【无人驾驶】“自主代客泊车”/自动泊车方案调研 2
目录
智行者发布自主代客泊车(AVP)方案
中电昆辰“鹰眼”定位(射频定位、UWB)
百度自主泊车解决方案
纵目科技
驭势科技
纽劢科技
Momenta
魔视智能
吉利
魔视智能
戴姆勒和博世
【无人驾驶】“自主代客泊车”概述 1
自主泊车方案在自动驾驶领域,作为L4级别自动驾驶方案中的一个分支,自主泊车方案一方面整合了L4级别自动驾驶的技术,另一面由于场地的特殊性让其商业落地成为现实。
智行者发布自主代客泊车(AVP)方案
2019入秋前一天,智行者发布自主代客泊车(AVP)方案。
这是继纽劢科技、百度、Momenta之后今年第四家发布自主代客泊车方案的科技公司。
相比其他三家不同,智行者自主代客泊车方案主要强调基于增强视觉标签的AVP解决方案,该方案结合低成本车规级硬件方案与轻量级场端改造。
智行者采用的增强视觉标签式AVP解决方案在车端配置了4个环视相机、1个前视相机、12个超声波雷达和4个毫米波雷达。

对于传感器硬件来说,这些都是可量产的传感器组合,价格可控制在千元级别,其中某些具备L2级别的自动驾驶汽车已实现部分硬件标配(包括10万元级别的国产车型)。
据介绍,智行者提出的AVP解决方案基于增强型视觉标签进行车辆的全局路段规划、高精度定位、局部路径引导以及特殊路段语义信息标注,通过增强标签及云端调度进行轻量级场地升级,模拟出一套适用于任意停车场的完备交通系统。

其中,增强视觉标签式AVP解决方案由云端进行全局路段规划,规划路段可表示为S1-S2-S3(A5)(见上图)将增强标签直接作为表述协议,使用这种方式可以简单准确地进行全局路段表述。
同时,通过标签拓扑关系及检测到的标签信息,车辆能够时刻定位当前所在的全局位置。

该方案所使用的局部路径规划技术利用了增强型视觉标签的组合,将连续标签的组合视为用于定位导航的虚拟车道中心线,车辆根据虚拟车道中心线进行局部路径规划。
增强视觉标签式AVP解决方案使用基于鱼眼环视相机,拼接生成鸟瞰图像,利用基于深度学习的计算机视觉方法,实现对标签的实时精准检测和定位,对外部环境如光线强度等鲁棒性较强,目前在各种干扰条件下可以达到精确检测标签类型超过20个,其中包括导航信息标签及语义信息标签等。
在计算基础平台层面,智行者计算基础平台分为ECU层、操作系统层和中间件层,ECU层包括高性能平台和安全平台。

前者强调计算性能,后者强调安全性。
针对前者,采用POSIX OS和Adaptive AUTOSAR发挥多核性能、保证灵活性。
针对后者,采用OSEK OS和Classic AUTOSAR保障安全,自动驾驶系统层实行软件与算法分离设计。通过可视化配置,可以轻松将基础组件(算法)进行组合(架构),快速形成产品。
可以说,低成本车规级硬件方案搭配轻量级场端改造,智行者推出的这项增强视觉标签式AVP解决方案在保障安全第一性的基础上,以量产级与商业化为重要优势,真正做到了兼顾智能车辆环境适应能力与改造成本这两个重要的评价指标。
增强视觉标签式AVP的主要优势包括以下五个方面:
1、完备性:所使用的增强标签系统能够模拟车道线、交通标志及红绿灯信息,形成完备的交通系统,实现泊车过程中跟随、让行、避让、车位检测及泊车功能;
2、轻量级:无需对场地地面实体进行改造,不需要安装激光雷达、UWB等昂贵的非量产设备,预计改造成本1000元/万平米,真正做到了降低改造成本和量产阻力,方案可适用于露天、地下及多层停车场等基本停车场场景,场地适应性强;
3、量产级:复用车载环视相机、毫米波雷达及超声波雷达,硬件成本低,对车身外观无需特殊要求;
4、标准化:可以全方位监控车辆状态,对接至客户已有云端系统,实现监控数据全透明化,并且可以根据客户需求定制手机APP、云端管理系统;
5、商业化:无需进行场端实体改造,场端改造成本低,场地标签作业流程快速高效,每天可完成1万平米场地作业,无需高精度地图采集和日常维护,运营维护成本低。
为了完整展示智行者自主泊车功能方案,这次智行者公布了一段实拍自主泊车视频。
https://v.qq.com/x/page/t0910w59yn7.html
从视频来看,智行者通过对一辆北汽新能源ARCFOX的首款微型电动车LITE进行改装,使用者在停车场入口通过手机APP选择自主泊车功能,同时,结合远程监控和调度平台该车会进入自主驾驶状态,值得注意的是远程监控和调度平台是智行者自主泊车方案中特有的云端后台调度系统,这一系统是完全由智行者自主实现,可同时实现上百台车辆的整体调度。
进入停车场后,智驾君发现与其他家在场端自建高精度地图不同的是,智行者通过视觉增强标签系统的方式引导车辆自主行驶,方案中配合视觉增强标签系统使用,为智能车辆下发场地配置信息与目标车位信息,提高车辆寻路、找车位的效率,同时可以进行多车调度,提高了整体泊车效率,这样做的好处是无需场端激光雷达改造和视觉建图。
在这一方案中配合视觉增强标签系统使用,为智能车辆下发场地配置信息与目标车位信息,提高车辆寻路、找车位的效率,同时可以进行多车调度,提高了整体泊车效率
在停车场中,智行者团队对该车设计了两种常见场景:行人穿行、车辆自主避让。
当有人从车辆一段快速出现时,该车成功完成自主刹车功能,当人离开车辆正前方,车辆继续前行。
当车辆驶出车位时,如遇到前方有正在驶过的车辆,该车会自动停车等待,当车辆完全驶过,该车辆继续行驶。
有人从车辆一段快速出现时,该车成功完成自主刹车功能,当人离开车辆正前方,车辆继续前行。
根据对外公布的视频来看,智行者自主泊车方案中的车辆行驶较为平稳,在行驶过程中偶遇行人、车辆判断障碍物准确,在转弯是,车辆方向盘转动规律平稳。
据介绍,智行者公司内部组织独立团队投入AVP的研发已有一年时间,现阶段该低成本量产级方案已达到设计指标要求,希望下一步合作伙伴一起推动该方案的快速落地,最快的商业预计在2020年左右。
从智行者发布的方案来看,相比国内之前发布的自主代客泊车方案,智行者自主代客泊车(AVP)方案主要优势在于我们结合了车端改造与场端改造的优势,使用轻量级场端改造,配合云端后台调度,不引入激光雷达、UWB等昂贵传感器。
同时在车端使用低成本车规级硬件方案,提高智能车辆环境适应能力,在环境适应能力与改造成本的平衡中取最优值,无需高精度地图,后期运营和维护成本低。
智行者联合创始人/技术研发部高级副总监张放表示,“视觉增强标签系统是我们这一方案的特色,从想法提出到实施完全由我们团队自主完成,我们不使用高精度地图的原因主要是,地图的采集与场端变化所造成的日常维护相对来说成本比较昂贵,并且在进行高精度地图匹配时,如果使用如果采用激光雷达传感器,那么会大大提高成本,如果采用摄像头传感器,那么会比较依赖外界光线条件。我们的视觉增强标签系统的定位精度是在厘米级的,相对于高精度地图的方案在成本和使用效果方面都有相当的优势。这一方案如果说弊端的话,就是在标签张贴上需要与停车场进行协调,与系统所带来的方便快捷相比,可以说是几乎没有什么推广压力了。"
目前,行业普遍认可的自动驾驶商业落地需要从4个维度进行考量:封闭场景/开放场景、固定路线/自由路线、低速/高速、车内有乘客/车内无乘客。
如果对这4个维度的8项条件进行整合,可以发现自主泊车将是L4级别自动驾驶中最先实现商用化的一项功能。
目前,国内外互联网科技巨头、传统车企和创业公司纷纷投身汽车智能化变革,提出了多种自动化驾驶解决方案实现自主代客泊车,可大致分为以下两类:
以场端改造为主的技术方案:该方案将激光雷达、UWB等传感器安装在停车场,车辆仅需具备电子制动、自动换挡、电子助力转向及远程互联功能即可。但由于其场端改造的建设和维护成本较高,目前仅有一些示范性演示,难以大规模推广。
以车端改造为主的技术方案:该方案主要利用车载视觉或激光雷达等传感器用于高精度建图、定位和障碍物检测。其不足之处为:依赖高精度地图,需要专业地图供应商介入,采集和更新地图成本高,短期内商务及运营压力大。
2018年11月12日,搭载驭势AVP自动代客泊车(自主泊车)系统的宝骏E200-智能泊车产品首先落地,并面向终端消费者落地交付。
行业预测到2023年,自动泊车系统的普及率会超过20%。
不过,另一面,就地下停车场而言处在非公共交通管理区域内,一旦无人的自主泊车车辆发生交通事故其事故责任很难鉴定。
最后,总结一下目前市场主流科技公司的自主泊车方案:
中电昆辰“鹰眼”定位(射频定位、UWB)
2017年8月底,中电昆辰公司开始试验公司研发的“鹰眼”自动驾驶定位系统。“鹰眼”室内定位的精准度、速度都达到了世界一流水平,市场发展势如破竹。梅赛德斯-奔驰在土耳其的卡车生产线,用中电昆辰的设备对工人、车辆以及大型物料进行监督和跟踪;富士康用中电昆辰产品来跟踪生产线上的手机。
“鹰眼”定位系统最高已经可以达到1cm定位精度,5ms定位延迟,120k单结点在网容量,多项定位底层技术指标均处于行业世界领先地位。

