规则引擎概述及选型
文章目录
- 一、规则引擎概述:
- 规则引擎的起源:
- 规则引擎的相关构件:
- ⑴信息元(Information Unit)
- ⑵信息服务(Information Services)
- ⑶规则集(Rule Set)
- ⑷队列管理器(Queue Manager)
- 规则引擎的工作机制:
- Java规则引擎API(JSR-94):
- ⑴规则管理API:
- ⑵运行时客户API:
- Java规则引擎API安全问题:
- 异常与日志:
- 规则引擎的优势:
- ①声明式编程。
- ②逻辑与数据分离。
- ③速度及可测量性。
- ④知识集中化。
- ⑤工具集成。
- ⑥解释机制。
- ⑦易懂的规则。
- 规则引擎的应用场景:
- 规则引擎的使用注意:
- 二、规则引擎选型比较:
- 常用规则引擎:
- ①Drools:
- 特性:
- ②Ilog JRules:
- 主要组件:
- ③Easy Rules:
- 特性:
- ④Jess:
- ⑤Visual Rules:
- ⑥Aviator:
一、规则引擎概述:
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。
规则引擎具体执行可以分为接受数据输入,解释业务规则,根据业务规则做出业务决策几个过程。
使用规则引擎可以把复杂、冗余的业务规则同整个支撑系统分离开,做到架构的可复用移植。
规则引擎通常允许您在不重新启动系统或部署新的可执行代码的情况下更改规则。规则引擎不是一个新的东西的魔法盒,它旨在成为一个提供更高级别抽象的工具,以便您可以更少地关注开发细节。
Rules engines are not really intended to handle workflow or process executions nor are workflow engines or process management tools designed to do rules.
规则引擎的起源:
Java规则引擎起源于基于规则的专家系统(RBES),而基于规则的专家系统又是专家系统的其中一个分支。专家系统属于人工智能的范畴,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。专家系统有很多分类:神经网络、基于案例推理和基于规则系统等。
RBES包括三部分:Rule Base(knowledge base)、Working Memory(fact base)和Inference Engine(推理引擎)。它们的结构如下所示:
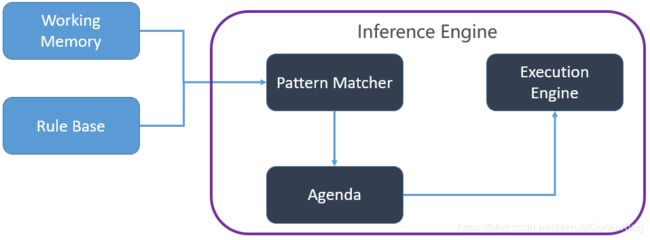
推理引擎包括三部分:模式匹配器(Pattern Matcher)、议程(Agenda)和执行引擎(Execution Engine)。推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。模式匹配器决定选择执行哪个规则,何时执行规则;议程管理模式匹配器挑选出来的规则的执行次序;执行引擎负责执行规则和其他动作。
和人类的思维相对应,推理引擎存在两者推理方式:演绎法(Forward- Chaining)和归纳法(Backward-Chaining)。演绎法从一个初始的事实出发,不断地应用规则得出结论(或执行指定的动作)。而归纳法则是根据假设,不断地寻找符合假设的事实。Rete算法是目前效率最高的一个Forward-Chaining推理算法,许多Java规则引擎都是基于 Rete算法来进行推理计算的。
推理引擎的推理步骤如下:
⑴将初始数据(fact)输入Working Memory。
⑵使用Pattern Matcher比较规则库(rule base)中的规则(rule)和数据(fact)。
⑶如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。
