MySQL5.7导入数据到ElasticSearch6.2.4
MySQL版本:5.7.23
ElesticSearch版本:6.2.4
服务器系统:CentOS7
最近导师交给我一个大鸡吧的任务,把MySQL中微博爬虫下来的数据存到ES,为了接下来的舆情文本分析。
在网上找了一圈有以下几种方法:
1、elasticsearch-jdbc(git主页地址:https://github.com/jprante/elasticsearch-jdbc)
我看最新更新还是两年前,最高支持es版本才2.3.4,pass
2、kafka
虽然会用,但是感觉很麻烦啊,pass
3、logstash-jdbc
版本ok,开搞。
--------------------------------------------------------skr 分割线 skr----------------------------------------------------------
1、安装logstash-input-jdbc插件前需要安装logstash
打开iterm连接服务器,然后就是一句话(一菊花)的事儿:
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.zip
解压一波:unzip logstash-6.2.4.zip
2、开始安装主角了:logstash-input-jdbc插件
cd /home/software/logstash-6.2.4/bin
./logstash-plugin install logstash-input-jdbc

看到这一幕,就是插件安装完成啦。
ps:看有的博客说原生的源不行,要换某宝的,我准备先试试看是不是不行,结果我笑了,安装的是异常的流畅
3、编写配置文件(jdbc.sql和jdbc.conf,建议在bin目录下vim jdbc.conf)
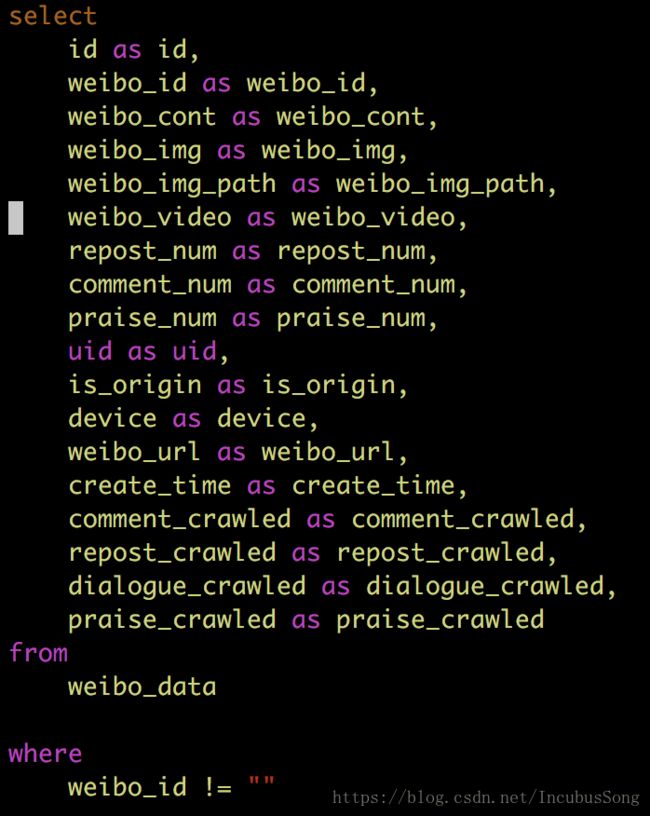
① jdbc.sql:这个就不多说了,正儿八经的sql语句,根据自己的情况去写啦
②下载MySQL连接驱动包
对应好自己的MySQL版本哈,我的是5.7的版本,所以我也就下5.1的驱动包
附上某盘的地址,方便大家嗨皮:https://pan.baidu.com/s/1YauAXVIZegpIr0pFgDz79Q
Summary of Connector/J Versions
| Connector/J version | Driver Type | JDBC version | MySQL Server version | Status |
|---|---|---|---|---|
| 5.1 | 4 | 3.0, 4.0, 4.1, 4.2 | 4.1, 5.0, 5.1, 5.5, 5.6, 5.7 | Recommended version |
| 5.0 | 4 | 3.0 | 4.1, 5.0 | Released version |
| 3.1 | 4 | 3.0 | 4.1, 5.0 | Obsolete |
| 3.0 | 4 | 3.0 | 3.x, 4.1 | Obsolete |
Summary of Connector/J Versions
| Connector/J version | JDBC version | MySQL Server version | JRE Supported | JDK Required for Compilation | Status |
|---|---|---|---|---|---|
| 6.0 | 4.2 | 5.5, 5.6, 5.7 | 1.8.x | 1.8.x | Developer Milestone |
| 5.1 | 3.0, 4.0, 4.1, 4.2 | 4.1, 5.0, 5.1, 5.5, 5.6*, 5.7* | 1.5.x, 1.6.x, 1.7.x, 1.8.x* | 1.5.x and 1.8.x | Recommended version |
③编写jdbc.conf,这是连接你们的mysql和es的账户密码索引表等等的信息
直接复制黏贴版代码:
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.1.85:3306/weibo?characterEncoding=UTF-8&useSSL=false&autoReconnect=true"
jdbc_user => "root"
jdbc_password => "root"
jdbc_driver_library => "/usr/local/logstash/config/mysql-connector-java-5.1.47.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
jdbc_default_timezone => "Asia/Shanghai"
statement_filepath => "/usr/local/logstash/bin/jdbc.sql"
schedule => "* * * * *"
type => "jdbc"
}
}
output {
elasticsearch {
hosts => "192.168.1.79:9200"
protocol => "http"
index => "opinion_system"
document_type => "opinion_type"
document_id => "%{id}"
}
}
解释版代码:
input {
jdbc {
# 连接的数据库地址和哪一个数据库,指定编码格式,禁用SSL协议,设定自动重连
jdbc_connection_string => "jdbc:mysql://192.168.1.85:3306/weibo?characterEncoding=UTF-8&useSSL=false&autoReconnect=true"
# 你的账户密码
jdbc_user => "root"
jdbc_password => "root"
# 连接数据库的驱动包,建议使用绝对地址
jdbc_driver_library => "/usr/local/logstash/config/mysql-connector-java-5.1.47.jar"
# 这是不用动就好
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
jdbc_default_timezone => "Asia/Shanghai"
statement_filepath => "/usr/local/logstash/bin/jdbc.sql"
# 这是控制定时的,重复执行导入任务的时间间隔,第一位是分钟
schedule => "* * * * *"
type => "jdbc"
}
}
output {
elasticsearch {
# 要导入到的Elasticsearch所在的主机
hosts => "192.168.1.79:9200"
protocol => "http"
# 要导入到的Elasticsearch的索引的名称
index => "opinion_system"
# 类型名称(类似数据库表名)
document_type => "opinion_type"
# 类型名称(类似数据库表名)
document_id => "%{id}"
}
}
4、开始导入
./logstash -f jdbc.conf

-----------------------------------------------------------skr 分割线 skr-----------------------------------------------------------------------
这里遇到一个小问题

把配置文件jdbc.conf里面的protocol注释掉即可