python selenium爬取QQ空间说说
准备工作
安装selenium, pyquery, json模块。
使用的是火狐浏览器,所以还要安装geckodriver, 下载好后,把geckodirver.exe文件放在python.exe同一文件夹下即可。
如果使用chrome浏览器,需要安装chromedriver,需要对应好版本号,否则运行不起来。把下载后的chromedriver.exe放在python的Scripts文件夹下即可。
本次爬取使用火狐浏览器。
爬取步骤
爬虫最重要的一步就是如何获取到网页源代码,对于现在各种各样的动态网页,有时候可以使用Ajax请求直接获取到数据,但是大多数时候Ajax请求中的参数繁多也难以确定规律,所以本次使用selenium来获取网页的源代码,所见即所爬。
1、获取网页源码
首先确定我们需要访问的网页网址。
![]()
中间的部分就是你想要爬取的QQ号。这里解释下后面的main为主页。将main换成了其他的一些数字,例如311,334等等,这些可以直接访问到说说,留言版等等,感兴趣的可以直接访问说说界面开始爬取信息,这里不做考虑,还是直接从主页开始一步步访问说说。
这里放一张图片,为什么是311可以直接访问到说说。(右键检查(查看元素)或者F12进入)

在进入空间主页后,我们接下来需要确定“说说”按钮,有两个说说按钮,获取其中一个就行。(详细代码后面再放)
btn_ss = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#QM_Profile_Mood_A span')))
btn_ss.click()
等待按钮可点击后,点击按钮,网页即跳转到说说界面。这里有个坑,如果这时候你直接获取网页源代码是获取不全的。
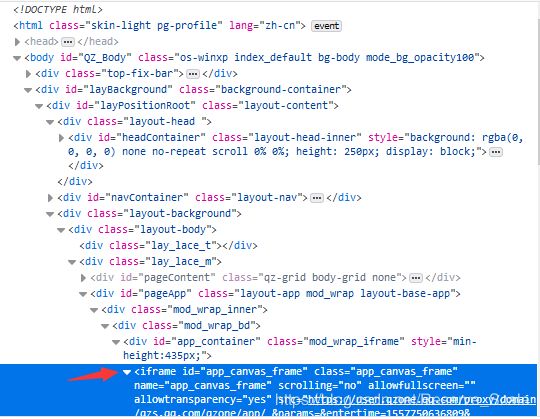
如果你没有从头分析网页结构,你肯定会忽略掉这个iframe标签,然后一直尝试获取网页源代码,但就是发现获取不到你想要的说说数据在哪。(卡了可能有一个小时,才想起来可能有iframe标签,o(╥﹏╥)o哭了)
如果不知道iframe标签的作用的话,这里简单介绍一下,如果你获取的网页中含有iframe或者frame标签,则你将获取不到这些标签里面的数据,必须使用switch_to.frame()方法切换frame,同样的在子frame中也是获取不到父frame中的数据。
browser.switch_to.frame('app_canvas_frame')
这里将browser切换frame,填入的参数为iframe的id即可成功切换。切换好数据后就可以成功的爬取数据了。
这里page可以先忽略,用来分页爬取时使用。
browser = webdriver.Firefox()
wait = WebDriverWait(browser, 10)
def index_page(qq, page):
# 进入主页
try:
url = 'https://user.qzone.qq.com/' + qq
browser.get(url)
btn_ss = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#QM_Profile_Mood_A span')))
btn_ss.click()
browser.switch_to.frame('app_canvas_frame')
if page > 1:
print('正在爬取', page, '页')
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#pager .textinput')))
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#pager .bt_tx2')))
input.clear()
input.send_keys(page)
submit.click()
get_info()
except TimeoutException:
index_page(qq, page)
2、解析网页源码
在获取网页源码前,最好先等待几秒,不然可能在切换frame后,仍然获取不到其中的数据。
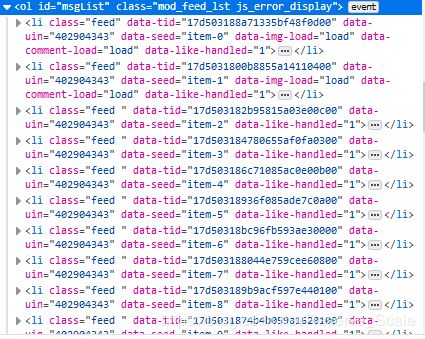
所有的说说都是在ol这个便签下,ol便签下的一个li标签对应一条说说,同时我们发现每个li标签都有feed属性。
所以第一步我们先获取到这些li标签,这里使用css选择器来获取到ol下所有的li标签。
items = doc('#msgList .feed').items()
如果对css选择器不熟悉的朋友,我这里再稍微解释一下,#号后面跟着的是id,.号后面跟着的是属性,如果像直接获取到标签就直接使用li, ol即可。,css选择器可以嵌套多个属性,标签等等。
获取到li标签后,我们再来解析li标签的结构。
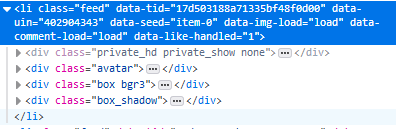
第一个div是用户的头像,第二个div才是我们需要的说说主体,第三个div没啥用。

