排序相关选择题
1.The best time complexity of quick sort algorithm is:(C)
A:O(lgn)B:O(n)C:O(nlgn)D:O(n*n)快排时间复杂度:最好O(nlgn),平均O(nlgn),最坏O(n^2); 这里问的是最好情况下
快排、堆排序、归并排序的平均时间复杂度为O(nlgn);
冒泡、选择排序O(n^2)
计数排序O(n^1.3)
2.c中,二维数组初始化的方法是:int a[3][3]={{1},{2},{3}};说法是否正确? (A)
A:正确B:错误二维数据就是以数组为元素的数组,外面的大括号表示这个数组,里面的大括号表示数组形式的元素,只有一个数字说明元素只赋了A[0][0],A[1][0],A[2][0],其余元素都没赋值
3.有个长度为12的无重复有序表,按折半查找法进行查找,在表内各元素等概率情况下,查找成功所需的平均比较(三元比较)的次数为(B)
A:35/12B:37/12C:39/12D:43/12已知元素序号(即下标)范围为1~12。查找1次成功的结点为:6。查找2次成功的结点为:3,9。查找3次成功的结点为:1,4,7,11。查找4次成功的结点为:2,5,8,10,12。成功查找所有结点的总的比较次为:1×1+2×2+3×4+4×5=37平均比较次数为37/12。
4.请问对一个排好序的数组进行查找,用平均时间复杂度最小的算法,时间复杂度为(B)
A:O(n)B:O(lgn)C:O(nlgn)D:O(1)已知数组顺序了,二分查找法复杂度最低
5.若数组A[0…m-1][0…n-1]按列优先顺序存储,则aij地址为( A)。
A:LOC(a00)+[j*m+i]B:LOC(a00)+[j*n+i]C:LOC(a00)+[(j-1)*n+i-1]D:LOC(a00)+[(j-1)*m+i-1]将i,j=0代入,排除C,D;(这个只是排除错误答案) 2.因为列主序,所以aij前有j列*m个+i个元素。
6.二维数组k[1..7,1..9],每元素大小占2个字节,而且使用列存储,a[5,4]的偏移量为(D)个字节。
A.78B.39C.25D.50首先可以确定的是9行7列,问题中的a[5][4]指的是在第五列的第四个,这个地方大家可能误解了,还有就是二维数组转化成一维数组的公式a[x][y]=b[x*列数+y],其中的x,y的起始地址为0,不是1,所以这题应该减一,也就是a[4][3],3*7+4=25,再乘以2 偏移量= 起始地址 + (a[1][1] + a[2][1] + a[1][2]) * size
7.在154个元素组成有序表进行二分法查找,可能的比较次数为(BCD)
A.10B.8C.4D.11.在这里光判断[log2(154)] = 7,最差的情况下找8次,所以8次及8次以内都有可能找到
2.折半查找过程可用二叉树来描述,把有序表中间位置上的结点作为树的根结点,左子表和右子表分别对应树的左子树和右子树。折半查找的过程就是走一条从根节点到被查结点的一条路径,比较的次数就是该路径中结点的个数,即,该结点在树中的层数。 所以该题可以转换为求有154个结点的二叉树有几层,小于等于这个层数的数值就是答案。 又知,深度为K的二叉树最多有2的K次方-1个结点,深度为7的二叉树最多有127个结点,深度为8的二叉树最多有255个结点,所以154个结点的二叉树有8层。
8.Which of the following sorting algorithm(s) is(are) stable sorting?(AD)
A.bubble sortB.quick sortC.heap sortD.merge sortE.Selection sort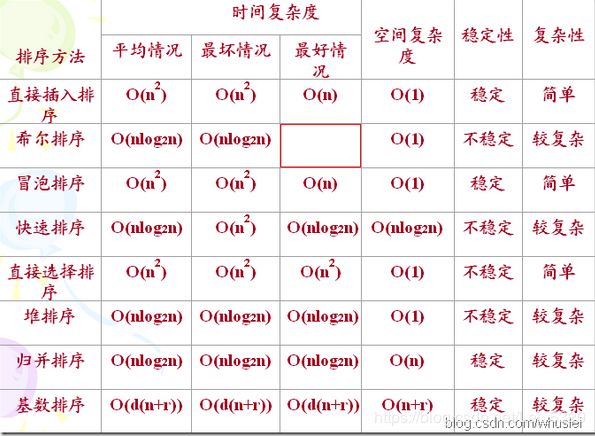
口诀:“一堆希尔快选” 都是不稳定 其他都是稳定的
9.设有序顺序表中有n个数据元素,则利用二分查找法查找数据元素X的最多比较次数不超过(D)。和第7题一样
A.log2n+1B.log2n-1C.log2nD.log2(n+1)10.在有序表( 7, 13, 33, 87, 99, 97, 117, 123,129,131,137)中,使用二分查找算法查找13时需要的关键字比较次数是(A)
