07_Ensemble Learning and Random Forests_Bagging_Out-of-Bag_Random Forests_Extra-Trees极端随机树_Boosting
Suppose you ask a complex question to thousands of random people, then aggregate their answers. In many cases you will find that this aggregated answer is better than an expert's answer. This is called the wisdom智慧 of the crowd. Similarly, if you aggregate the predictions of a group of predictors (such as classifiers or regressors), you will often get better predictions than with the best individual predictor. A group of predictors is called an ensemble; thus, this technique is called Ensemble Learning, and an Ensemble Learning algorithm is called an Ensemble method.
For example, you can train a group of Decision Tree classifiers, each on a different random subset(sub training set's size 100; variation set's size=7900; test set's size=2000) of the training set. To make predictions, you just obtain the predictions of all individual trees, then predict the class that gets the most votes (Q8. Grow a forest.
https://blog.csdn.net/Linli522362242/article/details/104542381). Such an ensemble of Decision Trees is called a Random Forest, and despite its simplicity, this is one of the most powerful Machine Learning algorithms available today.
#n_splitsint, default 10 #Number of re-shuffling & splitting iterations. #similar to random sampling with replacement
###len(variation set OR test_size)=8000-100=7900 then sub_training set's size=100
rs = ShuffleSplit(n_splits=1000, test_size=len(X_train)- 100, random_state=42)
for mini_train_index, mini_test_index in rs.split(X_train):
X_mini_train = X_train[mini_train_index] ###length=100
y_mini_train = y_train[mini_train_index]
mini_sets.append( (X_mini_train,y_mini_train) )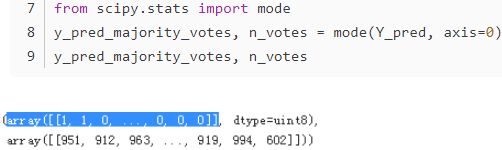
Moreover, as we discussed in (https://blog.csdn.net/Linli522362242/article/details/103646927), you will often use Ensemble methods near the end of a project, once you have already built a few good predictors, to combine them into an even better predictor. In fact, the winning solutions in Machine Learning competitions often involve several Ensemble methods (most famously in the Netflix Prize competition).
In this chapter we will discuss the most popular Ensemble methods, including bagging, boosting, stacking, and a few others. We will also explore Random Forests.
Voting Classifiers
Suppose you have trained a few classifiers, each one achieving about 80% accuracy. You may have a Logistic Regression classifier, an SVM classifier, a Random Forest classifier, a K-Nearest Neighbors classifier, and perhaps a few more (see Figure 7-1).
Figure 7-1. Training diverse classifiers Figure
A very simple way to create an even better classifier is to aggregate the predictions of each classifier and predict the class that gets the most votes. This majority-vote classifier is called a hard voting classifier (see Figure 7-2).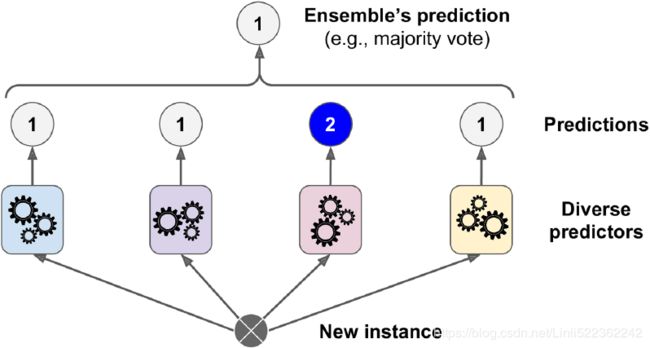
Figure 7-2. Hard voting classifier predictions
Somewhat surprisingly, this voting classifier often achieves a higher accuracy than the best classifier in the ensemble. In fact, even if each classifier is a weak learner (meaning it does only slightly better than random guessing), the ensemble can still be a strong learner (achieving high accuracy), provided there are a sufficient number足够数量 of weak learners and they are sufficiently diverse足够多样化.
How is this possible? The following analogy分析 can help shed阐明 some light on this mystery. Suppose you have a slightly biased偏差的 coin that has a 51% chance of coming up heads, and 49% chance of coming up tails. If you toss it 1,000 times, you will generally get more or less 510 heads and 490 tails, and hence a majority of heads. If you do the math, you will find that the probability of obtaining a majority of heads after 1,000 tosses is close to 75%正面概率为 51% 的人比例为 75%. The more you toss the coin, the higher the probability (e.g., with 10,000 tosses, the probability climbs over 97%). This is due to the law of large numbers大数定律: as you keep tossing the coin, the ratio of heads gets closer and closer to the probability of heads (51%). Figure 7-3 shows 10 series of biased coin tosses. You can see that as the number of tosses increases, the ratio of heads approaches 51%. Eventually all 10 series end up so close to 51% that they are consistently above 50%.
# Scikit-Learn ≥0.20 is required
import sklearn
assert sklearn.__version__ >= "0.20"
# Common imports
import numpy as np
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)heads_proba = 0.51
coin_tosses = ( np.random.rand(10000,10)
np.cumsum( coin_tosses, axis=0 )[:5]
cumulative_heads_ratio[-2:]
plt.figure( figsize=(12,5) )
plt.plot( cumulative_heads_ratio ) #10 curves
plt.plot( [0,10000],[0.51,0.51], 'k--', linewidth=2, label='51%') # a 51% chance of coming up heads
plt.plot( [0,10000],[0.5, 0.5], 'k-', label='50%' ) # a 50% chance of coming up heads
plt.xlabel( 'Number of coin tosses' )
plt.ylabel( 'Heads ratio' )
plt.legend(loc='lower right')
plt.axis([0,10000, 0.42,0.58])
plt.title('Figure 7-3. The law of large numbers')
plt.show()
Similarly, suppose you build an ensemble containing 1,000 classifiers that are individually correct only 51% of the time (barely better than random guessing). If you predict the majority voted class, you can hope for up to 75% accuracy! However, this is only true if all classifiers are perfectly independent (all classifiers should not be trained on the same data), making uncorrelated errors, which is clearly not the case since they are trained on the same data不会发生有相关性的错误的情况下才会这样. They are likely to make the same types of errors, so there will be many majority votes for the wrong class, reducing the ensemble's accuracy.
###############################################
TIP
Ensemble methods work best when the predictors are as independent from one another as possible. One way to get diverse classifiers is to train them using very different algorithms. This increases the chance that they will make very different types of errors, improving the ensemble's accuracy.
###############################################
The following code creates and trains a voting classifier in Scikit-Learn, composed of three diverse classifiers (the training set is the moons dataset, introduced in https://blog.csdn.net/Linli522362242/article/details/104151351):
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X,y = make_moons( n_samples=500, noise=0.30, random_state=42 )
X_train, X_test, y_train, y_test = train_test_split( X,y, random_state=42 ) #default test_size=0.25
len(X_train), len(X_test), len(y_train), len(y_test)![]()
Note: to be future-proof, we set solver="lbfgs", n_estimators=100, and gamma="scale" since these will be the default values in upcoming Scikit-Learn versions.
