数据库的创建表时,字段的数据类型和约束条件
文章目录
- 数据类型
- 数值类型:
- 整数类型:
- 浮点型:
- 日期类型:
- 字符串类型:
- 枚举类型与集合类型:
- 约束条件
- null与default
- unique
- primary key
- auto_increment
- 修改初始值
- foreign key
数据类型
数值类型:
整数类型:
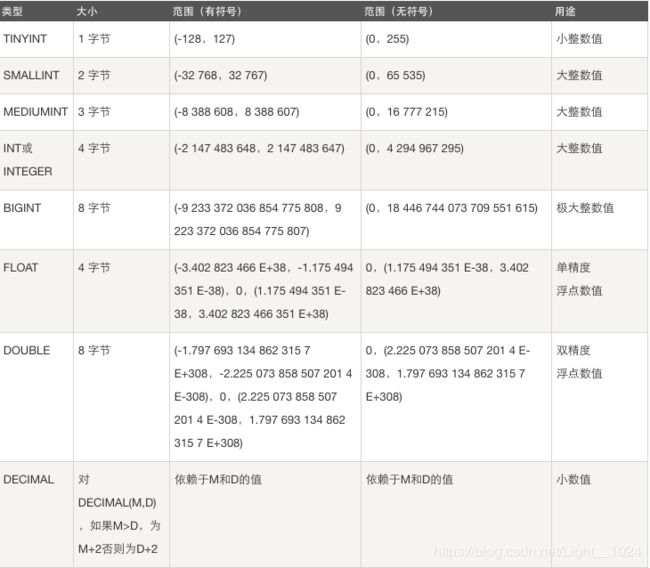
- tinyint 默认有符号,[unsigned]代表无符号,超出范围显示最大范围。
语法:
tinyint[(m)] [unsigned] [zerofill]
- int类型无符号的存储宽度4个字节,
- 创建表整形类型不指定宽度。指定宽度对存储宽度没用,只是更改显示宽度。显示宽度是指查询时显示的宽度,用 [zerofill] 填充。
- 其他所有类型指定宽度都表示存储宽度。
- 默认得无符号得显示宽度 是10
默认得有符号得显示宽度 是11
语法:
int[(m)][unsigned][zerofill]
浮点型:
浮点类型:float double decimal=dec
作用:存储薪资、身高、体重、体质参数等。
规则:
# FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
单精度浮点数(非准确小数值),
m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
精确度:
随着小数的增多,精度变得不准确 ****
# DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
双精度浮点数(非准确小数值),
m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
精确度:
随着小数的增多,精度比float要高,但也会变得不准确
# decimal[(m[,d])] [unsigned] [zerofill]
定义:
准确的小数值,
m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
精确度:
随着小数的增多,精度始终准确
decaimal能够存储精确值的原因在于其内部按照字符串存储。
示例:
1 mysql> create table t1(x float(256,31));
2 ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30.
5 mysql> create table t1(x float(255,30)); #建表成功
8 mysql> create table t2(x double(255,30)); #建表成功
15 mysql> create table t3(x decimal(65,30)); #建表成功
28 mysql> insert into t1 values(1.1111111111111111111111111111111); #小数点后31个1
29 Query OK, 1 row affected (0.01 sec)
30
31 mysql> insert into t2 values(1.1111111111111111111111111111111);
32 Query OK, 1 row affected (0.00 sec)
33
34 mysql> insert into t3 values(1.1111111111111111111111111111111);
35 Query OK, 1 row affected, 1 warning (0.01 sec)
36
37 mysql> select * from t1; #随着小数的增多,精度开始不准确
38 +----------------------------------+
39 | x |
40 +----------------------------------+
41 | 1.111111164093017600000000000000 |
42 +----------------------------------+
43 row in set (0.00 sec)
44
45 mysql> select * from t2; #精度比float要准确点,但随着小数的增多,同样变得不准确
46 +----------------------------------+
47 | x |
48 +----------------------------------+
49 | 1.111111111111111200000000000000 |
50 +----------------------------------+
51 row in set (0.00 sec)
52
53 mysql> select * from t3; #精度始终准确,d为30,于是只留了30位小数
54 +----------------------------------+
55 | x |
56 +----------------------------------+
57 | 1.111111111111111111111111111111 |
58 +----------------------------------+
59 row in set (0.00 sec)
精度: decimal double float
日期类型:
YEAR DATE TIME DATETIME TIMESTAMP
作用:存储用户注册时间,文章发布时间等
规则:
YEAR
YYYY(1901/2155)
DATE
YYYY-MM-DD(1000-01-01/9999-12-31)
TIME
HH:MM:SS('-838:59:59'/'838:59:59')
DATETIME
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y)
TIMESTAMP
YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
示例:
19 MariaDB [db1]> create table t11(d date,t time,dt datetime);
20 MariaDB [db1]> desc t11;
21 +-------+----------+------+-----+---------+-------+
22 | Field | Type | Null | Key | Default | Extra |
23 +-------+----------+------+-----+---------+-------+
24 | d | date | YES | | NULL | |
25 | t | time | YES | | NULL | |
26 | dt | datetime | YES | | NULL | |
27 +-------+----------+------+-----+---------+-------+
28
29 MariaDB [db1]> insert into t11 values(now(),now(),now());
30 MariaDB [db1]> select * from t11;
31 +------------+----------+---------------------+
32 | d | t | dt |
33 +------------+----------+---------------------+
34 | 2017-07-25 | 16:26:54 | 2017-07-25 16:26:54 |
35 +------------+----------+---------------------+
36
37 ============timestamp===========
