CPU Sched - CPU 调度
Introduction
本文将介绍 CPU 高级策略之 CPU 调度,针对一系列调度策略展开。
Q:
如何制定调度策略?
- 如何开发一个基本框架考虑调度策略?
- 需要做哪些关键的假设?
- 哪些指标是最重要的?
- 最早的计算机使用的基本方法?
工作量假设 [Workload Assumptions]
在开始介绍策略之前,首先对系统中运行的进程 (或称为工作量) 做一些假设。
确定工作量是建立策略的步骤中最重要的部分
Hint: 这些看似不可行的假设,在之后的介绍中会放宽要求,简化了全业务调度的开发
- 所有进程的运行时间相同;
- 所有进程同时到达等待启动;
- 一旦开始,所有进程终将进行完整的运行流程;
- 所有的进程均只利用 CPU(不执行任何 I/O)
- 每个进程的运行时间已知
调度指标 [Scheduling Metrics]
我们需要一样东西来衡量不同的调度策略,即调度指标
设定一个简单的指标:Turnaround Time (理解为 “周转时间” ), 其定义为进程完成的时刻减去到达等待开始的时刻:
T t u r n a r o u n d = T c o m p l e t i o n − T a r r i v a l T_{turnaround } = T_{completion} - T_{arrival} Tturnaround=Tcompletion−Tarrival
在工作量假设中有一条假设:所有进程同时等待启动,所以 T a r r i v a l = 0 T_{arrival} = 0 Tarrival=0 ,进一步, T t u r n a r o u n d = T c o m p l e t i o n T_{turnaround } = T_{completion} Tturnaround=Tcompletion。也就是说放宽假设的要求,这个观点就会改变。
生活不总是完美的
注意到,周转时间是一个性能指标,由此不得不再设定一个指标,Fairness (理解为公平性)
在调度中,性能和公平性常常是不一致的
For Example:调度程序可以优化性能,但代价是阻止一些作业运行,从而降低公平性。
先进先出(FIFO)
FIFO 的优点在于简单易实现
我们可以实现的最基本的算法是先进先出调度 ( 亦被称为 First Come, First Served - FCFS )
For Example:
假设系统中有三个进程,A、B和C,大致同时到达( T a r r i v a l = 0 T_{arrival}= 0 Tarrival=0)。因为 FIFO 必须把某个进程放在第一位执行。假设当它们同时到达时,A在B之前到达,而B在C之前到达。同时假设每个进程运行10秒。这些工作的平均周转时间将是多少?

图中模拟了进程执行时间,A 在10 的位置完成,B 在20 的位置完成,C 在30 的位置完成
那么,平均周转时间计算为:
10 + 20 + 30 3 = 20 {\frac{10+20+30}{3}} = 20 310+20+30=20
问题来了:
如果我们放宽第一个假设的要求,不再假设每个进程的运行时间相同。
- 这种情形下,FIFO 如何运行?
- 如何构建工作量,会导致 FIFO 性能崩溃?
我们继续通过例子模拟进程的运行时间,以及不同运行时间的进程如何搞垮 FIFO
For Example:
接着之前的三个进程 A、B、C,与上次不同的是 A 运行时间为100,B、C均为10
模拟结果:

B、C 在运行之前先等待 A 运行 100,这样,平均周转时间计算为:
100 + 110 + 120 3 = 110 {\frac{100+110+120}{3}} = 110 3100+110+120=110
一些资源较短的潜在消费者排在一些重量级资源消费者的后面,这便是经典的护航效应 (convoy effect)。
Q:
怎样才能开发出一个更好的算法来处理运行时间不同的进程呢?
Shortest Job First - SJF
是一个通用的调度原则,它可以应用于任何系统
特点是:每个进程的周转时间平等重要
忆上个学期运筹学中的运输问题解决办法 − - −>最短作业法事实上,这个方法可以应用于计算机系统中的工作调度。
这个新的调度规则称为最短作业优先 (最短作业优先),其名称应该很容易记住,因为它非常完整地描述了策略: 首先运行最短作业,然后运行下一个最短作业,以此类推。