A.4B.3C.2D.5mid=(left+right)//2=5 num[5]=97 13<97 right=mid-1=4
mid=(left+right)//2=2 num[2]=33 13<33 right=mid-1=1
mid=(left+right)//2=0 num[0]=7 13>7 left=mid+1=1
mid=(left+right)//2=1 num[1]=13 13==13 break
注意:最后确定的那一次还要判断
11.字符串 "YONYOU",有几种不同的全排列方式?(A)
A.180B.720C.120D.540如果六个字母不同则有A66 种方法
但有两个字母重复,一个字母重复是除以2,两个就是A66 /4=180
12.数组 A[0…5 , 0…6] 的每个元素占 5 个字节,将其按列优先次序存储在起始地址为 1000 的内存单元中,则元素 A[5 , 5] 的地址为(A)
A.1175B.1180C.1205D.1210数组 A[0…5 , 0…6] 等价于A[7][6]
a[5][5]是第6行第6个元素(下标从0开始的)
元素A[m][n] 的地址= (m*6+n)*5+1000.
A[5][5]的地址=1175
13.一个有序数列,序列中的每一个值都能够被2或者3或者5所整除,这个序列的初始值从1开始,但是1并不在这个数列中。求第1500个值是多少?(C)
A.2040B.2042C.2045D.2050先考虑一个循环有多少 最多在公倍数处
能被2整除的数有 30 / 2 = 15 个,
能被3整除的数有 30 / 3 = 10 个,
能被5整除的数有 30 / 5 = 6 个,
能被2整除也能被3整除的数有 30 / 6 = 5 个,
能被2整除也能被5整除的数有 30 / 10 = 3 个,
能被3整除也能被5整除的数有 30 / 15 = 2 个,
能被2整除、能被3整除也能被5整除的数有 30 / 30 = 1 个,
下来避免重复的能被2整除或能被3整除或能被5整除的数的个数为: 15 + 10 + 6 - 5 - 3 - 2 + 1 = 22
也就是说1500个值重复了多少次 1500/22==68 余4 那么 68*30=2040 加上第4处的5就是2045
所以说1500个值是2045
14.在一个有8个int数据的数组中,随机给出数组的数据,找出最大和第二大元素一定需要进行(B)次比较:
A.8 B.9 C.10 D.11
从图中不难看出第一次找到最大A需要7次比较,那么找次大值找出除过A和本身其他的元素比较,因为A为最大已经比较了其他的6个元素只需要用B和剩下的两个元素比,那么剩下的两个元素比加1次,B和这两个其中大的比较也加1次,所以总共9次。
15.下列关于ASCII码和十进制的对应关系说明错误的是?(C)
A.0--48, 9--57B.A--65 , Z--90C.a--98 , z—123D.B--66 ,F-700--48 9--57
A--65 Z--90
a--97 z—122
十进制:decimal,简称:DEC
16.为了确定下一条微指令的地址,通常采用的断定方式,其基本思想是。"通过微指令顺序控制字段由设计者指定或由设计者指定的判别字段控制产生后继微指令地址"
17.递归函数中的形参是(A)
A.自动变量B.外部变量C.静态变量D.可根据需要自定义存储类型可以这样说递归函数是在栈里实现的,那么自动变量就是存储在栈里的,随着递归那么自动创建和销毁,外部变量和静态变量存放在静态存储区。外部变量和静态变量是不能作为递归函数的参数的。自动变量可以大体上等价于局部变量。但也不完全相同,递归的过程中,会创建变量存放在栈顶,
18.有两个32bit的数A、B,使用下面方式得到32bit的数C、D。哪一种可以使用C、D得到A、B的值?(C)
A.C=(int32)(A+B),D=(int32)(A-B)B.C=(int32)(A+B),D=(int32)((A-B)>>1)C.C=(int32)(A+B),D=BD.C=(int32)(A+B),D=(int32)(A+2*B)E.C=(int32)(A+B),D=(int32)(A/B)这题主要考察是否超过int范围