⑷解决冲突,将激活的规则按顺序放入Agenda。
⑸使用执行引擎执行Agenda中的规则。重复步骤⑵至⑸,直到执行完毕所有Agenda中的规则。
上述即是规则引擎的原始架构,Java规则引擎就是从这一原始架构演变而来的。
规则引擎的相关构件:
规则引擎是一种根据规则中包含的指定过滤条件,判断其能否匹配运行时刻的实时条件来执行规则中所规定的动作的引擎。与规则引擎相关的有四个基本概念,为更好地理解规则引擎的工作原理,下面将对这些概念进行逐一介绍。
⑴信息元(Information Unit)
信息元是规则引擎的基本建筑块,它是一个包含了特定事件的所有信息的对象。这些信息包括:消息、产生事件的应用程序标识、事件产生事件、信息元类型、相关规则集、通用方法、通用属性以及一些系统相关信息等等。
⑵信息服务(Information Services)
信息服务产生信息元对象。每个信息服务产生它自己类型相对应的信息元对象。即特定信息服务根据信息元所产生每个信息元对象有相同的格式,但可以有不同的属性和规则集。需要注意的是,在一台机器上可以运行许多不同的信息服务,还可以运行同一信息服务的不同实例。但无论如何,每个信息服务只产生它自己类型相对应的信息元。
⑶规则集(Rule Set)
顾名思义,规则集就是许多规则的集合。每条规则包含一个条件过滤器和多个动作。一个条件过滤器可以包含多个过滤条件。条件过滤器是多个布尔表达式的组合,其组合结果仍然是一个布尔类型的。在程序运行时,动作将会在条件过滤器值为真的情况下执行。除了一般的执行动作,还有三类比较特别的动作,它们分别是:放弃动作(Discard Action)、包含动作(Include Action)和使信息元对象内容持久化的动作。
⑷队列管理器(Queue Manager)
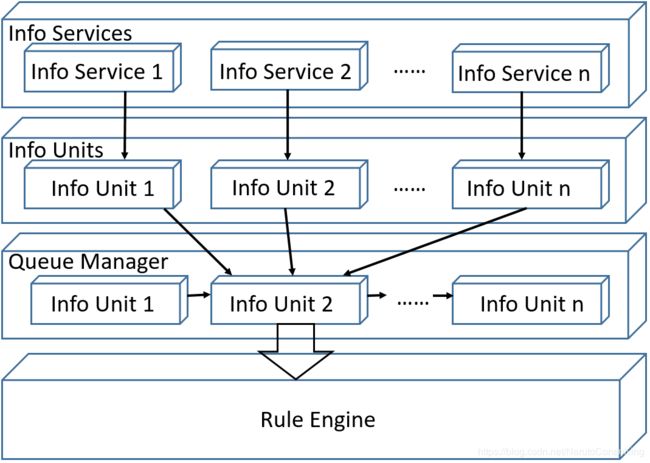
队列管理器用来管理来自不同信息服务的信息元对象的队列。
如下图所示,处理过程分为四个阶段进行:信息服务接受事件并将其转化为信息元,然后这些信息元被传给队列管理器,最后规则引擎接收这些信息元并应用它们自身携带的规则加以执行,直到队列管理器中不再有信息元。
规则引擎的工作机制:
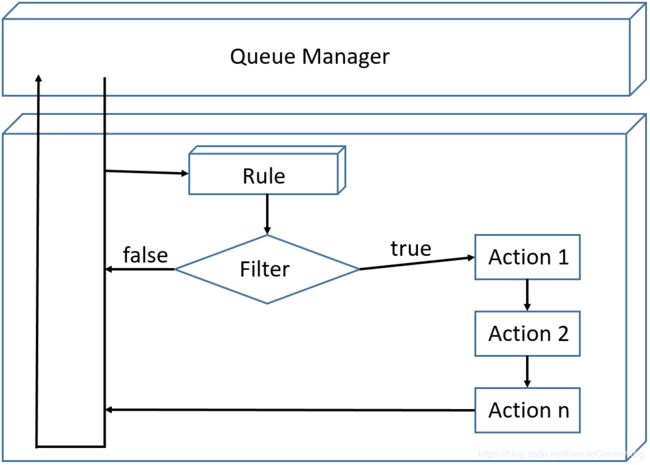
下面研究规则引擎的内部处理过程。如下图所示,规则引擎从队列管理器中依次接收信息元,然后依规则的定义顺序检查信息元所带规则集中的规则。规则引擎检查第一个规则并对其条件过滤器求值,如果值为假,所有与此规则相关的动作皆被忽略并继续执行下一条规则。如果第二条规则的过滤器值为真,所有与此规则相关的动作皆依定义顺序执行,执行完毕继续下一条规则。该信息元中的所有规则执行完毕后,信息元将被销毁,然后从队列管理器接收下一个信息元。在这个过程中并未考虑两个特殊动作:放弃动作(Discard Action)和包含动作(Include Action)。放弃动作如果被执行,将会跳过其所在信息元中接下来的所有规则,并销毁所在信息元,规则引擎继续接收队列管理器中的下一个信息元。包含动作其实就是动作中包含其它现存规则集的动作。包含动作如果被执行,规则引擎将暂停并进入被包含的规则集,执行完毕后,规则引擎还会返回原来暂停的地方继续执行。这一过程将递归进行。
Java规则引擎的工作机制与上述规则引擎机制十分类似,只不过对上述概念进行了重新包装组合。Java规则引擎对提交给引擎的Java数据对象进行检索,根据这些对象的当前属性值和它们之间的关系,从加载到引擎的规则集中发现符合条件的规则,创建这些规则的执行实例。这些实例将在引擎接到执行指令时、依照某种优先序依次执行。一般来讲,Java规则引擎内部由下面几个部分构成:工作内存(Working Memory)即工作区,用于存放被引擎引用的数据对象集合;规则执行队列,用于存放被激活的规则执行实例;静态规则区,用于存放所有被加载的业务规则,这些规则将按照某种数据结构组织,当工作区中的数据发生改变后,引擎需要迅速根据工作区中的对象现状,调整规则执行队列中的规则执行实例。Java规则引擎的结构示意图如下图所示。

