Yolo-6D(Real-Time Seamless Single Shot 6D Object Pose Prediction)理解
文章目录
- 本文创新点
- 作者Ideal来源
- 作者方法
- 核心思想
- 算法流程
- 点的信息
- 网络结构
- 3D框置信度计算
- 3D框Anchor的选择
- 九个关键点的计算
- PnP
- loss计算
- 实验
- 性能
- 参考文献
文中所有灰色引用部分都是在阅读文章时的思考,阅读时可直接跳过灰色部分,不会影响内容
本文创新点
- 从一个RGB图像预测他的6D位姿估计,不需要多阶段也不需要检验多种假设,也不需要精确的目标纹理模型,精准度足够不需要后期处理。
- 提出了一个新的CNN结构,直接预测目标的射影顶点的2D图像位置,然后用PnP算法估计目标的3D位姿。
相比之下其他的算法:
- 运行速度随着检测物体的数量直线上升,而作者的方法运行时间和目标数量关系不大,保持稳定。
- 现存的一些算法都需要微调他们的结果,这样就导致了每个物体检测都超时了,作者不需要微调速度更快
但是:
作者的方法需要先验3D模型知识
作者Ideal来源
ta mu gong, o mu zi a
作者方法
没什么很新的方法,就把方法和训练写一起了
核心思想
用网络预测3D包围盒角落的射影的2D位置,这涉及到预测比2D包围盒回归更多的2D点。得到了2D的角落射影,再加上先验3D点信息,直接用PnP算法就是能求出6D位姿
Deep3Dbox只用了四个点,难道是预测的物体的中心点?再加上一些看似立体的、Deep3Dbox并没有预测的点?
算法流程
点的信息
用9个控制点参数化每个目标的3D模型,好处:
这几个参数能用在任意形状和拓扑的刚体上,九个点展开到2D图像很方便,而且对许多人造物体有语义意义。
咋还用这么多?八个不够吗,中心点有啥用
答:也不一定非要用9点法表示,也可以用其他方法
在这些点里面,选择紧凑的3D包围盒的八个角点来拟合3D模型。
第九个点当形心
有了形心是不是比较好判断方向?
网络结构
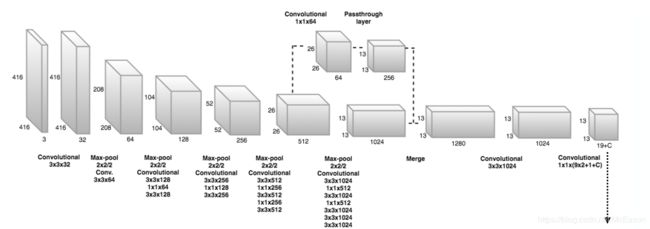
用全卷积加工输入的2D图片,如Figure 1 (a)
F i g u r e 1 ( a ) Figure\ 1\ (a) Figure 1 (a)
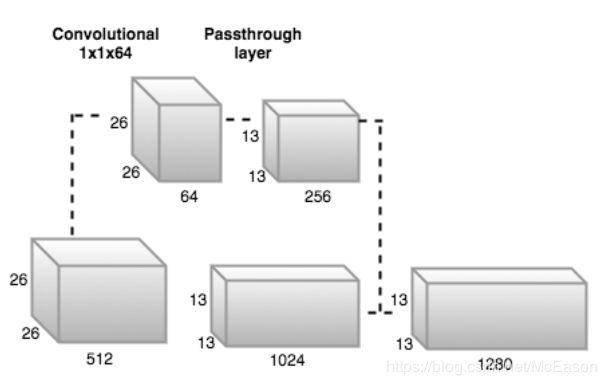
用的是v2的yolo,共使用23个卷积层和5个最大池化层,选择 S = 13 S=13 S=13。还允许网络高层添加转移层来使用fine-grained特征。从维度是 26 × 26 × 512 26\times 26 \times 512 26×26×512的层提取出了特征,卷积成 13 × 13 × 256 13 \times 13 \times 256 13×13×256后和 13 × 13 × 1024 13\times 13 \times 1024 13×13×1024特征图结合。
为了获得更精细的特征?很像残差,这样对预测小尺度物体有好处,是为了这个吗?
