用Python在某乎爬取了5W+张表情包,问一句:斗图谁与争锋?
平时聊天的时候输入法都有便捷表情包通道,但感觉数量还是太少,并且不够逗比不够贱啊!不能满足经常斗图的需求,于是我决定从无所不有的互联网中挖掘表情包资源。

这次的爬取目标是人均年薪百万的某乎,里面有关表情包的问答,几乎每个回答都给出了大量的表情包,来自五湖四海的网友在某乎以表情包会友,那我就来把你们发的全部都收集起来~
首先我们先把所有回答展开,查看全部回答。打开开发者工具,找到回答所在页面,将Requests Headers里的内容全部拷贝到咱们自己的Headers中。利用 requests 爬取该页面。
params 中的 offset 根据页面的更改更改其值,每翻一页,offset 就加5 。其他的参数不发生改变。
接着观察网页源代码,我们可以清楚的看到每一张图片的链接就放在 data-actualsrc 之后。
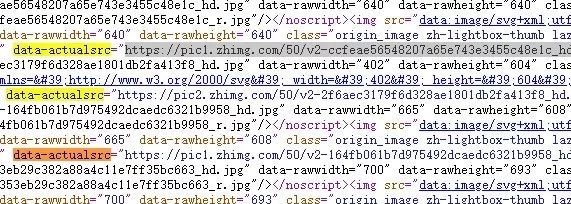
而这个链接的获取可以使用正则表达式将其从网页源代码中获取。
pic_urls=re.findall(r'data-actualsrc="(.*?.(gif|jpg|png))',content)
根据这些图片的url链接,我们只要再构造requests请求,便可以把所有图片下载下来。一个很直观的想法就是先访问源网页,用一个列表保存所有的图片url,然后遍历这个列表,逐个访问并下载内容。
这样操作的话消耗的内存比较大,并且下载图片的速度较慢,因此我采取了另外一种策略,一个简单的 Requests + Redis 的分布式爬虫。

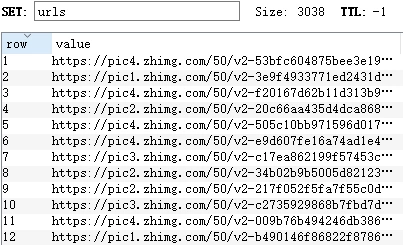
获取图片URL
按照之前所说的那样,爬取获得URL链接,不同的是,我们将其存储在Redis中把所有 url 添加到同一个集合中。
在学习过程中有什么不懂得可以加我的
python学习扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
def get_urls(self,offset,urls):
params={
'include': 'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_labeled,is_recognized,paid_info,paid_info_content;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics',
'limit': 5,
'offset': offset,
'platform': 'desktop',
'sort_by': 'default'
}
r=requests.get(self.url,headers=self.headers,params=params)
data=r.json()['data']
for i in data:
content=i['content']
pic_urls=re.findall(r'data-actualsrc="(.*?.(gif|jpg|png))',content)
for j in range(len(pic_urls)):
self.r.sadd("urls",pic_urls[j][0])
图片下载
新建一个py文件用于下载图片,因为链接的获取速度比图片下载速度快不少,因此在图片下载这一环中采用了多线程处理 requests 请求。
在学习过程中有什么不懂得可以加我的
python学习扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
def download(self):
if "urls" in self.r.keys():
while True:
try:
url=self.r.spop("urls")
r=requests.get(url,headers=self.headers)
with open(img_path+os.path.sep+'{}{}'.format(self.count,url[-4:]),'wb') as f:
f.write(r.content)
print("已经成功下载{}张表情包!".format(self.count))
self.count+=1
except:
if "urls" not in self.r.keys():
print("表情包已全部下载完成")
break
else:
print("{}请求发送失败!".format(url))
continue
else:
self.download(self)
两个程序同时运行,一边获取url存入Redis, 另一边提取url 下载图片。大大加快了下载速度,并且减少了内存的使用。
成果展示
一共爬取了5W+张表情包,包含骚骚的gif动图。哈哈!斗胆问一句:斗图谁与争锋?

各种源代码教程放在我们的学习圈!想学习Python的小伙伴都可以来取经!