UWB超宽带技术是近年来发展起来的一种无线电技术,其脉冲信号具有良好的障碍穿透能力及精确测距能力。基于UWB技术的鹰眼定位模块性能稳定,外形小巧的原因得益于电子科技大学深厚的技术底蕴、得益于中电昆辰是国内唯一一家进行超宽带底层技术研究的学科性公司。在公司组建之前,朱晓章在这一学术研究方向已经申请了多项相关专利,成立公司后才能将其进行几代的优化和改进。
鹰眼定位模块已成功应用于监狱人员管理、消防演练、工厂人员管理、自动驾驶、智能叉车、智能驾校、物料跟踪等领域。
汽车寻鹰眼
2017年,国内某一线主机厂花了将近一年的时间在全球寻找能用于车辆精确定位的技术,前期选用了国外一家供应商的方案。但真到了DV实验环节,在做高精度指标测试时,才发现无法满足自动驾驶的严苛要求,项目濒临失败。
在同济大学朱西产教授的推荐下,该主机厂在UWB领域广泛征集供应商。中电昆辰临危受命,在研发团队人数比较有限的条件下,最终在极短的时间内完成EP1验证,在一个春节的时间完成DV测试。在首次参与汽车电子产品供应的情况下,中电昆辰仅几个月就完成量产前装单供定点。主机厂对供应商审查十分严格,一个产品需要多达200多项测试,中电昆辰最后顺利成为该主机厂单一供应商。
在车辆外观上,仅需要在鲨鱼鳍内加载一个名片大小的鹰眼定位模块,就可以在布置了配套基站的高架桥和隧道、高楼遮挡区域、地下车库获取厘米级的车辆位置。

百度自主泊车解决方案

2019年7月3日,2019年百度AI开发者大会在北京国家会议中心举行,百度董事长、CEO董事长李彦宏演示了百度自主泊车解决方案的新进展。李彦宏介绍,目前的自主泊车功能可以通过手机APP召唤车辆,车辆能远程启动、自动开出地库;行进中,车子能准确判断路况,决定行动或是等待;开到目的地,如果非常拥堵,司机直接下车走了,无人驾驶的车能够跟在人类司机驾驶的车流里,自动排队开往地下停车场;车辆也不会把路边正常行走的行人当成障碍物,做出误判;并且,遇到很小难停的车位,人类司机可能会吃力,无人驾驶的车却能很轻松停进去。百度自主泊车解决方案已拿到多个车企的合作订单,将让一部分人实现“最后一公里自由”。
视频演示https://v.qq.com/x/page/v088217mxa6.html
https://v.qq.com/x/page/w0893zqq0i5.html
百度自主泊车解决方案试运营_最后一公里自由
传感器配置:未透露
是否场端改造:否
商业时间:2020年。
智驾点评:作为智能驾驶时代的技术创新产物,百度Apollo Valet Parking自主泊车方案利用百度独有的车云图厂一体解决方案以及云和高精地图优势,实现了智能泊车场端改造的最佳性价比,车端百度通过车规级传感器可以实现车辆的中、近环境感知、轨迹规划和车辆控制,加之百度云和百度的数据积累经验及大数据分析能力,百度高精地图在国内多家OEM测试通过率100%,相对精度为0.1 ~ 0.2米,冗余率/遗漏率仅为0.01%,从而实现自主泊车巡航精度和高安全。,与此同时,基于高精地图和视觉AI,自主泊车可以保障10cm精度定位和巡航。
纵目科技
成立于2013年的纵目科技是为数不多已经进入汽车前装、实现量产和营收的ADAS 创业公司,主打产品为环视ADAS。去年11月30日,纵目科技发布其针对停车场低速场景的自主泊车系统,正式从环视ADAS切入自动驾驶。
我们通过这个视频来看一下自主泊车来怎么样改善逛Shopping mall这个问题。

这段时间很多城市又开始陆续增加了共享分时租赁的电动车。我自己也亲身体验过一次,是在上海还算覆盖比较好的地区,早上七点钟时候开始约车,结果一辆车都没有,因为所有的车都被约走了。然后我就像刷火车票一样不停地刷,刷了二十分钟之后,终于刷到了一辆车,这辆车离我1.5公里,我只有十五分钟的时间来找到这辆车。整体体验其实并不是很好。作为用户来说,我希望可以像使用共享单车那样使用共享汽车,这就需要解决好最后5公里的问题。对于运营商来说,现在的分时租赁汽车还无法形成盈利,主要原因就是汽车每天使用的频次太低,调度的成本又太高。而自主泊车的技术恰恰能够解决这些问题。

李德毅院士今年在走访纵目的时候提出,企业要把自动驾驶的最后一公里当做最先的一公里来做。
自主泊车技术可以应用在两个商业模式里面。面向车主(To C)的市场,依然是从严格的OEM到Tier1、Tier2供应商这种分级体制;而面向共享出行市场的To B模式,需要OEM、运营商以及不同的技术提供商在一起相互配合来构造整个生态系统。这里可能会涉及到停车场的管理、车队运营管理、无线充电甚至是保险公司等不同的商业模式。

我们把自主泊车的落地划分成了三个阶段:
在1.0中,我们主要想解决的是停车场以及简单园区的应用;
在2.0中,我们会扩展到复杂的园区以及结构复杂的多层停车场;
在3.0中,我们会进一步扩展到停车场周边的市区道路。
大家可以看出这三个阶段的场景是从封闭到开放,从简单到复杂的过程。在1.0中,我们是要来开发验证我们系统架构的关键技术。在2.0和3.0中,我们会通过大量的测试来提高技术的成熟度。

我们再来看一下自主泊车所面对的技术挑战。首先我们来看一下系统需要什么样的传感器。因为传感器的成本几乎占据了整个自动驾驶系统成本的绝大部分。刚才我们已经分析过了,面向大规模量产的自主泊车系统必须是一个低成本的方案。我们认为这个方案的成本应该比Waymo的系统至少低两个数量级。
但低成本不代表在质量和可靠性方面有任何的妥协,产品必须按照最高的功能安全等级来设计,要完成大量各种各样的测试。
另外停车场的环境有很强的特点和挑战性,比如收不到GPS信号、缺乏统一的建筑标准、光线变化很大、有些停车场的地面反光很严重、很多停车场的建筑重复度很高、很多区域非常相似、人在里面也很容易迷路以及墙面都是白色的,缺少一些必要的纹理信息,这些都是对传感器算法的挑战。

下面分别从感知、定位和规划三个核心算法来看一下我们是如何解决这些问题的。
在开车的时候我们到底需要什么样的感知能力?如果是人在开车,在高速的场景通常是比较简单的,你基本上只需要眼睛看着前方一百米这样的距离,保持一个放松的姿势就可以了。反而在低速的时候,驾驶员需要不断地来回转动头部来观察周围的视角。这就是为什么很多新手司机可以在高速上开车,但是到了市区反而不敢开的原因。因此,我们可以得出一个结论,就是感知的距离和车速成正比,而感知的角度和车速成反比。
因此,我们认为在低速时候,环视的4个鱼眼摄像头能够非常好地满足这些需求;同时,我们也会将5个高分辨率的毫米波雷达和12个超声波雷达进行融合,形成必要的冗余。
现在很多图商所提供的高精度地图里面都包含了标志牌的3D信息。通过这些信息,我们可以计算出标志牌到相机平面的Homography矩阵,来计算出车辆的精确的姿态。

我们现在再来看一下高精度定位的问题。首先我想帮大家捋清三个概念,分别是高精度地图、SLAM以及定位。
在机器人学里面,几乎所有的概念都是以概率的形式来定义的。高精度地图就是在轨迹测量值已知的情况下来计算地图的概率分布。这里x代表了传感器每一时刻的姿态,z代表的观测值,m代表了地图。
如果x和z是非常精确的,那么这个过程就会变得非常容易。图商在制作高精度地图的时候通常会采用非常昂贵的地图采集车。而采集车的成本,每辆大概在几百万到上千万人民币,车上有高精度的组合导航设备可以获得厘米级的姿态,多线数的激光雷达可以对环境进行非常精确的测量。对于像隧道或者停车场这种场景,他们还会布置临时的一些基站来实现室内定位。
在这些定位和测量基础上,我们就可以得到一个非常高质量的地图。然后在这样的基础地图上去生成高精度的地图数据,这个过程在第一季高德公开课的谷小丰老师的讲座里面已经讲得非常清楚了。
对于自主泊车来说,有些停车场可能还没有这样的高精度地图数据。客户也希望能够通过学习和训练的方式来实现自主泊车的功能。实际上这是一个SLAM的过程,也就是说,当m和x都是未知的时候,我们要通过u和z来同时求解x和m的概率分布。这里的u代表的是一个控制命令,也可以用里程计来代替。u的质量对SLAM的效果影响还是非常大的。在我们的控制器里面,我们设计了一套极低成本、紧耦合的组合导航,可以输出非常高质量的里程计数据,从而保证SALM的效果。

上面这张图是用单目鱼眼镜头在停车场内的一个地图构建,里面包含了停车场两层的结构,大家可以看到重建出来的效果还是非常好的。
我们也尝试过用普通的前视相机在停车场里面运行SLAM,但结果并不理想。原因主要还是由于墙面缺少必要的纹理信息。这就好比把一个人放在一个陌生的房间里面,但是你限制了他的视野,给他戴上了一个望远镜,那么他就很难搞清楚自己的位置和周围的环境。因此这种超大FOV鱼眼镜头在停车场里面是非常有优势的。

这张图我们是用4个环视鱼眼相机实现的多目联合SLAM优化,可以进一步的提高算法的鲁棒性。这张图表示的是在完成闭环前的一个状态。熟悉SLAM的同学可以看出来,在这个闭环的结合处,闭环误差是非常小的。

当有了地图,我们车辆在进入到地图覆盖区域的时候,我们就可以通过重定位的算法来实现与地图的匹配,然后对车身的姿态进行连续跟踪。一旦跟踪成功,我们就可以开启自主泊车的功能。
有些时候定位和SLAM也是耦合在一起的。比如可以通过Local map获得更好的观测来提升定位的效果,也可以通过定位时候的观测更新地图来获得一个更可靠的地图。SLAM和定位都需要使用车身自身的传感器,所以这个成本还是非常重要的。
从右边这张图我们可以看到,每个传感器都有自己的特点和适用的场景。我们的方案是将多个低成本的传感器融合在一起来实现定位,其中涉及到了4个鱼眼镜头、4个毫米波雷达、12个超声波雷达、来自车身的轮速传感器以及我们低成本的组合导航。这样一套方案的成本非常低,但是它可以覆盖绝大多数的场景。

这是自动驾驶中的规划部分,大部分的自动驾驶方案采取的都是类似这样的规划:第一步是根据自车的位置向目标点规划一条全局的路径。这个过程和普通导航差别并不是很大。但是,在自主泊车寻找空车位的过程中,我们产生的通常不是最短路径,而是一条最有可能找到空车位的遍历路径,然后我们再通过局部路径的算法和决策的迭代来生成最终的规划轨迹。

在决策中我们可以采取比较保守基于规则的策略。这种适用于规则比较简单明确的场景,也可以让系统从人类驾驶员这个专家数据中去学习,学习人类的驾驶习惯,也可以把这个算法放在模拟器里面通过增强学习的方式来学习。

这幅图是一个简单的迷宫任务,我们通过一个CNN的网络来学习专家规划出的路径。从这个结果中可以看到,绿色代表的是专家规划出来路径,红色代表的是网络学习之后自己规划出来路径。从中我们可以看出网络通过学习之后,会规划出一条和专家的策略类似但又不完全一致的一条路径。

对于局部路径规划来说,停车场内的局部路径规划和道路上有比较大的不同。停车场内的很多区域比较狭窄,转弯也都比较急;对于人类的新手司机来说,也经常会发生各种各样的擦碰事故。
大家知道汽车的运动受到非完整性约束的限制,没办法进行原地转向。左边这张图是MIT在DARPA 2007城市挑战赛中的算法,主要是通过RRT的方式在状态空间中随机采样,然后再通过closed-loop在线模拟生成一条更优化的轨迹。
右图是CMU提出的方法,他在A*搜索的基础上面,把二维的搜索空间扩展到了三维的搜索空间,可以去覆盖不同的航向角。后面也有人提出了进一步优化,比如把曲率、速度、加速度都加到搜索空间里面,但是这样会造成搜索空间非常的庞大。
这两种算法都可以用在停车场里面,具体的细节大家可以去阅读一些相关的Paper。但是在具体实现的产品实现的时候,还是有很多的细节技巧可以来帮助提升整体的性能。

最后我们再来系统地看一下纵目的方案。我们这里采用了4路环视摄像头,一个前视摄像头、一个非常低成本的IMU,大概是几个美金左右,还有4轮转动脉冲、方向盘转角是来自于车身,一个普通的GPS传感器、超声波雷达以及5个毫米波雷达。
可以看出这些都是非常低成本的,而且得到了广泛量产验证的传感器。低成本的传感器通常来说精度也都比较低,因此我们需要通过传感器融合算法来相互抵消这些误差。
对于传感器融合,要想得到一个好的效果,就需要把每个细节尽可能地做到极致。比如实现传感器的时钟同步就有好几种方式,如果每一个传感器都带来几毫秒甚至几十毫秒的误差,那整个系统就很难把效果做好。
再比如标定。标定的算法优劣也会对精度有一些影响,对普通的视觉功能来说,可能看不出特别大的差别,但是对于自动驾驶功能来说,经常就是失之毫厘,谬以千里。

这是纵目APA自动泊车的架构,我们输入4路环视摄像头、超声波雷达以及车身传感器的数据,通过我们的APA ECU融合这些数据信息,然后做出相应的规划来向车身发出横向和纵向的控制指令。

这是我们自主泊车的控制器架构。我刚才提到了我们和APA保持了非常相近的架构设计。这里只需要增加几个传感器,然后升级ECU就可以完成自主泊车的功能。

在自主泊车的ECU中,我们采用了两个计算单元:高通的骁龙820A可以完成非常复杂的深度学习、SLAM、规划等算法的计算;恩智浦(NXP)的S32K可以来完成涉及功能安全的控制。
之前有很多小伙伴来问我们,说为什么我们会选择高通820,而不是其他公司芯片?我也想借这个机会来分析一下我们的想法。
首先,我们的软件和算法是跨平台设计的,很容易就可以移植到不同的硬件平台上面。但SOC并不是一个标准化的产品。另外,想把每个芯片的性能发挥到最佳的水平,就需要进行深度优化工作。这一点我非常感谢高通过去给我们大力的支持。我们和高通总部研发部门保持着密切的沟通。我们的想法也会得到及时的配合,甚至体现在下一代芯片设计之中。
第二,从战略的眼光来看,我们认为在自动驾驶中,单纯比拼计算能力的时间很快就会过去。因为我们看到,其实每家芯片原厂都已经具备了非常强大神经网络加速功能,最终比拼的还是综合能力,比如成本控制、生态构建甚至是公司文化。我们相信高通和恩智浦在汽车领域的决心和能力。

这是我们产品的HMI设计,除了标准的车机导航之外,我们还会有一个手机的APP。

除了车机和手机之外,我们还会有一个云端架构。在这个云端架构之中,我们可以和更多的停车场、地图数据、充电服务商等后台进行对接,还可以实现用户管理、安全认证、人车通信,对传感器的数据进行收集,然后再利用这些数据迭代来实现算法的更新、地图的构建、甚至未来的众包地图。
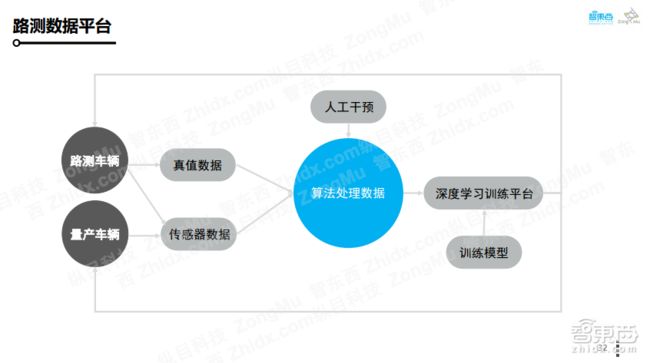
这是我们的数据平台。在整个开发过程中,我们会利用自己的路测车辆采集大量的数据,这些数据会包含车身传感器的所有数据以及一些真值数据。同时,我们的每一个用户车辆也是数据采集平台。这些数据经过一些少量的人工干预之后,会送入到我们的深度学习平台进行训练,这样我们会得到更好的算法。同时,这些算法模型会更新到每辆车辆中,我们在通过这种方式形成有效的数据闭环,快速迭代我们的算法。

在产品认证阶段,我们也有不同的方式来进行验证。首先,我们有一套针对停车场的环境以及我们自身的传感器架构定制的模拟器。我们可以把真实停车场的高精度地图以及路测数据导入到模拟器中,也可以定义各种各样不同的环境以及交通流。我们在这个模拟器的环境里面可以积累大量的测试用例。
我们也有自己封闭式的测试区。在每个版本发布之前,我们都会在封闭区内完成一系列的测试。我们会根据功能安全的分析,来设计各种各样的传感器失效场景以确认系统的鲁棒性,这些都会在封闭测试里面完成。
我们还将在开放的停车场里面进行路测。当然也是在符合国家法规的情况下,会根据实际的情况来生成具体脱离次数的检验报告。
在网络安全方面,我们也有互联网方面的安全专家来进行网络攻击的测试。
视频七(在车东西公众号回复关键字“视频”获取)
这个视频是我们专门为停车场环境所定义的模拟器。

对于这些事情我们也有一整套的行动计划,我们在去年年底发布了自主泊车1.0,现在正在开发2.0的版本。我们的自主泊车车队会在今年积累到十万公里以上的路测数据,这些是我们在2018年需要做的事情。
到了2019年,我们会利用这些收集起来的数据来验证我们的系统。我们会和共享出行的合作伙伴一起来部署一万辆车。然后再利用这些车到路上去收集更多的数据,这样我们可以快速积累到上百公里的路测数据,之后通过这些数据来迭代产品的性能,验证我们的可靠性。我们相信在这之后主机厂的相关车型也会逐渐导入量产,而这个时间点大概是在2020年。
最后再来总结一下,对于大规模量产的自主泊车方案来说,成本是非常重要的,但是安全更加重要。要用低成本的传感器来实现高水平的感知和定位能力,必须要有足够的传感器融合能力,这里不仅包含软硬件以及融合算法,并且还要一整套开发验证的流程来支撑。
驭势科技
演示视频 https://v.qq.com/x/page/x06364gy80t.html
传感器配置:环视摄像头+前后视摄像头+超声波雷达
是否场端改造:否
商业时间:2018年11月
智驾点评:作为自主泊车功能最早实现商用的科技公司,驭势科技除了自身技术过硬之外,很重要的一点在于通过运营运维服务平台实现端到端仿真系统、人机交互系统和数据管理平台等几大模块实现对车上传感器数据的采集、存储、传输及分析流程自动化,不断优化无人驾驶算法、系统安全性及用户体验,对系统组件做实时和预测性的运维,支持无人驾驶应用的运营和管理,同时远程监控系统可以进一步增强系统在复杂环境下的运营能力。
自动驾驶视觉定位与导航技术的研究与应用
视觉定位与导航技术是智能体具备的基础能力之一,随着无人驾驶的发展,基于低成本摄像头及人工智能算法的视觉定位与导航技术成为了无人驾驶的主流技术路线之一。在传统工作方式中,视觉定位与导航技术通常采用SLAM(Simultaneous Localization And Mapping,同步定位与建图)的方式构建一个几何地图,然后在地图中进行路径规划和导航。在每一个时刻,无人车可以通过使用当前图像和地图比对的方式,或者采用视觉里程计的方式,估计当前相机的位姿进行无人车定位。
但在开放、复杂的无人驾驶场景中,视觉定位与导航技术在传统工作方式下还存在一些明显的挑战:
Part 1
视觉定位的挑战
一、摄像头视角有限
有限的摄像头视角,限制了无人车在停车场等拥堵场景中做到实时鲁棒的位姿估计。一方面,当相机发生旋转,偏移建图路线的时候,有限的可视角度会导致特征点丢失。另一方面,当场景中动态物体较多的时候,可能导致相机的视野中被动态的车辆和行人占满,导致位姿估计错误。
基于此,我们采用了鱼眼相机、多相机等作为传感器,显著扩大了视觉定位中的摄像头视角。
鱼眼相机:应用鱼眼相机可以为视觉定位创造一个超大范围的场景视角,但同时鱼眼相机也存在较大的畸变这一挑战,大畸变使得普通的相机模型无法适配,并且普通的描述子也不能适用。另外目前常见的开源SLAM系统,如ORB-SLAM等并不能很好地支持鱼眼SLAM模型。针对这个问题,我们提出了一种基于立方体展开相机模型的SLAM系统(CubemapSLAM,图1),该模型既可以有效去除鱼眼相机图像中存在的较大畸变,又能够保留原始图像所有的场景视角。目前,在公开数据集和驭势科技自主采集的数据集中,我们的算法均优于已有的鱼眼SLAM方法。

