论文翻译《Facial Expression Recognition from World Wild Web》
Facial Expression Recognition from World Wild Web
来自万维网的面部表情识别
摘要
在计算机视觉中,在现实世界中识别人脸表情仍是一个具有挑战的任务。万维网是一个很好的面部图像的来源,其中大部分是在不受控制的条件下拍摄的。事实上,英特网是一个带有表情的面部图像的万维网。这篇论文提供了一项新的研究结果关于在网络中收集、标注和研究真实的面部表情。三个搜索引擎使用六种不同语言中的1250个情感相关的关键字进行检索图片,再由两位注解员将检索的图像映射到六个基本的表情中。深度神经网络和噪声建模被用在三个不同的训练场景中,为了找到当在使用查询词(如happy face、laughing man等)从网上收集到有噪声的图像进行训练时,如何能准确的识别面部表情?我们实验的结果展示了深度神经网络识别真实面部表情准确率为82.12%。
- 介绍
(介绍背景,网上的面部表情图片众多,引出问题)
万维网(也就是Internet)已经变成了一个有着巨大而丰富的信息和数据的资源。尤其是随着社交媒体的发展和使用,以及智能手机上的数码相机的普及,人们可以很容易地通过拍照、写一篇简短的描述,并及时将他们更新到社交媒体,从而将数据添加到互联网上。在互联网上,人们通过做标签(喜欢,不喜欢),或是评论朋友或其他人上传的照片来增加更多的数据。据估计,每天有超过4.3亿张照片被上传到Facebook和Instagram的服务器上[10,4]。在网上上传的这些图片中,人脸图像的出现率最高(比如,如今非常流行的自拍)。这些人脸照片通常是在现实中的自然条件下拍摄的,参数各不相同,例如环境灯光、使用者头部姿势、相机视角、图片的分辨率和背景、被拍摄者的性别、种族、和面部表情等。此外,用户给定的标签使用了宽泛的词汇,来描述图片中的内容如情感、面部特征、和表情。无论是在图像质量/条件,还是用户给出的标签,这些照片是真实环境中的图像。一个有趣的问题是,在网上如何将普通用户给定的面部图像的标签与心理学家定义的六种基本情感相一致。
(采样及现有数据集存在的问题)
另一方面,计算机视觉和识别面部表情的机器学习技术正在融入新一代人机界面的设计中。为了训练机器学习系统,许多研究者已经创建出了使用人类演员/受试者来描述基本情感的数据集。然而,大多数捕获的数据集主要包含在受控环境中获取的摆拍表情。这主要是由于,在实验室环境中,收集摆拍(unpose)的面部表情数据是困难和耗时的。但是,在实际应用中,系统需要捕获和识别自发的表情,这些表情涉及不同的面部肌肉,较少的夸张/强度,比摆姿势的表情有不同的动态。研究者们已经创建了“自发表情数据集”,通过捕获人们在看短视频或填写问卷的时候的表情[7, 17, 18]。但是,这些数据集仍然是在受控的实验室环境中获取的(例如,具有相同的照明、分辨率等),或者对象、种族的数量有限,并且摆出的姿势不能很好地代表现实世界中所面临的环境和条件。现实环境中现有的数据集,如SFEW[3]或FER2013 [6],它们要么非常小,要么分辨率很低,没有用于预处理的面部标志点。
(继数据集难题之后,又提出两个难题)
此外,目前最好的机器学习算法,如深度神经网络需要大量数据训练来对核心算法进行评估。鉴于上述动机,本文提出了我们最近的研究结果,旨在解决以下问题:
- 在面部图像中,如何统一普通用户给定的表情标签和由专家定义的六种基本的表情标签?
- 当对使用查询词(如happy face, laughing man等)从网上收集的面部图像进行训练时,最先进的算法能对图像进行多准确分类?
