Python高级--数据分析(pandas + matplotlib 绘图)
一、matplotlib 库
一个用来绘图的库
import matplotlib.pyplot as plt
1)plt.imread(“图片路径”)
功能: 将图片加载后返回一个维数组
>>> jin = plt.imread("./jin.png")
>>> jin
array([[[0.24313726, 0.24313726, 0.24705882],
...,
[0.7294118 , 0.7294118 , 0.7294118 ]]], dtype=float32)
>>> jin.shpae
(273, 411, 3)
'''
这是一个三维数组
第一层代表将图片分成273行,
第二层代表将图片的第一层的每一行分为411列,
第三层代表将每一像素点中的(R,G,B)
注意:有些图片加载后最内层有4个元素,分别是(R,G,B,A[阿尔法/透明度])
'''
2)plt.imshow(ndarray)显示图片
功能: 将多维数组渲染为一张图片
>>> plt.imshow(nd) #将加载后的多维数组传入就可以将图片渲染出来
'''
有的图片加载出来之后数据范围在0-255之间的需要将数据/255之后转化为0-1之间的就可以和0-1的图片进行合并操作
'''
这里就可以将图片进行处理(反转,拉伸,改色)等操作

3)plt.imsave(ndarray)保存图片
plt.imsave(ndarray)
默认保存到当前路径
plt.imsave('图片名称.png',图片数据,cmap='gray') #保存图片
cmap:将图片保存为黑白图片
二、Pandas绘图
1.绘制简单的线型图
1.1)简单的Series图表示例 .plot()
绘制正弦曲线
# 正弦曲线
x = np.linspace(0,2*np.pi,100) # 从0 到 2π 取100份
y = np.sin(x) # y 为sin(x) 的值
s = Series(data=y,index=x) # 构建一个Series对象