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# three diverse classifiers #For multiclass problems, ‘lbfgs’ handle multinomial loss
log_clf = LogisticRegression( solver="lbfgs", random_state=42 )#"l-bfgs":limited memory
rnd_clf = RandomForestClassifier( n_estimators=100, random_state=42 )
svm_clf = SVC( gamma='scale', random_state=42 )##############probability=False
# votingstr, {‘hard’, ‘soft’} (default=’hard’)
# If ‘hard’, uses predicted class labels for majority rule voting.
# Else if ‘soft’, predicts the class label based on the argmax of the sums of the predicted probabilities,
#which is recommended for an ensemble of well-calibrated良好校准的 classifiers.
voting_clf = VotingClassifier(
estimators=[ ('lr', log_clf), ('rf',rnd_clf), ('svc', svm_clf)],
voting='hard'
)voting_clf.fit( X_train, y_train )
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit( X_train, y_train )
y_pred = clf.predict( X_test )
print( clf.__class__.__name__, accuracy_score(y_test, y_pred) )
There you have it! The voting classifier slightly outperforms all the individual classifiers. If all classifiers are able to estimate class probabilities (i.e., they have a predict_proba() method), then you can tell Scikit-Learn to predict the class with the highest class probability, averaged over all the individual classifiers. This is called soft voting. It often achieves higher performance than hard voting because it gives more weight to highly confident votes. All you need to do is replace voting="hard" with voting="soft" and ensure that all classifiers can estimate class probabilities. This is not the case of the SVC class by default, so you need to set its probability hyperparameter to True (this will make the SVC class use cross-validation to estimate class probabilities, slowing down training, and it will add a predict_proba() method). If you modify the preceding code to use soft voting, you will find that the voting classifier achieves over 91% accuracy!
log_clf = LogisticRegression( solver='lbfgs', random_state=42 )
rnd_clf = RandomForestClassifier( n_estimators=100, random_state=42 )
#if gamma='scale' (default) is passed then it uses 1 / ( n_features * X.var() ) as value of gamma,
svm_clf = SVC( gamma="scale", probability=True, random_state=42 )#############probability=True
voting_clf = VotingClassifier(
estimators=[ ('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf) ],
voting='soft'
)
voting_clf.fit( X_train, y_train )
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print( clf.__class__.__name__, accuracy_score(y_test, y_pred) )
Bagging and Pasting
One way to get a diverse set of classifiers is to use 1.very different training algorithms, as just discussed. Another approach is to use the same training algorithm for every predictor, but to 2.train them on different random subsets of the training set. When sampling is performed with replacement, this method is called bagging装袋法(short for bootstrap aggregating自助法聚合 '. When sampling is performed without replacement, it is called pasting.
In other words, both bagging and pasting allow training instances to be sampled several times across multiple predictors, but only bagging allows training instances to be sampled several times for the same predictor. This sampling and training process is represented in Figure 7-4.
Figure 7-4. Pasting/bagging training set sampling and training
Once all predictors are trained, the ensemble can make a prediction for a new instance by simply aggregating the predictions of all predictors. The aggregation function is typically the statistical mode (i.e., the most frequent prediction, just like a hard voting classifier) for classification, or the average for regression. Each individual predictor has a higher bias than if it were trained on the original training set, but aggregation reduces both bias and variance. Generally, the net result is that the ensemble has a similar bias but a lower variance than a single predictor trained on the original training set.
As you can see in Figure 7-4, predictors can all be trained in parallel, via different CPU cores or even different servers. Similarly, predictions can be made in parallel. This is one of the reasons why bagging and pasting are such popular methods: they scale可扩展性 very well.
Bagging and Pasting in Scikit-Learn
Scikit-Learn offers a simple API for both bagging and pasting with the BaggingClassifier class (or BaggingRegressor for regression). The following code trains an ensemble of 500 Decision Tree classifiers, each trained on 100 training instances randomly sampled from the training set with replacement (this is an example of bagging, but if you want to use pasting instead, just set bootstrap=False). The n_jobs parameter tells Scikit-Learn the number of CPU cores to use for training
and predictions (–1 tells Scikit-Learn to use all available cores):
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
#500 Decision Tree classifiers #100 instances randomly sampled
bag_clf = BaggingClassifier( DecisionTreeClassifier(random_state=42), n_estimators=500, max_samples=100, #The number of samples to draw from X to train each base estimator.
random_state=42,
bootstrap=True, n_jobs=-1 ) #(–1 tells Scikit-Learn to use all available CPU cores
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
from sklearn.metrics import accuracy_score
print( accuracy_score(y_test, y_pred) )![]()
# the predictor(DecisionTreeClassifier is trained on the original training set)
tree_clf = DecisionTreeClassifier( random_state=42 )
tree_clf.fit( X_train, y_train )
y_pred_tree = tree_clf.predict(X_test)
print( accuracy_score( y_test, y_pred_tree ) )![]()
from matplotlib.colors import ListedColormap
def plot_decision_boundary( clf, X,y, axes=[-1.5,2.45, -1,1.5], alpha=0.5, contour=True ):
x1s = np.linspace( axes[0],axes[1], 100 )
x2s = np.linspace( axes[2],axes[3], 100 )
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[ x1.ravel(), x2.ravel() ]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap( ['#fafab0','#9898ff','yellow'] )
plt.contourf( x1,x2, y_pred, alpha=0.3, cmap=custom_cmap ) #ploting region
if contour:
custom_cmap2 = ListedColormap( ['#7d7d58','#9898ff','#507d50']) #ploting decision boundary
plt.contour(x1,x2, y_pred, cmap=custom_cmap2, alpha=0.8)
plt.plot( X[:,0][y==0], X[:,1][y==0], "yo", alpha=alpha )
plt.plot( X[:,0][y==1], X[:,1][y==1], "bs", alpha=alpha )
plt.axis( axes )
plt.xlabel( r"$x_1$", fontsize=18 )
plt.ylabel( r"$x_2$", fontsize=18, rotation=0 )
fix, axes = plt.subplots( ncols=2, figsize=(10,4), sharey=True )
plt.sca( axes[0] )
plot_decision_boundary(tree_clf, X,y)
plt.title("Decision Tree", fontsize=14)
plt.sca( axes[1] )
plot_decision_boundary(bag_clf, X,y)
plt.title("Decision Tree with Bagging", fontsize=14)
plt.ylabel("")
plt.show()
Figure 7-5. A single Decision Tree versus a bagging ensemble of 500 trees
######################################
NOTE
The BaggingClassifier automatically performs soft voting instead of hard voting if the base classifier can estimate class
probabilities (i.e., if it has a predict_proba() method), which is the case with Decision Trees classifiers.
######################################
Figure 7-5 compares the decision boundary of a single Decision Tree with the decision boundary of a bagging ensemble of 500 trees (from the preceding code), both trained on the moons dataset. As you can see, the ensemble’s predictions will likely generalize much better than the single Decision Tree’s predictions: the ensemble has a comparable bias but a smaller variance (it makes roughly the same number of errors on the training set, but the decision boundary is less irregular).
Bootstrapping introduces a bit more diversity in the subsets(training instances randomly sampled from the training set with replacement ) that each predictor is trained on, so bagging ends up with a slightly higher bias than pasting, but this also means that predictors(classifiers) end up being less correlated so the ensemble’s variance is reduced. Overall, bagging often results in better models, which explains why it is generally preferred. However, if you have spare time and CPU power you can use cross-validation to evaluate both bagging and pasting and select the one that works best.
########################################################################################
8.2 Bagging, Random Forests, Boosting
Bagging, random forests, and boosting use trees as building blocks to construct more powerful prediction models.
8.2.1 Bagging
The bootstrap is an extremely powerful idea. It is used in many situations in which it is hard or even impossible to directly
compute the standard deviation of a quantity of interest. We see here that the bootstrap can be used in a completely different context, in order to improve statistical learning methods such as decision trees.
The decision trees discussed in Section 8.1(https://blog.csdn.net/Linli522362242/article/details/104542381) suffer from high variance. This means that if we split the training data into two parts at random, and fit a decision tree to both halves, the results that we get could be quite different(可能得到截然不同的两棵树). In contrast, a procedure with low variance will yield similar results if applied repeatedly to distinct data sets; linear regression tends to have low variance, if the ratio of n to p is moderately large. Bootstrap aggregation, or bagging, is a general-purpose procedure for reducing the variance of a statistical learning method; we introduce it here because it is particularly useful and frequently used in the context of decision trees.