(解决上述问题的办法:创建数据集—设置训练模式—训练原理)
为了解决这些问题,我们通过查询不同的搜索引擎(谷歌、Bing和Yahoo)创建了一个真实面部表情数据集。然后,我们使用两个人类面部注释器对查询图像的子集进行标注,并展示了搜索引擎对面部表情识别的一般准确性。我们使用不同的训练设置训练了两种不同的深度神经网络架构,即1)训练含有正确标注的清晰数据,2)训练清晰和含有噪声混合的数据,和3)训练清晰和含有噪声混合的,并伴随有使用[38]中引入的通用框架进行噪声建模方法的数据。另一方面,根据给定标注的结果,每个搜索引擎被评估噪声等级作为我们的后验数据集标签上的先验分布,当我们以相同的比例采样噪声标签和真实标签时,可以获得更好的分类性能。为了达到这样的效果,我们学习了一个随机矩阵,其中的元素是混淆标签的概率。从这个矩阵中,我们可以提取数据真实标签上的后验分布,条件是真实标签上有噪声的标签,而有噪声标签上有获得的数据。有关此技术的更多信息,请参见[38]。
(其余内容的概述)
本文的其余部分如下。第2节回顾了现有的数据集和面部表情识别在真实情况下的最先进的方法。第3节解释了从互联网上自动收集大量面部表情图像的方法和由两个专家注释器进行验证的过程。第4节给出了两种不同网络架构在不同训练设置下的训练实验结果,第五部分是本文的总结。
- 真实环境中的面部表情识别
(列举了一些提取特征和分类的方法)
自动面部表情识别(FER)是人机交互(HMI)系统中社交交互的重要部分。传统的面部表情自动识别方法主要包括三个步骤:1)注册与预处理;2)特征提取;3)分类。预处理和注册是AFER管道的重要组成部分。许多研究表明,使用人脸图像注册的优点是,在人脸身份识别和面部表情识别中,提高分类精度[8,27]。在特征提取阶段,许多方法如HOG[17]、Gabor滤波[14]、局部二值模式等(LBP)[31],人脸特征点标定[12],像素强度[19],局部相位量化(LPQ)[43],或使用多种核学习方法的多个特征的组合[41,42],提取鉴别特征。分类是大多数后处理技术的最后一步。支持向量机[43]、多核学习[41,42]、字典学习[20]等已被证明在对前一阶段提取的鉴别特征进行分类方面有很好的表现。
(传统的ML做分类时存在的缺点)
尽管,传统的机器学习方法在受控环境下对摆拍面部表情进行分类时取得了一些成功,但它们不能灵活地对以自发的、不受控制的方式(“在野外”)捕捉的图像进行分类,也不能灵活地将这些图像应用到不是专门为他设计的数据集中。传统方法的泛化能力较差,主要是由于许多方法依赖于主题或数据库,只能识别与训练数据库中类似的夸张或有限的表情。许多FER数据库都严格控制光照和姿态条件。此外,获得准确的训练数据尤其困难,尤其是像悲伤或恐惧这样的情绪,很难精确地复制,而且在现实生活中并不经常发生。
(AFEW和SFEW数据集的优缺点)
近年来,面部表情数据集在真实环境中的应用引起了人们的广泛关注。Dhall等人发布了[2]Acted Facial Expression in the Wild(AFEW),它通过一个基于字幕的推荐系统,通过半自动的方式从电影中挑选图片。AFEW解决了获取面部表情的问题,它是唯一的暂时公开可用的在现实环境中的面部表情数据集。Static Facial Expressions in the Wild (SFEW)(是一个静态的子集),它是通过选择静态帧创建的,它涵盖了不受约束的面部表情,不同的头部姿势,年龄范围,接近真实世界的照明。然而,它只包含1635张图片,数据库集只有95个对象。此外,由于数据集的本身设置,所发布的人脸位置和标识并不能正确地捕获所有图像中的人脸,使得一些训练和测试样本无法使用(见图1)。

图1.来自SFEW[3]的图像样本和它们在数据集中发布的原始注册图像。
(FER2013数据集的由来及缺点)