38 MariaDB [db1]> create table t12(time timestamp);
39 MariaDB [db1]> insert into t12 values();
40 MariaDB [db1]> insert into t12 values(null);
41 MariaDB [db1]> select * from t12;
42 +---------------------+
43 | time |
44 +---------------------+
45 | 2017-07-25 16:29:17 |
46 | 2017-07-25 16:30:01 |
47 +---------------------+
48
49 ============注意===========
50 1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入
51 2. 插入年份时,尽量使用4位值
52 3. 插入两位年份时,<=69,以20开头,比如50, 结果2050
53 >=70,以19开头,比如71,结果1971
66 =======================
67 MariaDB [db1]> create table student(
68 -> id int,
69 -> name varchar(20),
70 -> born_year year,
71 -> birth date,
72 -> class_time time,
73 -> reg_time datetime);
74
75 MariaDB [db1]> insert into student values
78 -> (3,'wsb',"1998","1998-01-01","13:13:13","2017-01-01 13:13:13");
79
80 MariaDB [db1]> select * from student;
81 +------+------+-----------+------------+------------+---------------------+
82 | id | name | born_year | birth | class_time | reg_time |
83 +------+------+-----------+------------+------------+---------------------+
86 | 1 | wsb | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 |
87 +------+------+-----------+------------+------------+---------------------+
datetime与timestamp的区别:
DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。- DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP空间利用率更高。
- DATETIME的默认值为null;TIMESTAMP的字段默认不为空(notnull),默认值为当前时间
一般用datetime就可以了
字符串类型:
官网:https://dev.mysql.com/doc/refman/5.7/en/char.html
#注意:char和varchar括号内的参数指的都是字符的长度
1.char类型:定长,浪费空间,存取速度快
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储:
存储char类型的值时,按指定宽度存,不够右填充空格,
所以定长检索速度快,定长的宽度去解析。
例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储
检索:
在检索或者说查询时,查出的结果显示时,会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式
(SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';)
2.varchar类型:变长,精准,节省空间,存取速度慢
字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:
存储:
varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来,
但是:varchar类型会在真实数据前加1-2Bytes的前缀,
表示真实数据的bytes字节数,检索的时候才知道检索多少。
如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535)
检索:
尾部有空格会保存下来,在查询时,正常显示包含空格在内的内容
#其他字符串系列(效率:char>varchar>text)
TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT
BLOB 系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB
BINARY系列 BINARY VARBINARY
虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。
-
大部分情况 下 用 char,存完之后 不查得话 就可以用varchar
-
建表得时候: 定长得数据 往前放,变长得数据往后放
-
一张表,char varchar 不要混着用
分别查看存储得字符数和字节数
length:查看字节数
char_length:查看字符数
1 mysql> create table t1(x char(5),y varchar(5));
2 Query OK, 0 rows affected (0.26 sec)
3
4 #char存5个字符,而varchar存4个字符
5 mysql> insert into t1 values('你瞅啥 ','你瞅啥 ');
6 Query OK, 1 row affected (0.05 sec)
12 mysql> select x,char_length(x),y,char_length(y) from t1;
13 +-----------+----------------+------------+----------------+
14 | x | char_length(x) | y | char_length(y) |
15 +-----------+----------------+------------+----------------+
16 | 你瞅啥 | 3 | 你瞅啥 | 4 |
17 +-----------+----------------+------------+----------------+
18 row in set (0.00 sec)
21 mysql> SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';
22 Query OK, 0 rows affected (0.00 sec)
25 mysql> select x,char_length(x),y,char_length(y) from t1;
26 +-------------+----------------+------------+----------------+
27 | x | char_length(x) | y | char_length(y) |
28 +-------------+----------------+------------+----------------+
29 | 你瞅啥 | 5 | 你瞅啥 | 4 |
30 +-------------+----------------+------------+----------------+