Recall that given a set of n independent observations(n independent samples) Z1, . . . , Zn, each with variance  ( samples' variance :
( samples' variance :![]() ), the variance of the mean
), the variance of the mean ![]() of the observations is given by
of the observations is given by ![]() . In other words, averaging a set of observations reduces variance. Hence a natural way to reduce the variance and hence increase the prediction accuracy of a statistical learning method is to take many training sets from the population, build a separate prediction model using each training set, and average the resulting predictions. In other words, we could calculate
. In other words, averaging a set of observations reduces variance. Hence a natural way to reduce the variance and hence increase the prediction accuracy of a statistical learning method is to take many training sets from the population, build a separate prediction model using each training set, and average the resulting predictions. In other words, we could calculate ![]() using B separate training sets, and average them in order to obtain a single low-variance statistical learning model, given by
using B separate training sets, and average them in order to obtain a single low-variance statistical learning model, given by 
Of course, this is not practical because we generally do not have access to multiple training sets在一般情况下难以取得多个训练集. Instead, we can bootstrap, by taking repeated samples from the (single) training data set. In this approach we generate B different bootstrapped training data sets. We then train our method on the bth bootstrapped training set in order to get ![]() , and finally average all the predictions, to obtain
, and finally average all the predictions, to obtain  This is called bagging.
This is called bagging.
While bagging can improve predictions for many regression methods, it is particularly useful for decision trees. To apply bagging to regression trees, we simply construct B regression trees using B bootstrapped training sets, and average the resulting predictions. These trees are grown deep, and are not pruned. Hence each individual tree has high variance, but
low bias. Averaging these B trees reduces the variance. Bagging has been demonstrated to give impressive可观的 improvements in accuracy by combining together hundreds or even thousands of trees into a single procedure.
Thus far, we have described the bagging procedure in the regression context, to predict a quantitative定量 outcome Y . How can bagging be extended to a classification problem where Y is qualitative定性(class/label, such as sex)? In that situation, there are a few possible approaches, but the simplest is as follows. For a given test observation, we can record the class predicted by each of the B trees, and take a majority vote: the overall prediction is the most commonly occurring
majority class among the B predictions. FIGURE 8.8. Bagging(OOB error:
FIGURE 8.8. Bagging(OOB error: ) and random forest results for the Heart data. The test error (black and orange) is shown as a function of B, the number of bootstrapped
) and random forest results for the Heart data. The test error (black and orange) is shown as a function of B, the number of bootstrapped
training sets used. Random forests were applied with m =![]() . The dashed line indicates the test error resulting from a single classification tree. The green and blue traces show the OOB(out-of-bag) error, which in this case is considerably lower.
. The dashed line indicates the test error resulting from a single classification tree. The green and blue traces show the OOB(out-of-bag) error, which in this case is considerably lower.
Figure 8.8 shows the results from bagging trees on the Heart data. The test error rate is shown as a function of B, the number of trees constructed using bootstrapped training data sets. We see that the bagging test error rate is slightly lower in this case than the test error rate obtained from a single tree. The number of trees B is not a critical决定作用的 parameter with bagging; using a very large value of B will not lead to overfitting. In practice we use a value of B sufficiently large that the error has settled down取足够大的B值,使误差是能够稳定下. Using B = 100 is sufficient to achieve good performance in this example.
is slightly lower in this case than the test error rate obtained from a single tree. The number of trees B is not a critical决定作用的 parameter with bagging; using a very large value of B will not lead to overfitting. In practice we use a value of B sufficiently large that the error has settled down取足够大的B值,使误差是能够稳定下. Using B = 100 is sufficient to achieve good performance in this example.
########################################################################################
########################https://rpubs.com/ppaquay/65561
We will now derive the probability that a given observation is part of a bootstrap sample. Suppose that we obtain a bootstrap sample from a set of n observations.
As bootstrapping sample with replacement, we have that the probability that the jth observation is not in the bootstrap sample is the product of the probabilities that each bootstrap observation is not the jth observation from the original sample
![]()
########################
Out-of-Bag Evaluation
With bagging, some instances may be sampled several times for any given predictor, while others may not be sampled at all. By default a BaggingClassifier samples m training instances with replacement (bootstrap=True), where m is the size of the training set. This means that only about 63%(As m grows, the ratio approaches , or
, or 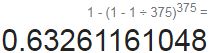 since we use 375 instances as the original sample ) of the training instances are sampled on average for each predictor. The remaining 37%(
since we use 375 instances as the original sample ) of the training instances are sampled on average for each predictor. The remaining 37%( ) of the training instances that are not sampled are called out-of-bag (oob) instances. Note that they are not the same 37% for all predictors.
) of the training instances that are not sampled are called out-of-bag (oob) instances. Note that they are not the same 37% for all predictors.
Since a predictor never sees the oob instances during training, it can be evaluated on these instances, without the need for a separate validation set or cross-validation. You can evaluate the ensemble itself by averaging out the oob evaluations of each predictor.
In Scikit-Learn, you can set oob_score=True when creating a BaggingClassifier to request an automatic oob evaluation after training. The following code demonstrates this. The resulting evaluation score is available through the oob_score_ variable:
bag_clf = BaggingClassifier(
DecisionTreeClassifier( random_state=42),
n_estimators=500, #500 Decision Tree classifiers
bootstrap=True, #samples m training instances with replacement
n_jobs=-1, #(–1 tells Scikit-Learn to use all available CPU cores
oob_score=True, # out-of-bag (oob) instances as a validation set
random_state=40
)
bag_clf.fit(X_train, y_train) #length=375
bag_clf.oob_score_![]()
According to this oob evaluation, this BaggingClassifier is likely to achieve about 90.1% accuracy on the validation set(the response for each observation is predicted using only the trees that were not fit using that observation). Let’s verify this:
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)![]()
We get 91.2% accuracy on the test set — close enough!
####################
The BaggingClassifier automatically performs soft voting instead of hard voting if the base classifier can estimate class
probabilities (i.e., if it has a predict_proba() method), which is the case with Decision Trees classifiers.
####################
The oob decision function for each training instance is also available through the oob_decision_function_ variable. In this case (since the base estimator has a predict_proba() method) the decision function returns the class probabilities for each training instance. For example, the oob evaluation estimates that the second training instance has a 34.1% probability of belonging to the positive class (and 65.9% of belonging to the positive class):
bag_clf.oob_decision_function_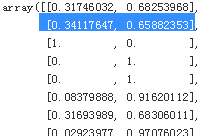
#############################################
########################https://rpubs.com/ppaquay/65561
As bootstrapping sample with replacement, we have that the probability that the jth observation is not in the bootstrap sample is the product of the probabilities that each bootstrap observation is not the jth observation from the original sample
![]()
########################
Out-of-Bag Error Estimation
It turns out that there is a very straightforward way to estimate the test error of a bagged model, without the need to perform cross-validation or the validation set approach. Recall that the key to bagging is that trees are repeatedly fit to bootstrapped subsets of the observations. One can show that on average, each bagged tree makes use of around two-thirds of the observations.( This means that only about 63%(As m grows, the ratio approaches, or since we use 375 instances as the original sample in bootstrap) of the training instances are sampled on average for each predictor. The remaining 37%() of the training instances that are not sampled are called out-of-bag (oob) instances. Note that they are not the same 37% for all predictors.) The remaining one-third of the observations not used to fit a given bagged tree are referred to as the out-of-bag (OOB) observations. We can predict the response for the ith observation using each of the trees in which that observation was OOB. This will yield around B*1/3 predictions for the ith observation(B different bootstrapped training data sets, n_estimators=B in sklearn). In order to obtain a single prediction for the ith observation, we can average these predicted responses (if regression is the goal, predict_proba() and bag_clf.oob_decision_function_) or can take a majority vote (if classification is the goal). This leads to a single OOB prediction for the ith observation. An OOB prediction can be obtained in this way for each of the n observations, from which the overall OOB MSE (for a regression problem) or classification error (for a classification problem) can be computed. The resulting OOB error is a valid estimate of the test error for the bagged model (bag_clf.oob_score_), since the response for each observation is predicted using only the trees that were not fit using that observation(likes each prediction was happened in their validation set). Figure 8.8 displays the OOB error on the Heart data. It can be shown that with B sufficiently large, OOB error is virtually equivalent to leave-one-out cross-validation error留一法交叉验证误差. The OOB approach for estimating the test error is particularly convenient when performing bagging on large data sets for which cross-validation would be computationally onerous麻烦的.