图1
我们的方法已于去年发表在ACCV2018,同时对我们的CubemapSLAM算法进行了开源,欢迎大家使用并反馈。
链接:
https://github.com/nkwangyh/CubemapSLAM
此外更重要的是,我们研究的算法并没有停留在论文阶段,而是更进一步,落地于公司商业化运营项目,在真实的自主代客泊车(AVP)场景中进行了运用(图2)。
图2
多相机系统:我们研发了紧耦合多相机的SLAM定位系统(图3)。在多相机系统中,由于每个相机的光心位置不同,因此,我们采用了一种叫做General Camera的模型来表达多相机系统。同时,多相机系统的精度受相机之间的外参影响比较大,因此标定的质量非常关键。除了常规静态标定之外,我们还将多相机的外参纳入到SLAM系统的优化框架中。

图3
二、Long-Term Visual Localization
自动驾驶视觉定位的另一个重大挑战是光照和环境的变化。同样的一个场景,如果建图的时间是白天,定位的时间是晚上,我们也需要无人车能够稳定工作。夏天建的图,到了冬天,定位系统也要能识别出来。因此,我们需要实现自动驾驶在不同光照与环境变化中的“Long-Term Visual Localization”任务,而这一任务,我们一般又划分为位置识别(Place Recognition)和位姿估计(Metric Localization)两项子任务。
位置识别任务旨在找到相机在地图中的大致位置,即找到地图数据库中跟当前图片最相近的一张图。最常见的传统做法一般是采用Bag-of-Words(BoW)技术,把图片中的SIFT,ORB等特征点转化成向量表示。在这个向量空间上最接近的图片,即认为是当前图片所在的位置。
但通过位置识别任务得到的只是当前相机的大致位置,在无人驾驶中,为了得到相机和车辆的精确位置,我们还需要接着做位姿估计。一般在这一步,算法会把当前图像上的特征点和地图中的特征点进行特征匹配(Feature Matching), 根据成功匹配的特征点计算中相机的最终精确位置。
位置识别和位姿估计这两项任务还存在很多挑战,面对其中最主要的挑战:光照和环境的变化,我们采取了深度学习(Deep Learning)的方法。目前,深度学习已经在计算机视觉多个领域得到广泛验证,具备超越传统方法的应用能力。
位置识别(Place Recognition):对于位置识别任务而言,如果我们把每一个位置当做一个类别(Class),那么我们有很容易获取的Label : GPS作为监督信号。GPS的坐标值本身是连续的,两个坐标之间的欧式距离可以反应出两张图之间的远近。因此可以把这个问题当做度量学习(Metric Learning)来训练。通过这样训练出来的Feature,可以做到大幅超过BoW的位置识别效果。我们在这种网络基础之上,提出了Landmark Localization Network (LLN,图4),帮助挑选出图像中最有显著性的部分。从结果中我们看到,仅仅使用GPS这个弱监督信号,我们却学习出了跟Place Recognition这个任务最相关的特征,如图6所示,我们对LLN网络的Feature Map进行了可视化,在第二行中我们看到垃圾桶部分的响应比后面的红墙要高很多,而在第三行中旅馆的招牌也得到较高的响应。我们的结果已发表在ICRA19。

图4

图5

图6
我们也尝试了使用GAN的方法来进行不同光照之间的变换。跟以往做法不同的是,我们可以做到在连续时间域上对图像进行连续变换(图7)。从图8可以看到,当把当前图像变换到和地图中的时刻后,特征匹配的数量会大幅提高。
图7

图8
位姿估计(Metric Localization):在位姿估计这一任务中,传统的方法会使用ORB,SIFT等特征进行匹配和解算位姿。目前也有很多使用CNN进行特征点提取(Detection)和描述(Description)的方法,比如Superpoint是其中效果比较好的一种。我们在Superpoint的基础上进行了改进,加入了Saliency Ranking机制(图9),在特征点提取数量较少的情况下,可以达到比Superpoint更高的重复率(Repeatability,图10)。我们用这个方法参与了今年CVPR19的Local Feature Challenge,并最终进入了前三名。

图9

图10
在这个基础上,我们也训练了一些检测器去识别高层语义特征,比如道路上的标牌,车道线,路灯杆等等。这些特征在公共道路上面普遍存在,相比较Low-Level特征点,这些语义特征更加稀疏和可靠。

Part 2
Navigation
地图和定位都是最终为了导航而服务。例如上述两点中的位姿估计(Metric Localization),对于人类司机来说并不是必须的,人并不会每时每刻知道自己的位姿。因此,我们也引入了一些相对导航的机制,例如利用车道线、灭点等信号,让车辆学会怎么沿着路开。
2017年,在我们和清华大学合作参与的一个Vizdoom比赛(图12)中,我们率先使用了SLAM和导航结合的技术。这个比赛环境是基于Doom(一款3D系列射击游戏)的第一人称射击游戏,选手的任务是在一个环境中移动和射杀对手,并赚取尽量多的分数。为了能很好地完成这个任务,空间感知能力是一个基础。而一般的深度强化学习方法并不会显式地表达这个空间概念。因此我们把SLAM构建的地图和强化学习网络相结合,通过把周围空间环境的信息加入到网络中提升了强化学习的空间感知能力,并最终在这个比赛中获得了第二名的好成绩。

图12
此外,驭势科技自主研发了驭势智能驾驶仿真系统,其场景画面和真实场景高度相似。因此我们可以在仿真平台中训练行车策略, 并且部署到真实场景中。
图13 基于仿真平台的Vanishing Point训练
我们还在Navigation上面做着更多的探索,More To Be Continued, Please Stay In Tune!
纽劢科技

传感器方案:未透露
是否场端改造:未透露
商业时间:未透露
智驾点评:纽劢科技自主泊车方案主要集中在自主接驾、实时车位寻找、智能经停、智能避障方面的能力,其在自主泊车的过程中,可以识别小孩、地锁、车辆、锥形桶等细分障碍物,通过厘米级定位最大化车端智能,具有鲁棒性高、入位误差距离小于5厘米、入位角度小于1度等特点。
Momenta