接着前面的例子重新模拟,平均周转时间计算为:
10 + 20 + 120 3 = 50 {\frac{10+20+120}{3}} = 50 310+20+120=50
[ 110 − > 50 ] [110->50 ] [110−>50]
理论上,如果假设进程同时到达成立,那么可以证明 SJF 是一个最优调度算法【实际中,非也】
问题来了:
针对假设2,对其要求再进一步放宽,让进程随机到达,而不是同时,会出现什么状况?
For Example:
假设 A 在 t = 0 时刻到达,需要运行 100 ,而 B 和 C 在 t = 10 到达,每个需要运行 10 。
模拟结果:

B、C 在 A 开始运行后到达,出现了和之前相同的护航效应,此时,平均周转时间计算为:
100 + ( 110 − 10 ) + ( 120 − 10 ) 3 = 103.33... {\frac{100+(110-10)+(120-10)}{3}} = 103.33... 3100+(110−10)+(120−10)=103.33...
Q:
调度究竟能做什么?
A:
为了解决新出现的问题,接下来考虑放宽假设 3 的要求
补充:
在以前的批量计算时代,开发了许多非抢占式调度程序,这种系统将正在运行的进程运行完毕才考虑要不要运行下一个新的进程,几乎所有的现代调度程序都是抢占式的,并且会为了运行另一个进程而停止一个进程的运行。
这意味着调度程序采用了我们之前了解到的机制;特别是,调度程序可以执行上下切换,暂时停止一个正在运行的进程,并恢复(或启动)另一个进程。
根据调度的本身机制,考虑到计时器中断和上下切换,当 B 和C到达时,调度器会做一些其他的事情:抢占 A 的运行时间并运行其他进程,或者决定先暂停稍后再运行。而 SJF 是一个非抢占式调度程序,因此无法改变平均周转时间仍然很长的现状。
那么可否将抢占机制加到 SJF 中呢,这样就可以完善了?答案是可以的,添加后的结果称为最短完成时间优先(STCF)或抢占最短作业优先(PSJF)调度程序
Shortest Time-to-Completion First (STCF)
放宽假设3的要求,进程不必要一旦开始就定要执行完毕
每当新进程进入系统时,STCF调度器确定剩余进程 (包括新进程) 中剩余时间最少的进程,并调度该进程。

