Keras 深度学习攻略两篇(1):十种卷积神经网络(CNN)框架——总结与可视化分析
典型深度学习框架
- 1. 概述
- 2 .可视化解读十种CNN框架
- 2.1 LeNet-5(1998)
- 2.2 AlexNet(2012)
- 2.3 VGG16(2014)
- 2.4 Inception-v1(2014)
- 2.5 Inception-v3(2015)
- 2.6 ResNet-50 (2015)
- 2.7 Xception (2016)
- 2.8 Inception-v4 (2016)
- 2.9 Inception-ResNet-V2 (2016)
- 2.10 ResNeXt-50 (2017)
- 2.11 附
- 模型的实现(基础模型)
- Network In Network (2014)
- MobileNets-ShuffleNet-MobileNetV2
- 3. 总结
十种卷积神经网络框架
1. 概述
-
论文发表时间:

-
Keras 中的部分模型

现在已经不止6种:Keras Documentation

“[m]ost of this progress is not just the result of more powerful hardware, larger datasets and bigger models, but mainly a consequence of new ideas, algorithms and improved network architectures.” (Szegedy et al, 2014)
2 .可视化解读十种CNN框架

2.1 LeNet-5(1998)

LeNet-5 是最简单的框架之一,由2个卷积层和三个全连接层组成(因此叫做”5“——这种使用据卷积层和全连接层的数量来命名是一种很常普遍的做法)
创新点:
这个模型成为了一个标准”模板“:堆叠卷积层和池化层,最后以一层或者多层的全连接层结尾。
发表:
- Paper: Gradient-Based Learning Applied to Document Recognition
- Authors: Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner
- Published in: Proceedings of the IEEE (1998)
2.2 AlexNet(2012)

参数量60M的AlexNet有八层网络——5层卷积核3层全连接层。
相比LeNet-5来说,AlexNet也不过是多了几层网络。作者在论文中提到,他们“在ImageNet子集上训练了到目前为止最大的神经网络之一”。
创新点:
- 第一次使用Rectified Linear Units (ReLUs) 作为激活函数
发表:
- Paper: ImageNet Classification with Deep Convolutional Neural Networks
- Authors: Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton. University of Toronto, Canada.
- Published in: NeurIPS 2012
2.3 VGG16(2014)

相信你也注意到了CNNs网络的层数变得越来越深。这是因为提升提升深度神经网络模型
性能最直接的方式就是提升它的大小(Szegedy et. al)。
VGG16由 Visual Geometry Group (VGG) 的人提出,它包含13个卷积层和3个全连接层,激活函数沿用的AlexNet的ReLU。
相比AlexNet,VGG16堆叠了更多地层,同时使用了更小的卷积核(2×2 and 3×3))。VGG16模型参数的大小是138M,同时需要500M的储存空间!他们也训练了另外一个网络:VGG19。
创新点:
- 正如上面提到的,使用了更深的网络(几乎是AlexNet的两倍)
发表: - Paper: Very Deep Convolutional Networks for Large-Scale Image Recognition
- Authors: Karen Simonyan, Andrew Zisserman. University of Oxford, UK.
- arXiv preprint, 2014
2.4 Inception-v1(2014)
注:这个模型的名称(Stem and Inception)并没有在这个版本使用,而是在其后续版本,Inception-v4 和 Inception-ResNets出来之后才这么叫。
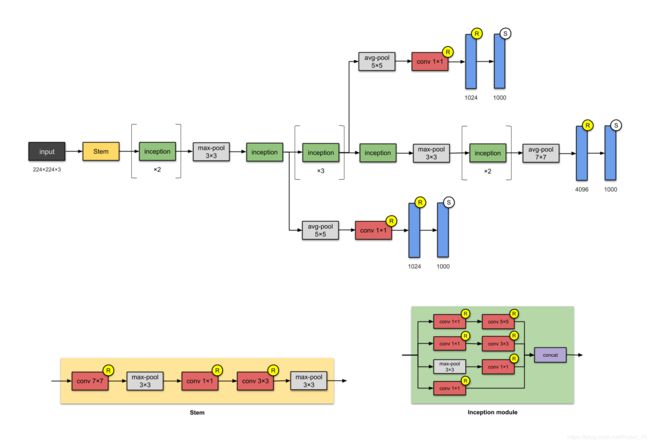
这个层数为22、参数大小为5M的网络叫做 Inception-v1。网络中的网络方法(参见 Appendix)被大量使用——一个研究稀疏结构的产物——Inception 模块。
每个模块呈现了三种思想:
- 拥有使用了不同大小卷积核( 1x1、3×3、5x5 等)的平行卷积层网络,并将得 到的特征映射在深度上拼接(堆叠)起来作为输出特征映射。(受 Arora et al的气启发-Provable bounds for learning some deep representations)
- 1×1卷积用于维数降低( 在进行 3×3、5×5 的卷积之前),以除去计算瓶颈。(1×1 的卷积相当于先进行一次特征抽取)
- 由于激活函数来自于1x1的卷积,因此它也增加了非线性性。(这个思路来自paper)
- The authors also introduced two auxiliary classifiers to encourage discrimination in the lower stages of the classifier, to increase the gradient signal that gets propagated back, and to provide additional regularisation. The auxiliary networks (the branches that are connected to the auxiliary classifier) are discarded at inference time.
It is worth noting that “[t]he main hallmark of this architecture is the improved utilisation of the computing resources inside the network.”
创新点:
- 利用密集的模块构建网络。使用了包含了卷积层的 modules or blocks 构建网络,而不是堆叠卷积层。故名”为盗梦空间“。((参照2010年由莱昂纳多·迪卡普里奥主演的的科幻电影盗梦空间)
发表:
- Paper: Going Deeper with Convolutions
- Authors: Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. Google, University of Michigan, University of North Carolina
- Published in: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
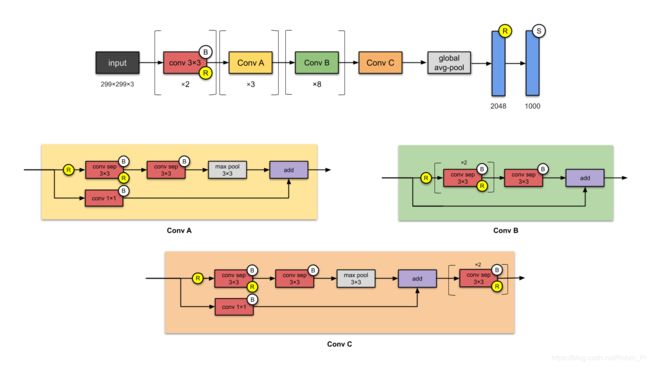
2.5 Inception-v3(2015)

