英伟达小样本换脸AI:金毛一秒变二哈,还有在线试玩


【导读】发明“草图秒变风景照”图像生成器GauGAN的英伟达研究团队,最近推出更有趣“宠物换脸”GANimals。只需上传一张照片,金毛能变成哈士奇、雪豹、老虎……这是什么黑科技
发明“草图秒变风景照”图像生成器GauGAN的英伟达研究团队,最近又推出一个有趣的项目:GANimals——宠物换脸。
GaoGAN曾经在互联网上引起轰动,它能将简单绘制的几根线条的草图转换成接近照片写实的风景照,其逼真程度让人惊叹。
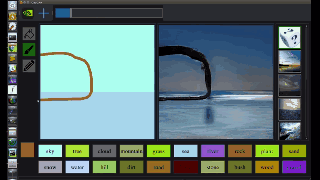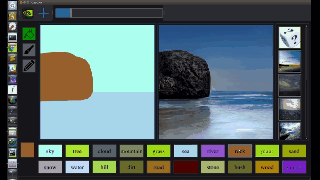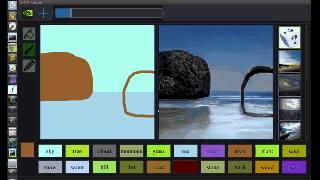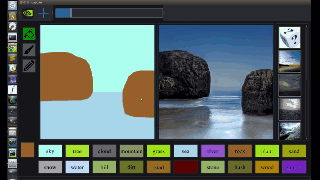
不过,GaoGAN仍然需要用户通过选择合适的笔刷和颜色来指出照片的哪些部分是水、树、山峰和其他地标。
但GANimals是完全自主的。你只需上传一张宠物的照片,它就会生成一系列其他逼真的照片。例如,输入一只金毛的照片,它会生成一系列其他品种狗狗,甚至其他类型的动物,神态、动作与输入一致。

金毛的“吐舌头、歪头”等表情被迁移到其他动物脸上
这项技术有望得到广泛应用。例如,电影制作者可能会拍摄狗狗表演绝技的视频,然后利用AI将它们的动作映射到,比如说,不太容易驾驭的老虎身上。
NVIDIA的研究人员利用GAN开发了一种AI技术,将宠物的表情和姿势转移到另一只动物中
该研究团队本周在首尔举行的国际计算机视觉大会(ICCV)上发表论文并报告了他们的工作,这是计算机视觉领域的三大顶级会议之一。
论文题为“Few-Shot Unsupervised Image-to-Image Translation”,描述了研究人员称为“FUNIT”的模型,这是一种小样本(Few-Shot)、无监督的图像到图像的转换算法,适用于之前未见过的目标类,这些目标类在测试时仅通过少量示例图像来指定。
“大多数基于GAN的图像翻译网络被训练来解决单个任务。例如,把马变成斑马,”该研究的主要作者Ming-Yu Liu说。
“在本研究中,我们训练一个网络来共同解决多个转换任务,其中每个任务都是通过利用目标动物的少量示例图像来将一个随机源动物转换成一个随机目标动物,”Liu解释说。“通过练习解决不同的转换任务,最终网络学会将已知的动物转换成未知的动物。”
研究人员还开放了一个在线测试链接,简单三步给你的萌宠“换脸”,快来玩吧~
第一步:上传一张宠物的照片

第二步:在脸的部位画一个框

第三步:点击“Translate”按钮,静候片刻即可大功告成!

地址:
https://nvlabs.github.io/FUNIT/ganimal.html
点击“进入空间站”分享你的萌宠换脸
在此工作之前,用于图像转换的网络模型必须使用大量目标动物的图像进行训练。现在,只需要一张照片就能成功,部分原因是训练函数包括许多不同的图像转换任务,团队将这些任务添加到GAN的过程中。
研究团队的目标是找到将类似人的想象力编码到神经网络的方法,这项工作是朝该目标走的下一步。Liu说:“这是我们通过解决各种新问题而在技术和社会上取得进步的方式。”
他们希望进一步扩展FUNIT工具,使其包含更多分辨率更高的图像。他们已经在用花和食物的图片进行了测试。

