第一章 数据类型趣谈
目录
1 值类型与引用类型
1.1 线程堆栈和托管堆
1.2 引用类型变量的内存模型
1.3 “=” 和 “==” 辨析
1.4 装箱与拆箱
2 说不尽的字符串
3 数据类型的模板化——泛型
1 值类型与引用类型
1.1 线程堆栈和托管堆
值类型:int、double、enum、struct
引用类型:类、接口、数组、委托、String
值类型变量与引用型变量的内存分配模型不同。分为“线程堆栈(Thread Stack)”和“托管堆(Managed Heap)”。
每个正在运行的程序都有一个“进程(Process)”,在一个进程内部,可以存在多个“线程(Thread)”,每个线程都拥有一个“线程堆栈”,大小为1MB。
值类型的变量所占用的内存单元是在线程堆栈中分配的。
引用类型变量引用的对象所占用的内存是在托管堆中分配的。
注:在.NET的托管环境下,堆由CLR进行管理,所以将其称为“托管堆”。用new关键字创建对象时,分配给对象的内存单元就位于托管堆中。
1.2 引用类型变量的内存模型
在C#程序中,我们可以使用new关键字创建多个对象,因此托管堆中的内存资源是可以动态申请并使用的,但用完需要释放。
下面通过一个实列来介绍引用类型变量的内存模型:
private void TestFunc()
{
MyClass obj;
obj = new MyClass();
}创建MyClass对象的代码:
class MyClass
{
public int Value;
public int[] Numbers = new int[10];
}此时内存对象模型如图所示。
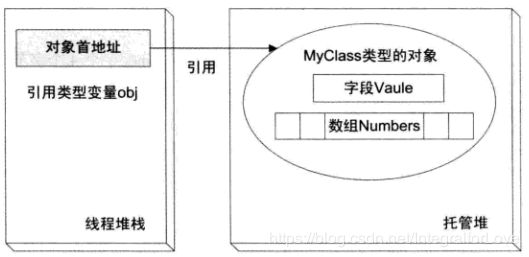
引用类型变量obj “生存” 于线程堆栈中(因为它是TestFunc方法的局部变量),而MyClass对象则生存与托管堆中,obj 所代表的位于线程堆栈中的内存单元保存了托管堆中MyClass对象的首地址。
(注:引用类型对象一般分为两部分:对象引用和对象实列。对象引用存放在栈中,程序使用该引用访问堆中的对象实例;对象实例存放在堆中,里面包含对象的数据内容)
1.3 “=” 和 “==” 辨析
引用类型赋值
MyClass obj1 = new MyClass() { Value = 100 };
MyClass obj2 = null;
obj2 = obj1; // 引用类型变量的赋值
Console.WriteLine("obj2.Value = " + obj2.Value); // 输出obj2.Value = 100;整个过程可以用下图来说明:
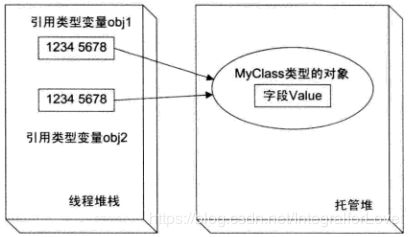
两个引用类型变量的相互赋值不会导致它们所引用的对象自身被复制,其结果是这两个引用类型的变量引用同一对象。可以看出,引用类型变量赋值后,对两个变量中任何一个操作,都会影响另外一个,这种情况会发生在引用类型 “传参” 过程中。
对象相等判断
当 “==” 施加于两个引用类型的变量时:
MyClass TheFirst = new MyClass();
MyClass TheSecond = new MyClass();
Console.WriteLine(TheFirst == TheSecond); // False
TheSecond = TheFirst; // 引用相同对象(即两个对象引用指向堆中同一个实例)
Console.WriteLine(TheFirst == TheSecond); // True注:虽然String是引用类型,但当使用 “==” 比较两个 String 变量时,判断是否包含相同的字符串。(String类型重载了 “==” 运算符,使得String类型看上去很像 “值类型”)
传参
所谓 “传参” ,其实就是赋值,将实参赋给形参。引用类型传参后,实参和形参指向的是堆中同一个实例,使用形参操作堆中的实例,直接能影响到实参指向的实例;而值类型传参后,形参是实参的一个副本,形参和实参包含有相同的内容,一般对形参进行的操作不会影响到实参。
static void Main(string[] args)
{
int NumA = 20, NumB = 100;
MyClass objRef = new MyClass() { Value = 100 };
objRef.Add(NumA, NumB);
Console.WriteLine("值类型传参:{0}", NumB); // 100
objRef.Add(NumA, objRef); // 引用类型传参
Console.WriteLine("引用类型传参:{0}", objRef.Value); // 120
}
class MyClass