31 row in set (0.00 sec)
33 #char类型:3个中文字符+2个空格=11Bytes
34 #varchar类型:3个中文字符+1个空格=10Bytes
35 mysql> select x,length(x),y,length(y) from t1;
36 +-------------+-----------+------------+-----------+
37 | x | length(x) | y | length(y) |
38 +-------------+-----------+------------+-----------+
39 | 你瞅啥 | 11 | 你瞅啥 | 10 |
40 +-------------+-----------+------------+-----------+
41 row in set (0.00 sec)
虽然 CHAR 和 VARCHAR 的存储方式不太相同,但是对于两个字符串的比较,都只比 较其值,where查询时后面加不加空格都可以查出来。但是用like查询时,必须保证与存储格式一致。
枚举类型与集合类型:
字段的值只能在给定范围中选择,不在范围内显示空值
-
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
-
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3…)
约束条件
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号
ZEROFILL 使用0填充
null与default
- 是否可空,null表示空,非字符串
- not null - 不可空
- null - 可空
- default - 默认值
设置默认值后,则无论字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值。
unique
- 设置位唯一不重复
- 可以设置复合唯一,单列可以重复,但不能同时重复。
设置方法:
方法一:
create table department1(
id int unique,
name varchar(20) unique,
comment varchar(100)
);
方法二:
create table department(
id int,
name char(10),
unique(id),
unique(name)
);
create table service(
id int ,
name varchar(20) unique,
host varchar(15) not null,
port int not null,
unique(host,port) #联合唯一
);
primary key
- 主键,存储引擎innodb一张表必须有主键,不指定会自动检索不为空且唯一的字段创建,检索不到会创建一个隐藏字段。建表时指定主键。
- 通常一张表,都应该有一个id字段用来标识记录编号,id通常设置为主键。
- 一个表内只能有一个主键primary key
- =not null unique 不为空且唯一
- 单列做主键:不为空且唯一;常用。
- 多列做主键(复合主键):多个字段连在一起,当作主键;
设置方法:
#方法一:not null+unique
create table department1(
id int not null unique, #主键
name varchar(20) not null unique,
comment varchar(100)
);
#方法二:在某一个字段后用primary key
create table department2(
id int primary key, #主键
name varchar(20),
comment varchar(100)
);
#方法三:在所有字段后单独定义primary key
create table department3(
id int,
name varchar(20),
comment varchar(100),
constraint pk_name primary key(id); #创建主键并为其命名pk_name
create table service(
ip varchar(15),
port char(5),
service_name varchar(10) not null,
primary key(ip,port)
);
auto_increment
-
约束字段为自动增长,被约束的字段必须同时被key约束
-
不指定id,则自动增长,可以指定id 。
-
对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
-
用truncate清空表。增长从1开始,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它,
mysql> truncate student;
Query OK, 0 rows affected (0.01 sec)
修改初始值
#在创建完表后,修改自增字段的起始值
mysql> create table student(
-> id int primary key auto_increment,
-> name varchar(20),
-> sex enum('male','female') default 'male'
-> );
mysql> alter table student auto_increment=3;
#也可以创建表时指定auto_increment的初始值,
注意初始值的设置为表选项,应该放到括号外
create table student(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') default 'male'
)auto_increment=3;
设置起始偏移量和步长
#步长:
auto_increment_increment默认为1
#起始偏移量
auto_increment_offset默认1
#设置步长
set session auto_increment_increment=5; 会话级别,本次连接有效
set global auto_increment_increment=5; 全局,所有会话重新再登陆才能起作用
#设置起始偏移量
set global auto_increment_offset=3;
强调:起始偏移量<=步长,如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值会被忽略
foreign key
外键,建立表与表之间的关系。
- 表类型必须是innodb存储引擎,且被关联的字段,即references指定的另外一个表的字段,必须保证唯一
- 语法:foreign key(dep_id) references dep(id)
- 最好不要用外键建立硬性关系,以后修改比较麻烦。
#先建被关联的表,并且保证被关联的字段唯一
create table dep(
id int primary key,
name char(16),
comment char(50)
);
#再建立关联的表
create table emp(
id int primary key,
name char(10),
sex enum('male','female'),
dep_id int,
foreign key(dep_id) references dep(id)
on delete cascade #如果没有,删除时候不能先删被关联的,也不能先更改被关联的。
on update cascade # 被关联的有更新或者删除都会关联,没有逗号
);
#先往被关联表插入记录
insert into dep values
#再往关联表插入记录
insert into emp values