sparksql按mysql实例+黑名单抽取数据,并生成hive的建表和视图的语句写入hdfs
最近做了一个小功能,在这记录一下:
- 一部分maxwell+fink+黑名单实时抽取mysql的binlog数据,落地到hive表
- 为了弥补历史数据未进行变更的问题,让我写了一套离线抽数据的程序
实现的功能点
- 一 配置信息mysql.properties
- 二 pom文件
- 三 解析mysql.properties文件
- 四 加载对应mysql 实例下的所有表
- 五 读取黑名单中的数据库和表,库和表都按,分隔
- 六 按照mysql 实例查询出改下所有表的主键信息
- 七 查询出写出成功的表的信息
- 八 获取mysql连接
- 九 写出建表语句
- 十 写出对应的去重视图语句
- 十一 追加写hdfs
- 十二 完整的程序如下
- 十三 根据DataFrame 匹配建表语句
- 十四 查询mysql 整个实例所有表的json字段
- 十五 提交脚本
- 十六 运行结果截图
- 总结
一 配置信息mysql.properties
#采集的数据实例配置
# url,用户名,密码,实例id
mysql.info1=jdbc:mysql://xxxxx:3306,root,zU!ykpx3EG)$$1e6,161345
#mysql.info1=jdbc:mysql://xxxxx.10:3306,root,Xfxcj2018@)!
#黑名单数据库配置表
config.url=jdbc:mysql://xxxxx:3306
# 黑名单表
config.table=flink_config.black_binlog_config
config.username=bgp_admin
config.password=3Mt%JjE#WJIt
# 分页条数 默认 20万 条数据 一个分区
pageSzie=200000
# 记录成功信息的mysql表
config.mysql_Crawl=flink_config.mysql_crawl
#数据落hdfs的目录
hdfs.url=/user/flink/flink-binlog/data
# hive 对应的库名
hive.database=mysql_json
#hive 对应的视图库
hive.viewDatabase=mysql_view
# 建表语句生成时写出去的hdfs 目录
hive.create_table_file=/user/flink/flink-binlog/schema
#视图语句生成时写出去的hdfs 目录
hive.create_view_file=/user/flink/flink-binlog/schema
二 pom文件
<properties>
<scala.version>2.11.8scala.version>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<spark.version>2.3.0spark.version>
<hadoop.version>2.6.0hadoop.version>
<scala.binary.version>2.11scala.binary.version>
properties>
<repositories>
<repository>
<id>scala-tools.orgid>
<name>Scala-Tools Maven2 Repositoryname>
<url>http://scala-tools.org/repo-releasesurl>
repository>
repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.orgid>
<name>Scala-Tools Maven2 Repositoryname>
<url>http://scala-tools.org/repo-releasesurl>
pluginRepository>
pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.43version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.kudugroupId>
<artifactId>kudu-spark2_2.11artifactId>
<version>1.10.0version>
dependency>
dependencies>
三 解析mysql.properties文件
/**
* 读取配置文件获取指定的实例信息
* @return
*/
def getMysqlMessage(properties:Properties):List[(String,String,String,String)]={
val keysSet: util.Enumeration[_] = properties.propertyNames()
var list = List[(String, String, String,String)]()
while (keysSet.hasMoreElements) {
val key = keysSet.nextElement()
if(key.toString.contains("mysql.info")){
val str = properties.getProperty(key.toString)
if(!StringUtils.isEmpty(str)){
list =(str.split(",")(0),str.split(",")(1),str.split(",")(2),str.split(",")(3))::list
}
}
}
list
}
四 加载对应mysql 实例下的所有表
/**
* 根据数据库实例 获取 对应的数据库 和对应的 表
* @param url
* @param userName
* @param password
* @return
*/
def getDataBaseAndTable(url:String,userName:String,password:String):List[MysqlTableInfo] ={
val conn=getMysqlConnection(url,userName,password)
val dataBaseSql ="select TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS,DATA_LENGTH from information_schema.tables"
val statement = conn.createStatement()
val res = statement.executeQuery(dataBaseSql)
var tables = List[MysqlTableInfo]()
// 处理所有的database
while (res.next()) {
tables = MysqlTableInfo(res.getString("TABLE_SCHEMA").toLowerCase,
res.getString("TABLE_SCHEMA").toLowerCase+"."+res.getString("TABLE_NAME").toLowerCase,
res.getLong("TABLE_ROWS"),
res.getLong("DATA_LENGTH"))::tables
}
res.close()
statement.close()
conn.close();
tables
}
五 读取黑名单中的数据库和表,库和表都按,分隔
/**
* 根据 配置文件里的信息读取对应黑名单配置信息表
* CREATE TABLE `black_binlog_config` (
* `id` int(8) NOT NULL AUTO_INCREMENT COMMENT '主键',
* `server_id` varchar(20) NOT NULL COMMENT 'mysql服务器标识',
* `black_databases` varchar(2000) DEFAULT NULL COMMENT '黑名单-数据库',
* `black_tables` varchar(4000) DEFAULT NULL COMMENT '黑名单-表',
* `create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