STCF将抢占 A 并运行 B 和 C 直到完成;只有当它们完成时,才会安排 A 的剩余时间。如此,平均周转时间计算为:
( 120 − 0 ) + ( 20 − 10 ) + ( 30 − 10 ) 3 = 50 {\frac{(120-0)+(20-10)+(30-10)}{3}} = 50 3(120−0)+(20−10)+(30−10)=50
和之前一样,考虑到我们的新假设,STCF是可证明最优的;考虑到如果所有工作同时到达,SJF是最优的。
However:
如果我们知道进程运行时间长度、进程仅需要 CPU,并且唯一的度量指标是周转时间,可以确定 STCF 是最优的调度策略。但是随着分时机的引入,用户在终端中也可以与系统进行交互。
出现了交互,我们需要引入一个新的度量指标:响应时间。
响应时间 [A New Metric: Response Time]
从进程到达系统到它第一次被调度的时间
T r e s p o n s e = T f i r s t r u n − T a r r i v a l T_{response} = T_{firstrun} - T_{arrival} Tresponse=Tfirstrun−Tarrival
利用之前的调度例子:
不同的是 A 在时间 0 时到达,B 和 C 在时间 10 时到达,每个进程的响应时间如下 : A为0,B为0,C为10,响应时间平均值为 3.33
可以看出:STCF及其相关并不利于优化响应时间。
For Example:
如果三个作业同时到达,那么第三个作业必须等待前两个作业全部运行,然后才进行一次调度。虽然这种方法对于周转时间很好,但是对于响应时间和交互性却很差。
实际上,现实生活中,终端前打字,不得不等上 10 秒钟才能看到系统的响应,因为在这之前有其他的进程已经被调度。
Q:
那么我们该如何构建一个对响应时间敏感的调度器?
A:
引入新的调度算法 − - −> Round Robin
轮询法 [Round Robin]
负载均衡算法【简称 RR】
RR 不再是一旦运行开始就必须运行完毕,而是运行一个时间片( 亦称为调度量 ),接着切换到运行队列中的下一个进程,反复这样做,直到所有工作完成。所以有时候 RR 冠之以时间切片的称号。
注意: 时间片的长度必须是计时器中断周期的倍数;因此,如果计时器每10毫秒中断一次,则时间片可以是10、20或任何其他10毫秒的倍数。
还是通过例子以达到对 RR 的彻底理解:
For Example:
假设A、B、C三个进程同时到达,并且每一个进程都希望运行 5 个时间单位。
一个 SJF 调度器就像之前介绍的一样在运行一个新的进程之前保证正在运行的进程运行完毕。
平均响应时间:(0+5+10) / 3 = 5 
相比之下,RR 按照 1 个时间单位的时间片可以很高效的完成所有任务。
平均响应时间:(0+1+2) / 3 = 1 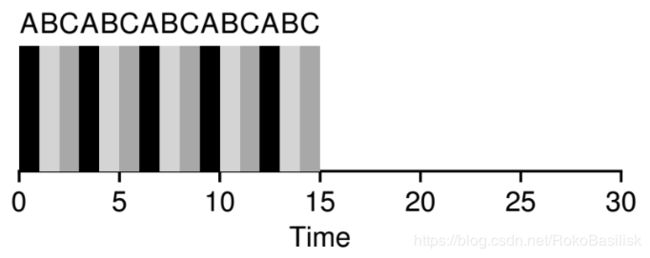
-
如上对比: 时间片的长度对于 RR 来说是至关重要的。它越短,在响应时间度量下 RR 的性能越好。
-
但是 ,盲目得让时间片太短是有问题的,突发的上下文切换带来的开销将主导整体性能。
-
因此,决定时间片的长度对系统设计人员来说是一种权衡。目的是使其有足够长的时间来摊销切换的成本,同时又不会使其太长而导致系统不再响应
【注意: 上下文切换的开销并不仅仅来自于OS保存和恢复几个寄存器的操作。当程序运行时,它们会在CPU缓存、缓存器、分支预测器和其他片上硬件中建立大量的状态。切换到另一个作业会导致刷新此状态并引入与当前正在运行的进程相关的新状态,这可能会导致显著的性能损失】
补充:
某项固定的开销产生时,往往伴随着系统中的摊销技术的体现。通过减少成本(即减少操作次数),降低了系统的总成本。
For Example:
-
如果时间片设置为10毫秒,而上下文切换成本为1毫秒,则大约10%的时间用于上下文切换,均被浪费;
-
如果我们想分摊这个成本,可以增加时间片到 100 毫秒。在这种情况下,不到 1% 的时间用于上下文切换,这样一来,时间成本得到了摊销。
-
如果响应时间是我们唯一的度量,那么具有合理时间片的RR就是一个非常好的调度器。
-
还记得之前我们以周转时间为唯一度量,那么在 RR 的例子的基础上,运行时间分别为 5 秒的 A、B和 C 同时到达,RR 是具有 1 个单位长时间片的调度器。从上面的图中我们可以看到,A结束于13,B结束于14,C结束于15,平均周转时间为14。
因此,如果周转时间是我们的度量标准,那么 RR 确实是最糟糕的策略之一也就不足为奇了。
从直觉上看: RR所做的就是尽可能地延长每个作业的执行时间,在执行下一个作业之前,只运行一小段时间。因为周转时间只关心作业何时完成,所以 RR 在特定情况下比 FIFO 的效果都差。
说白了就是:权衡
任何公平的策略(如 RR),即在小时间尺度上将 CPU 平均分配给活动进程的策略,相应的在周转时间等指标上都会表现不佳。
事实上,这是一种内在的权衡 。当然,你也可以运行更短的作业到完成,但代价是响应时间;如果你重视公平,则响应时间会降低,但代价是周转时间。
补充:
在尽可能的情况下,重叠操作得以最大限度地利用系统。重叠在许多不同的域中都很有用,包括在执行磁盘 I/O 或向远程计算机发送消息时;
在这两种情况下,启动操作然后切换到另一个工作空间,可以提高系统的总体利用率和效率。
至此,需要进行总结…
Summary
我们认知了两种类型的调度策略:【就两个度量指标进行对比】
-
第一种类型(SJF,STCF)优化了周转时间,但对响应时间不利。
-
第二种类型(RR)优化了响应时间,但不利于周转。
试回想 5 个假设,我们已经涉及到了前三个假设,并且都进行了需求更改。
接下来,需要进一步面对剩余两个假设…
Incorporating I/O
针对假设 4 :所有的进程均只利用 CPU(不执行任何 I/O)
对于假设 4 ,当然正常情况下所有程序都执行I/O。
-
设想一个不接受任何输入的程序,它每次都将会产生相同的输出;
-
再想象一个没有输出的程序,那么它有没有在运行似乎已经变得无关紧要。
当一个进程启动一个I/O请求时,调度器显然具有决策权。因为当前运行的进程在 I/O 期间不会使用CPU,它在等待 I/O 完成时被阻塞。
如果 I/O 是输出到硬盘驱动器,进程可能会被阻塞几毫秒甚至更长时间,具体取决于驱动器的当前 I/O 负载。从而,调度器可能在 CPU 上调度另一个进程。
具有决策权的调度器还必须在 I/O 完成时做出决定。做决定时会引发中断,操作系统运行并将请求 I/O 的进程从阻塞状态移回就绪状态。当然,它甚至也可以决定在那时进行这个任务。
Q:
那么,对待每一个进程,可以重新开始也可以继续进行,操作系统应该如何对待每项工作?
A:
e.g. 假设有两个进程,A 和 B,每个进程都需要50毫秒的计算时间。区别在于,A 运行10毫秒,然后发出一个I/O请求( 这里假设每个I/O需要10毫秒 ),而 B 只使用50毫秒计算时间,不执行I/O。这种情形下,调度器会先运行A,然后运行B。