演示视频 https://v.qq.com/x/page/n0897emjswx.html
传感器配置:4个环视鱼眼摄像头、12个超声波雷达以及消费级IMU和GPS。
是否场端改造:否
商业时间:未透露
智驾点评:相比昂贵的激光雷达建图,Momenta采用视觉为主的方案实现自动化建图,该视觉方案与自动泊车硬件可通用,在建图过程中,通过深度学习算法提取视觉语义特征,使用SLAM技术自动生成基于语义的高精度地图,整个系统可进行云端和车端自动建图,精度达到10cm级别。
完全自主泊车,千元级硬件成本
今日正名者:Momenta。
这家中国自动驾驶独角兽公司,刚刚发布了自主泊车产品Mpilot Parking。
这是一款怎样的产品,不多说,先看货。
产品初体验
自主泊车,顾名思义就是泊车进库全程让车“自主”。
在Momenta苏州总部地下约500平米的多层写字楼停车库,我们随这辆自动驾驶改装痕迹并不明显的林肯MKZ,体验了全过程:
到达停车场,司机下车,自主泊车启动:
开始从地面进入地下,下坡,光线变暗。
地库行车中,速度5公里\小时左右,但人车混行场景很常见:
也有其他人类司机正在泊车,无人车选择停下等待,先让其完成:
最后,到达目标停车位,倒车入库。如果是非写字楼场景,也可以指定或让无人车“自主”寻找空闲车位泊入:
接下来切换使用场景——无人车受到车主远程召唤,泊出:
再次遇到其他车辆,但这次无人车检测判定可以绕行,于是绕行通过——相似场景,不同处理方式,也体现出系统老司机的那一面。
最后到达电梯口,车主上车,自动驾驶系统继续帮助开出地库。
全程零接管,车主远程通过手机就能一键启动和召唤。
可以预想的是,一旦方案进入前装并以量产车交付,停车入库的时间将得到节省,不少停车场的剐蹭事故也能极大避免。
而且令人振奋的还有时间表,Momenta方面透露,跟多个标杆客户的实际合作已经展开,2021年-2022年该产品方案就会陆续通过量产车交付。
自动驾驶产品检验标准
虽然不是头一家推出自主泊车产品,但Momenta该款产品,确实不一样。
有啥不一样?体现在车主体验层面的大不一样。
区别于之前的自主泊车方案——不限场景、不堆昂贵传感器,甚至不依赖停车场智能化改造。
产品可以经得起三大标准的检验:可用、好用,容易用。
先从可用说起,核心检验项是成本。
一套自主泊车方案,从车库入口到车位停稳熄火,如今技术上并非不能实现,然而一旦需要加持激光雷达等激光雷达的传感器,量产门槛就会被大大推高。
而且当我们说“可用”,还得是人人买得起的可用,任何车型可配的可用,无需经年累月等待车规标准的可用。
Momenta的方案,实际就是以此倒推打造的成果。
整套传感器系统,共搭载4路环视鱼眼相机、一个前视摄像头,外加12个超声波雷达,均是已成熟量产符合车规的传感器。

虽然没有明确公布成本数据,但略微对汽车产业供应链熟悉的话,也就约为一部手机的售价——还是国产手机。
如果传感器成本才多一部手机的钱,就能让每天车库出入交给机器,算不算可用?
其次是好用,核心考验的是场景应对能力。
换而言之,任何时候任何场景都不需要车主来接管的能力。
区别于环路无人驾驶,地库车速相对较低,但依然不乏极端场景。
比如人和其他车辆不规范操作的场景,车辆占道或超出正常车位的场景,多层车库上下坡造成环境变化的场景。
都会影响自动驾驶正常行进,也就要求自主泊车方案能够准确感知障碍物的种类、尺寸、距离以及运动状态,也需要有更完善准确的定位能力。
最后是容易用。核心要求是买来即用,不挑场地。
之前已经发布的自主泊车方案,或者对车端智能传感设备配置要求高,或者对停车场智能化改造有依赖。
最常见的是用传感器改装停车场,通过车路协同的方式降低车端智能的难度,但无论是成本,还是改装时间,都带来新问题。
这都会阻碍自主泊车的真正落地使用。
从车厂和车主角度而言,谁又希望卖车和新方案时,还要让用户考虑是否所有停车场都能去的问题?
所以场端依赖一日不解决,自主泊车方案都不能算易用。
而且既然是容易上手,就得“开箱即用”,不能再让用户参与长时间的“路测”。
所以此次Momenta也将其另一项核心壁垒能力——高精度地图的建图定位技术,落地到了产品方案上。
背后技术详解
如此水准的自主泊车方案实现,所用技术肯定不止一项。
现已业内耳熟能详的感知、决策规划、控制和定位,均在其中发挥作用。
但此次Momenta之所以方案可用好用易用,最具功力的自然是高精度地图建图方面的突破。
熟悉Momenta创业史的人,都对Momenta的高精度地图方案不陌生。
但现在,“重活苦活”正在转换为优势。

一方面是Momenta业已成熟的低成本自动化建图。
相比昂贵的激光雷达建图,Momenta采用视觉为主的方案实现低成本自动化建图。
建图采集系统使用成熟的四路环视鱼眼相机、消费级IMU及轮速等传感器,总成本较低。
在建图过程中,通过深度学习方法提取视觉语义特征,使用SLAM技术自动化生成基于语义的高精地图。
整个系统云端和车端都能完成实现,无需人员参与,精度达到10cm级别。这是什么概念?一般车道线是20cm。
另一方面是建图的低门槛:量产车行驶过停车场就能完成。
当搭载了Mpilot Parking的车辆进入地图未覆盖区域,车辆行驶过停车场即可自我学习、建立该区域地图,并上传到云端,便于后续基于此地图上进行定位。同时,行驶在此区域的其他车也可共享受惠。
这种众包方式,也是快速规模化实现低成本建图和更新的关键所在。
无需专门的地图采集车,支持量产车辆自主建图,多辆车通过众包实现快速规模化建图和更新。
而且随着时间的推移,地库中增加或消失的元素,都可以通过众包车辆进行地图元素的实时更新。
不得不说,确实是应对“无限战争”的一次人民汪洋大海式的解决之道。
魔视智能

传感器配置:4个环视摄像头、12个超声波雷达、5个毫米波雷达。
是否场端改造:否
商业时间:未透露
智驾点评:魔视智能自动代客泊车技术基于V-SLAM完成定位,在不需要场端改造设施情况下可实现跨层泊车,通过实时定位,魔视智能具备传感器检测到的信息与地图进行实时叠加能力,其车辆车辆定位精度可控制在10厘米以内。
核心技术
1、深度学习
深度学习深刻的影响和推动了人工智能革命。立足和专注于自动驾驶,魔视智能聚集了世界级的算法团队,在自动驾驶领域主要的算法比赛上都名列前茅。
在语义分割领域权威的Cityscapes Semantic Segmentation比赛上,魔视智能长时间位居前列。魔视智能将深度学习算法技术,和中国的汽车市场化紧密结合, 快速推动自动驾驶技术落地。
MOTOVIS团队在自动驾驶相关的多项算法评测中获得世界大奖第一,第二的好成绩。
2、VSLAM
地图构建(VSLAM)技术, 使汽车能够在未知环境下实现定位与建图。 该技术能够融合车载摄像头和其它传感器的连续信息,在理解环境的几何结构的同时定位车辆的相对位置。
从特征点到三维轮廓乃至更高级的带有语义信息的交通标志与车道标记。 在为车辆实时定位提供3D几何信息的同时,这种多层级的3D特征的语义性内容也能够为L4自动驾驶的决策与路径规划打下良好的基础。