* PRIMARY KEY (`id`)
* ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COMMENT='flink-binlog黑名单配置表'
*
* databases,tables
*
* @param spark
* @param properties
* @return
*/
def getFilterDataBaseAndTable(spark: SparkSession,properties:Properties):Map[String,(String,String)] ={
import org.apache.spark.sql.functions._
import spark.implicits._
spark.read.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", properties.getProperty("config.url"))
.option("dbtable", properties.getProperty("config.table"))
.option("user", properties.getProperty("config.username"))
.option("password", properties.getProperty("config.password"))
.load()
.select("server_id", "black_databases", "black_tables", "create_time")
.withColumn("rn", row_number().over(Window.partitionBy("server_id").orderBy(desc("create_time"))))
.where("rn=1")
.select("server_id", "black_databases", "black_tables")
.as[(String, String, String)].
collect().toList.map(it=>{(it._1,(it._2,it._3))}).toMap[String,(String,String)]
}
六 按照mysql 实例查询出改下所有表的主键信息
/**
* 按照mysql的实例信息查询出 该实例下所有表的主键信息
*
*Map[表名,主键名]
*
*
* @param url
* @param username
* @param password
*/
def queryMysqlTablePri(url:String,username:String,password:String)={
val conn=getMysqlConnection(url,username,password)
val pri_sql ="SELECT TABLE_SCHEMA,TABLE_NAME,COLUMN_NAME from information_schema.`COLUMNS` where COLUMN_KEY ='PRI'"
val statement = conn.createStatement()
val res = statement.executeQuery(pri_sql)
var tables = List[(String,String,String)]()
// 处理所有的database
while (res.next()) {
tables =((res.getString("TABLE_SCHEMA").toLowerCase,
res.getString("TABLE_SCHEMA").toLowerCase+"."+res.getString("TABLE_NAME").toLowerCase,
res.getString("COLUMN_NAME")))::tables
}
res.close()
statement.close()
conn.close();
tables.map(it=>{(it._2,it._3)}).toMap[String,String]
}
七 查询出写出成功的表的信息
/**
* 查询出所有已经写出成功的表的名称
* CREATE table mysql_crawl (
* table_name VARCHAR(100) PRIMARY KEY,
* server_id VARCHAR(50),
* STATUS int,
* message VARCHAR(500)
* )
*
* @param spark
* @param properties
* @return
*/
def getSuccessTableList(spark: SparkSession,properties:Properties): List[String] ={
import spark.implicits._
spark.read.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", properties.getProperty("config.url"))
.option("dbtable", properties.getProperty("config.mysql_Crawl"))
.option("user", properties.getProperty("config.username"))
.option("password", properties.getProperty("config.password"))
.load().select("table_name").where("status=1").as[String].collect().toList
}
八 获取mysql连接
/**
* 获取mysql 的连接
* @param url
* @param userName
* @param password
* @return
*/
def getMysqlConnection(url:String,userName:String,password:String)={
Class.forName("com.mysql.jdbc.Driver")
DriverManager.getConnection(url, userName, password)
}
九 写出建表语句
hive库名.mysq库名_mysql表名
/**
* 按照数据拼接对应的hive 建表语句
* @param spark
* @param dataFrame
*/
def writeCreateHiveTableSql(spark: SparkSession,dataFrame: DataFrame,tableName:String,hdfsLocation:String,properties:Properties,server_id:String): Unit ={
dataFrame.printSchema()
// val columns = dataFrame.drop("in_hive_path").columns
val list = getTableFields(dataFrame)
val stringBuffer =new StringBuffer(s"CREATE EXTERNAL TABLE IF NOT EXISTS ${properties.getProperty("hive.database")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)}(").append("\n")
var columns_Str = List[String]()
list.foreach(column=>
columns_Str = s"${column._1} ${column._2}"::columns_Str
)
val str: String = columns_Str.reverse.mkString(",\n")
stringBuffer.append(str).append("\n")
stringBuffer.append(")").append("\n")
stringBuffer.append("ROW FORMAT serde 'org.apache.hive.hcatalog.data.JsonSerDe'").append("\n")