Variable Importance Measures变最重要性的度量
As we have discussed, bagging typically results in improved accuracy over prediction using a single tree. Unfortunately, however, it can be difficult to interpret the resulting model. Recall that one of the advantages of decision trees is the attractive and easily interpreted diagram that results, such as the one displayed in Figure 8.1. https://blog.csdn.net/Linli522362242/article/details/104542381 However, when we bag a large number of trees, it is no longer possible to represent the resulting statistical learning procedure using a single tree, and it is no longer clear which variables are most important to the procedure. Thus, bagging improves prediction accuracy at the expense of interpretability.
Although the collection of bagged trees is much more difficult to interpret than a single tree, one can obtain an overall summary of the importance of each predictor using the RSS (for bagging regression trees) or the Gini index
(for bagging classification trees). In the case of bagging regression trees, we can record the total amount that the RSS (8.1) is decreased due to splits over a given predictor, averaged over all B trees(B different bootstrapped training data sets, n_estimators=B in sklearn). A large value indicates an important predictor. Similarly, in the context of bagging classification trees, we can add up the total amount that the Gini index (8.6) is decreased by splits over a given predictor, averaged over all B trees.
FIGURE 8.9. A variable importance plot for the Heart data. Variable importance is computed using the mean decrease in Gini index, and expressed relative to the maximum.
A graphical representation of the variable importances in the Heart data is shown in Figure 8.9.We see the mean decrease in Gini index for each variable, relative to the largest. The variables with the largest mean decrease in Gini index are Thal, Ca, and ChestPain.
#############################################
Random Patches and Random Subspaces随机贴片与随机子空间
The BaggingClassifier class supports sampling the features as well. This is controlled by two hyperparameters: max_features and bootstrap_features. They work the same way as max_samples and bootstrap, but for feature sampling instead of instance sampling. Thus, each predictor will be trained on a random subset of the input features.
This is particularly useful when you are dealing with high-dimensional inputs (such as images). Sampling both training instances and features is called the Random Patches method. Keeping all training instances (i.e., bootstrap=False and max_samples=1.0) but sampling features (i.e., bootstrap_features=True and/or max_features smaller than 1.0) is called the Random Subspaces method.
Sampling features results in even more predictor diversity, trading a bit more bias for a lower variance.
采样特征导致更多的预测多样性,用高偏差换低方差。
Random Forests
As we have discussed, a Random Forest is an ensemble of Decision Trees, generally trained via the bagging method (or sometimes pasting), typically with max_samples set to the size of the training set. Instead of building a BaggingClassifier and passing it a DecisionTreeClassifier, you can instead use the RandomForestClassifier class, which is more convenient and optimized for Decision Trees (similarly, there is a RandomForestRegressor class for regression tasks). The following code trains a Random Forest classifier with 500 trees (each limited to maximum 16 nodes), using all available CPU cores:
a Random Forest is an ensemble of Decision Trees, generally trained via the bagging method (or sometimes pasting(bootstrap=False)), typically with max_samples set to the size of the training set; building a BaggingClassifier and passing it a DecisionTreeClassifier
bag_clf = BaggingClassifier( #each limited to maximum 16 nodes
DecisionTreeClassifier( splitter="random", max_leaf_nodes=16, random_state=42 ),
n_estimators= 500,
max_samples=1.0, #The number of samples to draw from X to train each base estimator. #max_samples * X.shape[0]
bootstrap=True, #samples are drawn with replacement #bootstrap
random_state=42,
n_jobs=-1 #using all available CPU cores
)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)use the RandomForestClassifier class
from sklearn.ensemble import RandomForestClassifier
#each limited to maximum 16 nodes #using all available CPU cores
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, random_state=42, n_jobs=-1)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)
np.sum(y_pred==y_pred_rf) / len(y_pred) #almost identical predictions![]()
With a few exceptions, a RandomForestClassifier has all the hyperparameters of a DecisionTreeClassifier (to control how trees are grown), plus all the hyperparameters of a BaggingClassifier to control the ensemble itself.
The Random Forest algorithm introduces extra randomness when growing trees; instead of searching for the very best feature when splitting a node (or region), it searches for the best feature among a random subset of features. This results in a greater tree diversity, which (once again) trades a higher bias for a lower variance, generally yielding an overall better model.
##########################################################
8.2.2 Random Forests
Random forests provide an improvement over bagged trees by way of a small tweak that decorrelates去相关 the trees. As in bagging, we build a number of decision trees on bootstrapped training samples. But when building these decision trees, each time a split in a tree is considered, a random sample of m predictors is chosen as split candidates from the full set of p predictors. The split is allowed to use only one of those m predictors. A fresh sample of m predictors is taken at each split, and typically we choose m ≈![]() —that is, the number of predictors considered at each split is approximately equal
—that is, the number of predictors considered at each split is approximately equal
to the square root of the total number of predictors (4 out of the 13 for the Heart data  ).
).
In other words, in building a random forest, at each split in the tree, the algorithm is not even allowed to consider a majority of the available predictors. This may sound crazy, but it has a clever rationale. Suppose that there is one very strong predictor in the data set, along with a number of other moderately strong predictors. Then in the collection of bagged trees, most or all of the trees will use this strong predictor in the top split. Consequently, all of the bagged trees will look quite similar to each other. Hence the predictions from the bagged trees will be highly correlated. Unfortunately, averaging many highly correlated quantities量 does not lead to as large of a reduction in variance as averaging many uncorrelated quantities.In particular, this means that bagging will not lead to a substantial reduction in variance over a single tree in this setting.
Random forests overcome this problem by forcing each split to consider only a subset of the predictors. Therefore, on average (p − m)/p of the splits will not even consider the strong predictor, and so other predictors will have more of a chance. We can think of this process as decorrelating去相关 the trees, thereby making the average of the resulting trees less variable and hence more reliable.
The main difference between bagging and random forests is the choice of predictor subset size m. For instance, if a random forest is built using m = p, then this amounts simply to bagging其实等于建立装袋法树. On the Heart data, random
forests using m =![]() leads to a reduction in both test error(RandomForest
leads to a reduction in both test error(RandomForest ) and OOB(RandomForest
) and OOB(RandomForest  ) error over bagging (Figure 8.8).FIGURE 8.8. Bagging and random forest results for the Heart data. The test error (black and orange) is shown as a function of B, the number of bootstrapped
) error over bagging (Figure 8.8).FIGURE 8.8. Bagging and random forest results for the Heart data. The test error (black and orange) is shown as a function of B, the number of bootstrapped
training sets used. Random forests were applied with m =![]() . The dashed line indicates the test error resulting from a single classification tree. The green and blue traces show the OOB(out-of-bag) error, which in this case is considerably lower.
. The dashed line indicates the test error resulting from a single classification tree. The green and blue traces show the OOB(out-of-bag) error, which in this case is considerably lower.
Using a small value of m in building a random forest will typically be helpful when we have a large number of correlated predictors. We applied random forests to a high-dimensional biological data set consisting of expression measurements of 4,718 genes measured on tissue组织 samples from 349 patients. There are around 20,000 genes in humans, and individual genes have different levels of activity, or expression, in particular cells, tissues, and biological conditions. In this data set, each of the patient samples has a qualitative定性 label with 15 different levels: either normal or 1 of 14 different types of cancer. Our goal was to use random forests to predict cancer type based on the 500 genes that have the largest variance in the training set.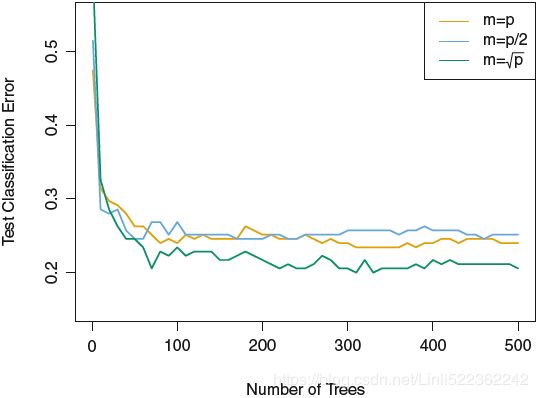
FIGURE 8.10. Results from random forests for the 15-class gene expression data set with p = 500 predictors. The test error is displayed as a function of the number of trees. Each colored line corresponds to a different value of m, the
number of predictors available for splitting at each interior tree node. Random forests (m < p) lead to a slight improvement![]() over bagging (m = p). A single classification tree has an error rate of 45.7%.
over bagging (m = p). A single classification tree has an error rate of 45.7%.