常规的视觉系统虽然不能直接提供图像的深度信息但却有其他明显的优点。
首先,当前的量产车辆很多已经配备了用于停车辅助和ADAS的环视系统。相比于其它解决方案,特别是基于激光雷达的解决方案,采用视觉系统有明显的经济优势。
其次,魔视的SLAM解决方案不仅仅依赖于图像, 还能够结合多种其他传感器(例如IMU,GPS, UWB, 里程计等)使整个系统能够实时运行并提供及时、 丰富的环境理解。
3、多传感器融合
视觉与雷达融合:将视觉极强的识别能力与雷达高精度测量特点集于一体,二者互相补充、互相验证,使得系统精度、检出率、虚警率、适应工况、可靠性和冗余度等都得到进一步提高,可以有效解决雷达传感器的多种corner case。corner case。
视觉与超声融合:基于全景环视图像的深度学习检测,够有效识别地面停车位、低矮障碍物、路沿、以及儿童、宠物等目标,弥补超声波传感器的检测盲点,并提前发现超声检测距离之外的运动行人和车辆。通过对超声和视觉检测的融合,魔视智能实现了完整的环境感知,避免倒车时碰撞造成的轮胎损坏或人员伤害。
此技术可应用于自动泊车辅助(APA)、自主代客泊车(AVP)等系统,实现更为安全,可靠的泊车功能。
4、嵌入式芯片
如何在低成本低功耗的硬件芯片局限下实现高度智能和实时的复杂深度学习网络,一直是困扰人工智能在汽车行业落地的难题,魔视智能完美的克服了这一巨大技术挑战,他们精心设计优化的深度学习计算引擎成功的运行于车规级嵌入式芯片,并达到>2.8倍的计算效率提升。
参考资料
【1】https://mp.weixin.qq.com/s/Q8PzeARVntDOnzABKzFEmA
【2】https://mp.weixin.qq.com/s/2qtcQIADA-070ZVbbO9fLg
吉利
吉利也早在今年5月10日的吉利汽车技术日上,展示过自己的AVP自动代客泊车系统——爬行者,凭借5G V2X车路协同、L2/L3级自动驾驶传感器等技术即可解决停车与取车问题。

值得一提的是,目前市售很多车辆上的“自动泊车”功能,准确说应该是叫停车辅助功能。
魔视智能
从最初的不被看好,到赛灵思、英飞凌为其加码。这意味着魔视智能的技术和实力已经得到了国际企业的认可,并在自动驾驶领域占有一席之地。
2018年9月27日,魔视智能宣布其基于嵌入式深度学习技术的乘用车及商用车辅助自动驾驶产品已在主机厂上正式量产。同时,其基于车规级嵌入式处理器和深度学习的量产级自动泊车产品也正式发布。魔智已带领其辅助自动驾驶前装产品开通了一条量产之路,成为国内首家实现基于深度学习的辅助驾驶前装量产的自动驾驶公司。
量产级自动泊车产品发布
魔视智能也公布了其基于FPGA方案和深度学习的量产级自动泊车产品。该自动泊车方案,通过四目视觉感知和超声传感器融合,采用深度学习算法,对车身周围停车位进行感知及决策,实现半自动和全自动泊车控制,以及一键式遥控泊车。

和传统自动泊车系统采用的纯视觉或超声波方案,基于深度学习的视觉同超声波融合的自动泊车方案的优势在于,能够满足车位识别的鲁棒性要求,可以完成不同形态车位、不同材质路面、路沿的识别。而采用传统学习算法的自动泊车产品,仅适用于单个或几种简单场景。
虞正华也介绍了未来泊车的发展路径及魔视智能的自动泊车产品规划:
-
3D环视:通过360度全景摄像头,完成简易的图像拼接显示功能。这也是目前大部分量产车辆搭载的辅助泊车方案。而通过360环视摄像头完成道路图像拼接,摄像头在检测道路信息的过程中并不支持目标图像识别,驾驶员仍需依据拼接图像控制车辆,完成泊车。
-
自动泊车:当驾驶员将车停在停车位附近时,系统通过环视检测、深度学习方法的图像识别感知垂直车位、横向及斜列车位等,实现自动泊车入位、遥控泊车,无需人工控制。魔视智能计划在2019年大规模量产自动泊车产品。
-
自主代客泊车:利用多摄像头与其它定位传感器融合,及在线或离线高精度地图,基于VSLAM和深度学习紧密耦合实现6D车辆定位。驾驶员无需寻找车位,车辆自主完成泊车。魔视智能计划在2020年完成自主代客泊车产品的量产。
自主代客泊车依赖车辆定位技术完成。魔视智能利用车上环视摄像头,基于VSLAM和深度学习的高度耦合,魔视智能已经完成了600米路径的闭环测试,定位精度达到10厘米左右,相对行驶距离的漂移为0.62%。目前KITTI上世界第一的结果是0.65%。值得一提的是,魔视智能在闭环测试中采用鱼眼环视摄像头的视觉方案,而图像畸变的出现,对于算法处理也是一大挑战
-
高级自动驾驶:即车辆实现完全自动驾驶
虞正华提到了目前自动泊车产品量产之路面临的一些难题:和车厂对接过程中,自动泊车产品在设计方面需要满足严格的车厂规范;同时,不同工况下,自动泊车产品的多场景覆盖性需要长时间的测试积累。
魔视智能基于深度学习和车规级嵌入式平台的自动泊车方案,目前已同多个主机厂及供应商进行产品测试和验证,并计划在2019年实现大规模量产。
魔视智能的三大高地
虞正华提到,除与赛灵思、英飞凌合作,使用其芯片外,魔视智能已经搭建了从数据采集、后端处理,到算法模型,训练模型,硬件搭载的完整闭环,并在深度学习算法、汽车嵌入化平台、优质数据三大方面构建了一套核心的技术路线。这也成为魔视智能对标辅助系统ADAS领域中其它公司的三大高地。
魔视智能是首个兼具深度学习及VSLAM算法技术的自动驾驶初创公司。不同于传统人工智能计算方案,魔视智能在成立之初将深度学习技术作为基调。同时,不依赖高成本激光雷达,利用摄像头为主的SLAM技术完成相对和绝对定位,解决了成本及量产难题,这成为魔视智能在核心算法方面的一大高地。
在深度学习方面,虞正华提到,魔视智能起步早,而Mobileye在第四代系统芯片EyeQ4上开始引入深度学习技术。另外,鉴于中国政策及复杂的道路环境,魔视智能在中国道路数据积累方面更有优势。
魔视智能深度学习算法曾参加无人驾驶算法评测数据集KITTI、CITYSCAPES算法评测数据集等多类比赛,并位居世界前列。CITYSCAPES由戴姆勒集团组织进行,Cityscapes Benchmark即基于深度学习的语义分割,其任务为基于道路视频的像素完成19种类别区分,包括各种道路和街景特征、交通标志等,并输出算法结果。
虞正华提到,完成算法测试效果并非重点,重要的是,基于强大的深度学习算法的优化设计能力,采用网络裁剪、低比特数定点化等技术,魔视智能将其应用到低成本的FPGA平台,并实现量产。基于深度学习的算法目前可以完成轿车、中巴、大巴、车道线、路沿、Freespace等道路信息的识别。
基于深度学习及VSLAM算法,如何做好汽车嵌入化平台是ADAS及自动驾驶视觉方案供应商的核心,也是魔视智能的第二大优势。在嵌入式芯片平台方面,魔视智能选择基于赛灵思FPGA方案设计开发视觉芯片系统。新智驾了解到,魔视智能在商用车、乘用车前视智能驾驶辅助一体机及自动泊车产品方面选用了两种不同的处理器方案:
-
针对面向商用车、乘用车前视智能驾驶辅助一体机产品,魔视智能基于Xilinx Zynq-7020处理器完成嵌入式开发平台;
-
自动泊车及自主泊车产品,魔视智能采用Xilinx ZYNQ 及MPSOC系列处理器。
算法复杂性对于芯片算力的依赖始终困扰着整车产品工程。 如何在低成本低功耗的硬件芯片局限下实现高度智能和实时的复杂神经网络,一直是困扰人工智能在汽车行业落地的难题。
魔智能将FPGA方案作为目前最优解。王学海提到,深度学习算法更新迭代迅速,FPGA的可编程性为其提供了灵活性。GPU成本功耗高,DSP并不适用深度学习。大规模量产的ASIC芯片有其成本优势,但当下其无法满足深度学习算法的更新。且因为国内车厂“多品种小批量”的打法,ASIC无法满足多功能的适配和功能的快速迭代。未来算法相对固定、足够的用户基数满足成本分摊,ASIC的优势才会显现。
同时,ADAS产品量产意味着汽车嵌入化平台已满足车规级要求。王学海提到,对于车厂量产来说,诸多公司在后备箱放置的大型演示机箱上量产车几乎成为不可能。而魔视智能已基于FPGA方案自主研发出一套低功耗低成本的小型化嵌入式芯片平台,完成了量产上车之路。
第三点即魔视智能积累的数据高地。成立之初,魔视智能将目光瞄准了深入学习,开始收集道路数据,目前其ADAS产品已经在全国30个省采集视频测试,积累了700万公里的道路数据。 魔视智能也自主并研发了一套高度自动化数据作业体系,通过深度学习算法,对众包数据进行预处理,破除人工打标效率低的壁垒。
自动驾驶汽车的构成
就像科幻电影里出现的那样,自动驾驶汽车有激光雷达,可以对周围半径60米甚至更远的环境进行扫描,并将结果以3D地图的方式呈现出来,给予计算机最初步的判断依据。
有些设计在后视镜附近安置摄像头,用于识别交通信号灯,并在车载电脑的辅助下辨别移动的物体,比如前方车辆、自行车或是行人。
汽车的轮胎上则有位置传感器,它通过测定汽车的横向移动来帮助电脑给汽车定位,确定它在马路上的正确位置。
google公司设计的自动驾驶汽车,安装了4个雷达传感器(前方3个,后方1个),用于测量汽车与前(和前置摄像头一同配合测量)后左右各个物体间的距离。
自动驾驶汽车最重要的主控电脑被安排在后车厢,这里除了用于运算的电脑外,还有拓普康(拓普康是日本一家负责工业测距和医疗器械的厂商)的测距信息综合器,这套核心装备将负责汽车的行驶路线、方式的判断和执行。
至于现在,很多的技术创新,以及人工智能的发展,赋予了自动驾驶更多的功能和能力。
譬如魔视智能科技(海)有限公司针对自动驾驶这一块,就有很多已经成熟的技术和产品问世,并将其应用在自动驾驶汽车上。
1、高级辅助驾驶
出色的夜视效果、识别各种场景,如下雨、下雪等情况、还有车道偏离预警、防碰撞预警、行人碰撞预警、可行驶区域识别、远近灯智能控制、智能交通标志识别、车道保持辅助系统、自主紧急制动系统、自适应巡航控制等。
2、自主泊车
半自动和全自动泊车控制,以及一键式遥控泊车;基于超声与视觉检测的融合结果,覆盖更为广泛的应用场合,提供更安全的自动泊车操作;360°全景环视系统,协助驾驶员检测车辆位置与周边环境。
戴姆勒和博世
戴姆勒和博世此次所展示的自动代客泊车技术,是针对固定停车场所打造的系统,可实现的功能是车辆自动寻找车位并停车,以及车辆自动驾驶至停车场出口位置。对于车主来说,将车辆驾驶至停车场的固定下车点后,仅需在手机APP上确认自动停车后即可离开。自动代客泊车功能的实现,是基于车辆与停车场两方面因素而打造的。在停车场部分,需要对停车场进行一定的改造,停车场必须具备摄像头、雷达、本地服务器、云端后台和互联服务器几大硬件配备。