在ICML 2013表示学习挑战赛中引入了面部表情识别2013(FER-2013)数据集。该数据集是使用Google图片搜索API创建的,该API与一组184个与情感相关的关键字匹配,用以捕获六个基本表情以及中性表情。由人类标签员拒绝不正确的标签图像。图像被调整为48x48像素,并转换为灰度。由此产生的数据集包含35887张图片,其中大部分是符合现实环境的,但只有547张是厌恶的表情的。图2显示了FER2013的一些示例图像。FER2013是目前在现实环境中最大的公开可用的面部表情数据集,使得许多研究人员能够训练需要大量数据的机器学习方法,如深度神经网络。但是,如图2所示,人脸并没有被注册,不幸的是,大多数的人脸标识(facial landmark)探测器都不能提取出这种分辨率和质量的人脸标识(facial landmark)。

图2.来自FER2013数据库[6]的图像样本
(困难的现实)
另外,真实环境中的FER无论对于机器还是人类都是一个具有挑战性的任务。在[5]中进行的大量实验表明,即使是人类,在不听音频的情况下,对所有类别的AFEW视频剪辑进行分类,在Fleiss kappa方面也只有53%的人达成一致。最先进的自动化方法已达到35%的准确性,对几个视频剪辑使用音频模式[44]。即使使用传统的机器学习方法从静态图像或静态帧中识别表情也不是很准确,而且在SFEW 2.0数据库报告中最好表现的准确率为50%(基线为39.13%)。
最近,深度神经网络又重新流行起来。最近,使用在视觉对象识别中的神经网络已产生最优的结果。使用神经网络在视觉对象识别[13,33],人体姿势估计[36],面部验证[34]等领域获得了最新的技术成果。到目前为止,即使在FER领域,结果也是乐观的[11、21、15、11],大多数面部表情识别挑战赛的获奖者都使用了深度神经网络[35、40]。
(FER问题中可用于训练的数据集很少,且相对单一)
然而,在FER问题中,与imageNet[1]等可视化对象数据集不同,现有的FER数据集通常对象数量有限,每个表情的样本图像或视频很少,或者数据集之间的差异很小,这使得神经网络的训练难度大大增加。例如,FER2013数据集[6](最近发布的最大的FER数据集之一)包含35887张不同对象的图片,但只有不到2%的图片表现出厌恶。类似地,CMU的MultiPIE face数据集[9]包含大约75万张图像,但仅有337个不同的实验对象,其中34.8万幅图像只描绘了一种“中性”的情绪,其余的图像没有描绘愤怒、恐惧或悲伤。
(2016年的一次尝试,适用于摆拍图像,在真实环境中表现不突出)
在最近的一项研究[21]中,作者提出了一种深度神经网络架构,并结合了7个著名的面部表情数据集(即MultiPIE、MMI、CK+、DISFA、FERA、SFEW和FER2013)对独立于主题的数据集和跨数据集进行了广泛的研究。所提出的网络结构的结果可与最先进的方法相媲美或更好,但是,大多数数据仍然是摆拍图像,在真实环境中的数据集(SFEW和FER2013)上的性能只能与之前最先进的方法相似。
(需要开发一个在真实环境中的FER)
考虑到需要开发一个可以在真实环境中运用的自动FER系统,以及目前在真实环境中面部表情难以获取的问题,一种可能的解决方案是从互联网上丰富的图像中自动收集大量的面部表情图像,并且直接将它们作为真实样本训练深层神经网络模型。但是,应该考虑避免在搜索引擎结果中出现厌恶或恐惧等表情的虚假样本。这是因为人们更倾向于发布快乐或中性的面部图片,而这些面部图片可能被网络用户贴上错误的标签,可能与厌恶或恐惧联系在一起。
尽管如此,半监督的[37]、转移学习[24]或噪声建模方法[32,38]可以通过从搜索引擎获得大量的面部表情图像,以及更小的完全标记良好的图像子集,来训练具有噪声数据的深度神经网络。
- 来自网络的面部表情
(我们创建的数据集的方法及规模)
为了建立一个包含大量深度神经网络所需图像的数据集,我们用六种不同语言的面部表情相关标签对三个搜索引擎进行了查询。我们使用了谷歌、Bing和Yahoo。其他搜索引擎如百度和Yandex也在考虑之列。但是,它们都没有产生高比例的预期图像,也没有用于自动查询并将图像url放入数据集的API。