Q:
假设我们用的调度器是STCF调度程序。那么应该如何解释?
A:
a 被分解成5个10毫秒的子作业,而B只是一个50毫秒的 CPU 需求,很显然,只需要运行一个进程,对于另一个没有把 I/O 考虑在内的进程是没有意义的。
另一种常见的方法是将 A 的每个 10ms 子作业视为独立作业。
因此,当系统启动时,其选择是调度 10 ms A还是 50 ms B。对于STCF,显然是选择较短的一个。当 A 的第一个子作业完成时,只剩下 B,它开始运行。然后提交一个新的 A 子作业,它抢占 B 并运行 10 ms。这样做允许重叠,一个进程使用CPU,同时等待另一个进程的 I/O 完成;高效的利用了 CPU。

Summary:
通过这种新的方法,我们可以看到调度器如何合并 I/O。将每个 CPU 突发当作一个作业来处理,调度器确保 “交互式” 运行。当这些交互作业执行 I/O 时,其他CPU密集型作业也会运行,从而更好地利用处理器。
No More Oracle
基于 合并 I/O 方法,我们就可以得到最后的假设,调度器知道每个作业的长度。正如我们之前所说,这可能是我们能做出的最不切实际的假设。事实上,在一个通用操作系统(就像我们关心的那些操作系统)中,操作系统通常对每个作业的长度知之甚少。
Summary
此文介绍了调度背后的基本思想,并开发了两种方法。第一个运行剩余的最短作业,从而优化周转时间;第二个在所有作业之间交替,从而优化响应时间。内在均衡问题导致无法判别某一种方法的绝对好坏。
我们也看到了如何将I/O集成到图片中,但仍然没有解决操作系统无法预见未来的问题。
经典 Q:
因此,如果没有这样的先验知识,我们怎么能建立一个像SJF/STCF这样的方法呢?此外,我们如何将我们看到的一些想法与RR调度器结合起来,从而使响应时间也相当好?
A:
通过构建一个调度程序,使用最近的过去来预测未来。这个调度程序称为多级反馈队列,见下回分晓…