We randomly divided the observations into a training and a test set, and applied random forests to the training set for three different values(m=p, ![]() ,
, ![]() ) of the number of splitting variables m. The results are shown in Figure 8.10. The error rate of a single tree is 45.7%, and the null rate is 75.4%(The null rate results from simply classifying each observation to the dominant class overall, which is in this case the normal class.). We see that using 400 trees is sufficient to give good performance, and that the choice
) of the number of splitting variables m. The results are shown in Figure 8.10. The error rate of a single tree is 45.7%, and the null rate is 75.4%(The null rate results from simply classifying each observation to the dominant class overall, which is in this case the normal class.). We see that using 400 trees is sufficient to give good performance, and that the choice ![]() gave a small improvement in test error over bagging (m = p) in
gave a small improvement in test error over bagging (m = p) in
this example. As with bagging, random forests will not overfit if we increase B(taking repeated samples from the (single) training data set-->B different bootstrapped training data sets-->to fit models, n_estimators=B in sklearn--> average), so in practice we use a value of B sufficiently large for the error rate to have settled down.
##########################################################
Extra-Trees
When you are growing a tree in a Random Forest, at each node only a random subset of the features is considered for splitting (as discussed earlier). It is possible to make trees even more random by also using random thresholds for each feature rather than searching for the best possible thresholds (like regular Decision Trees do).
A forest of such extremely random trees is simply called an Extremely Randomized Trees ensemble 极端随机树(or Extra-Trees for short). Once again, this trades more bias for a lower variance. It also makes Extra-Trees much faster to train than regular Random Forests since finding the best possible threshold for each feature at every node is one of the most time-consuming tasks of growing a tree.
You can create an Extra-Trees classifier using Scikit-Learn's ExtraTreesClassifier class. Its API is identical to the RandomForestClassifier class. Similarly, the Extra TreesRegressor class has the same API as the RandomForestRegressor class.
#############################
TIP
It is hard to tell in advance whether a RandomForestClassifier will perform better or worse than an ExtraTreesClassifier.
Generally, the only way to know is to try both and compare them using cross-validation (and tuning the hyperparameters using grid search).
#############################
Feature Importance
Yet another great quality of Random Forests is that they make it easy to measure the relative importance of each feature. Scikit-Learn measures a feature’s importance by looking at how much the tree nodes that use that feature reduce impurity on average (across all trees in the forest): (父节点的impurity-左右子节点的不存度的平均)×n_samples. More precisely, it is a weighted average, where each node’s weight is equal to the number of training samples that are associated with it.
###########################################
2. Is a node's Gini impurity generally lower or greater than its parent's? Is it generally lower/greater, or always lower/greater?
Equation 6-1. Gini impurity 
![]() is the ratio of class k instances among the training instances in the
is the ratio of class k instances among the training instances in the ![]() node/region.
node/region.

probabilities: 0% for Iris-Setosa (0/54), 90.7% for Iris-Versicolor (49/54), and 9.3% for Iris-Virginica (5/54)
![]() <0.5 #A node's Gini impurity is generally lower than its parent's(0.5).
<0.5 #A node's Gini impurity is generally lower than its parent's(0.5).

 =0.02119230769230769230769230769231
=0.02119230769230769230769230769231
Equation 6-4. CART cost function for regression

A node's Gini impurity is generally lower than its parent's. This is due to the CART training algorithm's cost function, which splits each node in a way that minimizes the weighted sum of its children's Gini impurities. However, it is possible for a node to have a higher Gini impurity than its parent, as long as this increase is more than compensated for by a decrease of the other child's impurity. For example, consider a node containing four instances of class A and 1 of class B. Its Gini impurity is 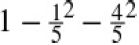 = 0.32. Now suppose the dataset is one-dimensional and the instances are lined up in the following order: A, B, A, A, A. You can verify that the algorithm will split this node after the second instance, producing one child node with instances A, B, and the other child node with instances A, A, A. The first child node's Gini impurity is
= 0.32. Now suppose the dataset is one-dimensional and the instances are lined up in the following order: A, B, A, A, A. You can verify that the algorithm will split this node after the second instance, producing one child node with instances A, B, and the other child node with instances A, A, A. The first child node's Gini impurity is ![]() = 0.5(>0.32), which is higher than its parent. This is compensated for by the fact that the other node is pure(Gini impurity=0), so the overall weighted Gini impurity is
= 0.5(>0.32), which is higher than its parent. This is compensated for by the fact that the other node is pure(Gini impurity=0), so the overall weighted Gini impurity is ![]() = 0.2 , which is lower than the parent's Gini impurity.
= 0.2 , which is lower than the parent's Gini impurity.
Scikit-Learn computes this score automatically for each feature after training, then it scales the results so that the sum of all importances is equal to 1. You can access the result using the feature_importances_ variable. For example, the following code trains a RandomForestClassifier on the iris dataset and outputs each feature’s importance. It seems that the most important features are the petal length (44%) and width (42%), while sepal length and width are rather unimportant in comparison (11% and 2%, respectively).
###########################################https://blog.csdn.net/Linli522362242/article/details/104097191
from sklearn.datasets import load_iris
iris = load_iris()
for k,v in iris.items():
print(k,v)

set(iris.target)![]()
rnd_clf = RandomForestClassifier(n_estimators=500, random_state=42, n_jobs=-1)
rnd_clf.fit( iris['data'], iris['target'] )
for name, score in zip( iris['feature_names'], rnd_clf.feature_importances_ ):
print(name, score)
It seems that the most important features are the petal length (44%) and width (42%), while sepal length and width are rather unimportant in comparison (11% and 2%, respectively).
https://blog.csdn.net/Linli522362242/article/details/87891370
#plt.barh(range(len(rnd_clf.feature_importances_)),rnd_clf.feature_importances_ )
import pandas as pd
data = pd.Series(rnd_clf.feature_importances_, index=iris['feature_names'])
data = data.sort_values(ascending=False)
data.plot.barh()
plt.show()
Similarly, if you train a Random Forest classifier on the MNIST dataset (introduced in https://blog.csdn.net/Linli522362242/article/details/103786116) and plot each pixel’s importance, you get the image represented in Figure 7-6.
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
mnist.target = mnist.target.astype(np.uint8) #mnist.target: array(['5', '0', '4', ..., '4','5','6'],dtype=object)
mnist.target![]()
rnd_clf = RandomForestClassifier( n_estimators=100, random_state=42 )
rnd_clf.fit(mnist['data'], mnist['target'])
def plot_digit(data):
image = data.reshape(28,28) #mnist["data"](70000,784): each instance 784=28*28
plt.imshow( image, cmap=mpl.cm.hot, interpolation="nearest")
plt.axis("off")plot_digit( rnd_clf.feature_importances_ )
cbar = plt.colorbar( ticks=[rnd_clf.feature_importances_.min(), rnd_clf.feature_importances_.max() ] )
cbar.ax.set_yticklabels(['Not important', 'Very important'])
plt.show()
Random Forests are very handy to get a quick understanding of what features actually matter, in particular if you need to perform feature selection.
Boosting提升
Boosting (originally called hypothesis boosting 假设增强) refers to any Ensemble method that can combine several weak learners into a strong learner. The general idea of most boosting methods is to train predictors sequentially, each trying to correct its predecessor前面的分类. There are many boosting methods available, but by far the most popular are AdaBoost (short for Adaptive Boosting适应性提升) and Gradient Boosting梯度提升. Let's start with AdaBoost.
AdaBoost (Adaptive Boosting适应性提升)
One way for a new predictor to correct its predecessor is to pay a bit more attention to the training instances that the predecessor underfitted. This results in new predictors focusing more and more on the hard cases. This is the technique used by AdaBoost.
For example, to build an AdaBoost classifier, a first base classifier (such as a Decision Tree) is trained and used to make predictions on the training set. The relative weight of misclassified training instances is then increased. A second classifier is trained using the updated weights and again it makes predictions on the training set, weights are updated, and so on (see Figure 7-7).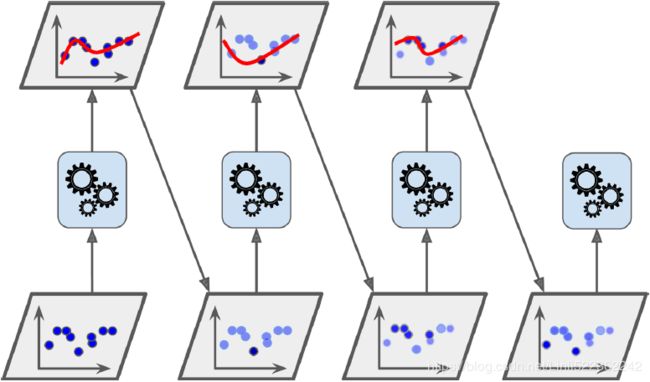
Figure 7-7. AdaBoost sequential training with instance weight updates
Figure 7-8 shows the decision boundaries of five consecutive predictors on the moons dataset (in this example, each predictor is a highly regularized SVM classifier with an RBF kernel (This is just for illustrative purposes. SVMs are generally not good base predictors for AdaBoost, because they are slow and tend to be unstable with AdaBoost.)). The first classifier gets many instances wrong, so their weights get boosted. The second classifier therefore does a better job on these instances, and so on. The plot on the right represents the same sequence of predictors except that the learning rate is halved (i.e., the misclassified instance weights are boosted half as much at every iteration误分类实例权重每次迭代上升一半). As you can see, this sequential learning technique has some similarities with Gradient Descent, except that instead of tweaking a single predictor’s parameters to minimize a cost function, AdaBoost adds predictors to the ensemble, gradually making it better.
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm='SAMME.R', learning_rate=0.5, random_state=42
)
# X,y = make_moons( n_samples=500, noise=0.30, random_state=42 )
# X_train, X_test, y_train, y_test = train_test_split( X,y, random_state=42 ,test_size=0.25)
ada_clf.fit( X_train, y_train )
from matplotlib.colors import ListedColormap
def plot_decision_boundary( clf, X,y, axes=[-1.5,2.45, -1,1.5], alpha=0.5, contour=True ):
x1s = np.linspace( axes[0],axes[1], 100 )
x2s = np.linspace( axes[2],axes[3], 100 )
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[ x1.ravel(), x2.ravel() ]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap( ['#fafab0','#9898ff','yellow'] )
plt.contourf( x1,x2, y_pred, alpha=0.3, cmap=custom_cmap ) #ploting region
if contour:
custom_cmap2 = ListedColormap( ['#7d7d58','#9898ff','#507d50']) #ploting boundary line
plt.contour(x1,x2, y_pred, cmap=custom_cmap2, alpha=0.8)
plt.plot( X[:,0][y==0], X[:,1][y==0], "yo", alpha=alpha )
plt.plot( X[:,0][y==1], X[:,1][y==1], "bs", alpha=alpha )
plt.axis( axes )
plt.xlabel( r"$x_1$", fontsize=18 )
plt.ylabel( r"$x_2$", fontsize=18, rotation=0 )
plot_decision_boundary(ada_clf, X,y)
https://blog.csdn.net/Linli522362242/article/details/104280075
minimize 
![]()
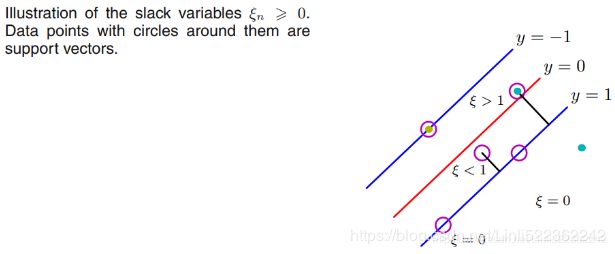
The width of the street is controlled by a hyperparameter ϵ(Epsilon ![]() , n: the index of instances)
, n: the index of instances)
The C parameter trades off correct classification of training examples against maximization of the decision function’s margin. For larger values of C, a smaller margin will be accepted if the decision function is better at classifying all training points correctly. A lower C will encourage a larger margin, therefore a simpler decision function, at the cost of training accuracy. In other words``C`` behaves as a regularization parameter
where the parameter C > 0 controls the trade-off between the slack variable penalty and the margin. Because any point that is misclassified has ξn > 1, it follows that ![]() is an upper bound on the number of misclassified points. The parameter C is therefore analogous相似的 to a regularization coefficient because it controls the trade-off between minimizing training errors and controlling model complexity. In the limit C → ∞, we will recover the earlier support vector machine for separable data.
is an upper bound on the number of misclassified points. The parameter C is therefore analogous相似的 to a regularization coefficient because it controls the trade-off between minimizing training errors and controlling model complexity. In the limit C → ∞, we will recover the earlier support vector machine for separable data.


Intuitively, the gamma parameter defines how far the influence of a single training example reaches, with low values meaning ‘far’ and high values meaning ‘close’
Increasing gamma(γ) makes the bell-shape curve narrower (see the left plot of Figure 5-8 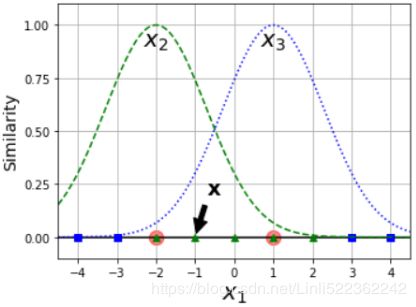 ), and as a result each instance’s range of influence is smaller: the decision boundary ends up being more irregular, wiggling扭动 around individual instances. Conversely, a small gamma(γ) value makes the bell-shaped curve wider, so instances have a larger range of influence, and the decision boundary ends up smoother. So γ acts like a regularization hyperparameter: if your model is overfitting, you should reduce it, and if it is underfitting, you should increase it (similar to the C hyperparameter).
