Hbase是一个高可靠、高性能、面向列、可伸缩的分布式数据库。其底层的LSM数据结构和RowKey有序排列等架构上的独特设计,使得hbase具有非常高的写入性能。但是在实际使用中,由于对hbase的写入方面的机制没有深入的了解,无法有效发挥出hbase的写入性能。本文主要记录了在刚开始使用hbase时,对hbase没有太多的了解的基础上,在写入方面遇到的一个问题和解决方法。
Hbase原生支持java写入,但由于实际业务的需要和迁移的成本,要使用python来写入hbase。hbase中集成了thrift框架,支持使用python对hbase进行操作。happybase是 FaceBook 员工开发的操作HBase的 Python库,其基于 Thrift,封装了大多数hbase的操作方法,使得通过python也能对hbase进行操作。
问题描述
在初步安装好6个RS的Hbase集群上,新建一张测试表,使用200G的数据,进行写入性能的测试。
采用happybase写入hbase,下面是一段简化的代码:
(con, table) = get_hbase_con(table_name=table_name)
with table.batch(batch_size=200) as batch:
with open(filepath) as fp:
for line in fp:
records = line.strip().split(',')
cf={"cf:data":records}
batch.put(row=rowkey, data=cf)
Happybase的put方法原本就是采用batch批量提交数据,在代码中使用table.batch可以自己控制batch_size的大小。采用batch提交,减少rpc请求次数,提高写入的性能。
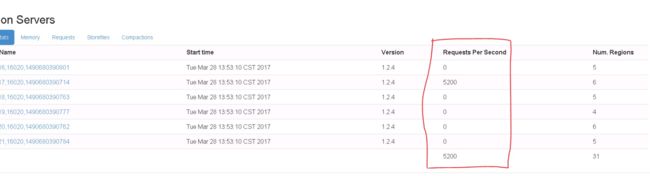
运行程序时,程序通过socket与hbase的thriftsever连接,将请求发给thriftsever,由thriftsever调用hbase的client端进行写入。使用单线程进行数据的写入一段时间之后,总会出现socket.timeout的问题。一旦出现该问题后,程序终止运行,如下图所示:
出现此问题时,写入的每秒请求数才5200多,并且是持续的向一个region中写入。
问题分析和解决
为了解决这个问题,我安装了ganglia监控工具。在写入的时候,查看集群上的指标,发现写入的节点上负载过重,cpu利用率飙升,其它节点基本处于休眠状态。由此现象可以初步断定是hbase写入的热点问题造成了timeout。解决hbase的热点问题,关键在于rowkey的设计和预分区上。
Hbase的RowKey是按字点排序由低到高进行存储的,在设计时需要遵循散列性,唯一性,同时也要兼顾实际业查询的需求,这样在写入的过程中不至于造成一台集群负载过重的情况。
现有的RowKey的设计规则如下:

很明显其是按时间有序排列的,不符合rowkey的散列性,原始数据是按时间顺序排列的,在插入时,就会一直向同一个region中插入,因此造成热点问题。通过改进,将后面的标示位放置rowkey的前缀,由于标示位是散列的,没有规律,RowKey的设计变成了:
RowKey = 标示位+预留10位+时间戳
清空测试表后,重新插入数据测试,发现插入时仍然会出现热点问题。继续进行分析,查到一段话:
默认情况下,当我们通过hbaseAdmin指定TableDescriptor来创建一张表时,只有一个region正处于混沌时期,start-end key无边界,可谓海纳百川。所有的rowkey都写入到这个region里,然后数据越来越多,region的size越来越大时,大到一定的阀值,hbase就会将region一分为二,成为2个region,这个过程称为分裂(region-split)。
如果我们就这样默认建表,表里不断的put数据,更严重的是我们的rowkey还是顺序增大的,是比较可怕的。存在的缺点比较明显:首先是热点写,我们总是向最大的start key所在的region写数据,因为我们的rowkey总是会比之前的大,并且hbase的是按升序方式排序的。所以写操作总是被定位到无上界的那个region中;其次,由于热点,我们总是往最大的start key的region写记录,之前分裂出来的region不会被写数据,有点打入冷宫的感觉,他们都处于半满状态,这样的分布也是不利的。
hbase热点问题(数据倾斜)解决方案—rowkey散列和预分区设计 - - ITeye技术网站
按照这个解释,即使对rowkey进行散列化设计,仍然不能解决热点问题,初始建表没有进行预分区时,只有一个region,其并没有一个上界,导致在插入时还是不断的向一个region中插入。因此接下的操作是进行表进行预分区。
由于RowKey的设计已经变成了散列性,导致预分区不好确定每个region的RowKey范围。针对此问题,在有限的数据中,采取了将所有的rowkey提取出来排序后,分段抽取的方式,确定了每个region的范围。
通过rowkey的散列化和预分区,每个节点上都启动ThrfftServer服务,将200G的大文件拆成了多个小文件,然后采用python的多进程再次进行测试。此时出现了可喜的结果,

从图可以看到,写入的请求分布的比较均匀,不再集中到一个region 上。从ganglia上的监控上看,单个节点的负载比之前有很大的下降。到此,hbase的写入热点问题基本上解决。
从图可以看到,写入的请求分布的比较均匀,不再集中到一个region 上。从ganglia上的监控上看,单个节点的负载比之前有很大的下降。到此,hbase的写入热点问题基本上解决。
但是timeout的情况依然出现,出现时间较之前有延后,可见问题并没有彻底的解决。timeout出现时间延后,说明解决hbase写入的热点问题对timeout问题是有帮助的。
因此我对hbase的写入过程中进行了更加深入的分析,看看数据在写入的过程中究竟发生了什么。
Hbase写入过程包括了客户端和服务端,采用客户端批量写入数据,数据会现在本地的buffer中缓存,到达阈值后,客户端就会将数据推送到服务端,服务端收到数据后先写日志,然后在写入memstore中,memstore满后就会flush到storefiles,当storefiles 的数量增长到一定阈值后,就会进行compact成更大的storefile,当storefile达到阈值后就会split成两个region,被hmaster分配到其它的regionserver中。
由于写入过快,服务器端需要大量compact,split操作时,很容易阻塞数据的写入,会出现has too many store files; delaying flush up to 90000ms等问题。一旦出现服务端阻塞写入的问题,client端就会延迟收到响应结果。如果在规定的时间内,客户端仍未接收到服务器端的响应,socket就会出现timeout的情况,然后客户端和服务器端的连接就会断掉,写入过程终止。通过对日志的分析,也说明了出现timeout的问题时,hbase正在进行compact或split操作。
从上述的分析中,明确了解决timeout问题的下一步目标是优化hbase的写入性能。通过对hbase的region size、rpc超时时间、scanner超时时间、memstore fluse size、blockingStoreFiles等参数优化,降低compact和split的频率,延迟超时出现的时间,也降低了超时的频率。
除非全部手动进行,hbase进行compact和split是不可避免的,因此写入超时也是不可避免的。从happybase的githup上找到了解决timeout一劳永逸的方法,将客户端的timeout置为不限。thriftpy0.3.3设置了默认的超时时间为3s,要想永不超时,将timeout设置为None即可。
Since thriftpy 0.3.3, there has been a socket_timeout option to TSocket. The default is 3000 ms. Setting it to None means “never timeout”. Remove the if self.timeout is not None conditional so a value of None can also be set explicitly from happybase.
Set socket timeout unconditionally on TSocket by ecederstrand · Pull Request #146 · wbolster/happybase · GitHub
# timeout = None
con = happybase.Connection(host=host, autoconnect=False, timeout=None, transport='buffered')
网上有建议将timeout设置更长一点,但是由于网络以及服务端的问题不确定性,超时的风险很大。直接设置成None,客户端就会一直等待服务端的响应,再也不会出现超时的问题。
上述方法虽然一劳永逸,但是如果有潜在的风险就是一直阻塞。推荐采取手动的处理超时问题。在捕获到超时后,选择断开连接,暂停一小段时间写入,重新连接然后进行写入。
总结
初入Hbase,作为一个小白,耗费了较长的时间才解决写入超时的问题。一个问题牵涉了Hbase的方方面面,使我收获满满:
1、更了解hbase的特点,RowKey的设计,表的预分区。
2、从源码上了解Hbase的写入过程
4、如何优化hbase性能
5、分析和解决问题的思路