s.plot() # 使用Series的plot()方法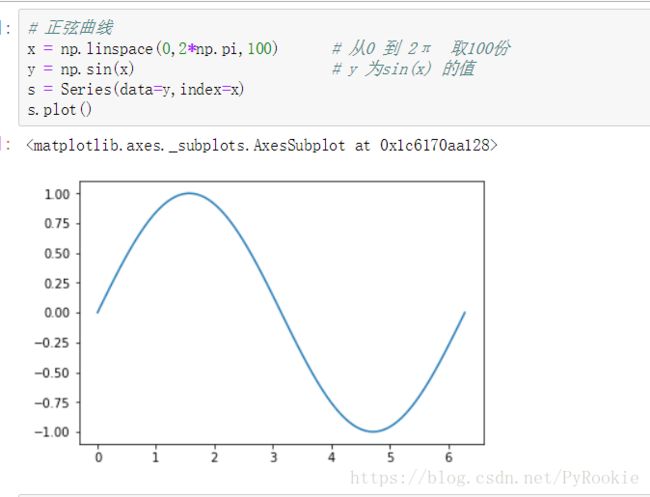 `
`
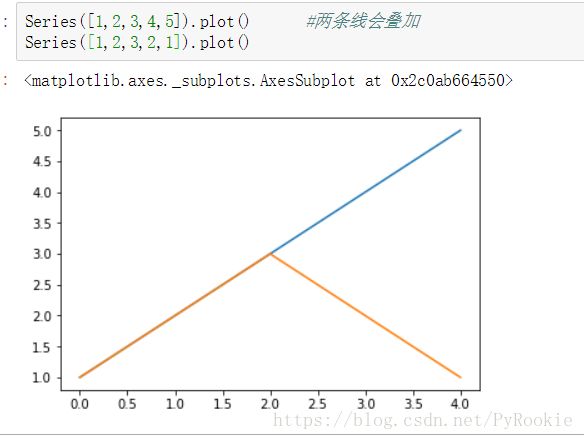
1.2) 两个Series绘制的曲线可以叠加
2)简单的DataFrame图表示例 .plot()
绘制余弦曲线
x = np.linspace(0,2*np.pi,100) # 从0 到 2π 取100份
df = DataFrame(data={'sin':np.sin(x),'cos':np.cos(x)},index=x) #创建DataFrame对象
df.plot()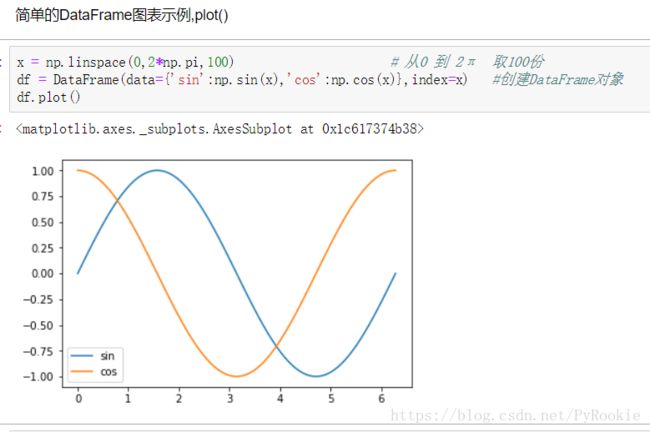
2.数据驱动的线型图(分析苹果股票)
导包
import numpy as np
import pandas as pd
from pandas import Series,DataFrame1.读取数据
- 读取文件AAPL.csv
df = pd.read_csv('./data/AAPL.csv')
df.head()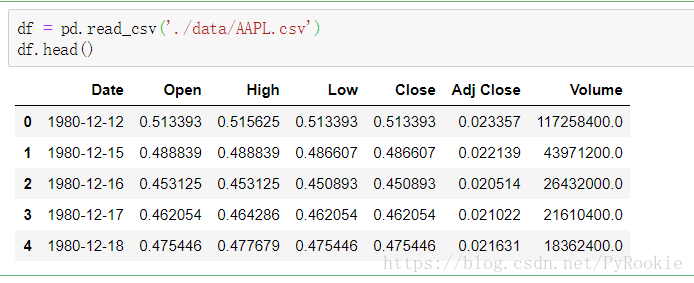
2.检查数据类型
df.dtypes
Date object #时间的数据类型为对象,在使用中需要做处理
Open float64
High float64
Low float64
Close float64
Adj Close float64
Volume float64
dtype: object
3.将’Date’这行数据转换为时间数据类型
pd.to_datetime(Series对象)
功能: 将Series转换为时间数据类型
df['Date'] # 这一列获取出来是一个Series
type(df['Date'])
df['Date'] = pd.to_datetime(df['Date'])df.dtypes
Date datetime64[ns] #此时已经是时间类型的数据了
Open float64