), and as a result each instance’s range of influence is smaller: the decision boundary ends up being more irregular, wiggling扭动 around individual instances. Conversely, a small gamma(γ) value makes the bell-shaped curve wider, so instances have a larger range of influence, and the decision boundary ends up smoother. So γ acts like a regularization hyperparameter: if your model is overfitting, you should reduce it, and if it is underfitting, you should increase it (similar to the C hyperparameter).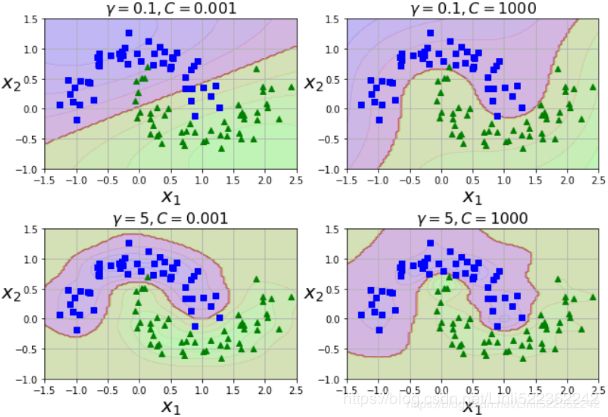
####################################################
from matplotlib.colors import ListedColormap
def plot_decision_boundary( clf, X,y, axes=[-1.5,2.45, -1,1.5], alpha=0.5, contour=True ):
x1s = np.linspace( axes[0],axes[1], 100 )
x2s = np.linspace( axes[2],axes[3], 100 )
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[ x1.ravel(), x2.ravel() ]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap( ['#fafab0','#9898ff','yellow'] )
plt.contourf( x1,x2, y_pred, alpha=0.3, cmap=custom_cmap ) #ploting region
if contour:
custom_cmap2 = ListedColormap( ['#7d7d58','#9898ff','#507d50']) #ploting boundary line
plt.contour(x1,x2, y_pred, cmap=custom_cmap2, alpha=0.8)
plt.plot( X[:,0][y==0], X[:,1][y==0], "yo", alpha=alpha )
plt.plot( X[:,0][y==1], X[:,1][y==1], "bs", alpha=alpha )
plt.axis( axes )
plt.xlabel( r"$x_1$", fontsize=18 )
plt.ylabel( r"$x_2$", fontsize=18, rotation=0 )sample_weights[ y_pred != y_train] *= ( 1+learning_rate ) # 1 for bias; ![]()
sample_weights[ y_pred != y_train] = sample_weights[ y_pred != y_train] * ( 1+learning_rate )
sample_weights[ y_pred != y_train] = sample_weights[ y_pred != y_train] + sample_weights[ y_pred != y_train] * learning_rate
![]() # j is the feature index, j>0
# j is the feature index, j>0![]() # i is the instance index,
# i is the instance index,
w_j = w_j + n*( yi - y^i ) * xi_j
w_0 = w0 + learning_rate *( yi - y^i )* 1
w_j = w_j + learning_rate *( yi - y^i )* xi_j
weights = weights + learning_rate *( yi - y^i ) * (1+xi) # class label: -1/+1 #1+xi : bias coefficient+ instance data
weights[ y_pred != y_train] = weights[ y_pred != y_train] + learning_rate*weights[ y_pred != y_train] # in AdaBoost
m = len(X_train)
fix, axes = plt.subplots( ncols=2, figsize=(10,4), sharey=True )
for subplot, learning_rate in ( (0,1), (1,0.5) ):
sample_weights = np.ones(m)
plt.sca( axes[subplot] )
for i in range(5): #using 5 classifiers
# use RBF kernel to project linearly inseparable data onto a higher dimensional via a mappling function(here is "rbf")
# (this action adds addtional features) to make data become linearly separable
# kernel trick can obtain a similar results as if you had added many similarity features without actually having to add them
# the parameter C > 0 controls the trade-off between the slack variable penalty and the margin.
#if gamma='scale' (default) is passed then it uses 1 / (n_features * X.var()) as value of gamma,
svm_clf = SVC( kernel="rbf", C=0.05, gamma="scale", random_state=42 )#'rbf': Gaussian Radial Basis Function高斯辐射基函数
svm_clf.fit( X_train, y_train, sample_weight=sample_weights )
y_pred = svm_clf.predict( X_train )
#https://blog.csdn.net/Linli522362242/article/details/96429442
sample_weights[ y_pred != y_train] *= ( 1+learning_rate ) # 1 for bias;=w0*1+W^T *X
plot_decision_boundary(svm_clf, X,y, alpha=0.2)
plt.title("learning_rate={}".format(learning_rate), fontsize=16)
if subplot ==0:
plt.text(-0.7, -0.65, "1", fontsize=14)
plt.text(-0.6, -0.10, "2", fontsize=14)
plt.text(-0.5, 0.10, "3", fontsize=14)
plt.text(-0.4, 0.55, "4", fontsize=14)
plt.text(-0.3, 0.90, "3", fontsize=14)
else:
plt.ylabel("")
plt.show()
Figure 7-8. Decision boundaries of consecutive predictors
The first classifier gets many instances wrong, so their weights get boosted. The second classifier therefore does a better job on these instances, and so on. The plot on the right represents the same sequence of predictors except that the learning rate is halved (i.e., the misclassified instance weights are boosted half as much at every iteration误分类实例权重每次迭代上升一半). As you can see, this sequential learning technique has some similarities with Gradient Descent, except that instead of tweaking a single predictor’s parameters to minimize a cost function, AdaBoost adds predictors to the ensemble, gradually making it better逐渐使其更好.
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm='SAMME.R', learning_rate=0.5, random_state=42
)
# X,y = make_moons( n_samples=500, noise=0.30, random_state=42 )
# X_train, X_test, y_train, y_test = train_test_split( X,y, random_state=42 ,test_size=0.25)
ada_clf.fit( X_train, y_train )
plot_decision_boundary(ada_clf, X,y) 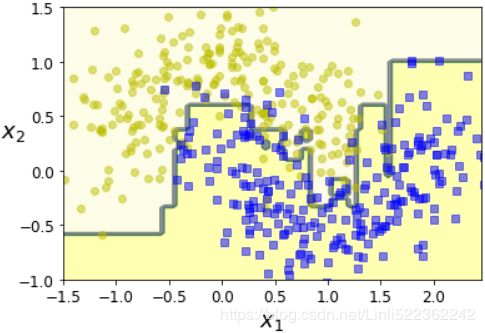
list(m for m in dir(ada_clf) if not m.startswith("_") and m.endswith("_"))
Once all predictors are trained, the ensemble makes predictions very much like bagging or pasting, except that predictors have different weights depending on their overall accuracy on the weighted training set.
###########################################
WARNING
There is one important drawback缺点 to this sequential learning technique: it cannot be parallelized (or only partially), since each predictor can only be trained after the previous predictor has been trained and evaluated. As a result, it does not scale as well as bagging or pasting.
###########################################
Let’s take a closer look at the AdaBoost algorithm. Each instance weight ![]() is initially set to
is initially set to ![]() (m: the number of instances). A first predictor is trained and its weighted error rate
(m: the number of instances). A first predictor is trained and its weighted error rate ![]() is computed on the training set; see Equation 7-1.
is computed on the training set; see Equation 7-1.
Equation 7-1. Weighted error rate of the![]() predictor
predictor where
where ![]() is the
is the ![]() predictor’s prediction for the
predictor’s prediction for the ![]() instance. ( for example weights[ y_pred != y_train])
instance. ( for example weights[ y_pred != y_train])
Equation 7-2. Predictor weight
The predictor’s weight ![]() is then computed using Equation 7-2, where η is the learning rate hyperparameter (defaults to 1).(The original AdaBoost algorithm does not use a learning rate hyperparameter) The more accurate the predictor is, the higher its weight will be. If it is just guessing randomly, then its weight will be close to zero. However, if it is most often wrong (i.e., less accurate than random guessing), then its weight will be negative.
is then computed using Equation 7-2, where η is the learning rate hyperparameter (defaults to 1).(The original AdaBoost algorithm does not use a learning rate hyperparameter) The more accurate the predictor is, the higher its weight will be. If it is just guessing randomly, then its weight will be close to zero. However, if it is most often wrong (i.e., less accurate than random guessing), then its weight will be negative.
for instances: =1/5 then
=1/5 then ![]() =0.5 * log( (1-1/5) / (1/5) ) ==>
=0.5 * log( (1-1/5) / (1/5) ) ==> 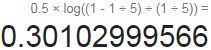
![]() =4/5 then
=4/5 then ![]() =0.5 * log( (1-4/5) / (4/5) ) ==>
=0.5 * log( (1-4/5) / (4/5) ) ==> ![]()
Next the instance weights are updated using Equation 7-3: the misclassified instances are boosted
Equation 7-3. Weight update rule
for i = 1, 2, ⋯,m
Then all the instance weights are normalized (i.e., divided by ![]() Note: accumulation in iteration proecess, so m is the number of instances has been used in current iteration).
Note: accumulation in iteration proecess, so m is the number of instances has been used in current iteration).
Finally, a new predictor is trained using the updated weights, and the whole process is repeated (the new predictor’s weight is computed, the instance weights are updated, then another predictor is trained, and so on). The algorithm stops when the desired number of predictors is reached, or when a perfect predictor is found.