A选项中: C=(int32)(A+B),D=(int32)(A-B) ,如果能表示,则表示成A=(C+D)/2,B=(C-D)/2,考虑到C-D=(A+B)-(A-B)=2B,虽然B在这个范围内,但是2B有可能超出了32位Int类型的表示范围了。
B,D,E选项同理都有可能超出32位int类型的表示范围。
C选项中,C=A+B,D=B,得到A=C-D,B=D,根据原式C-D=A+B-B=A,D=B,肯定不会超出范围。
19.Unicode缺省是否用16位来表示一个字的。(A)
A.对
B.错
Unicode字符编码标准是固定长度的字符编码方案,有8位和16位(两个字节)两种格式,缺省的格式是16位的。
20.请指出堆排序、选择排序、冒泡排序、快速排序、的时间复杂度(A)
A.nlogn、n^2、n^2、nlognB.n^2、n^2、n^2、nlognC.nlogn、nlogn、n^2、nlognD.nlogn、n^2、n^2、n^2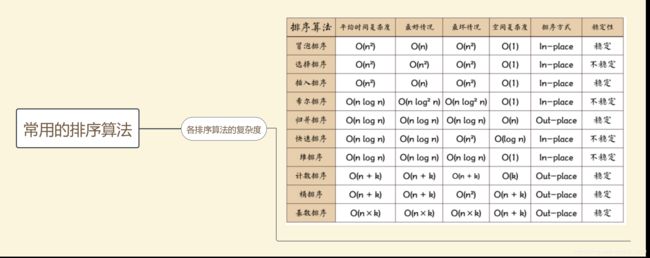
O(n2)级别有冒泡排序,选择排序,插入排序
O(n log n)级别有希尔排序,归并排序,快速排序,和堆排序
O(n+k)级别计数排序,桶排序
O(n×k)级别基数排序
21在有序表中,关于斐波那契查找和折半查找说法错误的是(ABC)
A.就平均性能而言,斐波那契查找的平均性能比折半查找差B.只有有序表中元素个数n等于某个斐波那契数时才能用斐波那契查找算法C.在最坏情况下,斐波那契查找的性能比折半查找好D.折半查找时间复杂度为O(log2n)A:平均性能是斐波纳切黄金分割查找更好
B:有序表长度不需要一定要是一个斐波纳切数才行,是可以补齐成为一个斐波纳切数的 补最大的数目直到长度是斐波纳切数
C:最坏情况下斐波纳切查找性能比折半是要差的
22.
解析:最快的就是 直接用log2(13)向上取整数 4
23.想制作一首大约一分半钟的个人单曲,具体步骤是 A 。
①设置电脑的麦克风录音②在“附件”的“录音机”中录制人声③从网上搜索伴奏音乐④在 COOLEDIT 软件中合成人声与伴奏
A.①②③④
B.③①④②
C.④①③②
D.①②④③
24.fun((exp1,exp2),(exp3,exp4,exp5))有几个实参?(A)
A.2
B.5
C.1
D.3
有两个实参,(exp1,exp2)和(exp3,exp4,exp5),每个实参都是一个元组
25.要交换变量A和B的值,应使用的语句组(B )
A.A=B;B=C;C=A
B.C=A;A=B;B=C
C.A=B;B=A
D.C=A;B=A;B=C
26.下列关于排序算法中的说法中,错误的有(D)
A.在待排序的元素序列基本有序的前提下,效率最高的排序方法是插入排序
B.堆排序的时间复杂度为O(nlogn)
C.关键字比较的次数与激励的初始排列次序无关的是冒泡排序
D.快速排序是一种稳定的排序算法
A:如果数组有序的话,插排只要O(n)
B:堆排序的时间复杂度为O(nlogn)
C:冒泡排序,每一趟都是两两相邻比较,(但是如果一趟中没有发生数据交换,可以结束循环),C不确定吧
D:稳定排序:冒泡,插排,归并
27.矩阵中的数据元素可以是不同的数据类型 ,这样的说法正确吗?(B)
A.正确
B.不正确
28.已知 x=101010B ,对 x 按位求非,结果是 (C )
A.000010B
B.010110B
C.010101B
D.000000B
0变成1,1变成0.。。B代表二进制
29.下列关于计算机存储容量单位的说法中,错误的是(C)
A.1KB<1MB<1GB
B.基本单位是字节(Byte)
C.一个汉字需要一个字节的存储空间
D.一个字节能够容纳一个英文字符
通常1个字节可以存入一个ASCII码,2个字节可以存放一个汉字国标码。UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节
Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节
30.命令 A>CD TEST 的执行结果是 (B )
A.查询TEST子目录
B.进入TEST子目录
C.建立批文件TEST.BAT
D.建立新的子目录TEST
31.三元操作,哪个语法是正确的?(A)
A.var x=y===true?”true”:”false”;
B.var x=y===true:”true”?”false”;