.append(s"STORED AS TEXTFILE LOCATION '$hdfsLocation';").append("\n")
val hiveCreateTable = stringBuffer.toString
// 写入 对应的hdfs 目录
val path = new Path(s"${properties.getProperty("hive.create_table_file")}/mysql_hive_create_table_sql_$server_id")
writeToHdfs(spark,path,hiveCreateTable,tableName)
}
十 写出对应的去重视图语句
/**
* 写出hive视图 语句
* 生成对应的hive去重 语句 写入到hdfs
* 先排序 然后过滤掉删除的数据
* select * from (
* * * SELECT *,row_number() over(partition by pri order by in_hive_time desc) as od from xxxx
* * * ) t where t.od =1 and t.in_hive_type<>0
*
* @param spark
* @param tableName
* @param properties
*/
def writeCreateHiveView(spark: SparkSession,dataFrame: DataFrame,tableName:String,properties:Properties,pri_map: Map[String, String],server_id:String)={
// 查询出所有表的主键信息
val fields = getTableFields(dataFrame).map(it=>it._1).mkString(",")
var create_viewSql: String =
s"""
|create view IF NOT EXISTS ${properties.getProperty("hive.viewDatabase")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)} as
| select ${fields}
| from
| (
| SELECT *,row_number() over(partition by ${pri_map.getOrElse(tableName, "erro")} order by in_hive_time desc) as rn from ${properties.getProperty("hive.database")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)}
| ) t where t.rn =1 and t.in_hive_type <> 0;
|""".stripMargin
var path = new Path(s"${properties.getProperty("hive.create_view_file")}/mysql_hive_create_view_sql_$server_id")
if(pri_map.get(tableName).isEmpty){
create_viewSql=
s"""
|create view IF NOT EXISTS ${properties.getProperty("hive.viewDatabase")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)} as
| select ${fields}
| from
| (
| SELECT *,row_number() over(partition by ${pri_map.getOrElse(tableName,"erro")} order by in_hive_time desc) as rn from ${properties.getProperty("hive.database")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)}
| ) t where t.rn =1 and t.in_hive_type <> 0;
|""".stripMargin
path = new Path(s"${properties.getProperty("hive.create_view_file")}/mysql_hive_create_view_sql_${server_id}_error")
}
writeToHdfs(spark,path,create_viewSql,tableName)
}
十一 追加写hdfs
/**
* 向hdfs 追加写文件
* @param spark
* @param path
* @param data
*/
def writeToHdfs(spark: SparkSession,path: Path,data:String,tableName:String) ={
val configuration = spark.sparkContext.hadoopConfiguration
val fs = FileSystem.get(configuration)
var dataOutPutStream: FSDataOutputStream = null;
val isWindows =System.getProperties().getProperty("os.name").toUpperCase().indexOf("WINDOWS")>0
if(isWindows){
dataOutPutStream = fs.create(new Path(path.toString+"/"+tableName), false);
}else{
if(fs.exists(path)){
dataOutPutStream =fs.append(path)
}else{
dataOutPutStream = fs.create(path, false);
}
}
dataOutPutStream.write(data.getBytes("utf-8"))
dataOutPutStream.flush()
dataOutPutStream.close()
}
十二 完整的程序如下
package com.xxxx.spark.entrance
import java.io.FileInputStream
import java.sql.{DriverManager, PreparedStatement}
import java.util
import java.util.Properties
import com.alibaba.fastjson.{JSON, JSONObject}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.fs.{FSDataOutputStream, FileSystem, Path}
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.types.{DateType, DecimalType, DoubleType, FloatType, IntegerType, StringType, StructType, TimestampType}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* created by chao.guo on 2020/5/14
**/
object ReadMysqlApplication {
case class MysqlTableInfo( database:String, tableName:String,tableRows:Long,dataLenth:Long )
def main(args: Array[String]): Unit = {
// 获取参数值
if(args.length<2){
System.err.println("请传入mysql的配置信息文件地址和hdfs master信息(如:hdfs://10.83.0.47:8020)")
return
}
val spark = SparkSession