当网络的下采样用32因子的时候,就用32的倍数的分辨率作为图象输入 { 320 , 352 , . . . , 608 } \{320,352,...,608\} {320,352,...,608},以此来增强对不同size物体的鲁棒性。
然后将图片分到2D规则网格 S × S S\times S S×S中去。
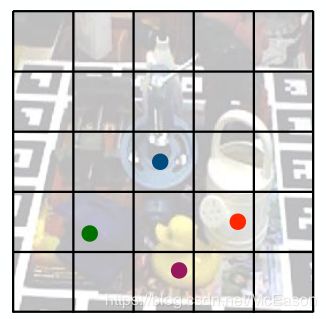
F i g u r e 1 ( c ) Figure\ 1\ (c) Figure 1 (c)
上图的每个cell中都包含着一个( 9 × 2 + 1 + C 9\times 2 + 1 + C 9×2+1+C)的特征向量,存放的是9个点( 18 18 18)、目标的分类概率( C C C)和整体的置信度( 1 1 1),如下图所示。
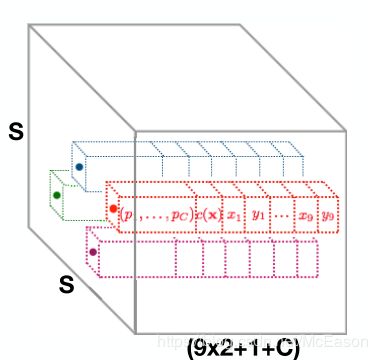
F i g u r e 1 ( e ) Figure\ 1\ (e) Figure 1 (e)
3D框置信度计算
在2D框的预测中,会根据object_confidence分数和IoU来进行筛选,在3D框的预测中,也需要这一步操作,但是3D的IoU求起来很麻烦,所以作者就用下面的公式计算置信度:
yolo v2的 confidence=P(object) *IOU
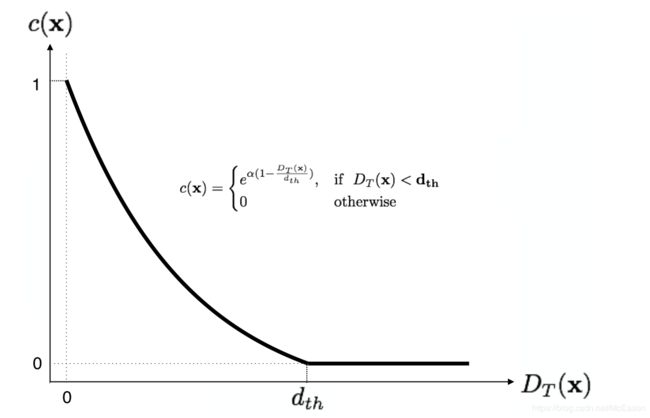
这 个 图 中 的 公 式 不 对 , 应 如 下 : 这个图中的公式不对,应如下: 这个图中的公式不对,应如下:
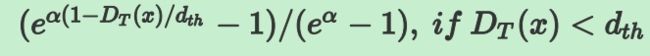
c ( x ) c(x) c(x)是置信度函数值
D T ( x ) D_T(x) DT(x)是预测的2D点到真实点之间的欧式距离
所以是全部的点吗?可能是
答:就是全部的点,然后计算平均值
3D框Anchor的选择
以上是单目标检测,多目标的话就要引入Anchor的概念:
当物体间靠的很近或者相互遮挡时,他们的中心可能在一个cell中,这种情况,作者给每个cell提供五个anchor,每个anchor都会有一套数据,然后训练的时候选择2D框和真实框IoU最大的那个。
IoU大于0.5就认为检测是正确的。
这个2D框是指yolov2预测出来的?不应该啊,预测的是九个点,还是说把这九个点平面化了,然后和真实的
所以,就算有靠的很近的,也不会全部标出来,还是选择当前IoU最大的一个显示出来,这时网络的输出就变成了 13 × 13 × ( 9 × 2 + 1 + C ) × 5 13\times 13\times (9\times 2 + 1 +C)\times 5 13×13×(9×2+1+C)×5
九个关键点的计算
在9对预测的2D坐标点中,形心点是相对于cell左上角的偏移 ( c x , c y ) (c_x,c_y) (cx,cy),将偏移量限制在 ( 0 , 1 ) (0,1) (0,1)中,其他的角点就不管了 ,都不会在cell中,这将迫使网络首先为对象找到近似的cell位置,然后改进它的八个角位置。
根据这句话就应该知道:其他的八个点不需要在cell中,所以也就不需要sigmoid操作,知道了这一点下面就不应该不理解了
中心点的计算:
g x = f ( x ) + c x g y = f ( y ) + c y g_x = f(x) + c_x\\ g_y = f(y) + c_y gx=f(x)+cxgy=f(y)+cy
f ( ) f() f()在形心的情况下是一个1D sigmoid 函数,在八个角点的情况下的单元函数
这是什么神奇算法?是八个点的sigmoid加在一块就是中心点了?
答:不是的,这里理解不好是翻译问题:
where f(·) is chosen to be a 1D sigmoid function in case of the centroid and the identity function in case of the eight corner points.
f ( ) f() f()在形心的情况下是一个1D sigmoid 函数,在八个角点的情况下的单元函数
特殊情况:
对于那大的物体,中心点可能在两个cell的交接处(点还有半径??offset变成了1??好巧啊)
这种情况怎么处理呢?分别看两个的分数?还是说两个cell都不会给出分数?应该都会给,选最大的一个
答:找有最大置信度的cell周围 3 × 3 3\times 3 3×3个cell,对每个cell的角点做加权平均,权重是他们的confidence 分数,找出加权分数最大的?这么说每个角点都有个分数?不应该啊
PnP
最后,有了预测的3D包围盒的投影点和真实的3D模型包围盒点,用PnP算法就能估计出位姿
这还得提前知道3D模型才行,好像挺难拜托预知3D模型的限制
loss计算
整个训练网络的loss:
L = λ p t L p t + λ c o n f L c o n f + λ i d L i d L = \lambda_{pt}L_{pt} + \lambda_{conf}L_{conf}+\lambda_{id}L_{id} L=λptLpt+λconfLconf+λidLid
对于坐标和置信度损失用的 L 2 L_2 L2损失函数,分类用的交叉熵。
一个提高模型稳定性的技巧:给confidence减权,当cell中有物体的时候把 λ c o n f \lambda_{conf} λconf设置成5.0,当cell中没物体的时候 λ c o n f \lambda_{conf} λconf设置成0.
实验
backbone:
用的是ImageNet初始网络来训练,一开始把 λ c o n f \lambda_{conf} λconf设置成了0来进行预训练,然后,根据有无物体设置 λ c o n f \lambda_{conf} λconf。
为什么预训练要把置信度设置为0?
答:一开始的置信度预测效果是很差的,连坐标都预测不准也就不用谈什么置信度了。当坐标预测稍微准了点的时候,再开始置信度的训练。
参数设置:
将指数的 α \alpha α参数设置成了2,距离阈值设置成了30像素。
学习率是0.001,每100个epoch除以10.
数据增强:
为防止过拟合,随机选择色调、饱和度、曝光来做1.2倍的处理。还随机平移和缩放20%。
度量:
在使用重投影误差时,我们认为当使用重投影误差的物体3D网格顶点的2D投影与地面真实位姿之间的平均距离小于5像素时,姿态估计是正确的
现在看好像不重要,怎么度量直接看比赛的度量方法就行。
训练数据操作:
作者使用训练集提供的mask标注,将图片中的物体抠出来,然后给安上别的背景图片
这样是不是更好训练,更容易识别,但是鲁棒性不会降低吗?还是说换了背景,关联性更小,鲁棒性更高,防止神经网络学习到了背景和物体之间的联系?
性能
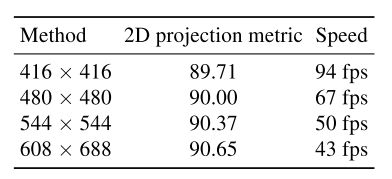
不 同 s i z e 的 输 入 不同size的输入 不同size的输入
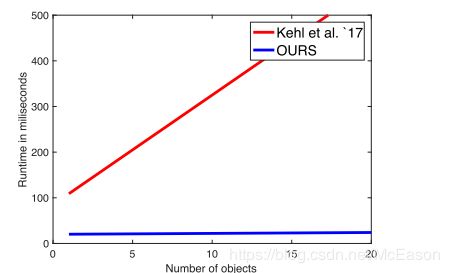
速 度 与 目 标 数 量 的 关 系 速度与目标数量的关系 速度与目标数量的关系

训 练 结 果 展 示 训练结果展示 训练结果展示
参考文献
知乎文章