在六种语言中,总共有1250个搜索查询语句被编译,然后在我通过爬取网络的搜索引擎获取的图片的URL,存储在我们的数据集中。每个查询语句返回的前200个url存储在数据集中(258,140个不同的url)。在258140个网址中,有201932张图片可供下载。使用OpenCV人脸识别获取每个人脸周围的边界框。采用主动外观模型(Active Appearance Model, AAM)[23]的双向翘曲和通过回归局部二进制特征的人脸对齐算法[26,39]提取66个面部标志。使用“300W竞赛”提供的标注训练面部标志定位技术进行训练。在接下来的处理阶段中,至少保留一个具有面部标识点的面部。总共保存了119481幅图像。如果适用,则存储查询的其他属性,例如;期望的情感,性别,年龄,语言搜索,以及它的英语翻译(如果不是英语)。
(专家注释器的分类标准,共分为10类)
每个被查询的情绪平均随机选择4000张图像,总共24000张图像交给两名专家注释器,将图像中的面部分为9类(即无面部,6种基本表情,中性、无、不确定)。注释器被要求在面部选择合适的表情类别,只要面部表情符合预期,表情的强度并不重要。No-face类别定义为:1)图像中无脸;2)脸上有水印;3)包围框不是在脸上或没有覆盖大部分的脸;3)面部是绘画、动画、绘制或打印在其他东西上的;4)虽然可以推断出一个表情,但是面部扭曲超出了自然或正常的形状。None类被定义为描述一种情绪的图像,但其表情/情绪可以被归类为六种基本情绪之一或中性图片的任意一类(如困倦、无聊、疲倦、诱惑、困惑、羞愧、专注等)。如果注释器对每种面部表情都不确定,那么图像就被标记为uncertain。图3显示了每个类别的一些示例以及用括号编写的查询语句。

图3. 来自web的查询图像及其注释标记的示例。括号中为查询的表情。
(24000幅图像的分类结果)
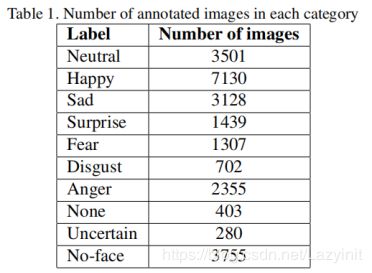
标注内容被表现为全盲和独立的,即注释器不知道预期的查询或其他注释器的响应。在63.7%的图像中,两位注解员的标注结果一致。对于标注结果不一致的图像,将偏向预期的查询表情,即如果其中一个注释器将图像标记为预期的查询,则图像将在数据集中标记为预期的查询。29.5%的图像有以上情况,剩下的结果不一致的图像,将被随机分配一个注解(由两位注解员中的任意一个分配注解)。由两位注释员给24000幅图像添加注解,表1显示了每个类别的图像数量。如图所示,尽管查询次数相同,但厌恶、恐惧和惊讶等表情与其他表情相比图像较少。
(六种基本表情与10类标记的混淆程度)
表2显示了查询的情绪和它们的注释之间的混淆矩阵。如图所示,高兴的命中率最高(68%),其他情绪的命中率低于50%。由于许多来自网络的图像都包含水印,绘图等,因此所有的情绪都与No-Face类别约有15%的混淆。在所有情绪中大约有15%与中性表情混淆。厌恶和愤怒相比于其他的情绪有最低的命中率,分别为17%和12%,大多数愤怒和厌恶的结果主要与高兴和No-Face类别相混淆。
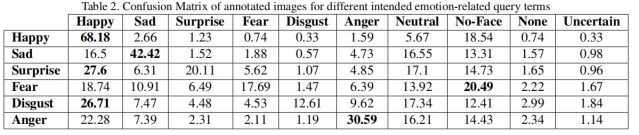
表2.针对不同的与情绪相关的查询词的注释图像的混淆矩阵
- 网络图片的训练
(训练规模)
这些标注了6种基本表情和中性面孔的注释图片是从24000张注释图片(18674张)中挑选出来的。每个标签标注的图片中20%被随机选择作为一个测试集(2,926张图片),其余用作训练和验证集。共选择60K未加注释的图像(每个基本表情10K)作为噪声训练集。
(三种训练场景,两个神经网络架构)
作为基线,两种不同的深度神经网络架构在三种不同的训练场景中进行训练:1)对标记良好的图像进行训练,2)对噪声和标记良好的集合进行混合训练,3)对噪声和标记良好的集合进行混合训练,使用[38]中引入的噪声建模方法。我们在这些实验中使用的网络架构是AlexNet[13]和一个最近在WACV2016上发表在[21]上的面部表情识别网络,本文其余部分称为WACV-Net。所有网络都是在一个标记良好的测试集上进行评估的。
(AlexNet与WACV-Net的网络架构)