.builder()
.appName("ReadMysqlApplication")
//.master("local[*]")
.getOrCreate()
spark.sparkContext.setLogLevel("error")
spark.sparkContext.hadoopConfiguration.set("fs.defaultFS", args(1)) //hdfs://10.83.0.47:8020
spark.sparkContext.hadoopConfiguration.setBoolean("dfs.support.append", true)
val mysql_config_path = args(0)
// System.setProperty("HADOOP_USER_NAME", args(1))
// System.setProperty("USER",args(1))
System.err.println(mysql_config_path)
val properties = new Properties()
// properties.load(new FileInputStream("mysql.properties"))
properties.load(FileSystem.get(spark.sparkContext.hadoopConfiguration).open(new Path(mysql_config_path)))
System.err.println(properties)
val hdfs_path = properties.getProperty("hdfs.url")
// 读取配置信息表 获取对应的数据库实例信息
val mysqlList = getMysqlMessage(properties)
// 查询指定的 黑名单表
val blackTbaleMap: Map[String, (String, String)] = getFilterDataBaseAndTable(spark, properties)
val success_crawl_mysql_tableList = getSuccessTableList(spark, properties) //写入成功的mysql 表
val conn = getMysqlConnection(properties.getProperty("config.url"), properties.getProperty("config.username"), properties.getProperty("config.password"))
val sql = "insert into "+properties.getProperty("config.mysql_Crawl")+"(table_name,server_id,status,message)values(?,?,?,?)" // 将成功的表写入mysql 以便下次从没跑的地方开始跑
println(sql)
val statement = conn.prepareStatement(sql)
for (mysql <- mysqlList) {
//每个实例对应的表和数据库信息
val jsonFielsMap = queryMysqlTableJsonFields(mysql._1, mysql._2, mysql._3)
val tables: List[MysqlTableInfo] = getDataBaseAndTable(mysql._1, mysql._2, mysql._3)
//过滤到不需要的数据表
for (elem <- tables) {
if (!success_crawl_mysql_tableList.contains(elem.tableName)) {
writeTbaleData(spark,elem, blackTbaleMap, hdfs_path, mysql, statement,properties,jsonFielsMap)
}
}
}
statement.close()
conn.close()
spark.close()
}
/**
* 查询出所有已经写出成功的表的名称
* CREATE table mysql_crawl (
* table_name VARCHAR(100) PRIMARY KEY,
* server_id VARCHAR(50),
* STATUS int,
* message VARCHAR(500)
* )
*
* @param spark
* @param properties
* @return
*/
def getSuccessTableList(spark: SparkSession,properties:Properties): List[String] ={
import spark.implicits._
spark.read.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", properties.getProperty("config.url"))
.option("dbtable", properties.getProperty("config.mysql_Crawl"))
.option("user", properties.getProperty("config.username"))
.option("password", properties.getProperty("config.password"))
.load().select("table_name").where("status=1").as[String].collect().toList
}
/**
* 按表 往外写表的数据
* @param elem
* @param blackTbaleMap
* @param hdfs_path
* @param mysql
*/
def writeTbaleData(spark: SparkSession,elem:MysqlTableInfo,blackTbaleMap:Map[String,(String,String)],hdfs_path:String,mysql:(String,String,String,String),statement:PreparedStatement,properties:Properties,jsonFieldsMap:Map[String,String])={
val database = elem.database // 数据库
val tableName = elem.tableName // 表的名字
val rows = if(elem.tableRows==0) 1 else elem.tableRows // 表的数据行数
val serverId = mysql._4 // 实例id
val total_count=elem.tableRows
//计算单条数据的大小
val record_length= elem.dataLenth /rows // 单条数据长度
// 假定以256M为一块
val block_length = 128*1024*1024
val pageSize =if(record_length==0) {1} else (block_length /record_length).toInt
//val pageSize =properties.getProperty("pageSzie").toInt
// val partitionNum = if (elem.dataLenth/1024/1024/128==0)1 else elem.dataLenth/1024/1024/128
val page = (if (elem.dataLenth%block_length==0)elem.dataLenth/block_length else elem.dataLenth/block_length+1).toInt
//val page = (if (total_count%pageSize==0)total_count/pageSize else total_count/pageSize+1).toInt
val dataBase_table:(String,String)= blackTbaleMap.getOrElse(serverId,null) // 从黑名单中根据serverID 获取对应的