注:All convolutional layers are followed by batch norm and ReLU activation.
Inception-v3 是 Inception-v1的改进版本,有24M的参数量。
为什么没有v2?因为v2是v3的早期版本所以没推广使用,作者将在v2版本中进行了各种实验,并将其中表现好的技巧用在了v3上。
v2 和 v3 创作之初是为了避免”表示瓶颈“( representational bottlenecks )的问题(大幅降低了下一层的输入维度)以及通过使用因式分解的方法使得计算更加更高效。
注:图中模块的名称(Stem, Inception-A, Inception-B etc.)在更后面的版本,比如 Inception-v4 和 Inception-ResNets 出来之后才被这样称呼。(这里只是为了方便理解才这么表示)
创新点:
- 最早使用 batch normalisation 的设计之一
相比v1的改进: - 使用连续的n × 1和1 × n来替换n × n的 卷积
- 使用两层 3 × 3 的 卷积来替换v1中的5 × 5的卷积
- 将7 x 7 的卷积改为一些列 3 x 3 的卷积
发表:
- Paper: Rethinking the Inception Architecture for Computer Vision
- Authors: Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna. Google, University College London
- Published in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2.6 ResNet-50 (2015)

ResNet-50 使用跳层连接skip connections (a.k.a. shortcut connections, residuals),使得深度有了一个量的飞跃。
ResNet-50 是最早使用 batch normalisation ( Ioffe and Szegedy - ICML in 2015)的模型之一,它有26M的参数。
可以简单地将 ResNet-50 看成下面这种结构:
conv and identity blocks → Identity block
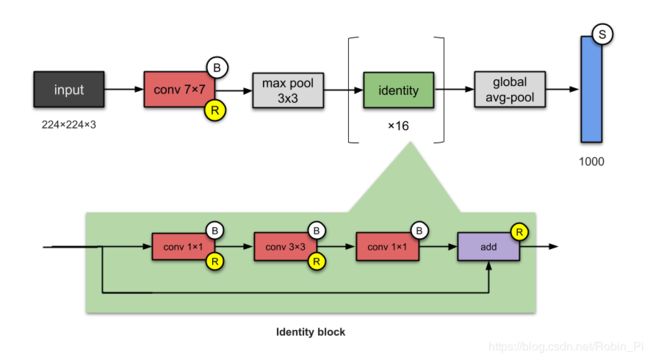
创新点:
- 使跳层连接广为人知(并不是他们发明的)
- 更深的网络(152层),但并没有损失泛化能力
- batch normalisation 最早使用者之一
发表:
- Paper: Deep Residual Learning for Image Recognition
- Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Microsoft
- Published in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2.7 Xception (2016)
Xception 是基于 Inception的一个改进模型,使用深度可分离卷积( depthwise separable convolutions) 替换了 Inception 模块。
它和的参数量和 Inception-v1 差不多(23M)
Xception 把 Inception 假设到了极致(eXcptionn)(因此得名)。
Firstly, cross-channel (or cross-feature map) correlations are captured by 1×1 convolutions.
Consequently, spatial correlations within each channel are captured via the regular 3×3 or 5×5 convolutions.
将上述思想运用到一个极值的意思是在每一个channel都使用 1x1 的卷积,然后3x3的卷积用在每个输出上。这等同于使用深度可分离卷积来替换 Inception 模块。
创新点:
引入完全基于深度方向的可分离卷积层CNN。
发表:
- Paper: Xception: Deep Learning with Depthwise Separable Convolutions
- Authors: François Chollet. Google.
- Published in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2.8 Inception-v4 (2016)