接下来就是定位说说的文字,图片,时间,转发评论数分别属于哪个部分,再通过css选择器选定标签,获取其中的信息。
def get_info():
time.sleep(3)
html = browser.page_source
# print(html)
doc = pq(html)
items = doc('#msgList .feed').items()
for item in items:
pic = []
images = item.find('.md img').items()
for image in images:
pic.append(image.attr('data-src'))
ss = {
'author': item.find('.bd .qz_311_author').text(),
'content': item.find('.bd .content').text(),
'image': pic,
'time': item.find('.ft .info').text()
}
save_to_txt(ss)
3、写入文件
写入文件没什么好介绍的,这里使用json,直接写入的是txt,可以选择存放在数据库中,或者csv文件。
def save_to_txt(ss):
with open('data.txt', 'a', encoding='gb18030') as file:
file.write(json.dumps(ss, ensure_ascii=False) + '\n')
4、分页爬取
MAX_PAGE = 17
if __name__ == '__main__':
for page in range(1, MAX_PAGE + 1):
index_page('qq号', page)
分页爬取时,需要先提前确定爬取的最大页数。
if page > 1:
print('正在爬取', page, '页')
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#pager .textinput')))
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#pager .bt_tx2')))
input.clear()
input.send_keys(page)
submit.click()
回到之前的if语句,这里是获取的是一个文本框与按钮。

判断在爬取到第二页的时候,因为我们一直都是访问第一页的说说,所以在解析前,需要进行跳转网页。如果使用下一页跳转的话,那比如在第十页跳转出错时,就无法直接从第十一页开始继续获取数据。
再强调一次,一定要记得切换frame,否则将无法获取到这些文本框,按钮,导致无法进行跳转!!!
说在最后的话
第一点:不要忘记切换frame
第二点:不要频繁尝试爬取一个人,因为可能被检测到,导致出现下面的提示。

别问我怎么知道的,ヾ(⌐ ■_■)。虽然出现这个并不影响继续爬虫,但是还是很难过啊,一般过几个小时候,就会自动解了。
第三点:爬取的时候可能会报错,解决办法就是once again,重新运行。还有就是在你觉得可能错误的地方,sleep一下,等待网页响应,因为可能你需要的控件没有加载出来。(可是我都wait了,为什么有时候没有跳转到说说界面,直接运行switch语句,不要问我,我也不知道orz…)
第四点:当你运行程序,弹出网页的时候,需要你登录,这时候你可以选择手动登录或者python 模拟登录。但是,模拟登录多了,也就是几次之后,就会出现验证码,要模拟验证这又是另一回事了。所以这里推荐还是手动登录,稳妥。又一个但是,如果你想要无界面爬取,就是使用PhantomJS的话,就必须模拟登录,并且需要判断是否需要进行验证,两个字:麻烦。模拟登录的代码,我注释了在总代码中,想要试试的朋友,直接将注释去掉即可。
第五点:你或许想爬那些需要访问授权的好友空间,我这里郑重告诉你,或许别人的代码可行,但是我的代码是不可以的。(因为没去考虑啊,干)
第五点:(这人话好多啊(╯‵□′)╯︵┻━┻)代码在这,差点忘了。https://github.com/DRNTT/Spider/blob/master/练习/kongjian.py