if(dataBase_table!=null){
import org.apache.spark.sql.functions._
val black_databases= dataBase_table._1.split(",")
val black_tables = dataBase_table._2.split(",")
if (!black_databases.contains(elem.database) && !black_tables.contains(elem.tableName)) {
System.err.println(s"正在读取${tableName},表的数据条数为${total_count/10000}万,表的数据量为${elem.dataLenth/1024/1024}M")
val write_hdfs_path =s"${hdfs_path}/mysql${serverId}/${database}/${tableName.split("\\.")(1)}" //过滤掉指定的数据库 和指定的数据表
var dataFrame: DataFrame = null
if((elem.dataLenth/1024/1024).toInt >200 && page>0){
System.err.println(s"正在处理的表 大于200M,pageSize为${pageSize},页数为${page}")
val pro = new Properties()
pro.put("user", mysql._2)
pro.put("driver","com.mysql.jdbc.Driver")
pro.put("password",mysql._3)
var partiionArray = Array[String]()
// val page = (if (total_count%pageSize==0)total_count/pageSize else total_count/pageSize+1).toInt
for (pag <- 1.to(page)) {
partiionArray = partiionArray.:+( s"1=1 limit ${(pag-1)*pageSize} , ${pageSize}")
}
System.err.println(partiionArray.mkString(","))
dataFrame = spark.read.jdbc(mysql._1, s"`${tableName.split("\\.")(0)}`.`${tableName.split("\\.")(1)}`",partiionArray,pro)
}else{
dataFrame = spark.read.format("jdbc")
.option("url", mysql._1)
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable", s"`${tableName.split("\\.")(0)}`.`${tableName.split("\\.")(1)}`")
.option("user", mysql._2)
.option("password", mysql._3)
// .option("query",s"select * from ${tableName} where 1=1")
.load()
}
val frame = dataFrame
.withColumn("in_hive_time", lit(System.currentTimeMillis()))
.withColumn("in_hive_type", lit(4))
.withColumn("in_hive_path", lit(s"mysql${serverId}/${database}/${tableName.split("\\.")(1)}"))
// if(total_count>0){
System.err.println(s"serverid=${serverId},url=${mysql._1},database=${database},tableName=${tableName},rows=${total_count},partitionNum=${page},write_hdfs_path=${write_hdfs_path}")
//数据写hdfs
if(total_count>0) {
val jsonFields = jsonFieldsMap.getOrElse(tableName,"")
System.err.println(s"jsonFiles------------------${jsonFields}")
// mysql 中数据类型为json 的数据 拉过来 使用 format("json") 写出去,会导致json 数据前包含“{ ,使用hive 的serde 无法解析
import spark.implicits._
val columns: Array[String] = frame.columns
val result = frame.mapPartitions(func = it => {
var list = List[String]()
while (it.hasNext) {
val json = new JSONObject()
val row = it.next()
for (elem <- columns) {
json.put(elem,row.getAs(elem))
if (!StringUtils.isEmpty(jsonFields)) {
val strings = jsonFields.split(",")
for (i <- 0.until(strings.length)) {
if (StringUtils.equals(strings(i), elem)) {
val str = row.getAs[String](elem)
json.put(elem, JSON.parse(str))
}
}
}
}
list = json.toString :: list
}
list.iterator
})
result.write.format("text").mode("append").save(write_hdfs_path)
// frame.write.format("json")
// .option("timestampFormat", "yyyy-MM-dd HH:mm:ss").mode("append").save(write_hdfs_path)
}else { // 创建空目录
val fs = FileSystem.get(spark.sparkContext.hadoopConfiguration)
if(!fs.exists(new Path(write_hdfs_path))){
fs.mkdirs(new Path(write_hdfs_path))
}
// 建表语句写hdfs
}
writeCreateHiveTableSql(spark,frame,elem.tableName,s"${write_hdfs_path}",properties,serverId)
// 视图建表语句写hdfs
val pri_map: Map[String, String] = queryMysqlTablePri(mysql._1,mysql._2,mysql._3)
writeCreateHiveView(spark,dataFrame,elem.tableName,properties,pri_map,serverId)
//将成功的表的数据写入到mysql
statement.setString(1,elem.tableName)
statement.setString(2,serverId)
statement.setInt(3,1)
statement.setString(4,s"serverid=${serverId},url=${mysql._1},database=${database},tableName=${tableName},rows=${total_count},partitionNum=${page},write_hdfs_path=${write_hdfs_path}")
statement.execute()