C.var x=(y===true):”true”?”false”;
D.var x=(y===true){“true”:”false”};
三元运算符的格式是:a ==b ? a : b,所以A正确。===表示同一类型变量的比较,将比较结果给x赋值
32.用高级语言编写的源程序转化为可执行程序,必须经过(C)
A.汇编和解释
B.编辑和链接
C.编译和链接
D.解释和编译
一个计算机程序执行的过程可分为编辑、编译、连接和运行四个过程。用高级语言编写程序的过程称为编辑,之后利用编译程序从源语言编写的源程序产生目标程序的过程称为编译,翻译完的目标程序不能立即被执行,要通过连接将目标程序和有关的系统函数库以及系统提供的其他信息连接起来,形成一个可执行程序。综上所述,用高级语言编写的源程序,将其转化成能在计算机上运行的程序过程是编辑、编译、连接。
33.下面关于查找算法的论述中哪个不是正确的?(A)
A.顺序查找需要查找表为有序表
B.折半查找需要查找表为有序表
C.查找表可分为静态查找表和动态查找表
D.动态查找表的特点是表结构本身在查找过程中动态生成的
简而言之,动态查找表的结构是可以随时修改或变化的,表结构本身在查找过程中动态生成,一般而言链式结构有这个特征,比如二叉查找树、三棵B树等,另外,基于顺序存储的Hash查找应该也算动态查找表;而静态查找表的结构一次性生成后就不再允许改变,就像在有序数组上使用折半查找那样。
34.在一个长度为n的顺序表中删除第i个元素(1<=i<=n)时,需向前移动 () 个元素(A)
A.n-i
B.n-i+l
C.n-i-1
D.i
第i个元素是a[i-1] 1-2-3-4-5-6-7-8-9-10 第3个元素,后面有4-5-6-7-8-9-10,10-3个。
最简单的就是当i=n时
35.常用的虚拟存储系统由()两级存储器组成,其中辅存是大容量的磁表面存储器。(A)
A.主存——辅存
B.Cache——辅存
C.主存——Cache
D.通用寄存器——主存
“虚拟存储”机制的提出主要是为了解决实际运行内存(主存)空间不足的问题:
在内存资源紧张的情况下,系统会把一部分短期内不会使用的数据从主存中移动到硬盘(辅存)里去,以释放出一部分内存空间供当前执行的程序使用。而当位于虚拟存储空间(硬盘)中的数据要被使用时,再把这些数据调回内存(主存)中。这样子,给人的感觉就好像内存空间变大了,虚拟存储系统主要由 “主存” 和 “辅存” 二级存储器组成:主存用于当前运行,特点是读写速度相对快、空间相对小;而辅存用于临时保存数据(以释放主存空间),特点是读写速度相对慢、空间相对大。
36.无符号数,下列数中最大的数是(A)
A.(100110001)2
B.(227)8
C.(98)16
D.(152)10
都转换为10进制比较,
A:2^0+2^4+2^5+2^8=305;
B:7*8^0+2*8^1+2*8^2=151;
C:8*16^0+9*16^1=152;
37.假设线性表的长度为n,则在最坏情况下,冒泡排序需要的比较次数为多少次?(C)
A.nn的二次方
B.n的二次方/2
C.n(n-1)/2
D.n(n+1)/2
首先最坏的情况是,全部逆序排序,然后依次比较(n-1)+(n-2)+...+1=n(n-1)/2,
例:8 7 6 5 4 3 2 1
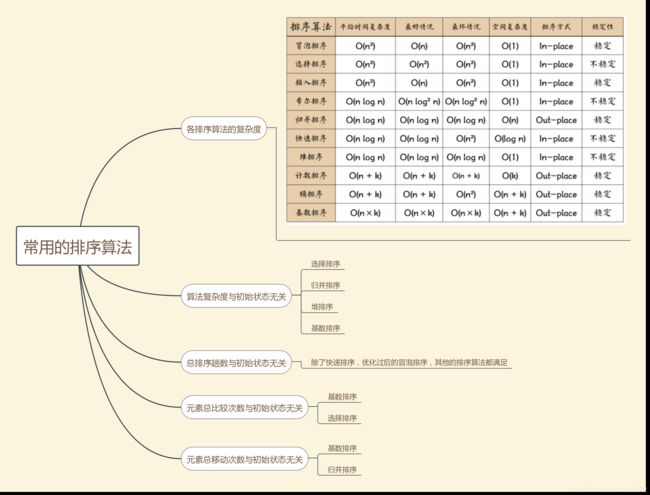
38.在最好情况下,下列排序算法中 排序算法时间复杂度最低的是。(B)
A.基数排序
B.直接插入排序
C.快速排序
D.归并排序
39.在用邻接表表示图时,拓扑排序算法时间复杂度为(D)
A.O(n)
B.O(n*n*n)
C.O(n*n)
D.O(n+e)
若为避免重复检测入度为零的顶点,使用栈来保存所有入度为零的顶点。对有n个顶点和e条弧的有向图而言,建立求各顶点的入度的时间复杂度为O(e);建零入度顶点栈的时间复杂度为O(n);在拓扑排序过程中,若有向图无环,则每个顶点进一次栈,出一次栈,入度减一的操作在while循环中总共执行e次,所以总的时间复杂度为O(n+e)。
40.数据表A中有10000个元案,如果仅要求求出其中最大的10个元素,则采用(C)排序算法最节省时间。
A.简单选择排序
B.希尔排序
C.堆排序
D.快速排序