{
public int Value;
public void Add(int a, int b)
{
b = a + b;
}
public void Add(int a, MyClass _obj)
{
_obj.Value = a + _obj.Value;
}
}引用类型传参和值类型传参各有优点,可以分场合使用不同的类型进行传参,有些时候我
们在调用方法时,希望方法在操作形参的时候,同时影响到实参,也就是说希望方法的调用能够对方法体外部变量起到效果,那么我们可以使用引用类型传参;如果仅仅是为了给方法传递一些必需的数值, 让方法能够正常运行,不需要方法的执行能够影响到外部变量,那么我们可以使用值类型(不包含引用类型成员) 传参。
浅复制
所谓“浅复制”,类似值类型赋值, 将源对象的成员一一进行拷贝,生成一个全新的对象。新对象与源对象包含相同的组成,值类型赋值就是一种“浅复制”。
浅复制发生时,简单值类型成员直接一一赋值,引用类型成员直接一一赋值,复合值类型成员由于本身可以再包含其它的成员,所以需要递归赋值。
static void Main(string[] args)
{
MyClass objRef1 = new MyClass(50);
MyClass objRef2 = objRef1;
MyClass objRef3 = objRef1.Clone();
objRef1.Value = 200;
Console.WriteLine("objRef2.Value = {0}", objRef2.Value); // objRef2.Value = 200
Console.WriteLine("objRef3.Value = {0}", objRef3.Value); // objRef2.Value = 50
}
class MyClass
{
public int Value;
public MyClass(int Value)
{
this.Value = Value;
}
public MyClass Clone()
{
return new MyClass(Value);
}
}要想复制出来的副本与源对象彻底断绝关联,那么需要将源对象成员(包括所有直接成员和间接成员) 中所有的引用类型成员全部进行浅复制,如果引用类型成员本身还包括自己的引用类型成员,那么必须依次递归进行浅复制, 由上向下递归进行浅复制的过程叫“深复制”。
深复制
“浅复制”仅仅是将对象成员进行一一赋值, 而无论成员是简单值类型、复合值类型还是引用类型,这就造成了一个问题:当一个对象包含有引用类型成员(包括直接成员和间接成员)时,浅复制出来的副本内部与源对象内部都包含一个指向堆中同一实例的引用。要想避免此问题,对象在进行浅复制时, 如果存在引用类型成员,不能直接赋值,必须对该引用类型成员再进行浅复制, 如果该引用类型成员本身还包含引用类型成员,必须依次递归进行浅复制。
static void Main(string[] args)
{
MyClass objRef1 = new MyClass(50,new int[]{1,2,3});
MyClass objRef2 = objRef1;
MyClass objRef3 = objRef1.Clone();
objRef1.Value = 200;
objRef1.Numbers[0] = 9;
Console.WriteLine("objRef2.Value = {0},objRef2.Numbers[0] = {1}", objRef2.Value, objRef2.Numbers[0]);
Console.WriteLine("objRef3.Value = {0},objRef3.Numbers[0] = {1}", objRef3.Value, objRef3.Numbers[0]);
// objRef2.Value = 200,objRef2.Numbers[0] = 9
// objRef3.Value = 50,objRef3.Numbers[0] = 9
}
class MyClass
{
public int Value;
public int[] Numbers = new int[3];
public MyClass(int Value,object Ref)
{
this.Value = Value;
this.Numbers = Ref as int[]; // 安全的引用类型转换(失败返回Null)
}
public MyClass Clone() // 浅复制
{
return new MyClass(Value, Numbers);
}
}
如果引用类型成员中又包含其它引用类型成员,那么依次递归浅复制。