当引擎执行时,会根据规则执行队列中的优先顺序逐条执行规则执行实例,由于规则的执行部分可能会改变工作区的数据对象,从而会使队列中的某些规则执行实例因为条件改变而失效,必须从队列中撤销,也可能会激活原来不满足条件的规则,生成新的规则执行实例进入队列。于是就产生了一种“动态”的规则执行链,形成规则的推理机制。这种规则的“链式”反应完全是由工作区中的数据驱动的。
任何一个规则引擎都需要很好地解决规则的推理机制和规则条件匹配的效率问题。规则条件匹配的效率决定了引擎的性能,引擎需要迅速测试工作区中的数据对象,从加载的规则集中发现符合条件的规则,生成规则执行实例。1982年美国卡耐基·梅隆大学的 Charles L. Forgy发明了一种叫Rete算法,很好地解决了这方面的问题。目前世界顶尖的商用业务规则引擎产品基本上都使用Rete算法。
Rete算法浅析
Java规则引擎API(JSR-94):
过去大部分的规则引擎开发并没有规范化,有其自有的API,这使得其与外部程序交互集成不够灵活。转而使用另外一种产品时往往意味需要重写应用程序逻辑和API调用,代价较大。为了使规则引擎技术标准化,Java社区制定了Java规则引擎API(JSR-94)规范。它为Java平台访问规则引擎定义了一些简单的API。
Java规则引擎API由javax.rules包定义,是访问规则引擎的标准企业级API。Java规则引擎API允许客户程序使用统一的方式和不同厂商的规则引擎产品交互,就像使用JDBC编写独立于厂商访问不同的数据库产品一样。Java规则引擎API包括创建和管理规则集合的机制,在Working Memory中添加,删除和修改对象的机制,以及初始化,重置和执行规则引擎的机制。
Java规则引擎API分为两个主要部分:规则管理API(the rules administration API)和运行时客户API(the Runtime client API)。
⑴规则管理API:
规则管理API在javax.rules.admin中定义,包括装载规则以及与规则对应的动作(执行集 execution sets)以及实例化规则引擎。规则可以从外部资源中装载,比如URI,Input streams,XML streams和readers等等。同时管理API提供了注册和取消注册执行集以及对执行集进行维护的机制。使用admin包定义规则有助于对客户访问运行规则进行控制管理,它通过在执行集上定义许可权使得未经授权的用户无法访问受控规则。
管理API使用类RuleServiceProvider来获得规则管理(RuleAdministrator)接口的实例。规则管理接口提供方法注册和取消注册执行集。规则管理器(RuleAdministrator)提供了本地和远程的RuleExecutionSetProvider。在前面已提及,RuleExecutionSetProvider负责创建规则执行集。规则执行集可以从如XML streams,input streams等来源中创建。这些数据来源及其内容经汇集和序列化后传送到远程的运行规则引擎的服务器上。大多数应用程序中,远程规则引擎或远程规则数据来源的情况并不多见。为了避免这些情况中的网络开销,API规定了可以从运行在同一JVM中规则库中读取数据的本地RuleExecutionSetProvider。
规则执行集接口除了拥有能够获得有关规则执行集的方法,还有能够检索在规则执行集中定义的所有规则对象。这使得客户能够知道规则集中的规则对象并且按照自己需要来使用它们。
⑵运行时客户API:
运行时API定义在javax.rules包中,为规则引擎用户运行规则获得结果提供了类和方法。运行时客户只能访问那些使用规则管理API注册过的规则,运行时API帮助用户获得规则对话并且在这个对话中执行规则。