41.int (*p)[3] p的含义是什么?(B)
A.一个指向int元素大小为3的指针数组
B.一个指向元素个数为3的int数组的指针
C.不合法
D.以上说法都不正确
1、int(*p)[4];------ptr为指向含4个元素的一维整形数组的指针变量(是指针) 2、int *p[4];-------定义指针数组p,它由4个指向整型数据的指针元素组成(是数组) 3、int(*)[4];--------实际上可以看作是一种数据类型。也就是第一个(int(*p)[4];)
42.显示C盘根目录下B5.PRG文件内容的DOS命令是( B )
A.DIR B5.PRG
B.TYPE C:\B5.PRG
C.DIR C:\B5.PRG
D.TYPE C:\B*.PRG
显示文件内容命令——type命令 1、格式:type [盘符:] [路径] 文件名 2、类型:内部命令 3、功能:把指定的文件内容在屏幕上显示或打印机输出,它常用作查阅和显示文本文件的内容和打印。
43.(1)静态链表既有顺序存储的优点,又有动态链表的优点。所以,它存取表中第i个元素的时间与i无关。
(2)静态链表中能容纳的元素个数的最大数在表定义时就确定了,以后不能增加.
(3)静态链表与动态链表在元素的插入、删除上类似,不需做元素的移动。
以上错误的是(B)
A.(1),(2)
B.(1)
C.(1),(2),(3)
D.(2)
静态链表是用数组存储节点数据,模拟链表的实现,但是没有用到指针。每个数组节点包括两部分:data域和cursor(游标)域。data存储数据,cursor指明下个元素在数组中的下标。
(1)存取第i个元素时,需要从头遍历到i-1和元素,由第i-1个节点的cursor,才能知道第i个元素存储的位置,因此和i是相关的。
(2)使用数组对元素进行存储,在定义时大小已经确定。
(3)插入和删除操作无需移动元素,只需要修改cursor游标的值即可,就像修改动态链表中的指针一样
44.char s[ ]=”china”; char *p; p=s;
则下列叙述中正确的是( D)。
A.s 和 p 完全相同
B.数组 s 中的内容和指针变量 p 中的内容相等
C.s 数组长度和 p 所指向的字符串长度相等
D.*p 和 s[0]值相等
1、首先明确的是两者都是指针,本质上两者是一样的东西,但代表的不一样。
2、s是作为一个数组的起始地址,仅仅保留了数据的起始地址即s【0】;为此s=p也就是说p也会保留s【0】的地址;故*p=s【0】
45.设A、B、C为任意集合,下面的命题为真的是(E)
A.如果A-B=Ø,则A=B。
B.如果A-C=B-C,则B=C。
C.如果A∪B=A∪C,则B=C。
D.如果A∩B=A∩C,则B=C。
E.Ø是Ø的子集。
1. 如果A-B=Ø,则A=B。反例:A{1,2}-B{1,2,3,4} = Ø,but A != B
2. 如果A-C=B-C,则B=C。反例:A{1,2}-C{1,2,3,4} = B{3,4}-C{1,2,3,4},but B != C
3. 如果A∪B=A∪C,则B=C。反例: A{1,2}∪B{1,2,3,4} = A{1,2}∪C{3,4},but B!=C
4. 如果A∩B=A∩C,则B=C。反例:A{1,2}∩B{3} = A{1,2}∩C{4},but B!=C
5. 正确结果:Ø是Ø的子集。Ø是任何集合的子集。
46.以下正确的函数原型声明语句是( )。
A.double fun(int x,int y)
B.double fun(int x;int y)
C.double fun(int,int);
D.double fun(int x,y);
/C++中的函数原型是指函数声明的形式返回值类型 函数名(参数列表);。注意分号是函数原型的组成部分,去掉分号的部分可以称为函数头,是函数定义的起始部分。 这里的参数列表和定义中的列表语法形式相同,其中的参数是形式参数,只需要指定类型,名称可有可无。
47.零地址的运算类指令在指令格式中不给出操作数地址,参加运算的两个操作数来自(C )
A.累加器和寄存器
B.累加器和暂存器
C.堆栈的栈顶和次栈顶单元
D.暂存器和堆栈的栈顶单元
累加器一般都是一地址指令将另一个数放在累加器!操作后,累加器用于存放结果!
48.广义表中的元素或者是一个不可分割的原子,或者是一个非空的广义表()