Thread.sleep(50)
// }
}
}
}
/**
* 按照mysql的实例信息查询出 该实例下所有表的主键信息
*
*Map[表名,主键名]
*
*
* @param url
* @param username
* @param password
*/
def queryMysqlTablePri(url:String,username:String,password:String)={
val conn=getMysqlConnection(url,username,password)
val pri_sql ="SELECT TABLE_SCHEMA,TABLE_NAME,COLUMN_NAME from information_schema.`COLUMNS` where COLUMN_KEY ='PRI'"
val statement = conn.createStatement()
val res = statement.executeQuery(pri_sql)
var tables = List[(String,String,String)]()
// 处理所有的database
while (res.next()) {
tables =((res.getString("TABLE_SCHEMA").toLowerCase,
res.getString("TABLE_SCHEMA").toLowerCase+"."+res.getString("TABLE_NAME").toLowerCase,
res.getString("COLUMN_NAME")))::tables
}
res.close()
statement.close()
conn.close();
tables.map(it=>{(it._2,it._3)}).toMap[String,String]
}
/**
* 写出hive视图 语句
* 生成对应的hive去重 语句 写入到hdfs
* 先排序 然后过滤掉删除的数据
* select * from (
* * * SELECT *,row_number() over(partition by pri order by in_hive_time desc) as od from xxxx
* * * ) t where t.od =1 and t.in_hive_type<>0
*
* @param spark
* @param tableName
* @param properties
*/
def writeCreateHiveView(spark: SparkSession,dataFrame: DataFrame,tableName:String,properties:Properties,pri_map: Map[String, String],server_id:String)={
// 查询出所有表的主键信息
// val fields = getTableFields(dataFrame).map(it=>it._1).mkString(",")
var create_viewSql: String =
s"""
|create view IF NOT EXISTS ${properties.getProperty("hive.viewDatabase")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)} as
| select *
| from
| (
| SELECT *,row_number() over(partition by ${pri_map.getOrElse(tableName, "erro")} order by in_hive_time desc) as rn from ${properties.getProperty("hive.database")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)}
| ) t where t.rn =1 and t.in_hive_type <> 0;
|""".stripMargin
var path = new Path(s"${properties.getProperty("hive.create_view_file")}/mysql_hive_create_view_sql_$server_id")
if(pri_map.get(tableName).isEmpty){
create_viewSql=
s"""
|create view IF NOT EXISTS ${properties.getProperty("hive.viewDatabase")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)} as
| select *
| from
| (
| SELECT *,row_number() over(partition by ${pri_map.getOrElse(tableName,"erro")} order by in_hive_time desc) as rn from ${properties.getProperty("hive.database")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)}
| ) t where t.rn =1 and t.in_hive_type <> 0;
|""".stripMargin
path = new Path(s"${properties.getProperty("hive.create_view_file")}/mysql_hive_create_view_sql_${server_id}_error")
}
writeToHdfs(spark,path,create_viewSql,tableName)
}
/**
* 根据df 获取对应df 获取表的字段的类型信息
* @param dataFrame
* @return
*/
def getTableFields(dataFrame: DataFrame):List[(String,String)] ={
val schema: StructType = dataFrame.drop("in_hive_path").schema
var lists = List[(String, String)]()
for (elem <- schema) {
val dataType = elem.dataType
val field_Type = dataType match {
case TimestampType => "BIGINT"
case IntegerType =>"INT"
case it:DecimalType=>s"DECIMAL(${it.precision},${it.scale})"
case DoubleType=>"DECIMAL(15,6)"
case FloatType =>"DECIMAL(15,2)"
case _ =>"STRING"
}
// println((elem.name,elem.dataType,elem.getComment()))
lists =(elem.name, field_Type)::lists
}
lists.reverse
}
/**
* 按照数据拼接对应的hive 建表语句
* @param spark
* @param dataFrame
*/
def writeCreateHiveTableSql(spark: SparkSession,dataFrame: DataFrame,tableName:String,hdfsLocation:String,properties:Properties,server_id:String): Unit ={
dataFrame.printSchema()
// val columns = dataFrame.drop("in_hive_path").columns
val list = getTableFields(dataFrame)
val stringBuffer =new StringBuffer(s"CREATE EXTERNAL TABLE IF NOT EXISTS ${properties.getProperty("hive.database")}.${tableName.split("\\.")(0)}_${tableName.split("\\.")(1)}(").append("\n")