FUNIT:一图换万物,非常有趣!
FUNIT的解释
所提出的FUNIT框架旨在通过利用在测试时可用的几个目标类图像,将源类的图像映射到目标类的类似图像。
为了训练FUNIT,研究人员使用来自一组对象类(例如各种动物物种的图像)中的图像,称为源类(source classes)。同时,不假设任何两个类之间存在配对的图像(即,不同物种的任何两个动物都不会是完全相同的姿势)。
研究使用源类里的图像来训练一个multi-class无监督图像到图像转换模型。
在测试过程中,研究人员从一个称为目标类(target class)的新对象类中提供少量几张图像。模型必须利用少量的目标图像来将源类里的任何图像转换为目标类里的类似图像。

图1
训练。训练集由各种对象类(源类)的图像组成。我们训练了一个模型在这些源对象类之间转换图像。
部署。我们向训练模型显示极少量目标类里的图像,这就足以将源类的图像转换为目标类的类似图像了,即使模型在训练期间从未见过目标类的任何图像。
需要注意的是,FUNIT生成器有两个输入:1)一个内容图像;2)一组目标类图像。它的目的是生成与目标类图像相似的输入图像的转换。
该框架由一个有条件的图像发生器G和一个多任务对抗性鉴别器D组成。
与现有无监督image-to-image translation框架中有条件的图像生成器不同,它们是将一张图像作为输入,而这里的生成器G需要同时将一张内容图像x和一组K类图像{y1, ..., yK}作为输入,生成输出图像x¯,公式如下:
实验结果:姿态和种类一起转换,超越基准模型
主要结果
如表1所示,FUNIT框架在Animal Faces和North American Birds两个数据集的所有性能指标都优于用于小样本无监督图像到图像转换任务的基线模型。
FUNIT在Animal Faces数据集的1-shot和5-shot设置上分别达到82.36和96.05 的Top-5 测试精度,以及在North American Birds数据集上分别达到60.19和75.75的Top-5 测试精度。
这些指标都明显优于相应的基准模型。
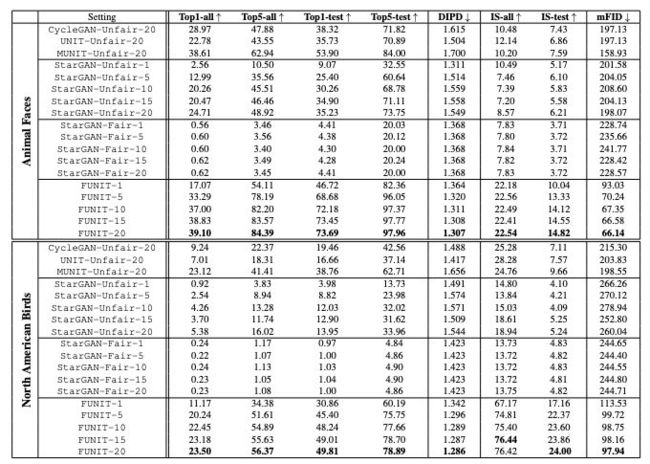
表1:
FUNIT与基线模型的性能比较。
↑表示数值越大越好,↓表示越小越好。
在图2中,研究人员对FUNIT-5计算的few-shot translation的结果进行了可视化。




图2:
无监督图像-图像转换结果的可视化。
计算结果采用FUNIT-5模型。
从上到下分别是来自动物面孔、鸟、花和食物数据集的结果。每个示例随机展示了2张目标类中的图像,输入内容图像x,以及转换后的输出图像x¯。
结果表明,模型能够成功地将源类的图像转换为新的类中的相似图像。对象在输入内容图像x和相应输出图像x¯中的姿态基本保持不变。输出图像也非常逼真,类似于目标类中的图像。
图3提供FUNIT与基线模型的结果比较。可以看到,FUNIT生成了高质量的图像转换输出。

图3:
小样本图像到图像转换效果的比较。
从左到右的列分别是输入内容图像x,两个输入目标类图像y1,y2,来自不公平的StarGAN基线的转换结果,来自公平的StarGAN基线的转换结果,以及来自FUNIT框架的结果。
参考链接:
https://blogs.nvidia.com/blog/2019/10/27/ai-gans-pets-ganimals/
论文和GitHub:
https://arxiv.org/pdf/1905.01723.pdf
https://nvlabs.github.io/FUNIT/petswap.html
https://github.com/NVlabs/FUNIT