High float64
Low float64
Close float64
Adj Close float64
Volume float64
dtype: object
4.将’Date’设置为行索引
df.set_index('Date',inplace=True)
'''
inplace:改变原来的变量的值
'''
5.绘制图形,以字段Adj Close(已调整收盘价格)为数据绘制
df['Adj Close'].plot()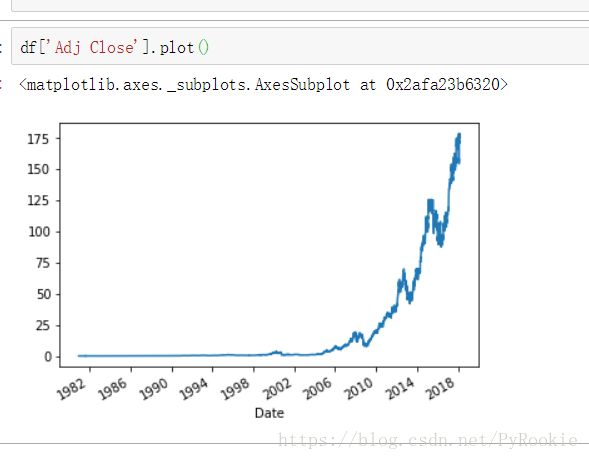
3.绘制简单的柱状图
1) Series柱状图示例,kind = ‘bar’/’barh’
随机产生5个数,对其绘制纵向柱状图
'''
data: 生成之后为Y轴的数据
index: 生成之后为X轴的索引
'''
s = Series(data=np.random.randint(0,10,size=5),index=list('abcde')) #随机产生5个数
s.plot(kind='bar')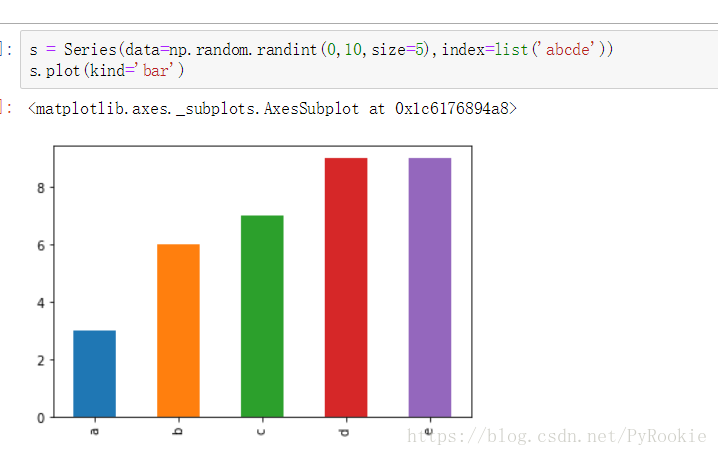
随机产生5个数,对其绘制横向柱状图
'''
data: 生成之后为Y轴的数据
index: 生成之后为X轴的索引
'''
s = Series(data=np.random.randint(0,10,size=5),index=list('abcde'))
s.plot(kind='barh')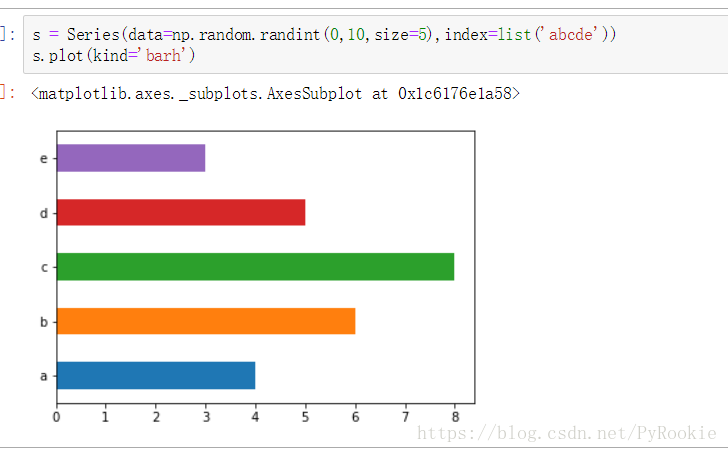
2) DataFrame柱状图示例
随机产生一个二维数组,并绘制纵向(kind=’bar’)柱状图
'''
index: 生成数据X轴的索引
columns: 特征的名称
'''
df = DataFrame(np.random.randint(0,10,size=(8,4)),index=list('abcdefgh'),columns=list('ABCD'))