运行时API提供了对厂商规则引擎API实现的类似于JDBC的访问方法。规则引擎厂商通过类RuleServiceProvider(类RuleServiceProvider提供了对具体规则引擎实现的运行时和管理API的访问)将其规则引擎实现提供给客户,并获得RuleServiceProvider唯一标识规则引擎的URL。
URL推荐标准用法是使用类似“com.mycompany.myrulesengine.rules.RuleServiceProvider”这样的Internet域名空间,这将有助于访问URL的唯一性。类RuleServiceProvider内部实现了规则管理和运行时访问所需的接口。所有的RuleServiceProvider要想被客户所访问都必须用RuleServiceProviderManager进行注册。注册方式类似于JDBC API的DriverManager和Driver。
运行时接口是运行时API的关键部分。运行时接口提供了用于创建规则会话(RuleSession)的方法,规则会话如前所述是用来运行规则的。运行时API同时也提供了访问在service provider注册过的所有规则执行集(RuleExecutionSets)。规则会话接口定义了客户使用的会话的类型,客户根据自己运行规则的方式可以选择使用有状态会话或者无状态会话。
无状态会话的工作方式就像一个无状态会话bean。客户可以发送单个输入对象或一列对象来获得输出对象。当客户需要一个与规则引擎间的专用会话时,有状态会话就很有用。输入的对象通过addObject() 方法可以加入到会话当中。同一个会话当中可以加入多个对象。对话中已有对象可以通过使用updateObject()方法得到更新。只要客户与规则引擎间的会话依然存在,会话中的对象就不会丢失。
RuleExecutionSetMetaData接口提供给客户让其查找规则执行集的元数据(metadata)。元数据通过规则会话接口(RuleSession Interface)提供给用户。
Java规则引擎API安全问题:
规则引擎API将管理API和运行时API加以分开,从而为这些包提供了较好粒度的安全控制。规则引擎API并没有提供明显的安全机制,它可以和J2EE规范中定义的标准安全API联合使用。安全可以由以下机制提供,如Java 认证和授权服务(JAAS),Java加密扩展(JCE),Java安全套接字扩展(JSSE),或者其它定制的安全API。使用JAAS可以定义规则执行集的许可权限,从而只有授权用户才能访问。
异常与日志:
规则引擎API定义了javax.rules.RuleException作为规则引擎异常层次的根类。所有其它异常都继承于这个根类。规则引擎中定义的异常都是受控制的异常(checked exceptions),所以捕获异常的任务就交给了规则引擎。规则引擎API没有提供明确的日志机制,但是它建议将Java Logging API用于规则引擎API。
规则引擎的优势:
①声明式编程。
规则引擎允许你描述做什么而不是如何去做。(规则比编码更容易阅读)
②逻辑与数据分离。
数据保存在系统对象中,逻辑保存在规则中。这根本性的打破了面向对象系统中将数据和逻辑耦合起来的局面。这样做的结果是,将来逻辑发生改变时更容易被维护,因为逻辑保存在规则中。这点在逻辑是跨领域或多领域中使用时尤其有用。通过将逻辑集中在一个或数个清晰的规则文件中,取代了之前分散在代码中的局面。
③速度及可测量性。
Rete算法、Leaps算法,以及由此衍生出来的Drools的Rete、Leaps算法,提供了对系统数据对象非常有效率的匹配。这些都是高效率尤其当你的数据是不完全的改变(规则引擎能够记得之前的匹配)。这些算法经过了大量实际考验的证明。
④知识集中化。
通过使用规则,将建立一个可执行的规则库。这意味着规则库代表着现实中的业务策略的唯一对应,理想情况下可读性高的规则还可以被当作文档使用。
⑤工具集成。