To make predictions, AdaBoost simply computes the predictions of all the predictors and weighs them using the predictor weights ![]() . The predicted class is the one that receives the majority of weighted votes (see Equation 7-4).
. The predicted class is the one that receives the majority of weighted votes (see Equation 7-4).
Equation 7-4. AdaBoost predictions
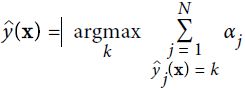 where N is the number of predictors.
where N is the number of predictors.
Scikit-Learn actually uses a multiclass version of AdaBoost called SAMME (which stands for Stagewise Additive Modeling using a Multiclass Exponential loss function这就代表了 分段加建模使用多类指数损失函数). When there are just two classes, SAMME is equivalent to AdaBoost. Moreover, if the predictors can estimate class probabilities (i.e., if they have a predict_proba() method), Scikit-Learn can use a variant of SAMME called SAMME.R (the R stands for “Real”), which relies on class probabilities rather than predictions and generally performs better.
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm='SAMME.R', learning_rate=0.5, random_state=42
)
# X,y = make_moons( n_samples=500, noise=0.30, random_state=42 )
# X_train, X_test, y_train, y_test = train_test_split( X,y, random_state=42 ,test_size=0.25)
ada_clf.fit( X_train, y_train )
plot_decision_boundary(ada_clf, X,y)#################################
TIP
If your AdaBoost ensemble is overfitting the training set, you can try reducing the number of estimators or more strongly regularizing the base estimator.
#################################
##########################################extra materials
8.2.3 Boosting
We now discuss boosting, yet another approach for improving the predictions resulting from a decision tree. Like bagging, boosting is a general approach that can be applied to many statistical learning methods for regression or classification. Here we restrict our discussion of boosting to the context of decision trees.
Recall that bagging involves creating multiple copies of the original training data set using the bootstrap, fitting a separate decision tree to each copy, and then combining all of the trees in order to create a single predictive model. Notably, each tree is built on a bootstrap data set, independent of the other trees. Boosting works in a similar way, except that the trees are grown sequentially: each tree is grown using information from previously grown trees. Boosting does not involve bootstrap sampling; instead each tree is fit on a modified version of the original data set.
########################
Algorithm 8.2 Boosting for Regression Trees
1. Set ![]() = 0 and residual
= 0 and residual ![]() =
= ![]() for all i in the training set. { fit a decision tree to the residuals from the model}
for all i in the training set. { fit a decision tree to the residuals from the model}
2. For b = 1, 2, . . .,B, repeat: The number of trees B. Unlike bagging and random forests, boosting can overfit if B is too large, although this overfitting tends to occur slowly if at all. We use cross-validation to select B.
- (a) Fit a tree
 with d splits (d+1 terminal nodes= d internal nodes(like features
with d splits (d+1 terminal nodes= d internal nodes(like features) to the training data (X, r).{fit a tree using the current residuals = 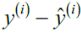 or
or 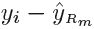 https://blog.csdn.net/Linli522362242/article/details/104542381}
https://blog.csdn.net/Linli522362242/article/details/104542381}
The number d of splits in each tree, which controls the complexity of the boosted ensemble. Often d = 1 works well, in which case each tree is a stump树桩, consisting of a single split. In this case, the boosted stump ensemble is fitting an additive model, since each term involves only a single variable. More generally d is the interaction depth, and controls interaction the interaction order of the boosted model, since d splits can involve depth at most d variables. - (b) Update
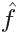 by adding in a shrunken压缩后的 version of the new tree:
by adding in a shrunken压缩后的 version of the new tree:
![]() . (8.10)
. (8.10)
The shrinkage parameter λ, a small positive number. This controls the rate at which boosting learns( ==η is the learning rate). Typical values are 0.01 or 0.001, and the right choice can depend on the problem. Very small λ can require using a very large value of B in order to achieve good performance.
for example:
w_j = w_j + learning_rate *( yi - y^i )* xi_j
weights = weights + learning_rate *( yi - y^i ) * (1+xi) # class label: -1/+1 #1+xi : bias coefficient+ instance data
weights[ y_pred != y_train] = weights[ y_pred != y_train] + learning_rate*weights[ y_pred != y_train]
- (c) Update the residuals(I believe
 is weighted error rate of the jth predictor ),
is weighted error rate of the jth predictor ),
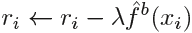 (8.11)
(8.11)
###############-->
###############
3. Output the boosted model,
 (8.12) is similar to
(8.12) is similar to 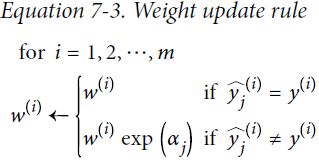
Consider first the regression setting. Like bagging, boosting involves combining a large number of decision trees, ![]() , . . . ,
, . . . , ![]() . Boosting is described in Algorithm 8.2.
. Boosting is described in Algorithm 8.2.
What is the idea behind this procedure? Unlike fitting a single large decision tree to the data, which amounts to fitting the data hard对数据的严格契合 and potentially overfitting, the boosting approach instead learns slowly. Given the current model, we fit a decision tree to the residuals from the model. That is, we fit a tree using the current residuals, rather than the outcome Y , as the response. We then add this new decision tree into the fitted function in order to update the residuals. Each of these trees can be rather small, with just a few terminal nodes, determined by the parameter d in the algorithm. By fitting small trees to the residuals, we slowly improve ![]() in areas where it does not perform well. The shrinkage parameter λ slows the process down even further, allowing more and different shaped trees to attack the residuals. In general, statistical learning approaches that learn slowly tend to perform well. Note that in boosting, unlike in bagging, the construction of each tree depends strongly on the trees that have already been grown.
in areas where it does not perform well. The shrinkage parameter λ slows the process down even further, allowing more and different shaped trees to attack the residuals. In general, statistical learning approaches that learn slowly tend to perform well. Note that in boosting, unlike in bagging, the construction of each tree depends strongly on the trees that have already been grown.
We have just described the process of boosting regression trees. Boosting classification trees proceeds in a similar but slightly more complex way, and the details are omitted here.
Boosting has three tuning parameters:
- The number of trees B. Unlike bagging and random forests, boosting can overfit if B is too large, although this overfitting tends to occur slowly if at all. We use cross-validation to select B.
- The shrinkage parameter λ, a small positive number. This controls the rate at which boosting learns( ==η is the learning rate). Typical values are 0.01 or 0.001, and the right choice can depend on the problem. Very small λ can require using a very large value of B in order to achieve good performance.
- the interaction depth d : The number d of splits in each tree, which controls the complexity of the boosted ensemble. Often d = 1 works well, in which case each tree is a stump树桩, consisting of a single split. In this case, the boosted stump ensemble is fitting an additive model, since each term involves only a single variable. More generally d is the interaction depth, and controls interaction the interaction order of the boosted model, since d splits can involve depth at most d variables.

FIGURE 8.11. Results from performing boosting and random forests on the 15-class gene expression data set in order to predict cancer versus normal. The test error is displayed as a function of the number of trees. For the two boosted
models, λ = 0.01. Depth-1 trees slightly outperform depth-2 trees, and both outperform the random forest, although the standard errors are around 0.02, making none of these differences significant. The test error rate for a single tree is 24%.
In Figure 8.11, we applied boosting to the 15-class cancer gene expression data set, in order to develop a classifier that can distinguish the normal class from the 14 cancer classes. We display the test error as a function of the total number of trees and the interaction depth d. We see that simple stumps(d = 1) with an interaction depth of one perform well if enough of them are included(若树的数量足够多). This model outperforms the depth-two model, and both outperform a random forest. This highlights one difference between boosting and random forests: in boosting, because the growth of a particular tree takes into account the other trees that have already been grown, smaller
trees are typically sufficient. Using smaller trees can aid in interpretability as well; for instance, using stumps leads to an additive model.
########################
##########################################
Gradient Boosting
https://blog.csdn.net/Linli522362242/article/details/105046444