分类/聚类结果评判指标: TP, TN, FP, FN,purity(纯度),F-scroe(F分数) python实现
Purity:
聚类划分的purity为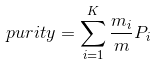 ,其中K是聚类(cluster)的数目,m是整个聚类划分所涉及到的成员个数。
,其中K是聚类(cluster)的数目,m是整个聚类划分所涉及到的成员个数。
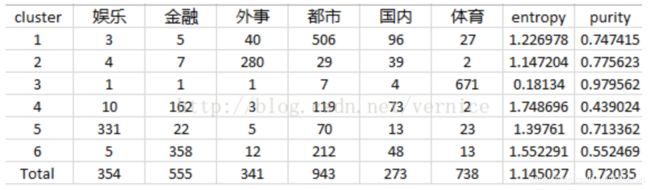
下表是对洛杉矶时报的3204篇文章进行k-means聚类的结果,k=6,label数=6。
python实现:
def purity(cluster, labels, k, label_set):
p = np.zeros((k, len(label_set)))
purity = 0
for i in range(len(cluster)):
p[int(cluster[i]), label_set.index(labels[i])] += 1
purity = sum(np.max(p, axis=1))/len(labels)
return purity
TP, TN, FP, FN
在二分类中:
TP(true positive):分类正确,把原本属于正类的样本分成正类。
TN(true negative):分类正确,把原本属于负类的样本分成负类。
FP(false positive):分类错误,把原本属于负类的错分成了正类。
FN(false negative):分类错误,把原本属于正类的错分成了负类。
后一个字母(N or P )是模型预测的结果,第一个字母(T or N ) 代表的是这个结果的正确与否

Accuracy准确率
准确率也就是正确比例
二分类:
Accuracy = (TN + TP) / (TP + TN + FP + FN)
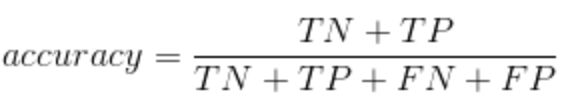
多分类:
Overall Accuracy:被正确分类的示例在数据集中的比例
ps:不适用于数据集不平衡的时候
例如:分类问题的数据集中本来就有97% 示例是属于X,只有另外3%不属于X,所有示例都被分类成X的时候,准确率很高为97%,但是不代表分类的效果好
Recall 召回率
又称:Sensitivity(灵敏度), TP Rate , True Positive Rate , Probability。
Recall=TP / (TP + FN)
真正属于X的示例中,成功预测为属于X(TP)的比例。
F-score
指标F-score能够综合考虑Precision和Recall的调和值
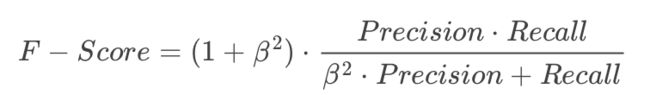
(多类)python实现:
def f_score(cluster, labels, label_set):
TP, TN, FP, FN = 0, 0, 0, 0
n = len(labels)
# a lookup table
for i in range(n):
if i not in cluster:
continue
for j in range(i + 1, n):
if j not in cluster:
continue
same_label = (labels[i] == labels[j])
same_cluster = (cluster[i] == cluster[j])
if same_cluster:
if same_label:
TP += 1
else:
FP += 1
elif same_label:
FN += 1
else:
TN += 1
precision = TP / (TP + FP)
recall = TP / (TP + FN)
fscore = 2 * precision * recall / (precision + recall)
return fscore, precision, recall, TP + FP + FN + TN
代码及数据下载:https://download.csdn.net/download/SAM2un/12036441