df.plot(kind='bar')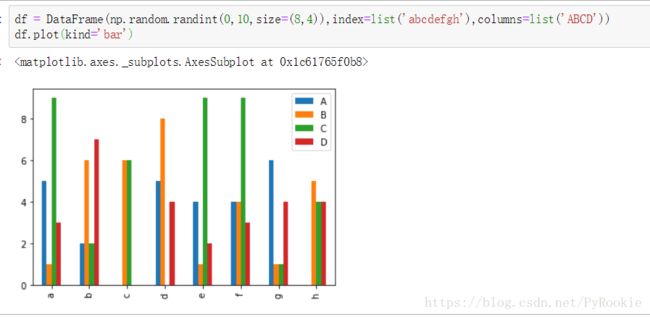
随机产生一个二维数组,并绘制横向(kind=’barh’)柱状图
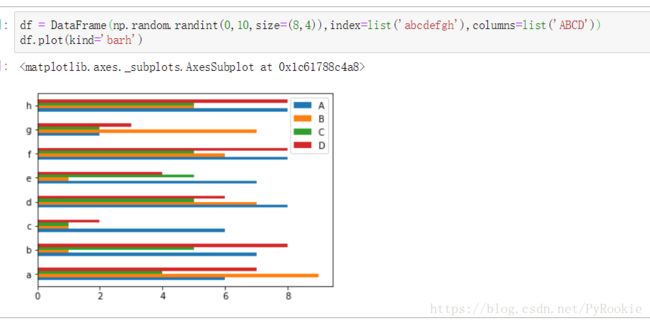
4.绘制简单的直方图
直方图
直方图(Histogram)又称质量分布图。是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据类型,纵轴表示分布情况。
s = Series(np.random.normal(loc=0,scale=5,size=10000)) # normal 正态分布
s.hist()
#这里模拟出一组以0为中心,标准差为5的正态分布数据, 绘制出的直方图如下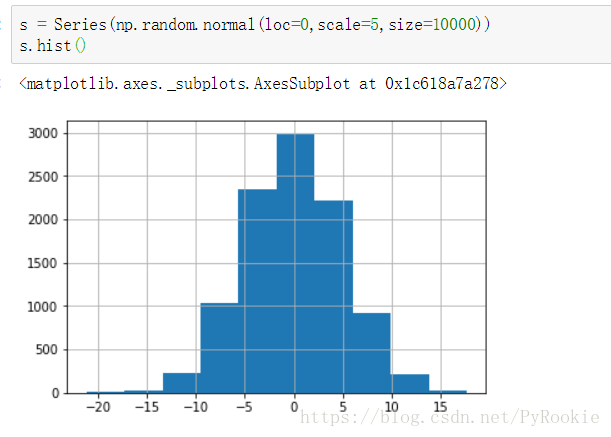
5.绘制简单的核密度(“ked”)图
核心密度估计:对分布的图进行估计核心
我们继续使用刚刚直方图的 Series的正态分布数据
Series(np.random.normal(loc=0,scale=5,size=10000))
s.plot(kind='kde')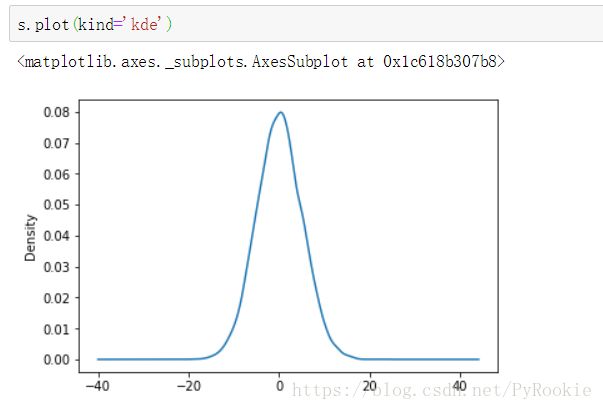
直方图一般和核密度图常常被画在一起,既展示出频率,又展示出了概率
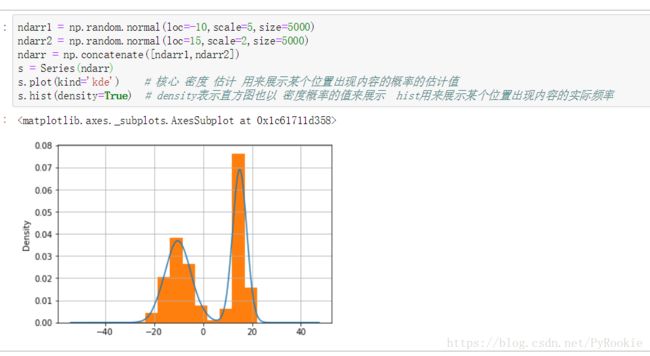
有两组数组,我们将这两组数据连接成为一个。
分析这组新数据
ndarr1 = np.random.normal(loc=-10,scale=5,size=5000) #第一组数据
ndarr2 = np.random.normal(loc=15,scale=2,size=5000) 第二组数据
ndarr = np.concatenate([ndarr1,ndarr2]) #将两组数据合为一组
s = Series(ndarr) #生成Series对象
s.plot(kind='kde') # 核心 密度 估计 用来展示某个位置出现内容的概率的估计值