AlexNet由5个卷积层和3个完全连接层组成,其中一些层后面是最大池化层。为了增大数据,十组大小为227*227像素的注册面部图像被输入AlexNet。我们尝试了一个更小的AlexNet版本,它的输入图像更小,分辨率为40x40像素,卷积核尺寸也更小,但是结果并不像原来的模型所期望的。WACV-Net由两个卷积层组成,每个卷积层后面是最大池、四个初始层和两个全连接层。输入图像被调整为48x48像素,增加了10组40 x40的像素的图片。由于Inception层的尺寸减小,我们的AlexNet版本执行了超过1亿次操作,而WACV-Net执行了大约2500万次操作。因此,WACV-Net的培训速度几乎是AlexNet的四倍,因此评估时间也更快。
(具体训练过程及结果)
在第一个场景中,网络只训练具有随机初始化的良好标记集。在第二种场景(噪声和标记良好的集合的混合)中,仅使用标记良好的数据对网络进行预训练,然后对噪声和标记良好的集合进行混合训练。与从零开始训练混合了有噪声和标记良好的集合的训练相比,这种方法的准确率提高了约5%。在最后一种情况下(使用噪声模型将嘈杂的和标记良好的集合混合在一起),因为如果网络被随机初始化,则后验计算可能是完全错误的[38],因此网络组件将使用标记良好的数据进行预训练。此外,我们引导/提升标记良好的数据到一半有噪声的数据。在所有场景中,我们都使用了256个小批处理大小。初始化学习率为0.001,每10000次迭代后除以10。我们不断地训练每个模型直到收敛。表3显示了在三种训练场景下在测试集上的AlexNet和WACV-Net的总体识别准确性。如表所示,在所有情况下,AlexNet的性能都优于WACV-Net。对混合噪声和良好标记数据的训练不如仅对良好标记数据的训练效果好。我们认为,这是由于从网络上抓取的面部表情图像是非常嘈杂的,在大多数表情中,只有不到50%的嘈杂数据描述了预期的查询。噪声估计方法可以提高训练在混合噪声和良好标记集上的网络的精度。最好的结果是在标记良好的数据上训练AlexNet。这比使用噪声建模对混合噪声和标记良好的集合进行训练的总体精度(1%)稍好一些。

表3.不同训练设置下,AlexNet和WACV-Net在标记良好的测试集上的识别精度
表4显示了在标记良好的集合上训练的AlexNet的混淆矩阵。表5给出了训练在噪声估计[38]下的混合噪声和标记良好的集合上的AlexNet的混淆矩阵。从表中可以看出,噪声估计方法可以提高悲伤、惊讶、恐惧和厌恶表情的识别精度。原因是,与其他标签相比,标记良好的集合中这些表达式的样本更少,因此,如果后验分布估计良好,则包含噪声数据会增加训练样本。然而,在某些情况下,如中性脸和愤怒脸,只训练标记良好的数据具有更高的识别精度,由于良好标记集上的先验分布可能不能完全反映噪声集上的后验分布。

表4.在良好标记设置下AlexNet训练的混淆矩阵
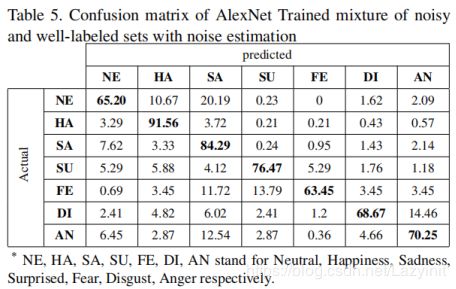
图4显示了一组随机选择的图像样本,这些图像被AlexNet错误分类,AlexNet对标记良好的图像进行了训练,括号中给出了相应的ground-truth。如图所示,很难对一些图像进行分类。例如,我们无法正确地分类第一行中的图像。此外,第二排的图片与分类错误的标签有相似之处,比如厌恶地皱起鼻子,或惊讶地扬起眉毛。需要指出的是,将复杂的面部表情归类为离散的情绪是非常困难的,尤其是在现实环境下。

- 总结
面部表情识别在野外环境中非常具有挑战性。目前的真实环境中的数据集要么非常小,要么分辨率很低,没有面部标识点进行预处理。互联网是一个巨大的图像资源,据估计,每天仅在社交网络服务器上就有超过4.3亿张照片被上传。大多数的图片都包含了人脸,这些人脸都是在不受控制的环境下拍摄的,比如灯光、姿势等等。事实上,这是一个面部图像的网络,它可以是一个巨大的资源,捕捉数以百万计的不同对象、年龄和种族的样本。
在三个训练情境中训练了两个神经网络架构。结果表明,即使采用噪声估计方法,仅对标记良好的数据进行训练也比对噪声和标记良好的数据的混合训练具有更高的总体精度。噪声估计可以提高悲伤、惊讶、恐惧和厌恶表情的准确性,因为在标记良好的数据中样本有限。但是,仅对标记良好的数据进行训练仍然具有更高的总体准确性。究其原因,正如网络图片注释所显示的那样,从网络上查询到的大部分面部图片都有色差。
整个数据集、查询术语、带注释的图像子集及其面部标识点将向研究社区公开。