var columns_Str = List[String]()
list.foreach(column=>
columns_Str = s"${column._1} ${column._2}"::columns_Str
)
val str: String = columns_Str.reverse.mkString(",\n")
stringBuffer.append(str).append("\n")
stringBuffer.append(")").append("\n")
stringBuffer.append("ROW FORMAT serde 'org.apache.hive.hcatalog.data.JsonSerDe'").append("\n")
.append(s"STORED AS TEXTFILE LOCATION '$hdfsLocation';").append("\n")
val hiveCreateTable = stringBuffer.toString
// 写入 对应的hdfs 目录
val path = new Path(s"${properties.getProperty("hive.create_table_file")}/mysql_hive_create_table_sql_$server_id")
writeToHdfs(spark,path,hiveCreateTable,tableName)
}
/**
* 根据 配置文件里的信息读取对应黑名单配置信息表
* CREATE TABLE `black_binlog_config` (
* `id` int(8) NOT NULL AUTO_INCREMENT COMMENT '主键',
* `server_id` varchar(20) NOT NULL COMMENT 'mysql服务器标识',
* `black_databases` varchar(2000) DEFAULT NULL COMMENT '黑名单-数据库',
* `black_tables` varchar(4000) DEFAULT NULL COMMENT '黑名单-表',
* `create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
* PRIMARY KEY (`id`)
* ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COMMENT='flink-binlog黑名单配置表'
*
* databases,tables
*
* @param spark
* @param properties
* @return
*/
def getFilterDataBaseAndTable(spark: SparkSession,properties:Properties):Map[String,(String,String)] ={
import org.apache.spark.sql.functions._
import spark.implicits._
spark.read.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", properties.getProperty("config.url"))
.option("dbtable", properties.getProperty("config.table"))
.option("user", properties.getProperty("config.username"))
.option("password", properties.getProperty("config.password"))
.load()
.select("server_id", "black_databases", "black_tables", "create_time")
.withColumn("rn", row_number().over(Window.partitionBy("server_id").orderBy(desc("create_time"))))
.where("rn=1")
.select("server_id", "black_databases", "black_tables")
.as[(String, String, String)].
collect().toList.map(it=>{(it._1,(it._2,it._3))}).toMap[String,(String,String)]
}
/**
* 读取配置文件获取指定的实例信息
* @return
*/
def getMysqlMessage(properties:Properties):List[(String,String,String,String)]={
val keysSet: util.Enumeration[_] = properties.propertyNames()
var list = List[(String, String, String,String)]()
while (keysSet.hasMoreElements) {
val key = keysSet.nextElement()
if(key.toString.contains("mysql.info")){
val str = properties.getProperty(key.toString)
if(!StringUtils.isEmpty(str)){
list =(str.split(",")(0),str.split(",")(1),str.split(",")(2),str.split(",")(3))::list
}
}
}
list
}
/**
* 根据数据库实例 获取 对应的数据库 和对应的 表
* @param url
* @param userName
* @param password
* @return
*/
def getDataBaseAndTable(url:String,userName:String,password:String):List[MysqlTableInfo] ={
val conn=getMysqlConnection(url,userName,password)
val dataBaseSql ="select TABLE_SCHEMA,TABLE_NAME,TABLE_ROWS,DATA_LENGTH from information_schema.tables"
val statement = conn.createStatement()
val res = statement.executeQuery(dataBaseSql)
var tables = List[MysqlTableInfo]()
// 处理所有的database
while (res.next()) {
tables = MysqlTableInfo(res.getString("TABLE_SCHEMA").toLowerCase,
res.getString("TABLE_SCHEMA").toLowerCase+"."+res.getString("TABLE_NAME").toLowerCase,
res.getLong("TABLE_ROWS"),
res.getLong("DATA_LENGTH"))::tables
}
res.close()
statement.close()
conn.close();
tables
}
/**
* 获取mysql 的连接
* @param url
* @param userName
* @param password
* @return
*/
def getMysqlConnection(url:String,userName:String,password:String)={
Class.forName("com.mysql.jdbc.Driver")
DriverManager.getConnection(url, userName, password)
}
/**
* 向hdfs 追加写文件
* @param spark
* @param path
* @param data
*/
