Python3数据分析入门实战_04 玩转Pandas 中
-
Apply进行数据预处理
案例 Demo# 数据读入 df = pd.read_csv('J:/csv/apply_demo.csv') # 采用Series为DataFrame添加新列 'A' s1 = Series(['a'] * 7978) df['A'] = s1 ----------------------------------------- time data A 0 1473411962 Symbol: APPL Seqno: 0 Price: 1623 a 1 1473411962 Symbol: APPL Seqno: 0 Price: 1623 a 2 1473411963 Symbol: APPL Seqno: 0 Price: 1623 a 3 1473411963 Symbol: APPL Seqno: 0 Price: 1623 a 4 1473411963 Symbol: APPL Seqno: 1 Price: 1649 a =================================================================
上述数据框中列data照片那个数据需要进行预处理
# data 中数据 需要做列拆分
# strip() 去除首尾空格
# split() 分隔数据项
df['data'][0].strip().split(' ')
----------------------------------
['Symbol:', 'APPL', 'Seqno:', '0', 'Price:', '1623']
自定义函数进行处理:实现上述代码功能,并返回data.dict中的values(通过索引)
# 自定义函数进行处理
def foo(data):
items = data.strip().split(' ')
return Series([items[1], items[3], items[5]])
apply 进行数据预处理
# 临时df 存储分隔后的 date列
df_temp = df['data'].apply(foo)
-------------------------------
0 1 2
0 APPL 0 1623
1 APPL 0 1623
2 APPL 0 1623
3 APPL 0 1623
4 APPL 1 1649
临时DataFrame列重命名
# 列重命名
df_new = df_temp.rename(columns={
0: 'Symbol',
1: 'Seqno',
2: 'Price'
})
---------------------------------
Symbol Seqno Price
0 APPL 0 1623
1 APPL 0 1623
2 APPL 0 1623
3 APPL 0 1623
4 APPL 1 1649
临时DataFrame与原DataFrame合并
# 将分隔完成的列添加到原df上
df_ = df.combine_first(df_new)
# 去除不必要的列 'A' 和列 'data'
del df_['A']
del df_['data']
------------------------------
Price Seqno Symbol time
0 1623.0 0.0 APPL 1473411962
1 1623.0 0.0 APPL 1473411962
2 1623.0 0.0 APPL 1473411963
3 1623.0 0.0 APPL 1473411963
4 1649.0 1.0 APPL 1473411963
保存至CSV文件
# 保存至文件
df_.to_csv('demo_duplicate.csv', index=False)
-
数据去重 参照预处理得到的
demo_duplicate.csv数据文件
如果保存CSV的时候,未添加index=False,再次读出的数据会出现索引列(列名为:Unnamed: 0),建议保存时进行索引去除。Price Seqno Symbol time 0 1623.0 0.0 APPL 1473411962 1 1623.0 0.0 APPL 1473411962 2 1623.0 0.0 APPL 1473411963 3 1623.0 0.0 APPL 1473411963 4 1649.0 1.0 APPL 1473411963
通过上述数据展示可以看出:time为基准(索引0、1,索引2、3重复),Seqno为基准(索引0、1、2、3重复),Symbol为基准(索引0、1、2、3、4重复),Price为基准(索引0、1、2、3重复)
重复检查方法:duplicated()

# 针对Seqno列进行去重,可通过keep参数选择保留首次出现的数据项或最终出现的数据项
# 去重前先查看下该列的重复情况 duplicated函数进行查看
df['Seqno'].duplicated()
------------------------
0 False
1 True
2 True
3 True
4 False
去重方法:drop_duplicates()
# 使用 drop_duplicates() 进行列去重
df.drop_duplicates(['Seqno'])
----------------------------------
Price Seqno Symbol time
0 1623.0 0.0 APPL 1473411962
4 1649.0 1.0 APPL 1473411963
-
时间序列的操作基础
引入datetimefrom datetime import datetime t1 = datetime(2018, 12, 7) ----------------------------- datetime.datetime(2018, 12, 7, 0, 0)创建时间序列
# 时间列表 date_list = { datetime(2016,6,6), datetime(2016,7,7), datetime(2018,8,18), datetime(2015,5,15), datetime(2014,4,14), } # 时间序列 s1 = Series(np.random.randn(5), index=date_list) ------------------------------------------------ 2018-08-18 -0.400025 2016-06-06 0.053413 2014-04-14 1.068531 2015-05-15 0.382434 2016-07-07 0.036097 dtype: float64特殊访问方式:模糊匹配
s1['2016-'] ----------- 2016-06-06 0.053413 2016-07-07 0.036097 dtype: float64生成特定时间内的时间序列
# 从2018-01-01 开始,长度为5,步长限制为W(周) 默认从SUN-SAT date_list = pd.date_range('2018-01-01', periods=5, freq='W') ------------------------------------------------------------ 2018-01-07 -1.601305 2018-01-14 0.554921 2018-01-21 0.344534 2018-01-28 0.040423 2018-02-04 -0.707336 Freq: W-SUN, dtype: float64 -
时间序列数据的采样和画图
-
采样
# 模拟时间列表 时间维度为一年 t_range = pd.date_range('2016-01-01', '2016-12-31') # 构建时间序列 s1 = Series(np.random.randn(len(t_range)), index = t_range)用
datetime作为序列索引可通过模糊匹配进行更好的数据采样工作。# 将一个月的数据平均值作为一个数据点,生成长度为12的数据集合 s1['2016-01'].mean() # 按照索引(月份)进行数据采样(平均值数据) s1_month = s1.resample('M').mean() ---------------------------------- 2016-01-31 -0.018625 2016-02-29 0.231429 2016-03-31 0.256555 2016-04-30 0.200803 2016-05-31 0.229022 2016-06-30 0.115717 2016-07-31 -0.207785 2016-08-31 -0.002188 2016-09-30 0.076884 2016-10-31 0.233269 2016-11-30 -0.303828 2016-12-31 -0.028217 Freq: M, dtype: float64备注:
# 也可以按照小时采样,但是数据项需要填充 ffill()、bfill() s1.resample('H').bfill() -
画图:结合上述例子,将时间序列按照月份采样后进行画图
# 准备时间序列 t = pd.date_range('2018-01-01', '2018-12-31') # 构建DataFrame df = DataFrame(index = t) # 填充数据列 df['S1'] = np.random.randint(0, 15, size = 365) df['S2'] = np.random.randint(0, 30, size = 365) # 引入matplotlib import matplotlib.pyplot as plt # 画图 df.plot()此时,画出的图比较密集,不适合查看,接下来进行数据采样重新构图。
# 准备一个新的DataFrame df_ = DataFrame() # 对时间序列的数据按照月份进行平均值采样 df_['S1'] = df['S1'].resample('M').mean() df_['S2'] = df['S2'].resample('M').mean()
-
-
数据分箱技术Binning:
cut()
分数统计Demo,数据准备# 原数据集 score_list = np.random.randint(25, 100, size=20) # 区间设置 bins = [0, 59, 70, 80, 100]数据分箱
# 数据分箱 res = pd.cut(score_list, bins) # res 的数据类型 CategoricalDtype(categories=[(0, 59], (59, 70], (70, 80], (80, 100]] ordered=True) # cut 方法是将score_list 中的数值按照分箱区间 bins 划分到不同的组中 # 相当将每一个数据项都打上分箱标签 pd.value_counts(res) -------------------- (80, 100] 7 (0, 59] 7 (59, 70] 5 (70, 80] 1 dtype: int64例子拓展
# 容器创建 df = DataFrame() # 数据项填充 df['score'] = score_list df['name'] = [pd.util.testing.rands(3) for i in range(20)] # 数据分箱 df['res'] = pd.cut(df['score'], bins, labels = ['Low', 'OK', 'Good', 'Great'])这里需要注意:labels 和 bins 中的分箱标签要保持对应统一
df.sort_values('score', ascending = False).head() ------------------------------------------------- score name res 1 90 dlw Great 7 90 HyF Great 17 87 a4M Great 11 82 L2y Great 19 73 lF5 Good -
数据分组技术GroupBy:
groupby()# 数据分组 g = df.groupby('city') # 查看组内数据项集合 g.groups -------- {'BJ': Int64Index([0, 1, 2, 3, 4, 5], dtype='int64'), 'GZ': Int64Index([14, 15, 16, 17], dtype='int64'), 'SH': Int64Index([6, 7, 8, 9, 10, 11, 12, 13], dtype='int64'), 'SZ': Int64Index([18, 19], dtype='int64')} =========================================== # 查看某个数据项集合 g.get_group('BJ') # 对组内数据项进行apply g.get_group('BJ').mean() ------------------------ temperature 10.000000 wind 2.833333 dtype: float64 ======================== # 对全组进行apply、 g.max() ------------------------------------------- date temperature wind city BJ 31/01/2016 19 5 GZ 31/07/2016 25 5 SH 27/03/2016 20 5 SZ 25/09/2016 20 4 =========================================== g_ = df.groupby(['city', 'wind']) # 获取具体数据项集合的时候需要采用元组的形式作为获取参数 g_.get_group(('BJ',2)) ---------------------- date city temperature wind 1 17/01/2016 BJ 12 2 2 31/01/2016 BJ 19 2 4 28/02/2016 BJ 19 2
Groupby = Split + Apply + Combine

-
数据聚合技术Aggregation:
agg()还是上述例子,对分组后数据的处理apply,我们采用
agg()方法代替。# agg() 进行数据聚合,含有内置函数 g.agg('mean') ------------- temperature wind city BJ 10.000 2.833333 GZ 8.750 4.000000 SH 4.625 3.625000 SZ 5.000 2.500000 ======================== # 自定义聚合函数 def foo(data): return data.max() - data.min() g.agg(foo) ---------- temperature wind city BJ 22 3 GZ 26 3 SH 30 3 SZ 30 3 -
透视表:
pivot_table()
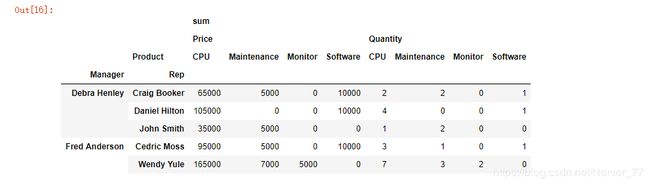
透视表类比视图作用,要对数据表结构比较熟悉和了解。# 读入数据文件 df = pd.read_excel('J:/csv/sales-funnel.xlsx') # aggfunc默认为mean求平均 # Manager 对应多个 Rep # aggfunc 变更为求和 sum 计算出 price、quantity的和 # columns 针对具体列数据项进行处理 ### 以下就是根据表结构构建的透视表,Manager-Rep的对应关系,以及每个Rep在每个产品上[销售业绩、销售数量] pd.pivot_table(df, index=['Manager', 'Rep'], values=['Price', 'Quantity'], columns = ['Product'], aggfunc=['sum'], fill_value=0)