A.对
B.错
非空的广义表中的元素或者是一个不可分割的原子,或者是一个非空的广义表,题目描述错误
49.如果原信息为1111011,特征多项式为X 3 +X 2 +1,则CRC校验码为 。
A.101
B.100
C.111
D.011
多项式最高次为3,则校验位有3位,在源信息后面需加3个0,即1111011000,再跟多项式的二进制1101进行异或运算。
多项式转为2进制数:1101
与源信息按位异或
1111011000
1101
---------------
0010011000
1101
--------------
01001000
1101
--------------
00100000
1101
--------------
00010100
1101
--------------
00001110
1101
--------------
00000011
50.数组指针和指针数组有什么区别 ?(AC)
A.数组指针只是一个指针变量,它占有内存中一个指针的存储空间
B.指针数组只是一个指针变量,它占有内存中一个指针的存储空间
C.指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间
D.数组指针是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间
数组指针(也称行指针)
定义 int (*p)[n];
()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。如要将二维数组赋给一指针,应这样赋值:
int a[3][4];
int (*p)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
p=a; //将该二维数组的首地址赋给p,也就是a[0]或&a[0][0]
p++; //该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]所以数组指针也称指向一维数组的指针,亦称行指针。
指针数组
定义 int *p[n];
[]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1是错误的,这样赋值也是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样 *p=a; 这里*p表示指针数组第一个元素的值,a的首地址的值。
如要将二维数组赋给一指针数组:
int *p[3];
int a[3][4];
for(i=0;i<3;i++)
p[i]=a[i];
这里int *p[3] 表示一个一维数组内存放着三个指针变量,分别是p[0]、p[1]、p[2]
所以要分别赋值。这样两者的区别就豁然开朗了,数组指针只是一个指针变量,似乎是C语言里专门用来指向二维数组的,它占有内存中一个指针的存储空间。指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间。
还需要说明的一点就是,同时用来指向二维数组时,其引用和用数组名引用都是一样的。
比如要表示数组中i行j列一个元素:*(p[i]+j)、*(*(p+i)+j)、(*(p+i))[j]、p[i][j]
51.Which statement declares a variable a which is suitable for referring to an array of 50 string objects?(Java)(BCF)
A.char a[][];
B.String a[];
C.String[] a;
D.Object a[50];
E.String a[50];
F.Object a[];
在java 中,声明一个数组时,不能直接限定数组长度,只有在创建实例化对象时,才能对给定数组长度.。
如下,1,2,3可以通过编译,4,5不行。而String是Object的子类,所以上述BCF均可定义一个存放50个String类型对象的数组。
1. String a[]=new String[50];
2. String b[];
3. char c[];
4. String d[50];
5. char e[50];