saveAsObjectFile("hdfs://node01:8020/objfile")
import org.apache.spark.rdd.RDD
val objrdd:RDD[(Int,String)] = sc.objectFile[(Int,String)]("hdfs://node01:8020/objfile/p*")
objrdd.collect()
//Array[(Int, String)] = Array((2,aa), (3,bb), (4,cc), (5,dd), (6,ee))
11.6、hadoop文件的输入输出
Spark的整个生态系统与Hadoop是完全兼容的,所以对于Hadoop所支持的文件类型或者数据库类型,Spark也同样支持.另外,由于Hadoop的API有新旧两个版本,所以Spark为了能够兼容Hadoop所有的版本,也提供了两套创建操作接口.对于外部存储创建操作而言,hadoopRDD和newHadoopRDD是最为抽象的两个函数接口,主要包含以下四个参数.
1) 输入格式(InputFormat): 制定数据输入的类型,如TextInputFormat等,新旧两个版本所引用的版本分别是org.apache.hadoop.mapred.InputFormat和org.apache.hadoop.mapreduce.InputFormat(NewInputFormat)
2) 键类型: 指定[K,V]键值对中K的类型
3) 值类型: 指定[K,V]键值对中V的类型
4) 分区值: 指定由外部存储生成的RDD的partition数量的最小值,如果没有指定,系统会使用默认值defaultMinSplits
其他创建操作的API接口都是为了方便最终的Spark程序开发者而设置的,是这两个接口的高效实现版本.例如,对于textFile而言,只有path这个指定文件路径的参数,其他参数在系统内部指定了默认值
val data = sc.parallelize(Array((30,"hadoop"), (71,"hive"), (11,"cat")))
data.saveAsNewAPIHadoopFile("hdfs://node01:8020/output4/",classOf[LongWritable] ,classOf[Text] ,classOf[org.apache.hadoop.mapreduce.lib.output.TextOutputFormat[LongWritable, Text]])
11.7、文件系统的输入输出
Spark 支持读写很多种文件系统, 像本地文件系统、Amazon S3、HDFS等。
11.8、数据库的输入输出
关系型数据库连接
支持通过Java JDBC访问关系型数据库。需要通过JdbcRDD进行,示例如下:
傻瓜式写入mysql:
val rdd = sc.parallelize(Seq[Int](1201,1202,1203,1204,1205),3)
val rdd1 = rdd.mapPartitions(
it => {
var connection: Connection = null
var statement: PreparedStatement = null
val result = List[(String,Int)]()
try {
while (it.hasNext) {
connection = DriverManager.getConnection("jdbc:mysql://node01:3306/userdb","root","123456")
statement = connection.prepareStatement("select name,salary from emp where id = ?")
statement.setInt(1,it.next())
val resultSet: ResultSet = statement.executeQuery()
while(resultSet.next()){
val name = resultSet.getString(1)
val age = resultSet.getInt(2)
println(s"name=====${name},age========@${age}")
result.+:(name->age)
}
}
result.toIterator
} catch {
case e: Exception => result.toIterator
} finally {
if (statement != null)
statement.close()
if (connection != null)
connection.close()
}
}
).collect()
}
mysql读取:
def main (args: Array[String] ) {
val sparkConf = new SparkConf ().setMaster ("local[2]").setAppName ("JdbcApp")
val sc = new SparkContext (sparkConf)
val rdd = new org.apache.spark.rdd.JdbcRDD (
sc,
() => {
Class.forName ("com.mysql.jdbc.Driver").newInstance()
java.sql.DriverManager.getConnection ("jdbc:mysql://localhost:3306/rdd", "root", "hive")
},
"select * from rddtable where id >= ? and id <= ?;",
1,
10,
1,
r => (r.getInt(1), r.getString(2)))
println (rdd.count () )
rdd.foreach (println (_) )
sc.stop ()
}
mysql写入:
def main(args: Array[String]) {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("HBaseApp")
val sc = new SparkContext(sparkConf)
val data = sc.parallelize(List("Female", "Male","Female"))
data.foreachPartition(insertData)
}
def insertData(iterator: Iterator[String]): Unit = {
Class.forName ("com.mysql.jdbc.Driver").newInstance()
val conn = java.sql.DriverManager.getConnection("jdbc:mysql://localhost:3306/rdd", "root", "admin")
iterator.foreach(data => {
val ps = conn.prepareStatement("insert into rddtable(name) values (?)")
ps.setString(1, data)
ps.executeUpdate()
})
}
JdbcRDD 接收这样几个参数。
• 首先,要提供一个用于对数据库创建连接的函数。这个函数让每个节点在连接必要的配 置后创建自己读取数据的连接。
• 接下来,要提供一个可以读取一定范围内数据的查询,以及查询参数中lowerBound和 upperBound 的值。这些参数可以让 Spark 在不同机器上查询不同范围的数据,这样就不 会因尝试在一个节点上读取所有数据而遭遇性能瓶颈。
• 这个函数的最后一个参数是一个可以将输出结果从转为对操作数据有用的格式的函数。如果这个参数空缺,Spark会自动将每行结果转为一个对象数组。
总结:
- 替换try{}catch{}的方法