常见的IDE工具为规则的修改与管理、即时获得反馈、内容验证与修补提供了可靠支持。
⑥解释机制。
通过将规则引擎的决断与决断的原因一起记录下来,规则系统提供了很好的“解释机制”。
⑦易懂的规则。
通过建立对象模型以及DSL(域定义语言),你可以用接近自然语言的方式来编写规则。这让非技术人员与领域专家可以用他们自己的逻辑来理解规则(因为程序的复杂性已经被隐藏起来了) 。
规则引擎的应用场景:
相对于业务系统,规则引擎可以认为是一个独立于业务系统的模块,负责一些规则的计算等。
一般来说,规则引擎主要应用在下面的场景中:
1、风控模型配置,风控规则的设置。
2、用户积分等配置,如日常操作引起积分变化等。
3、简单的离线计算,各类数据量比较小的统计等。
规则引擎的使用注意:
规则引擎作为一个单独模块,有其自身的笨重与复杂,并不是所有相关业务系统都需要引入规则引擎。
1、必须建立一些数据模型。
2、考虑规则的冲突、优先级等。
3、控制规则的复杂度,以免给规则配置人员增加过多的学习成本。
由此可见,对于一些时间周期短、规则复杂且不常变更的项目,规则引擎并不十分适用。
二、规则引擎选型比较:
常用规则引擎:
目前的规则引擎系统中,使用较多的开源规则引擎是Drools,另外还有商用的规则管理系统BRMS是ILOG JRules。这两款规则引擎设计和实现都比较复杂,学习成本高,适用于大型应用系统。
①Drools:
Drools 是用 Java 语言编写的开放源码规则引擎,基于Apache协议,基于RETE算法,于2005年被JBoss收购。
特性:
1、简化系统架构,优化应用。
2、提高系统的可维护性和维护成本。
3、方便系统的整合。
4、减少编写“硬代码”业务规则的成本和风险。
②Ilog JRules:
IBM WebSphere ILOG JRules 是目前业界领先的业务规则管理平台。与传统的由 IT 人员用硬代码来维护规则的做法不同,ILOG JRules 让业务用户能够在不依赖或者有限依赖于 IT 人员的情况下,快速创建、修改、测试和部署业务规则,以满足经常变化的业务需求。ILOG JRules 提供了一整套的工具,帮助开发人员和业务人员进行规则的全生命周期管理。
主要组件:
1、Rule Studio(RS) 面向开发人员使用的开发环境,用于规则的建模和编写。
2、Rule Scenario Manager 规则测试工具。
3、Rule Team Server(RTS) 基于Web的管理环境,面向业务人员使用,用于规则发布、管理、存储。
4、Rule Execution Server(RES) 面向运维人员使用,用于规则执行、监控。
③Easy Rules:
Easy Rules 是一款 Java 规则引擎,它的诞生启发自有Martin Fowler 一篇名为 “Should I use a Rules Engine?” 文章。Easy Rules 提供了规则抽象来创建带有条件和操作的规则,以及运行一组规则来评估条件和执行操作的RulesEngine API。
特性:
1、轻量级框架和易于学习的API。
2、基于POJO的开发。
3、通过高效的抽象来定义业务规则并轻松应用它们。
4、支持创建复合规则。
5、使用表达式语言定义规则的能力。
④Jess:
Jess是Java平台上的规则引擎,它是CLIPS程序设计语言的超集,由Sandia国家实验室的Ernest Friedman-Hill开发。Jess提供适合自动化专家系统的逻辑编程,它常被称作“专家系统外壳”。近年来,智能代理系统也在相似的能力上发展起来。
⑤Visual Rules:
旗正VisualRules是由国家科技部和财政部的创新基金支持,专门针对国内规则引擎市场空白的情况,结合国内项目的特点而开发的一款业务规则管理系统(BRMS)产品。
⑥Aviator:
Aviator是一个高性能、轻量级的java语言实现的表达式求值引擎,主要用于各种表达式的动态求值。
详见:Aviator学习笔记