Inception-v4 是基于 Inception-v3 的改进,The main difference is the Stem group and some minor changes in the Inception-C module.
有人认为 Inception-v4 表现的更好是因为增加了模型的体量。
创新点:
- Change in Stem module.
- Adding more Inception modules.
- Uniform choices of Inception-v3 modules, meaning using the same number of filters for every module.
发表:
Paper: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Authors: Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Google.
Published in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
2.9 Inception-ResNet-V2 (2016)

创新点:
- Converting Inception modules to Residual Inception blocks.
- Adding more Inception modules.
Adding a new type of Inception module - (Inception-A) after the Stem module.
发表:
- Paper: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- Authors: Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Google
- Published in: Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
2.10 ResNeXt-50 (2017)
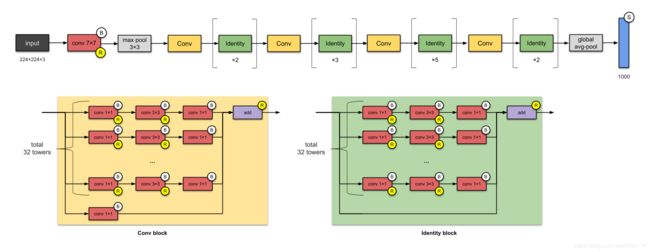
ResNeXt-50 的参数量是 25M,和 ResNets (参数量 25.5M)的确相关。差别主要是 ‘’ResNeXts is the adding of parallel towers/branches/paths within each module, as seen above indicated by ‘total 32 towers.’”
发表:
- Paper: Aggregated Residual Transformations for Deep Neural Networks
- Authors: Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He. University of California San Diego, Facebook Research
- Published in: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2.11 附
模型的实现(基础模型)
keras实现常用深度学习模型
利用Keras实现常用CNN结构
Network In Network (2014)
Recall that in a convolution, the value of a pixel is a linear combination of the weights in a filter and the current sliding window. The authors proposed that instead of this linear combination, let’s have a mini neural network with 1 hidden layer. This is what they coined as Mlpconv. So what we’re dealing with here is a (simple 1 hidden layer) network in a (convolutional neural) network.
Mlpconv 的思路被称为 1x1卷积,并且成为了 Inception 网络的主要的结构特征。
创新:
- MLP convolutional layers, 1×1 convolutions
- Global average pooling (taking average of each feature map, and feeding the resulting vector into the softmax layer)
发表:
- Paper: Network In Network
- Authors: Min Lin, Qiang Chen, Shuicheng Yan. National University of Singapore
- arXiv preprint, 2013
MobileNets-ShuffleNet-MobileNetV2
-
MobileNets: EfficientConvolutional Neural Networks for Mobile Vision Applications
-
ShuffleNet: AnExtremely Efficient Convolutional Neural Network for Mobile Devicest
-
MobileNetV2: Inverted Residuals and Linear Bottlenecks
3. 总结
多尺寸卷积核——Inception 初版;
Pointwise Conv = PW= 1x1卷积——Inception-v1、MobileNet V2 ;
使用多个小卷积核替代大卷积核——Inception v3;
Bottleneck——
Depthwise Separable Conv——MobileNet、Xception
总结:
- Xception :先 Depthwise Conv 再 Pointwise Conv
- Inception到Xception:
多个不同尺寸的卷积核,提高对不同尺度特征的适应能力。
PW 卷积,降维或升维的同时,提高网络的表达能力。
多个小尺寸卷积核替代大卷积核,加深网络的同时减少参数量。
精巧的 Bottleneck 结构,大大减少网络参数量。
精巧的 Depthwise Separable Conv 设计,再度减少参数量。
后续参考:
- CNN网络架构演进:从LeNet到DenseNet
- 对于xception非常好的理解
- 关于「Inception」和「Xception」的那些事
- 网络 Inception, Xception, MobileNet, ShuffeNet, ResNeXt, SqueezeNet, EfficientNet, MixConv
- 深度学习之CNN模型演化
参考:
博客
- Keras Documentation
- Illustrated: 10 CNN Architectures
- keras系列︱迁移学习:利用InceptionV3进行fine-tuning及预测、完美案例(五)
- 深度学习在表情识别中的应用
- Building powerful image classification models using very little data
- DeepLearning(keras框架)–图像输入大小及通道调整问题
- Display Deep Learning Model Training History in Keras
论文
- Gradient-Based Learning Applied to Document Recognition
- ImageNet Classification with Deep Convolutional Neural Networks
- Very Deep Convolutional Networks for Large-Scale Image Recognition
- Going Deeper with Convolutions