def writeToHdfs(spark: SparkSession,path: Path,data:String,tableName:String) ={
val configuration = spark.sparkContext.hadoopConfiguration
val fs = FileSystem.get(configuration)
var dataOutPutStream: FSDataOutputStream = null;
val isWindows =System.getProperties().getProperty("os.name").toUpperCase().indexOf("WINDOWS")>0
if(isWindows){
dataOutPutStream = fs.create(new Path(path.toString+"/"+tableName), false);
}else{
if(fs.exists(path)){
dataOutPutStream =fs.append(path)
}else{
dataOutPutStream = fs.create(path, false);
}
}
dataOutPutStream.write(data.getBytes("utf-8"))
dataOutPutStream.flush()
dataOutPutStream.close()
}
/**
* 按整个实例查询出整个数据库中字段类型是json的数据
* @param url
* @param username
* @param password
* @return
*/
def queryMysqlTableJsonFields(url:String,username:String,password:String)={
val conn=getMysqlConnection(url,username,password)
val pri_sql ="SELECT TABLE_SCHEMA,TABLE_NAME,GROUP_CONCAT(COLUMN_NAME) as COLUMN_NAMES from information_schema.`COLUMNS` where DATA_TYPE ='JSON' group by TABLE_SCHEMA,TABLE_NAME"
val statement = conn.createStatement()
val res = statement.executeQuery(pri_sql)
var tables = List[(String,String,String)]()
// 处理所有的database
while (res.next()) {
tables =((res.getString("TABLE_SCHEMA").toLowerCase,
res.getString("TABLE_SCHEMA").toLowerCase+"."+res.getString("TABLE_NAME").toLowerCase,
res.getString("COLUMN_NAMES")))::tables
}
res.close()
statement.close()
conn.close();
tables.map(it=>{(it._2,it._3)}).toMap[String,String]
}
}
十三 根据DataFrame 匹配建表语句
/**
* 根据df 获取对应df 获取表的字段的类型信息
* @param dataFrame
* @return
*/
def getTableFields(dataFrame: DataFrame):List[(String,String)] ={
val schema: StructType = dataFrame.drop("in_hive_path").schema
var lists = List[(String, String)]()
for (elem <- schema) {
val dataType = elem.dataType
val field_Type = dataType match {
case TimestampType => "bigInt"
case IntegerType =>"Int"
case it:DecimalType=>s"decimal(${it.precision},${it.scale})"
case DoubleType=>"decimal(15,6)"
case FloatType =>"decimal(15,2)"
case _ =>"String"
}
// println((elem.name,elem.dataType,elem.getComment()))
lists =(elem.name, field_Type)::lists
}
lists.reverse
}
十四 查询mysql 整个实例所有表的json字段
/**
* 按整个实例查询出整个数据库中字段类型是json的数据
* @param url
* @param username
* @param password
* @return
*/
def queryMysqlTableJsonFields(url:String,username:String,password:String)={
val conn=getMysqlConnection(url,username,password)
val pri_sql ="SELECT TABLE_SCHEMA,TABLE_NAME,GROUP_CONCAT(COLUMN_NAME) as COLUMN_NAMES from information_schema.`COLUMNS` where DATA_TYPE ='JSON' group by TABLE_SCHEMA,TABLE_NAME"
val statement = conn.createStatement()
val res = statement.executeQuery(pri_sql)
var tables = List[(String,String,String)]()
// 处理所有的database
while (res.next()) {
tables =((res.getString("TABLE_SCHEMA").toLowerCase,
res.getString("TABLE_SCHEMA").toLowerCase+"."+res.getString("TABLE_NAME").toLowerCase,
res.getString("COLUMN_NAMES")))::tables
}
res.close()
statement.close()
conn.close();
tables.map(it=>{(it._2,it._3)}).toMap[String,String]
}
十五 提交脚本
spark-submit \
--class com.xx.spark.entrance.ReadMysqlApplication \
--deploy-mode client \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 2 \
--num-executors 4 \
--master yarn \
--jars hdfs:///user/admin/mysql_syn/mysql-connector-java-5.1.43.jar \
hdfs:///user/admin/mysql_syn/xx-2.1.jar hdfs:///user/admin/mysql_syn/xx.properties hdfs://10.83.0.47:8020
十六 运行结果截图

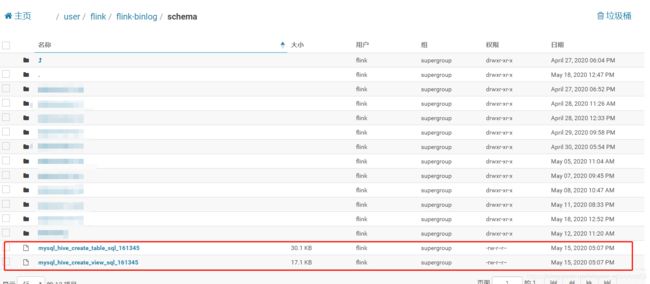

总结
1 mysql中数据类型为json 的数据,直接使用sparksql 抽过来会变成string 类型,再使用format(“json”)写出的json 数据会带有"{ }" 包裹json字符串,导致hive的serde无法成功映射,解决办法
a 拉去mysql 对应表的json 字段信息,再写出数据的时候自己将json 字段转换为Json对象,再转为JSon字符串 使用text方式写出
b 拉去mysql 中数据的时候需要注意,不能直接使用记录数去决定分区的个数,因为一些json 数据的表,记录条数很少,但是整个表很大。