得益于停车场硬件配置的完整布局,实现自动代客泊车功能的车辆并不用像当下的自动驾驶车辆一样需要多个传感器,自动代客泊车功能仅要求车辆带有电子驻车、电动助力转向、电子挡把、ESP系统、远程车辆启停功能和互联系统。这些硬件配置看似比较繁多,但当下不少车型都已经搭载了这样的配置。
这套自动代客泊车系统的特别之处是将车辆的自动驾驶重任放在了云端后台上,并不依赖与车辆本身的硬件配备,这样做最直接的好处在于降低了车主的使用成本,消费者并不需要为过多的传感器买单,此外,多车同时使用自动代客泊车系统时也更便于计算,以降低事故概率。
实车演示 井然有序/可处理紧急情况

车辆停放至起始区域

通过手机APP控制
系统启动时车辆的识别灯
使用自动代客泊车系统的第一步是驾驶员将车辆停放至起始区域,下车后启动手机APP,点击自动代客泊车即可。在自动代客泊车系统启动后,车辆的转向灯以及尾部高位刹车灯会呈现蓝色状态,以提醒其他车辆。


停车路线的规划是在停车场云端后台的计算下完成的,再通过网络传送至车辆的服务器上,使得车辆在无人的状态下按照规定路线驶入车位并熄火。整个过程中无需人的介入,包括车辆的转向与倒车挡位切换,车辆停好后车主会收到相应提醒。

雷达
云端后台的计算是通过停车场雷达所提供的数据完成的,在地面上有多个这样的雷达桩,停车位的后面也配有同样的装置。停车场布置雷达的方法不仅比在每辆车上都安装传感器的方案成本更低,而且这些雷达的另一个作用是可侦测路面的情况并及时反馈给云端后台。
这样的雷达看似体积不小,其实重要的仅是下面的探测器部分。如果在停车场内布置太多雷达不仅影响美观,而且也进一步占用了停车面积,因此戴姆勒表示,量产后的产品会将雷达系统集成在停车场所需的摄像头内,使其更隐蔽也更美观。

手机APP

驶出车位

模拟路径上的障碍物

车辆可精准刹停
在车主需要离开时,只需抵达停车场出口处的特定区域,并通过手机APP让车辆自动驶出至该区域。在演示过程中,戴姆勒以车模来演示了雷达对路径上障碍物的侦测效果,自动驾驶汽车精准的停在车模之前。此外还用足球来模拟儿童等速度较快物体的突发状况,车辆全都及时的停下。

模拟车辆服务工位

在戴姆勒和博世的构架中,为自动洗车、车辆检测等服务项目预留出了位置。因此接下来的演示中,戴姆勒以两台车同时使用自动代客泊车系统的车辆为例,来演示在服务工位满载的情况下,车辆先停入停车位,之后前往服务工位的情况,两台车均顺利完成。
最后,戴姆勒和博世表示,自动代客泊车系统的开发和使用并不会局限于戴姆勒旗下的车型,而是欢迎其他汽车品牌共同加入其中,在大家的努力下一起打造先进的出行体验。
总结:能够亲身感受到这样一场带有未来感的体验我深感荣幸,但同时我对这套系统的成本、以及在国内交通环境下的可行性也不免有些担心,我希望这套系统能够早日推向市场,但同时也希望这套系统不会仅出现在市中心或高端小区的停车场,不过我也相信戴姆勒和博世会为此而不断努力。