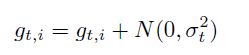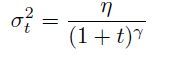综述--梯度下降优化算法
paper: An overview of gradient descent optimization algorithms
梯度下降优化算法,一般作为黑箱优化来使用,对其优缺点缺乏充足的认识。
首先,回顾一下一些常用的梯度下降算法。有3种梯度下降法的变种,区别在于使用多少数据来更新梯度,在更新的准确度和计算时间中达到一个平衡。
Batch Gradient Descent
对整个训练数据集计算参数梯度,并更新一次参数,计算很冗余,不允许online更新模型,即只学习新样本。保证收敛到局部最小点。(非凸)
BGD在每次参数更新前,都对相似样本重复计算梯度。SGD去除了这种冗余性,因此更新非常快,且可以online更新模型。但是SGD更新太过频繁,且更新大小浮动很大(方差很大),导致目标函数产生巨大波动。
Stochastic Gradient Descent
对整个训练样本计算参数梯度,并更新一次参数,计算很慢,不允许online更新模型,即只学习新样本。保证收敛到局部最小点。(非凸)SGD的浮动性,一方面可以使SGD跳到局部更优点,一方面又导致不能达到确切的局部最优点。随着缓慢降低学习率,SGD具有和BGD一样的收敛性。
Mini-batch Gradient Descent(typically the algorithm of choice)
考虑到BGD和SGD两者的优点,相较于SGD,参数更新的方差更小,收敛更加稳定,每个mini-batch后更新一次参数,一般mini-batch的大小选在50-256之间。之后提到的SGD一般指代mini-batch SGD。
其次,总结训练时遇到的困难。
一般的SGD方法,无法保证良好的收敛性,且存在许多问题,迄待解决。
1)挑选一个合适的学习率。太小收敛过慢,太大会导致难以收敛至极值点。
2)学习方法(learning schedule),训练中调整学习率。根据一个预先定义的学习计划,逐渐降低学习率,或者如果在每个epoch之间,目标函数的变化小于某个阈值,降低学习率(annealing)。需要提前设定,不能根据数据集的特征而自动调整。
3)对于不同的参数,有相同的学习参数。对于不同的参数,可能不希望同步调整参数,希望对于低频的变量有更大的更新量。
4)在最小化目标函数过程中,避免陷于局部次优点。saddle point,只有一维梯度上升,其他维度梯度降低,鞍点周围目标函数近似相等,梯度近似0,很难逃离。
介绍一下最常用的梯度下降优化方法。
momentum
momentum加速趋向局部最小值点,并抑制振荡。将之前的更新量乘以γ(通常设为0.9),加到这一步的更新量上,达到加快收敛,抑制振荡的效果。
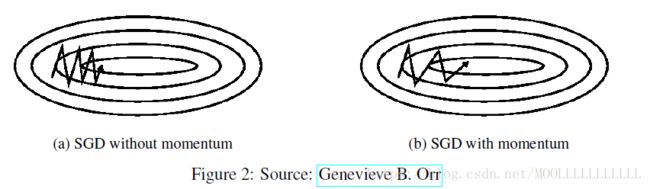
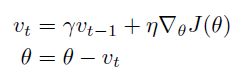
Nesterov Accelerated gradient(NAG)
计算下一个参数近似位置的梯度,而不是现在变量的梯度,避免了前进太快,增加了敏捷性。
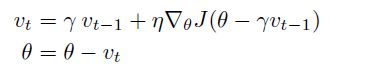

蓝色是Momentum,绿色是NAG。
我们可以针对单个变量,根据其重要性,相应地调整或大或小的更新。
Adagrad
对不同参数相应地调整学习率,频繁参数更新量小,不频繁参数更新量大。适合稀疏数据。
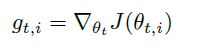
Adagrad调整了普遍的学习率,Gt是一个对角矩阵,ε是一个避免分母为0的参数,一般取1e-8
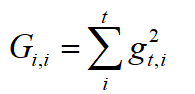
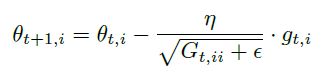
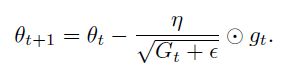 matrix-vector multiplication
matrix-vector multiplication
Adagrad的优点,不需要手动调整学习率,可以一直设为0.01。缺点在于分母上不断积累梯度平方和,不断增加,导致学习率不断收缩,直到无限小,导致无法继续训练。
Adadelta
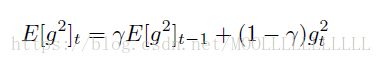
将Gt替换为衰减平均值E[g2]t。
变为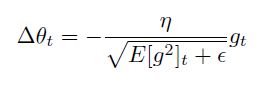 ,即
,即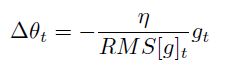
考虑到变量单位不对称的问题,定义了变量更新量的衰减平均值,并使用其RMS替换学习率来进行学习。
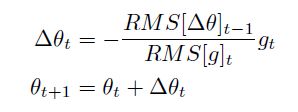
取消了学习率。
RMSprop
是Adadelta的一个特殊情况。建议学习率设为0.001
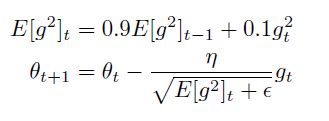
Adam

Adam在RMSprop的基础上计算了一阶矩,来替代现在的梯度量进行参数更新,因为mt,vt初始为0,观察到其偏于0,尤其在训练初期,以及当衰减率很小的时候。
提出一个bias-corrected量来抵消偏好的作用
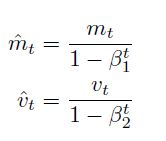
使用bias-corrected量来进行参数更新
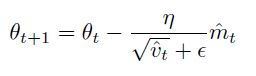
β1 取0.9, β2 取0.999
Adamax
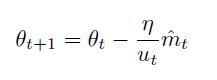
![]()
ut是Adam中vt的l∞正则化形式。max操作不受偏好影响。学习率取0.002.
Nadam
Adam可以看作RMSprop和momentum的结合,NAG比momentum更优越,因此Nadam考虑结合Adam和NAG.
Adam有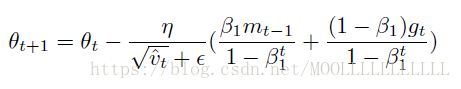
可以看出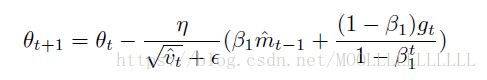
使用mt替换mt-1,有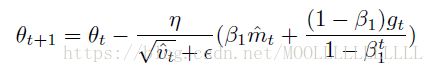
which optimizer to use?
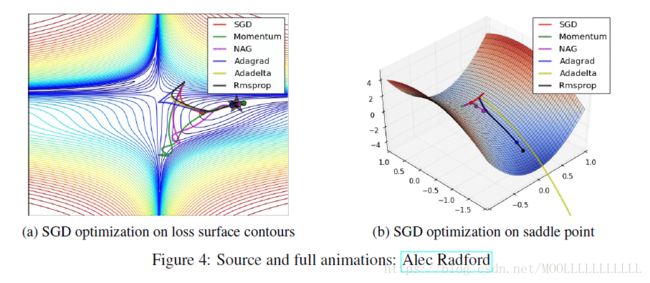
使用自适应学习率方法更好,相较于RMSprop,Adam增加了偏好修正bias-correction和动量。Adadelta, RMSprop, Adam是很相似的方法,其中Adam最佳。
最后,优化梯度方法之外的有效策略,用以提高效果。
1)shuffle data after every epoch,避免训练数据排列有一定意义,从而导致偏好。对于一些逐渐变难的问题,使用curriculum learning(对训练数据进行有意义的排序),效果可能更加。
2)batch normalization,为了促进学习,初始化参数时,一般取均值0,方差1。随着训练的不断进行,这种归一化逐渐消失,导致训练的变慢,且随着网络的加深,参数的改变被放大。每个mini-batch之后,batch normalization参数,且变化通过BP算法传递给变量。对于部分模型使用BN,可以使用更大的学习率,且初始化参数可更随意。BN作为一定程度上充当正则化作用,减少了dropout的需要。
3)gradient noise,每次对梯度更新增加噪音,噪音服从高斯分布N(0,σt2),增加梯度噪音可以使网络对于poor初始化更鲁棒