public MyClass Clone() // 深复制(递归浅复制)
{
return new MyClass(Value, Numbers.Clone());
}
// objRef2.Value = 200,objRef2.Numbers[0] = 9
// objRef3.Value = 50,objRef3.Numbers[0] = 11.4 装箱与拆箱
值类型到引用类型,称为 “装箱”;
引用类型到值类型,称为 “拆箱”;
int num = 123;
object obj = num; // 装箱
int value = (int)obj; // 拆箱
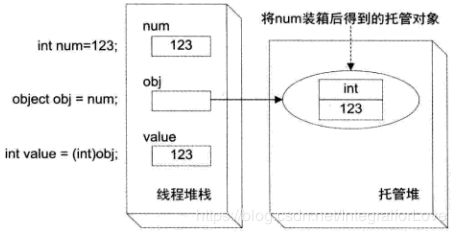
注:拆箱与装箱操作会影响程序的运行性能,因此需尽量避免操作。
栈中的存储是连续的,而堆中存储可以是随机的。
2 说不尽的字符串
String 类型的基类型是 Object,它是一个特殊的引用类型,它的判等不同于其它引用类型去比较对象引用是否指向堆中同一实例,而是和值类型判等一致,比较对象内容是否一一相等。 除此之外,String 类型还是不可改变类型,对 String 对象的任何操作均不能改变该对象。
注:C#中可用两个字符串类型,一个 “String”,另一个 “string”,大写的 String 指的是 System.String,即.NET公共语言规范所定义的字符串类型,而小写的 string 则是C#自己的字符串类型,但C#编译器将它映射到 System.String。所以,这两者其实是一样的。
3 数据类型的模板化——泛型
泛型的英文表述是 “generic”,这个单词意为 “通用的”。从字面意思可知,泛型代表的就是 “通用类型”,它可以代替任意的数据类型,使类型参数化,从而达到只实现一个方法就可以操作多种数据类型的目的。泛型将方法实现行为与方法操作的数据类型分离,实现了代码重用。
List intList = new List(); // 用int作为实际参数来初始化泛型参数
intList.Add(3); // 往列表中加入int型元素
List stringList = new List(); // 用string作为实际参数来初始化泛型参数
stringList.Add("Devin"); // 往列表中加入string元素 List
自定义泛型函数:
static void Add(T a, T b)
{
a.GetType();
b.GetType();
Console.WriteLine(a.GetType().ToString());
Console.WriteLine(b.GetType().ToString());
}
Add(50, 60); 
泛型除了可以实现代码重用外,还提供了更好的性能和类型安全。
static void testGeneric()
{
Stopwatch time = new Stopwatch();
List genericlist = new List();
time.Start();
for (int i = 1; i < 10000000; i++)
{
genericlist.Add(i); // 泛型测试
}
time.Stop();
TimeSpan ts = time.Elapsed;
Console.WriteLine("泛型类型运行时间:" + ts.TotalMilliseconds);
}
static void testNonGeneric()
{
Stopwatch time = new Stopwatch();
ArrayList arrayList = new ArrayList(); // 非泛型数组
time.Start();
for (int i = 1; i < 10000000; i++)
{
arrayList.Add(i); // 非泛型测试
}
time.Stop();
TimeSpan ts = time.Elapsed;
Console.WriteLine("非泛型类型运行时间:" + ts.TotalMilliseconds);
}
static void Main(string[] args)
{
testGeneric();
testNonGeneric();
} 
以上代码中,使用了Stopwatch类来对代码运行时间进行测量。比较泛型类型和非泛型类型的性能差异。
从图中两个运行时间可以明显看出,非泛型ArrayList的Add(object value)方法中,参数为object类型,当把int类型的参数传入时,会发生装箱操作,从而导致性能的损失,使运行时间变得更长。
泛型也可以保证类型安全。当你想泛型数组中添加string类型时,会造成 “无法从string转换为int” 的编译错误。