s.hist(density=True) # density表示直方图也以 密度概率的值来展示 hist用来展示某个位置出现内容的实际频率
#展示效果如下'''
s.plot(kind='kde') 展示某个位置的估计值
s.hist(density=True) 表示某个位置出现内容的实际频率
'''
6.绘制简单的散点图
散布图是观察两个一维数据数列之间的关系的有效方法
示例数据
df = DataFrame(np.random.randint(0,150,size=(20,3)),columns=['python','math','eng'])
df #模拟一个DataFrame数据,列名为'python','math','eng'
python math eng
0 141 41 55
1 37 76 96
2 61 28 135
。。。
17 124 103 83
18 86 47 44
19 35 85 85将这组数据生成散点图
df.plot(kind='scatter',x='python',y='eng')
# kind = 'scatter' , 给明标签columns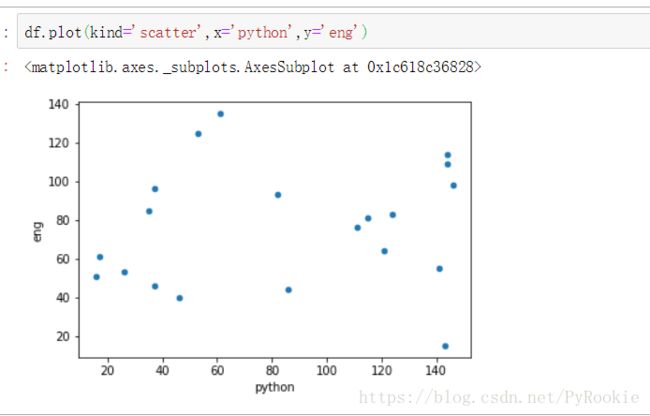
这样其实是没有什么实际的意义的
现在我们再加一列和“python”相关的数据
np.random.randint(-10,10,1)[0] # 0-10之间 随机取一个数
df['php'] = df['python'].map(lambda x: x*0.9+np.random.randint(-10,10,1)[0])
df
python math eng php
0 121 67 15 113.9
1 148 33 149 123.2
。。。
18 79 77 108 74.1
19 105 107 53 102.5我们从数据是很难看出来python和php有什么关系
这时我们就可以用散点图来绘制出观察
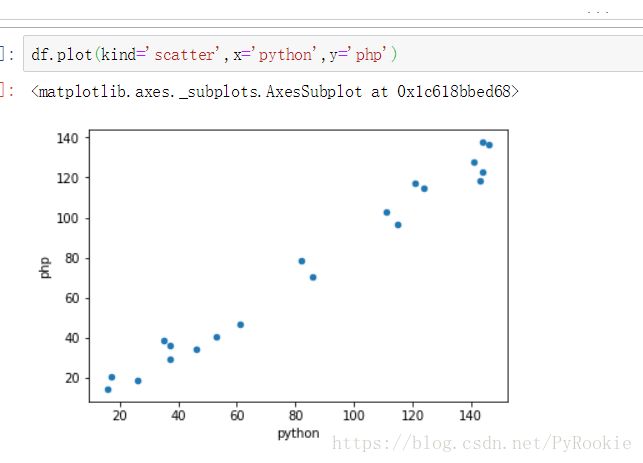
可以看出有python的值增大,php的值也会增大。