logstash+grok匹配nginx日志示例
Logstash内部定义(匹配正则):
/usr/local/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns
Nginx日志grok过滤示例:
Nginx日志格式如下:
| log_format main '$remote_addr - - [$time_local] "$request" $status $body_bytes_sent "$http_user_agent" "$request_time"';
access_log logs/access.log main; |
Logstash过滤规则配置如下:
| input { file { type => "nginx-access" path => "/usr/local/nginx/logs/access.log" } } filter { grok { match => { "message" => '%{IPV4:remote_ip} \- \- \[%{HTTPDATE:timestamp}\] "%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:bytes} %{QS:referer} "%{NUMBER:req_time}"' } } }
output { elasticsearch { hosts => "192.168.254.131:9200" } stdout { codec => rubydebug } if [response] == "403" { exec { command => "echo '%{host}:%{type}' | mail -s '403_error' [email protected]" } } } |
Grok debugger调试工具:
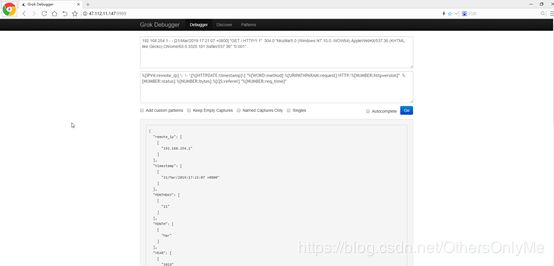
官方翻译部分:
Grok的工作原理是将文本模式组合成与日志匹配的内容。
grok模式的语法是%{syntax:SEMANTIC}
语法是匹配文本的模式的名称。例如,3.44匹配数字模式,55.3.244.1匹配IP模式。语法是如何匹配的。
语义是您为匹配的文本提供的标识符。例如,3.44可以是事件的持续时间,因此可以简单地将其称为持续时间。此外,字符串55.3.244.1可能标识发出请求的客户机。
对于上面的例子,您的grok过滤器应该是这样的:
%{NUMBER:duration} %{IP:client}
您还可以选择向grok模式添加数据类型转换。默认情况下,所有语义都保存为字符串。如果希望转换语义的数据类型,例如,将字符串更改为整数,然后将其后缀为目标数据类型。例如%{NUMBER:num:int},它将num语义从字符串转换为整数。目前唯一支持的转换是int和float。
例子:有了语法和语义的概念,我们可以从一个示例日志中提取有用的字段,比如这个虚构的http请求日志:
55.3.244.1 GET /index.html 15824 0.043
其模式可能是:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
一个更实际的例子,让我们从一个文件中读取这些日志:
input {
file {
path => "/var/log/http.log"
}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
在grok过滤器之后,事件中会有一些额外的字段:
- client: 55.3.244.1
- method: GET
- request: /index.html
- bytes: 15824
- duration: 0.043
常规Expressionsedit
Grok位于正则表达式之上,因此任何正则表达式在Grok中都是有效的。正则表达式库是Oniguruma,您可以在Oniguruma站点上看到完全支持的regexp语法。
自定义Patternsedit
有时logstash没有您需要的模式。对此,您有几个选项。
首先,你可以使用Oniguruma的命名捕获语法,这将让你匹配一段文本,并保存为一个字段:
(?the pattern here)
例如,postfix日志的队列id是10或11个字符的十六进制值。我可以像这样很容易地捕捉到:
(?[0-9A-F]{10,11})
另外,您可以创建一个自定义模式文件。
创建一个名为patterns的目录,其中包含一个名为extra的文件(文件名无关紧要,但您可以为自己取一个有意义的名称)
在该文件中,将需要的模式作为模式名称、空格,然后为该模式编写regexp。
例如,执行上面的postfix队列id示例:
# contents of ./patterns/postfix:
POSTFIX_QUEUEID [0-9A-F]{10,11}
然后使用这个插件中的patterns_dir设置来告诉logstash自定义模式目录的位置。下面是一个完整的例子与样本日志:
Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<[email protected]>
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
以上将匹配并在以下字段中得到结果:
- timestamp: Jan 1 06:25:43
- logsource: mailserver14
- program: postfix/cleanup
- pid: 21403
- queue_id: BEF25A72965
- syslog_message: message-id=<[email protected]>
- 时间戳、logsource、程序和pid字段来自SYSLOGBASE模式,它本身由其他模式定义。
- 另一个选项是使用pattern_definition在过滤器中内联定义模式。这主要是为了方便,并允许用户定义一个模式,该模式只能在该过滤器中使用。pattern_definition中新定义的模式在特定的grok过滤器之外不可用。
附kibana页面内置grok调试工具:
